网络爬虫
什么是网络爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫会遇到的问题
有人抓取,就会有人想要防御。网络爬虫在运行过程中也会遇到反爬虫策略。常见的有:
- 访问频率限制;
- Header头部信息校验;
- 采用动态页面生成;
- 访问地址限制;
- 登录限制;
- 验证码限制等。
这些只是传统的反爬虫手段,随着AI时代的到来,也会有更先进的手段的到来。
一个简单的爬虫示例
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.MalformedURLException; import java.net.URL; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Reptile { public static void main(String[] args) { // 传入你所要爬取的页面地址 String url1 = "http://www.xxxx.com.cn/"; // 创建输入流用于读取流 InputStream is = null; // 包装流, 加快读取速度 BufferedReader br = null; // 用来保存读取页面的数据. StringBuffer html = new StringBuffer(); // 创建临时字符串用于保存每一次读的一行数据,然后 html 调用 append 方法写入 temp; String temp = ""; try { // 获取 URL; URL url2 = new URL(url1); // 打开流,准备开始读取数据; is = url2.openStream(); // 将流包装成字符流,调用 br.readLine() 可以提高读取效率,每次读取一行; br = new BufferedReader(new InputStreamReader(is)); // 读取数据, 调用 br.readLine() 方法每次读取一行数据, 并赋值给 temp, 如果没数据则值 ==null, // 跳出循环; while ((temp = br.readLine()) != null) { // 将 temp 的值追加给 html, 这里注意的时 String 跟 StringBuffer // 的区别前者不是可变的后者是可变的; html.append(temp); } // 接下来是关闭流, 防止资源的浪费; if (is != null) { is.close(); is = null; } // 通过 Jsoup 解析页面, 生成一个 document 对象; Document doc = Jsoup.parse(html.toString()); // 通过 class 的名字得到(即 XX), 一个数组对象 Elements 里面有我们想要的数据, 至于这个 div的值,打开浏览器按下 F12 就知道了; Elements elements = doc.getElementsByClass("xx"); for (Element element : elements) { // 打印出每一个节点的信息; 选择性的保留想要的数据, 一般都是获取个固定的索引; System.out.println(element.text()); } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }
示例分析:
- 输入想要爬取的url地址;
- 发送网络请求获取页面内容;
- 使用jsoup解析dom;
- 获取需要的数据,输出到控制台。
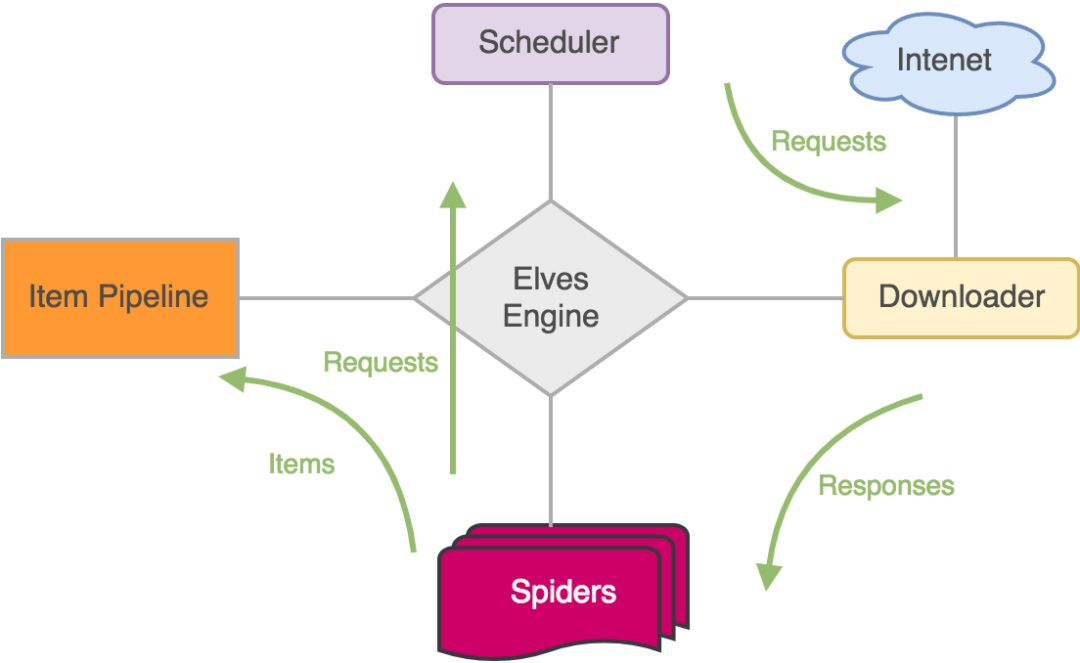
网路爬虫框架
设计框架的目的就是将这些流程统一化,将通用的功能进行抽象,减少重复工作。设计网络爬虫框架需要哪些组件呢?
- url管理;
- 网页下载器;
- 爬虫调度器;
- 网页解析器;
- 数据处理器。
- URL管理器
爬虫框架要处理很多的 URL,我们需要设计一个队列存储所有要处理的 URL,这种先进先出的数据结构非常符合这个需求。 将所有要下载的 URL 存储在待处理队列中,每次下载会取出一个,队列中就会少一个。我们知道有些 URL 的下载会有反爬虫策略, 所以针对这些请求需要做一些特殊的设置,进而可以对 URL 进行封装抽出 Request。
- 页面下载器
如果没有网页下载器,用户就要编写网络请求的处理代码,这无疑对每个 URL 都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用什么库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网络请求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
- 爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的 URL 发送给调度器,调度器再次的传输给下载器,这样就会让各个组件有条不紊的进行工作。
- 网页解析器
我们知道当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还需要提取出真正需要的数据, 以前的做法是通过 String 的 API 或者正则表达式的方式在 DOM 中搜寻,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方式来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
- 数据处理
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应该是各司其职的,我们先通过解析器将需要的数据解析出来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是存储到数据库,也可能通过接口发送给老王。
基本特性
上面说了这么多,我们设计的爬虫框架有以下几个特性,没有做到大而全,可以称得上轻量迷你挺好用。
-
易于定制:很多站点的下载频率、浏览器要求是不同的,爬虫框架需要提供此处扩展配置
-
多线程下载:当 CPU 核数多的时候多线程下载可以更快完成任务
-
支持 XPath 和 CSS 选择器解析
架构图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号