
结对编程
【作业信息】
结对过程及照片
结对过程
这次结对编程非常荣幸能够和编程大佬罗伟诚组队。我在群里面问了一下有没有人还没组队,然后他就回我了,问我要不要组队,我说要得,然后我们就正式结对。确定结对之后为了以后更好的沟通合作,我们先是制定了编码规范,然后就开始写代码,罗伟诚对于编程非常积极,我们三下五除二就把程序编好了,跟他合作也非常愉快。
编码规范
1.命名规范:总体采用驼峰命名法,类名首字母大写,变量和方法名首字母小写,常量全部大写,禁止拼音命名。
2.布局:采用vs自动缩进,大括号不于代码同行,注释单独在一行,位于注释部分的上方。
3.接口:方法的形参和传输的参数命名相同,必要时在上方备注参数类型
4.代码规范:
适当使用空行,来增加代码的可读性
方法的命名,一般将其命名为动宾短语,一个方法只完成一个任务
常用缩进和换行,使代码层次清晰,明了
对泛型进行循坏时,尽量foreach
缩进和间隔:缩进用TAB,不用 SPACES
注释需和代码对齐
避免写太长的方法。一个典型的方法代码在1~25行之间。
结对编程照片

PSP表格
| PSP2.1 | Personal Software Process Stages | 估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| ·Planning | ·计划 | 40 | 55 |
| ·Estimate | · 估计这个任务需要多少时间 | 90 | 90 |
| ·Development | ·开发 | 60 | 75 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 35 |
| · Design Spec | · 生成设计文档 | 15 | 18 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 40 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 50 | 70 |
| ·Reporting | ·报告 | 100 | 120 |
| · Test Report | · 测试报告 | 50 | 55 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 10 |
| ___ | 合计 | 685 | 823 |
解题思路描述
-对于这种类型的编程我也是第一次接触,首先百度这种程序该怎么写。知道这种程序的写法后就开始想算法。首先确定功能,在博客要求中功能已经列举的很详细经过我们整理,主要要以下功能
1.统计文件字符
这个功能比较好实现,因为Windows自带的函数库就可以解决。这个功能的要求是统计所有字符,包括空格,换行,所以我们只需要读取文件,把内容转化为字符串,然后再用CharactersNum()方法就可以统计所有的字符数
2.统计单词数
对于这个功能,我们首先想到的是计算文本里面的空格数。但是题目要求:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。所以这里需要用到正则表达式进行限制。按行读取文本,存入集合中,再用正则表达式进行筛选。
3.统计行数
这个也简单,直接统计换行符即可
4.统计单词频率
在统计单词数的基础上,将确定为单词的字符串存入一个集合中,然后再从第一个单词开始进行匹配,并计数。
5.写入文件
首先输入文件路径,然后用StreamWriter()创建一个对象,再用里面的write方法,就可以将内容写入文件。
6.筛选定长单词
在统计单词个数的基础上,将确定为单词的字符串存入一个列表中,然后依次遍历每个单词,再用string.len()可以得到每个单词的长度,然筛选出指定长度的单词即可
实现过程
首先类的设计就两个,第一个数函数类,第二个方法类。主函数类调用方法,而方法类中包含了所有需要用到的方法。方法类就七个函数,其中有一个公共方法getDic 这个方法用于获得字典,存入字典中的是长度大于四且不以数
字开头的单词以及他们出现的次数,这个方法会返回一个Hashtable,方法getWordFre()方法将字典按照单词出现的次数进行排序,并返回一个动态数组。
其他的,可以直接调用,getWordFre这个方法利用返回的数组进行相应功能的实现。
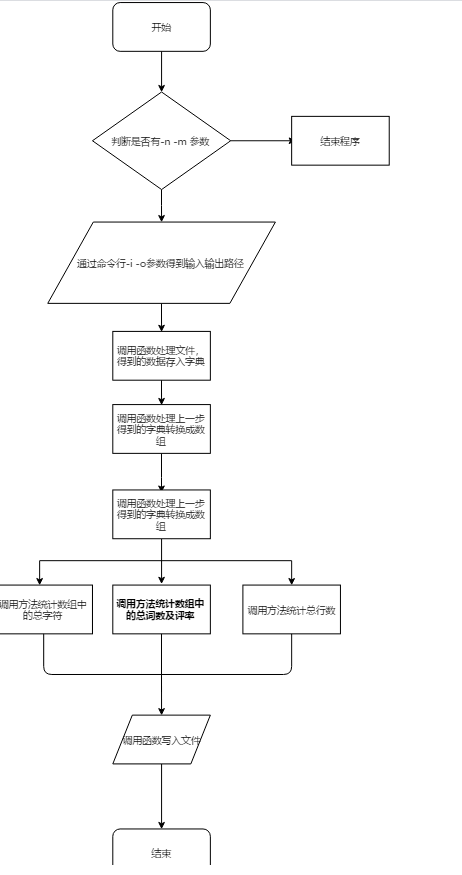
流程图
单元测试
部分测试代码
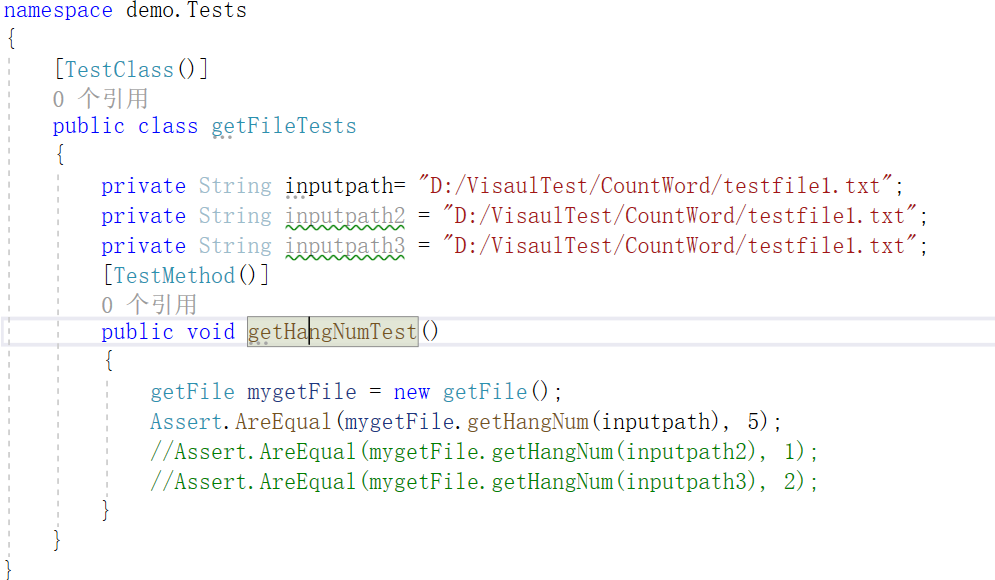
测试结果
测试文件

如图所示,结果符合预期。
单元测试2
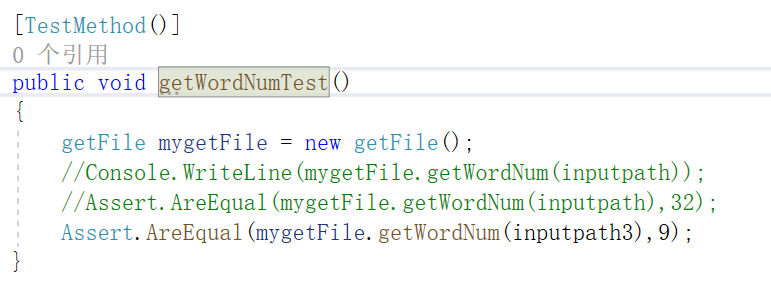
测试文件

结果
测试文件

代码互审
代码互审我们进行得比较模糊,就是每个人完成了一个功能模块,再交给另一个人测试,审核,看看有没有错误,或者有没有更好的算法。
刚开始我们都不知道用正则表达式,我也是通过百度才了解正则表达,然后我们就改进了以前写的算法,大幅度缩短了代码量而且出错率低
性能测试及改进
性能分析如图所示

性能分析是我们完成代码之后一起做的,所以这张图是和罗伟诚一样的。
这里的代码改进主要有两点,第一点使用字典,第二点使用正则表达式。
刚开始写代码的时候,首先想到的使用数组,或者字符串类型封装的一
写方法。但是这样编写起来代码冗长,而且容易出错,最后我们采用了
比较高效的正则表达式和字典。
代码说明
1.获取字典
提取文本中的单词并放入列表中,同时统计出每个词词频放到Hashtable中,最后返回一个Hashtable

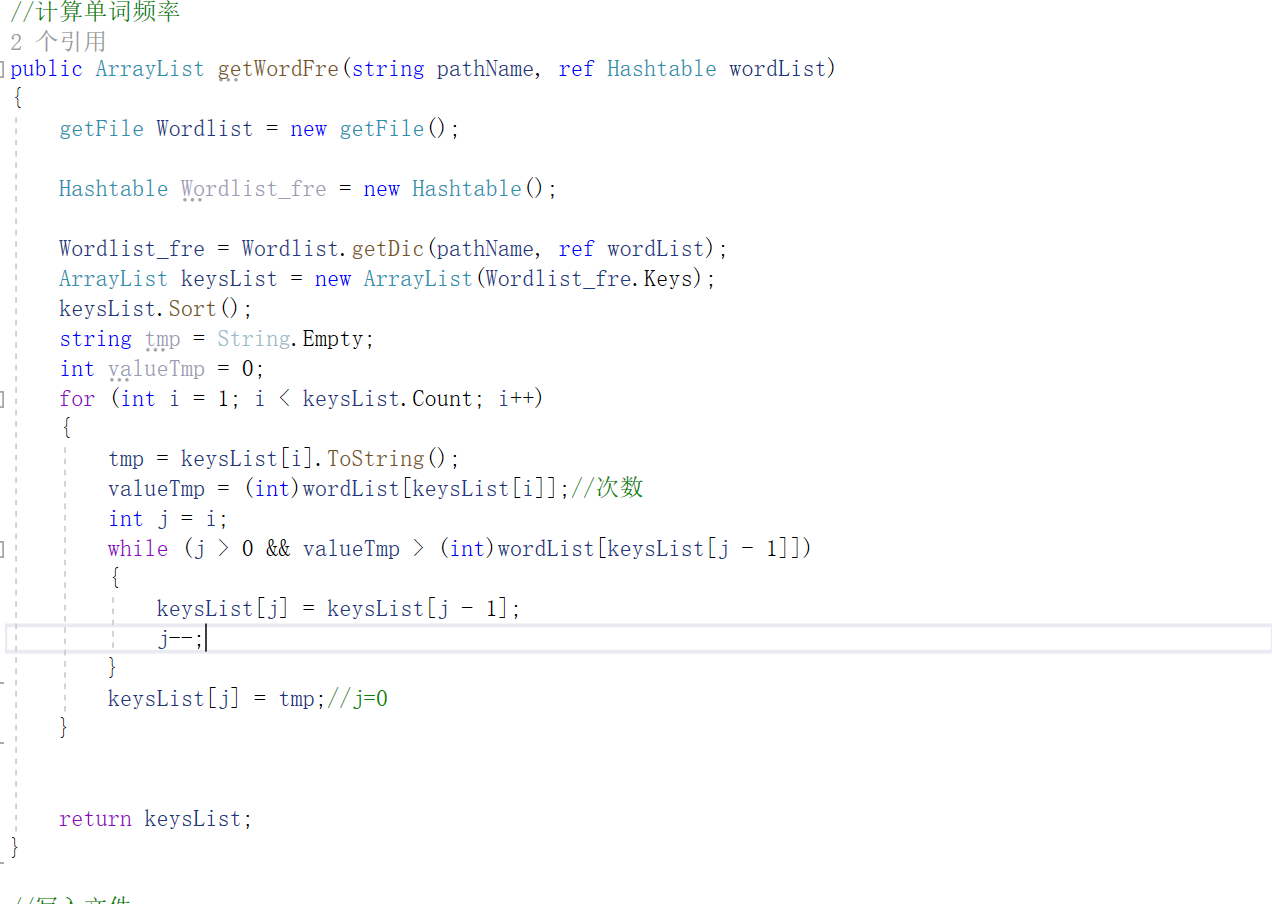
2.计算单词频率
getWordFre(string pathName, ref Hashtable wordList)将传递过来的wordList进行按频率排序,并将Hashtable转换成动态数组并返回
3. 将结果写入文件
首先输入文件路径,然后用StreamWriter()创建一个对象,再用里面的write方法,就可以将内容写入指定文件。
public void write(string outputPath, ref Hashtable wordList, int lines, int words, int characters, int wordsOutNumFla, int wordsOutNum, int m, string inputPath)
{
getFile Wordlist = new getFile();
ArrayList keysList = new ArrayList();
ArrayList keysList1 = new ArrayList();
keysList1 = Wordlist.getPhrase(inputPath, outputPath, ref wordList, m);
keysList = Wordlist.getWordFre(outputPath, ref wordList);
StreamWriter sw = new StreamWriter(outputPath);
sw.WriteLine("characters:{0}", characters);
sw.WriteLine("words:{0}", words);
sw.WriteLine("lines:{0}", lines);
if (wordsOutNumFla == 1)
{
wordsOutNum = wordsOutNum;
}
else
wordsOutNum = 10;
for (int i = 0; i < wordsOutNum; i++)
{
sw.WriteLine("<{0}>:{1}", keysList[i], wordList[keysList[i]]);
}
sw.WriteLine("以下是长度为{0}的词组:\n", m);
foreach (string j in keysList1)
{
sw.WriteLine("<{0}>:{1}", j, 1);
}
sw.Flush();
sw.Close();
}
4.统计行数
按行读取,每读取一行加一,最后得出行数

5.统计单词数,读取文件,用正则表达式进行筛选

6.统计字符数,这个比较简单,按行读取文件,累加每行的长度即可

7.获取定长单词数量

感想总结
首先看到题目要求的时候就觉得脑壳大,想了半个小时才把逻辑相同。然后在编写代码的时候也比较头疼,因为我是第一次接触这种命令行的程序。以前写的都先运行程序,然后再一个一个输入参数运行。通过罗伟诚的科普,我才知道,原来主函数的参数 args[]数组是用来存放吗命令的。我让罗伟诚写了一段,示范给我看一下,这才理解了。这次的结对编程,不仅体验到了两个写代码的优越性,还让我学会了使用字典和正则表达式。最后感谢罗伟诚的合作和帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号