hashmap
HashMap是如何定位下标的?#
先获取 key ,对 key 进行 hash 得到 一个hashcode, 然后用 Hashcode 与 hashmap 中 的
数组长度 - 1进行 按位与 运算, 取得下标
至于为什么用
&(按位与运算) 而不是 使用%(取余),是因为 取余在 某些 应用上边运算比较慢 ,而&是基于 二进制 的运算, 怎样运行都不会太慢
HashMap由什么组成?#
数组 + (单)链表,在jdk1.8 中又添加了 红黑树, 当链表节点数超过 8 且 数组长度 大于等于 64 时 才会树化,如果
数组长度小于 64 ,则会选择扩容
为什么选择红黑树,而不是其他数据结构?
红黑树的 查询和插入效率 都是比较高的,这是一个综合取优 的选择
树化阈值(8) 与 退化阈值(6) 为什么不选取一样的值
红黑树在 节点 小于 6 个时,会退化为链表,退化的阈值选择为 6
主要是为了防止出现节点个数频繁在一个相同的数值来回切换,举个极端例子,现在单链表的节点个数是9,开始变成红黑树,然后红黑树节点个数又变成8,就又得变成单链表,然后节点个数又变成9,就又得变成红黑树,这样的情况消耗严重浪费,因此干脆错开两个阈值的大小,使得变成红黑树后“不那么容易”就需要变回单链表,同样,使得变成单链表后,“不那么容易”就需要变回红黑树
HashMap往链表里插入节点的方式#
jdk1.7: 采用的是头插法,效率高, 但是链表容易过长影响查询效率且
线程同时扩容时容易出现死链jdk1.8以后是尾插法,为了防止环化,而且引入红黑树之后,就需要判断单链表的节点个数(超过8个后要转换成红黑树),所以干脆使用尾插法,正好遍历单链表,读取节点个数。也正是因为尾插法,使得HashMap在插入节点时,可以判断是否有重复节点。
Hashmap中的 put(未完)#
Hashmap 是 懒加载,并不会立即初始化,在开始使用时才会初始化
jdk1.7:
- 判断数组是否为空,如果为空进行初始化,初始化的是数组容量
- 判断key是否为空,执行方法,key为null存在index为0的位置
- 根据key得到hash,对key进行hashcode,
- 根据hash值和容量得到下标,indexFor方法
- 覆盖逻辑,遍历链表,短路与先判断hash值是否相等,再判断key,value覆盖,返回oldvalue
- addEntry(hash,key,value,i),先有(@Q6扩容机制),再根据四个值,头插法或尾插法插入
jdk1.8:
- 判断数组是否为空,调用resize方法进行初始化
- 判断数组元素是否为空,为空则添加新节点
hashmap 里面的数组容量为什么是 2 的 幂次方#
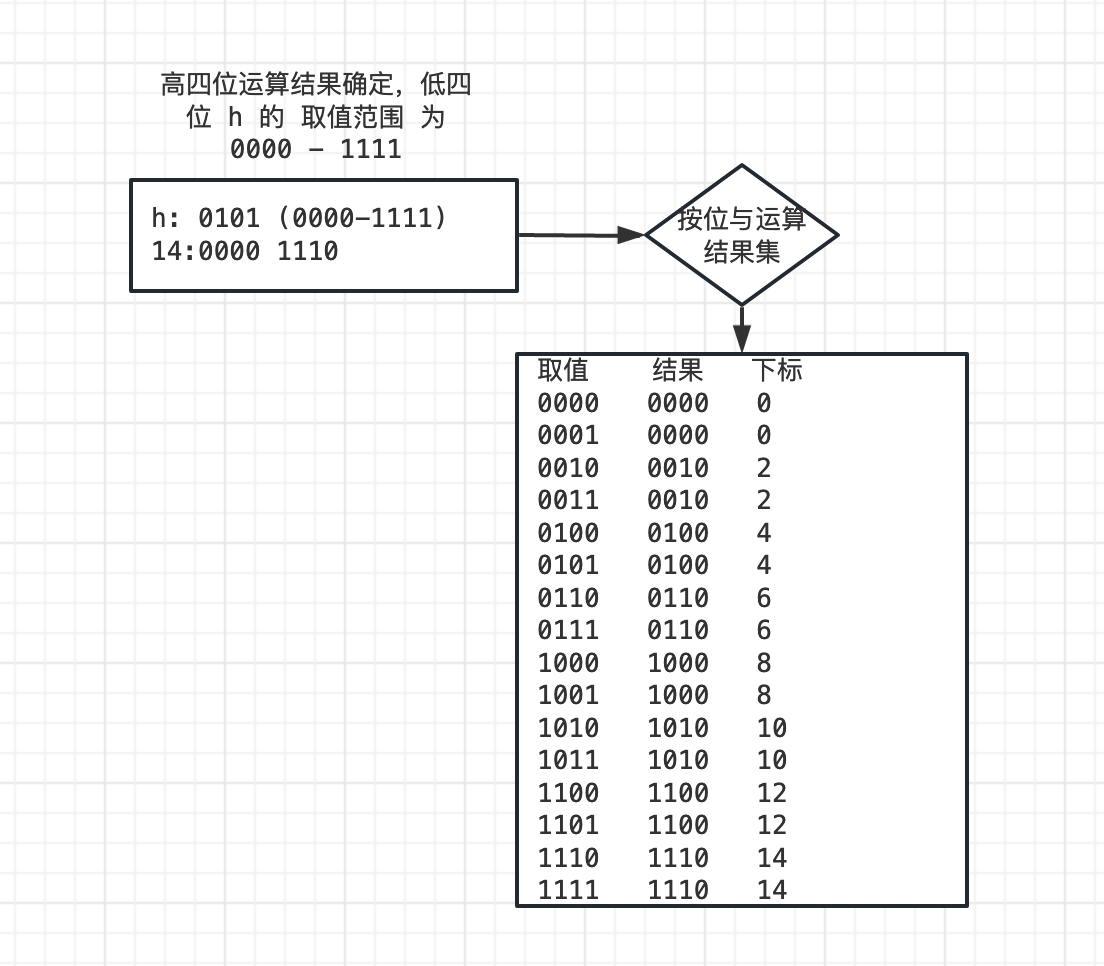
当容量为 2 的幂次方时, 转换为 二进制 才只有 一位 为1 : 如: 0001 0000(16) , 0010 0000(32)
例如 hashcode 的值为 0101 0101, 数组的长度为 16 则因为数组的可用下标 为 0-15 所以 数组长度 在与 hashcode 进行 与 运算时 需要减 1 即: h 为 hashcode, l 为数组长度 - 1
h: 0101 0101
l: 0000 1111 此时进行 与 运算结果为 0000 0101(5) 就为 数组下标. 而此时可用值的范围为[1]
0000~1111,满足数组的索引如果 数组的长度为 17(0-16) 或者 15(0-14)
h: 0101 0101
14: 0000 1110 此时的可用范围 只有 0000() - 1110(14) 运算结果如下,会形成链表,降低了查询速率,且造成数组内存空间为的 浪费
16: 0001 0000 此时的可用范围(对于当前的 Hashcode 值) 只有 0001 0000 即 只有一个能用的值
至于为什么用
&(按位与运算) 而不是 使用%(取余),是因为 取余在 某些 应用上边运算比较慢 ,而&是基于 二进制 的运算, 怎样运行都不会太慢
hashmap 在计算 hashcode 值时为什么要 进行右移 及 异或运算#
先右移: 高位补 0 低位省略,
再异或运算: 相同 为 0 不同为 1
结果再与 Hashcode的值进行 按位与运算
这样使得 高位也可以影响到运算的结果
上边 的情况中 实际上决定运算结果的只有 低位, 而进行 右移及异或运算 是为了 让 高位也参与进来
这样的话 可以有效的 缓解哈希冲突 问题
扩容#
JDK1.7 : 先扩容,再添加
在添加元素时还是会 遍历节点,但是不一定会遍历完链表,找到与添加元素的key 相同是直接替换,不会再往下遍历
JDK1.8: 先添加元素,再扩容
使用的是尾插法,因为要判断链表长度,所以无论如何都需要完全遍历, 在添加元素时,同上
注释#
在此例子,因为 高四位 的运算结果永远 为 0 ,所以可用值的范围就由 低四位 的运算结果决定 ↩︎
作者:Bikakaso
出处:https://www.cnblogs.com/Bikakaso/p/hashmap.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
本文来自博客园,作者:Bikakaso,转载请注明原文链接:https://www.cnblogs.com/Bikakaso/p/hashmap.html




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)