
一、Rancher管理
1. 为什么要选择Rancher
docker本身只提供了一个运行环境,除了把服务跑起来外,我们还需要让多个服务容器协同起来工作,所以,我们就需要一个容器编排系统,一般来说我们期望编排系统能帮我们实现几个目的:
(1)基本发布自动化功能:
编排过程包含分配机器,拉取镜像,启动/停止/更新容器,存活监控,容器数量扩展和收缩
(2)声明式定义服务栈:
提供一种机制,可以用配置文件来声明服务的网络端口,镜像及版本,在需要的时候通过配置可再现的创建出一整套服务。
(3)服务发现:
提供DNS和负载均衡,一个容器启动之后,需要其他服务能够访问到它,一个容器终止运行之后,需要保证流量不会再导向它。
(4)状态检查:
需要持续监控系统是否符合配置中声明的状态,比如一台宿主机挂了,需要把上面运行的容器在其他健康的节点上启动起来,如果一个容器挂了,需要把它重新启动。
从设计思路,社区活跃度等因素来看,Kubernetes无疑是编排工具最好的选择,但由于组件较多,学习成本并不低,还有墙的因素,在国内甚至安装都不是件容易的事。
这个时候我们发现Rancher正式发布了,虽然没有kubernetes那么热门,但它提供了所有我们需要的功能,还有一个简单容易上手的Web UI。在早期我们的机器和服务数量都比 较少,又急需一个编排工具好把有限精力都投入到开发上,所以迅速的把服务都迁移到Rancher上了。
准确的说,Rancher是一套容器管理打包方案,支持三种编排引擎:Kubernetes,Swarm,还有Rancher自己开发的Cattle(最近好像换成了Mesos)。从功能的完整性和易用性来看,Rancher甚至可以算得上一个商业软件了,部署极其简单,这也是我们选择它作为入门级容器管理平台的原因。
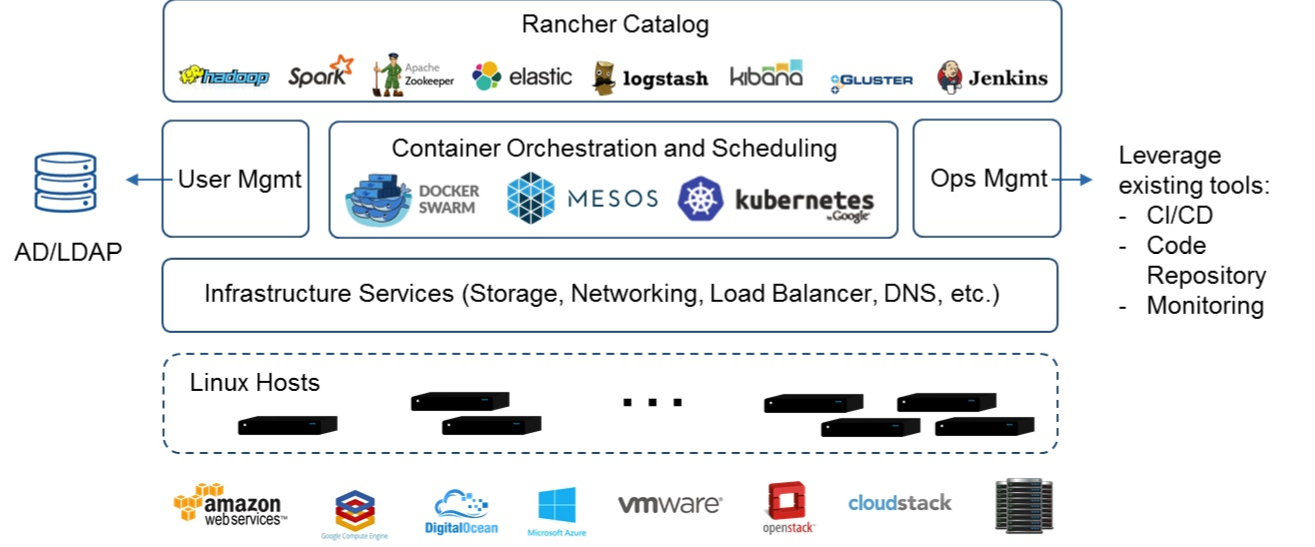
Rancher组件图,中小企业常用的软件功能都能找到:
2. 具体演示
添加应用(以测试环境为例)

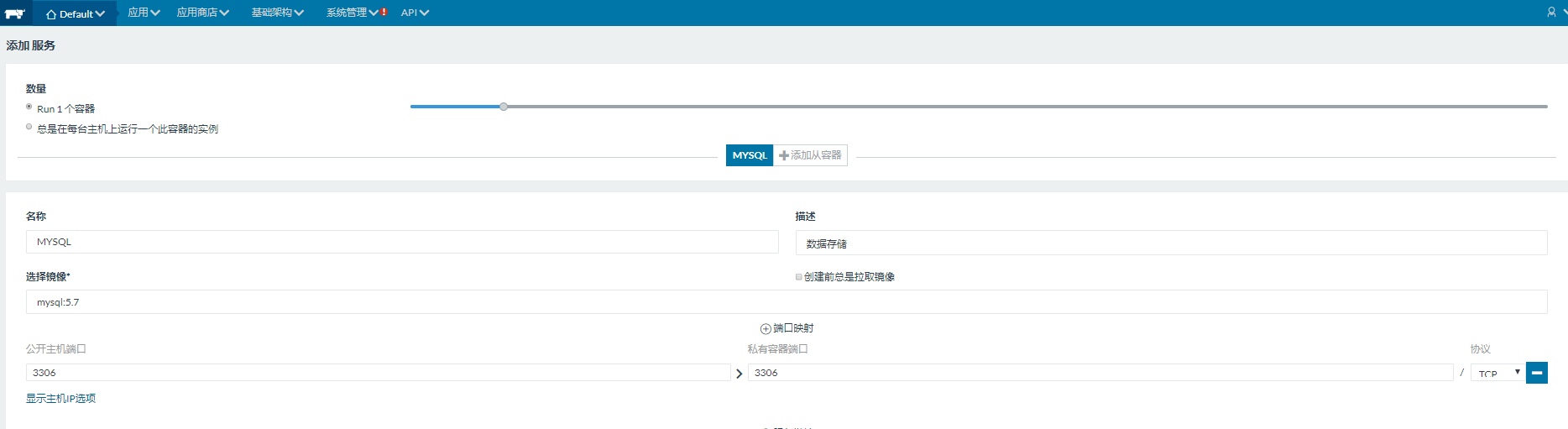
添加服务(以Mysql为例)
(1)导入镜像,设置端口参数
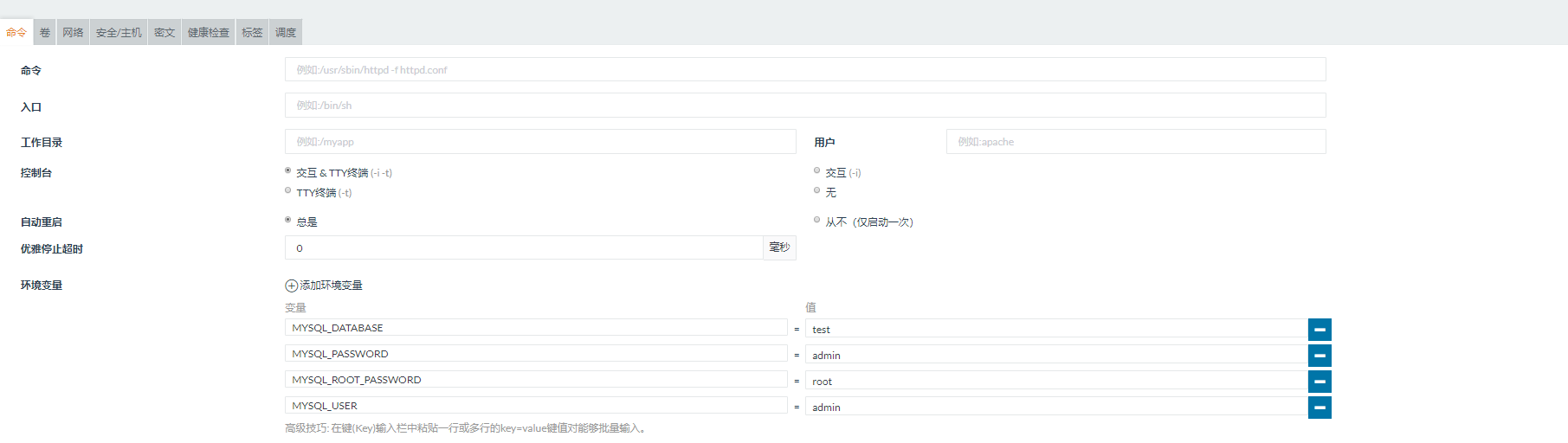
(2)在mysql中设置环境变量:mysql的用户、密码、数据库都可以创建
二、Kafka+Spark-Streaming构建实时计算平台
1. Kafka应用场景
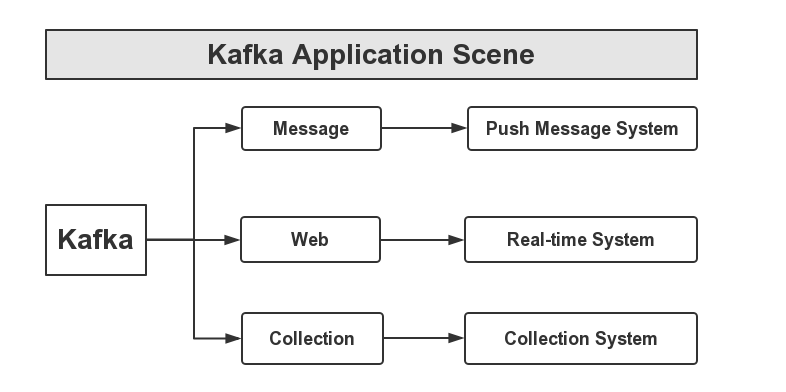
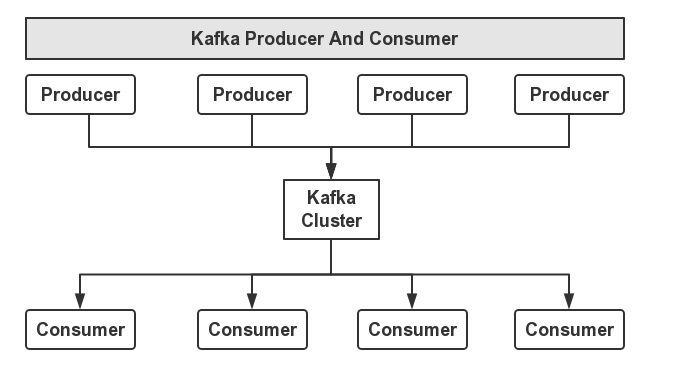
首先,Kafka可以应用于消息系统,比如,当下较为热门的消息推送,这些消息推送系统的消息源,可以使用Kafka作为系统的核心组建来完成消息的生产和消息的消费。然后是网站的行迹,我们可以将企业的Portal,用户的操作记录等信息发送到Kafka中,按照实际业务需求,可以进行实时监控,或者做离线处理等。最后,一个是日志收集,类似于Flume套件这样的日志收集系统,但Kafka的设计架构采用push/pull,适合异构集群,Kafka可以批量提交消息,对Producer来说,在性能方面基本上是无消耗的,而在Consumer端中,我们可以使用HDFS这类的分布式文件存储系统进行存储。
2.1. Spark-Streaming概念

Spark Streaming内部工作原理,其接收实时输入数据流,同时将数据划分成批次,然后通过Spark引擎处理生成按照批次的结果流。

2.2. Spark-Streaming应用场景
通过获取Kafka中的流数据,将其进行一定的业务逻辑处理(如计数统计,筛选,修改等操作),并输出到外部系统(如HDFS)。目前Spark Streaming在业务场景中主要ETL、实时报表统计、个性化推荐类的营销场景以及风控与安全的应用。从抽象上来说,可以分为数据过滤抽取、数据指标统计与模型算法的使用。其中,实时报表统计与展现也是Spark Streaming使用较多的一个场景,数据可以基于Process Time统计,也可以基于Event Time统计。由于本身Spark Streaming不同批次的job可以视为一个个的滚动窗口,某个独立的窗口中包含了多个时间段的数据,这使得使用SparkStreaming基于Event Time统计时存在一定的限制。一般较为常用的方式是统计每个批次中不同时间维度的累积值并导入到外部系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号