Java Web(1)高并发业务
互联网无时无刻不面对着高并发问题,例如商品秒杀、微信群抢红包、大麦网抢演唱会门票等。
当一个Web系统,在一秒内收到数以万计甚至更多的请求时,系统的优化和稳定是至关重要的。
互联网的开发包括Java后台、NoSQL、数据库、限流、CDN、负载均衡等。
一、互联系统应用架构基础分析

防火墙的功能是防止互联网上的病毒和其他攻击,正常的请求通过防火墙后,最先到达的就是负载均衡器。
负载均衡器的主要功能:
- 对业务请求做初步的分析,决定分不分发请求到Web服务器,常见的分发软件比如Nginx和Apache等反向代理服务器,它们在关卡处可以通过配置禁止一些无效的请求,比如封禁经常作弊的IP地址,也可以使用Lua、C语言联合 NoSQL 缓存技术进行业务分析,这样就可以初步分析业务,决定是否需要分发到服务器
- 提供路由算法,它可以提供一些负载均衡算法,根据各个服务器的负载能力进行合理分发,每一个Web服务器得到比较均衡的请求,从而降低单个服务器的压力,提高系统的响应能力。
- 限流,对于一些高并发时刻,如双十一,需要通过限流来处理,因为可能某个时刻通过上述的算法让有效请求过多到达服务器,使得一些Web服务器或者数据库服务器产生宕机。当某台机器宕机后,会使得其他服务器承受更大的请求量,这样就容易产生多台服务器连续宕机的可能性,持续下去就会引发服务器雪崩。因此,在这种情况下,负载均衡器有限流的算法,对于请求过多的时刻,可以告知用户系统繁忙,稍后再试,从而保证系统持续可用。
为了应对复杂的业务,可以把业务存储在 NoSQL 上,通过C语言或者Lua语言进行逻辑判断,它们的性能比Web服务器判断的性能要快速得多,从而降低Web服务器的压力,提高互联网系统的响应速度。
二、应对无效请求
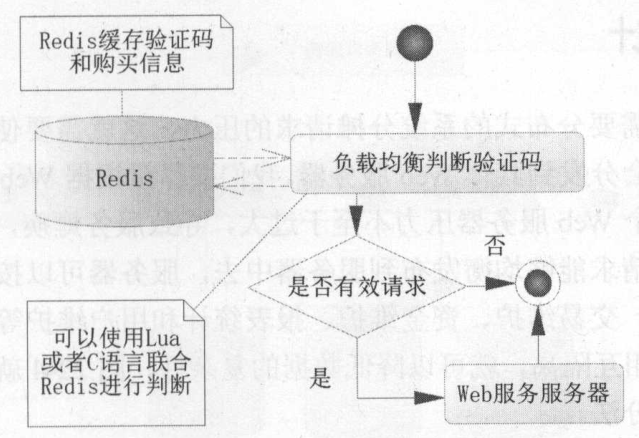
在负载均衡器转发给Web服务器之前,使用C语言和Redis进行判断是否是无效请求。对于黄牛组织,可以考虑僵尸账号排除法进行应对。
三、系统设计
高并发系统往往需要分布式的系统分摊请求的压力,要尽量根据 Web 服务器的性能进行均衡分配请求。
划分系统可以按照业务划分,即水平划分。也可以不按照业务分,即垂直划分。
按照业务划分可以提高开发效率以及更方便地设计数据库。但是,还要通过RPC(Remote Procedure Call Protocol)远程过程调用协议处理这些信息,例如Dubbo、Thrift和Hessian等。
四、数据库设计
为了得到高性能,可以使用分表或分库技术,从而提高系统的响应能力。
分表是指在一个数据库内本来一张表可以保存的数据,设计成多张表去保存。例如,将每一年的交易记录分别分成交易表,而不是只有一张交易表来记录所有的交易记录。
分库是把表数据分配在不同的数据库中,分库首先需要一个路由算法确定数据在哪个数据库上,然后才能进行查询,这里可以把用户和对应业务的数据库的信息缓存到Redis中,这样路由算法就可以通过Redis从读取的数据来决定使用哪个数据库进行查询了。
另外,还可以考虑SQL优化,建立索引等优化,提高数据库的性能。
五、动静分离技术
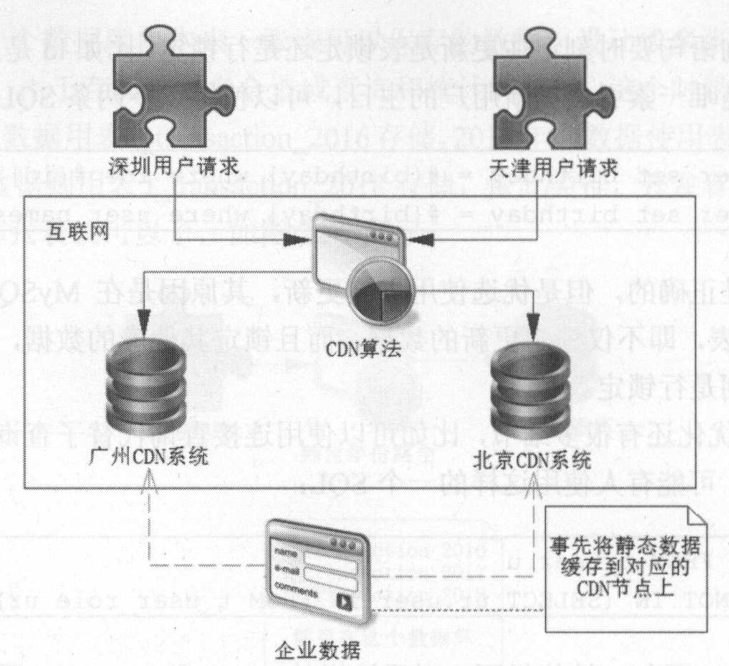
对于互联网而言,大部分数据都是静态数据,只有少数使用动态数据,动态数据的数据包很小,不会造成网络瓶颈,而静态的数据则不一样,静态数据包含图片、CSS、JavaScript 和视频等互联网的应用,尤其是图片和视频占据的流量很大,如果都从动态服务器(比如Tomcat、WildFly和WebLogic等)获取,那么动态服务器的带宽压力会很大,这个时候应该考虑动静分离技术。
可以使用静态HTTP服务器,例如Apache,将静态数据分离到静态HTTP服务器上,这样图片、HTML、脚本等资源都可以从静态服务器上获取,尽量使用 Cookie 等技术,让客户端缓存能够缓存数据,避免多次请求,降低服务器的压力。
企业可以还可以使用高级的动静分离技术,例如CDN(Content Delivery Network,即内容分发网络),它允许企业将自己的静态数据缓存到网络 CDN 的节点中,对于用户的请求,直接通过CDN算法去指定的CDN节点去响应请求。
六、锁和高并发
无论区分有效请求和无效请求、水平划分还是垂直划分、动静分离技术,还是数据库分表、分库技术,都无法避免动态数据,而动态数据的请求最终也会落在一台 Web 服务器上。
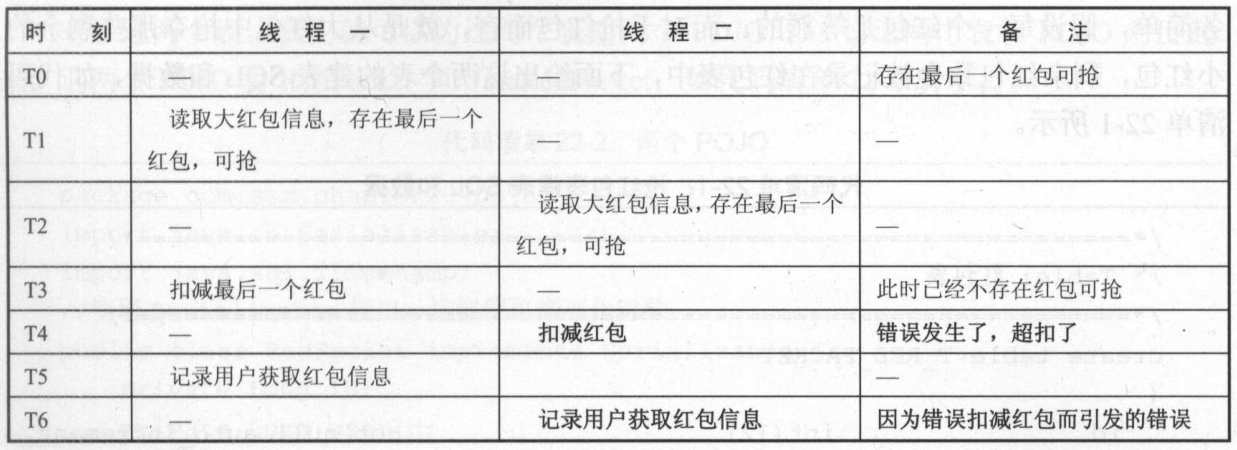
例如,发放一个总额为 20 万元的红包,拆分成 2 万个金额为 10 元 的小红包,供给网站的 3 万个会员在线抢夺,这就是一个典型的高并发的场景。
由于会出现多个线程同时发起请求,由于线程每一步完成的顺序不一样,这样会导致数据的一致性问题。
为了保证数据一致性,可以使用加锁的方式,但是加锁会影响并发,从而影响系统的性能,而不加锁就难以保证数据的一致性,这就是锁和高并发的矛盾。
为了解决锁和高并发的矛盾,大部分企业提出了悲观锁和乐观锁的概念,
- 对于数据库而言,如果在短时间内需要执行大量SQL,对于服务器的压力可想而知,需要优化数据库的表设计、索引、SQL语句等。
- 还可以使用 Redis 事务和 Lua 语言所提供的原子性来取代现有的数据库技术,从而提高数据的存储响应,以应对高并发场景,但是严格来说也属于乐观锁。
0.T_RED_PACKET为红包表,T_USER_RED_PACKET为用户抢红包表
(0)未加锁情况下,并发导致了数据的不一致
<!-- 查询红包具体信息 --> <select id="getRedPacket" parameterType="long" resultType="com.ssm.chapter22.pojo.RedPacket"> select id, user_id as userId, amount, send_date as sendDate, total, unit_amount as unitAmount, stock, version, note from T_RED_PACKET where id = #{id} </select>
业务逻辑:
@Override @Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED) public int grapRedPacket(Long redPacketId, Long userId) { // 获取红包信息 // RedPacket redPacket = redPacketDao.getRedPacket(redPacketId); // 悲观锁 RedPacket redPacket = redPacketDao.getRedPacketForUpdate(redPacketId); // 当前小红包库存大于0 if (redPacket.getStock() > 0) { redPacketDao.decreaseRedPacket(redPacketId); // 生成抢红包信息 UserRedPacket userRedPacket = new UserRedPacket(); userRedPacket.setRedPacketId(redPacketId); userRedPacket.setUserId(userId); userRedPacket.setAmount(redPacket.getUnitAmount()); userRedPacket.setNote("抢红包 " + redPacketId); // 插入抢红包信息 int result = userRedPacketDao.grapRedPacket(userRedPacket); return result; } // 失败返回 return FAILED; }
1.使用数据库的悲观锁和乐观锁进行设计
(1)悲观锁
悲观锁是一种利用数据库内部机制提供的锁的方法,也就是对更新的数据加锁,这样在并发期间一旦有一个事务持有了数据库记录的锁,其他的线程将不能再对数据进行更新了。
修改SQL语句,加入“for update”,意味着将持有对数据库记录的行更新锁(因为这里使用主键查询,所以只会对行加锁。如果使用的是非主键查询,要考虑是否对全表加锁的问题,加锁后可能引发其他查询的阻塞),那就意味着在高并发的场景下,当一条事务持有了这个更新锁后才能往下操作,其他的线程如果要更新这条记录都需要等待,这样就不会出现超发现象引发的数据不一致的问题了。
但是,悲观锁会导致系统性能下降。对于悲观锁来说,当一条线程抢占了资源后,其他的线程将得不到资源,那么这个时候,CPU 就会将这些得不到资源的线程挂起,挂起的线程也会消耗 CPU 的资源。由于高并发环境下的频繁挂起线程和恢复线程,导致CPU频繁切换线程上下文,从而使CPU资源得到了极大的消耗,造成了性能不佳的问题。悲观锁也称独占锁。
业务逻辑和不加锁时一致。
<!-- 查询红包具体信息 --> <select id="getRedPacketForUpdate" parameterType="long" resultType="com.ssm.chapter22.pojo.RedPacket"> select id, user_id as userId, amount, send_date as sendDate, total, unit_amount as unitAmount, stock, version, note from T_RED_PACKET where id = #{id} for update </select>
(2)乐观锁
乐观锁是一种不会阻塞其他线程并发的机制,它不会使用数据库的锁进行实现,它的设计里面由于不阻塞其他线程,所以不会引发线程频繁挂起和恢复,这样可以提高并发能力。乐观锁也称为非阻塞锁。乐观锁使用的是CAS原理。
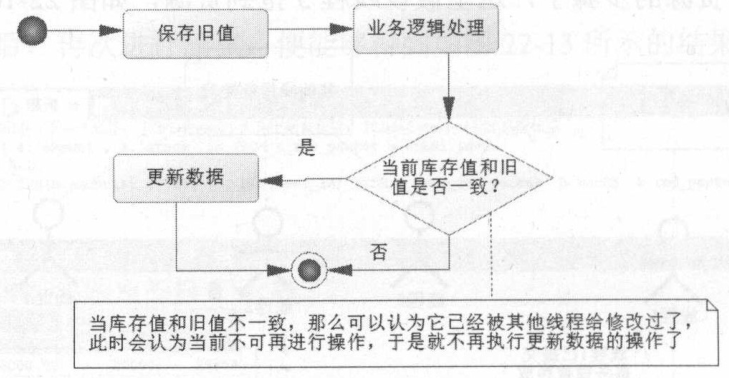
CAS原理并不排斥并发,也不独占资源,只是在线程开始阶段就读入线程共享数据,保存为旧值。当处理完逻辑,需要更新数据的时候,会进行一次比较,即比较各个线程当前共享的数据是否和旧值保持一致,如果一致,就开始更新数据,如果不一致,就认为该数据已经被其他线程修改了,那么就不再更新数据,可以考虑重试或者放弃。有时候可以重试,这样就是一个可重入锁。
CAS原理存在ABA问题,ABA问题是因为业务逻辑存在回退的可能性。如果加入一个非业务逻辑的属性,比如在一个数据中加入版本号,每次修改变量的数据时,强制版本号只能递增,而不会回退,即使是其他业务数据回退,它也会递增,那么就解决了ABA问题。
对于查询来说,没有“for update”语句,避免了锁的发生,就不会造成线程阻塞。然后,增加了对版本号的判断,其次每次扣减都会对版本号加1,这样就可以避免ABA问题了。
<!-- 通过版本号扣减抢红包 每更新一次,版本增1, 其次增加对版本号的判断 --> <update id="decreaseRedPacketForVersion"> update T_RED_PACKET set stock = stock - 1, version = version + 1 where id = #{id} and version = #{version} </update>
在Service中使用乐观锁,无重入的代码:其中,redPacket先获取到了红包的记录,其redPacket.getVersion()表示的就是version版本值,在执行更新数据库方法时,将redPacket.getVersion()传入作为version变量,由于在判断时增加了“and version = #{version}”语句,因此,如果不相等,就不执行update SQL语句,因此update返回值就为0,表明版本号发生了变化。
// 乐观锁,无重入 @Override @Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED) public int grapRedPacketForVersion(Long redPacketId, Long userId) { // 获取红包信息,注意version值 RedPacket redPacket = redPacketDao.getRedPacket(redPacketId); // 当前小红包库存大于0 if (redPacket.getStock() > 0) { // 再次传入线程保存的version旧值给SQL判断,是否有其他线程修改过数据 int update = redPacketDao.decreaseRedPacketForVersion(redPacketId, redPacket.getVersion()); // 如果没有数据更新,则说明其他线程已经修改过数据,本次抢红包失败 if (update == 0) { return FAILED; } // 生成抢红包信息 UserRedPacket userRedPacket = new UserRedPacket(); userRedPacket.setRedPacketId(redPacketId); userRedPacket.setUserId(userId); userRedPacket.setAmount(redPacket.getUnitAmount()); userRedPacket.setNote("抢红包 " + redPacketId); // 插入抢红包信息 int result = userRedPacketDao.grapRedPacket(userRedPacket); return result; } // 失败返回 return FAILED; }
在实际测试的情况下,经过3万次的抢夺,原来的2万个红包中,由于版本号version不一致导致了还有8千多个没有被抢到,也就是说,抢红包失败的记录太大了。
(3)乐观锁重入机制
为了克服这个问题,提高成功率,还会考虑使用锁重入机制。也就是一旦因为版本原因没有抢到红包,则重新尝试抢红包,但是过多的重入会造成大量的SQL执行,有两种方式:
- 按时间戳重入,也就是在一定的时间内(例如:当前时间+100毫秒),不成功的会循环到成功为止,直至超过时间戳,不成功才会退出,返回失败。
- 按次数重入,比如限定3次,如果超过3次尝试后还失败,那么就判定此次失败
按时间戳重入:有时候时间戳并不是那么稳定,也会随着系统的空闲或者繁忙导致重试次数不一。
// 乐观锁,按时间戳重入 @Override @Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED) public int grapRedPacketForVersion(Long redPacketId, Long userId) { // 记录开始时间 long start = System.currentTimeMillis(); // 无线循环,直到成功或者满100毫秒退出 while (true) { // 获取循环当前时间 long end = System.currentTimeMillis(); // 如果超过了100毫秒就结束尝试 if (end - start > 100) { return FAILED; }
... 和乐观锁部分一样
}
按次数重入:限制重试次数,这样就能避免过多的重试导致过多的SQL被执行,从而保证数据库的性能。
// 乐观锁,按重试次数重入 @Override @Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED) public int grapRedPacketForVersion(Long redPacketId, Long userId) { for (int i = 0; i < 3; i++) { // 获取红包信息,主要是version值 RedPacket redPacket = redPacketDao.getRedPacket(redPacketId); // 当前小红包库存大于0 if (redPacket.getStock() > 0) { // 再次传入线程保存的version旧值给SQL判断,是否有其他线程修改过数据 int update = redPacketDao.decreaseRedPacketForVersion(redPacketId, redPacket.getVersion()); // 如果没有数据更新,则说明其他线程已经修改过数据,则重新抢夺 if (update == 0) { continue; }
...
}
2.使用Redis进行设计
数据库最终会将数据保存到磁盘中,而Redis使用的是内存,内存的速度比磁盘速度快得多。
Redis的Lua语言是原子性的,且功能更为强大,因此优先选择Lua语言实现抢红包业务。
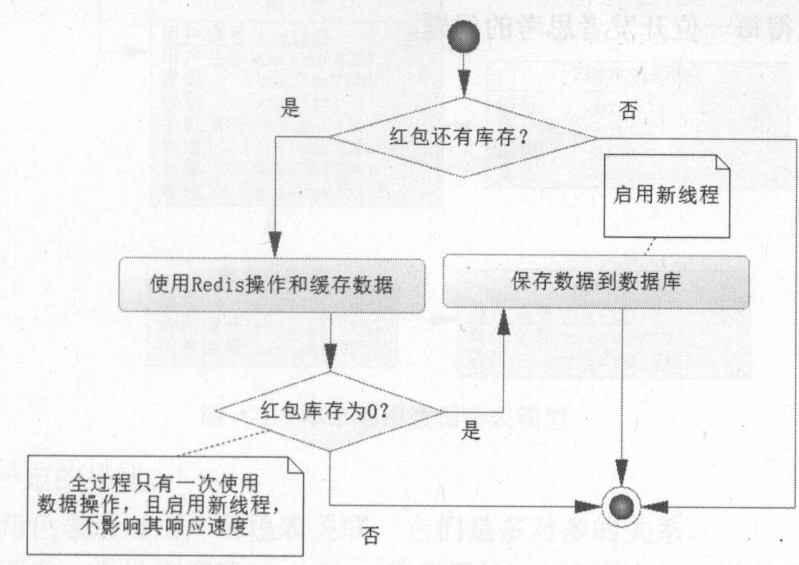
Redis并非是一个长久存储数据的地方,它存储的数据是非严格和安全的环境,更多的时候只是为了提供更为快速的缓存,因此当红包金额为0或者红包超时的时候,将红包数据保存到数据库中,这样才能够保证数据的安全性和严格性。
(0)表设计
使用下面的Redis命令在Redis中初始化了一个编号为5的大红包,其中库存为2万个,每个10元
127.0.0.1:6379> hset red_packet_5 stock 20000 (integer) 1 127.0.0.1:6379> hset red_packet_5 unit_amount 10 (integer) 1
在数据库中通过下面的SQL语句创建用户抢红包信息表:
create table T_USER_RED_PACKET ( id int(12) not null auto_increment, red_packet_id int(12) not null, user_id int(12) not null, amount decimal(16,2) not null, grab_time timestamp not null, note varchar(256) null, primary key clustered (id) );
(1)Lua脚本设计
// Lua脚本 String script = "local listKey = 'red_packet_list_'..KEYS[1] \n" // 被抢红包列表 key + "local redPacket = 'red_packet_'..KEYS[1] \n" // 当前被抢红包 key + "local stock = tonumber(redis.call('hget', redPacket, 'stock')) \n" // 读取当前红包库存 + "if stock <= 0 then return 0 end \n" // 没有库存,返回0 + "stock = stock -1 \n" // 库存减1 + "redis.call('hset', redPacket, 'stock', tostring(stock)) \n" // 保存当前库存 + "redis.call('rpush', listKey, ARGV[1]) \n" // 往Redis链表中加入当前红包信息 + "if stock == 0 then return 2 end \n" // 如果是最后一个红包,则返回2,表示抢红包已经结束,需要将Redis列表中的数据保存到数据库中 + "return 1 \n"; // 如果并非最后一个红包,则返回1,表示抢红包成功。
当返回为2的时候,说明红包已经没有库存,会触发数据库对链表数据的保存,这是一个大数据量的保存,因为有20000条记录。为了不影响最后一次抢红包的响应,在实际的操作中往往会考虑使用 JMS 消息发送到别的服务器进行操作。这里只是创建了一条新的线程去运行保存 Redis 链表数据到数据库的程序。
保存 Redis 抢红包信息到数据库的服务类:
package com.ssm.chapter22.service.impl; ... @Service public class RedisRedPacketServiceImpl implements RedisRedPacketService { private static final String PREFIX = "red_packet_list_"; // 每次取出1000条,避免一次取出消耗太多内存 private static final int TIME_SIZE = 1000; @Autowired private RedisTemplate redisTemplate = null; // RedisTemplate @Autowired private DataSource dataSource = null; // 数据源 @Override // 开启新线程运行 @Async public void saveUserRedPacketByRedis(Long redPacketId, Double unitAmount) { System.err.println("开始保存数据"); Long start = System.currentTimeMillis(); // 获取列表操作对象 BoundListOperations ops = redisTemplate.boundListOps(PREFIX + redPacketId); Long size = ops.size(); Long times = size % TIME_SIZE == 0 ? size / TIME_SIZE : size / TIME_SIZE + 1; int count = 0; List<UserRedPacket> userRedPacketList = new ArrayList<UserRedPacket>(TIME_SIZE); for (int i = 0; i < times; i++) { // 获取至多TIME_SIZE个抢红包信息 List userIdList = null; if (i == 0) { userIdList = ops.range(i * TIME_SIZE, (i + 1) * TIME_SIZE); } else { userIdList = ops.range(i * TIME_SIZE + 1, (i + 1) * TIME_SIZE); } userRedPacketList.clear(); // 保存红包信息 for (int j = 0; j < userIdList.size(); j++) { String args = userIdList.get(j).toString(); String[] arr = args.split("-"); String userIdStr = arr[0]; String timeStr = arr[1]; Long userId = Long.parseLong(userIdStr); Long time = Long.parseLong(timeStr); // 生成抢红包信息 UserRedPacket userRedPacket = new UserRedPacket(); userRedPacket.setRedPacketId(redPacketId); userRedPacket.setUserId(userId); userRedPacket.setAmount(unitAmount); userRedPacket.setGrabTime(new Timestamp(time)); userRedPacket.setNote("抢红包 " + redPacketId); userRedPacketList.add(userRedPacket); } // 插入抢红包信息 count += executeBatch(userRedPacketList); } // 删除Redis列表 redisTemplate.delete(PREFIX + redPacketId); Long end = System.currentTimeMillis(); System.err.println("保存数据结束,耗时" + (end - start) + "毫秒,共" + count + "条记录被保存。"); } /** * 使用JDBC批量处理Redis缓存数据. * * @param userRedPacketList 抢红包列表 * @return 抢红包插入数量. */ private int executeBatch(List<UserRedPacket> userRedPacketList) { Connection conn = null; Statement stmt = null; int[] count = null; try { conn = dataSource.getConnection(); conn.setAutoCommit(false); stmt = conn.createStatement(); for (UserRedPacket userRedPacket : userRedPacketList) { String sql1 = "update T_RED_PACKET set stock = stock-1 where id=" + userRedPacket.getRedPacketId(); DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String sql2 = "insert into T_USER_RED_PACKET(red_packet_id, user_id, " + "amount, grab_time, note)" + " values (" + userRedPacket.getRedPacketId() + ", " + userRedPacket.getUserId() + ", " + userRedPacket.getAmount() + "," + "'" + df.format(userRedPacket.getGrabTime()) + "'," + "'" + userRedPacket.getNote() + "')"; stmt.addBatch(sql1); stmt.addBatch(sql2); } // 执行批量 count = stmt.executeBatch(); // 提交事务 conn.commit(); } catch (SQLException e) { /********* 错误处理逻辑 ********/ throw new RuntimeException("抢红包批量执行程序错误"); } finally { try { if (conn != null && !conn.isClosed()) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } // 返回插入抢红包数据记录 return count.length / 2; } }
这里的@Async注解表示让Spring自动创建另外一条线程去运行它,这样它便不在抢最后一个红包的线程之内,因为这个方法是一个较长时间的方法,如果在同一个线程内,那么对于最后抢红包的用户来说就需要等待相当长的时间,影响用户体验。
为了使用@Async注解,还需要在 Spring 中配置一个任务池:
package com.ssm.chapter22.config; ... @EnableAsync public class WebConfig extends AsyncConfigurerSupport { ... @Override public Executor getAsyncExecutor() { ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor(); taskExecutor.setCorePoolSize(5); taskExecutor.setMaxPoolSize(10); taskExecutor.setQueueCapacity(200); taskExecutor.initialize(); return taskExecutor; } }
用户抢红包逻辑:grapRedPacketByRedis接收的参数,第一个是大红包名称“red_packet_5”中的5,而userId是jsp文件中发起抢红包请求的唯一标识[0,30000]中的某一个i值。
当[0,30000]中的某一个值i发起请求后,假设 i 为 1000
- jsp中直接异步post到url: "./userRedPacket/grapRedPacketByRedis.do?redPacketId=8&userId=" + i,然后调用grapRedPacketByRedis(Long redPacketId, Long userId)方法,其中redPacketId=5,而userId=1000。
- 然后通过Object res = jedis.evalsha(sha1, 1, redPacketId + "", args);执行自定义的Lua脚本,其中,1表示key的个数,args表示grapRedPacketByRedis方法的两个参数值。定义用户抢红包信息在Redis中的键listKey=red_packet_list_5,大红包在Redis中的键red_packet_5,然后查询red_packet_5中的stock,返回还剩红包的数量stock,此时假设stock=7777,则由于还有红包,于是将stock变为7776,并更新到red_packet_5的stock中,然后将键值对red_packet_list_5-ARGV[1](也就是userId),即red_packet_list_5 - 1000写入Redis中。
- 当返回结果为 2 时,说明最后一个红包已经被抢了,这个时候,jedis.hget("red_packet_" + redPacketId, "unit_amount");得到red_packet_5 → unit_amount 即单个小红包的金额10赋给变量unitAmount,然后saveUserRedPacketByRedis(redPacketId, unitAmount);方法将Redis中键red_packet_list的信息加上每个小红包金额信息,以及其他各种信息对应成用户抢红包数据库表定义,另开一个线程,将20000个数据库记录添加到数据库中保存起来。
@Autowired private RedisTemplate redisTemplate = null; @Autowired private RedisRedPacketService redisRedPacketService = null; // Lua脚本 String script = "local listKey = 'red_packet_list_'..KEYS[1] \n" + "local redPacket = 'red_packet_'..KEYS[1] \n" + "local stock = tonumber(redis.call('hget', redPacket, 'stock')) \n" + "if stock <= 0 then return 0 end \n" + "stock = stock -1 \n" + "redis.call('hset', redPacket, 'stock', tostring(stock)) \n" + "redis.call('rpush', listKey, ARGV[1]) \n" + "if stock == 0 then return 2 end \n" + "return 1 \n"; // 在缓存LUA脚本后,使用该变量保存Redis返回的32位的SHA1编码,使用它去执行缓存的LUA脚本[加入这句话] String sha1 = null; @Override public Long grapRedPacketByRedis(Long redPacketId, Long userId) { // 当前抢红包用户和日期信息 String args = userId + "-" + System.currentTimeMillis(); Long result = null; // 获取底层Redis操作对象 Jedis jedis = (Jedis) redisTemplate.getConnectionFactory().getConnection().getNativeConnection(); try { // 如果脚本没有加载过,那么进行加载,这样就会返回一个sha1编码 if (sha1 == null) { sha1 = jedis.scriptLoad(script); } // 执行脚本,返回结果 Object res = jedis.evalsha(sha1, 1, redPacketId + "", args); result = (Long) res; // 返回2时为最后一个红包,此时将抢红包信息通过异步保存到数据库中 if (result == 2) { // 获取单个小红包金额 String unitAmountStr = jedis.hget("red_packet_" + redPacketId, "unit_amount"); // 触发保存数据库操作 Double unitAmount = Double.parseDouble(unitAmountStr); System.err.println("thread_name = " + Thread.currentThread().getName()); redisRedPacketService.saveUserRedPacketByRedis(redPacketId, unitAmount); } } finally { // 确保jedis顺利关闭 if (jedis != null && jedis.isConnected()) { jedis.close(); } } return result; }
控制器方法:
@RequestMapping(value = "/grapRedPacketByRedis") @ResponseBody public Map<String, Object> grapRedPacketByRedis(Long redPacketId, Long userId) { Map<String, Object> resultMap = new HashMap<String, Object>(); Long result = userRedPacketService.grapRedPacketByRedis(redPacketId, userId); boolean flag = result > 0; resultMap.put("result", flag); resultMap.put("message", flag ? "抢红包成功": "抢红包失败"); return resultMap; }
模拟高并发的jsp文件,其中,由于post是异步请求,所以可以模拟多个用户同时请求的情况:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>参数</title> <!-- 加载Query文件--> <script type="text/javascript" src="https://code.jquery.com/jquery-3.2.0.js"> </script> <script type="text/javascript"> $(document).ready(function () { //模拟30000个异步请求,进行并发 var max = 30000; for (var i = 1; i <= max; i++) { //jQuery的post请求,请注意这是异步请求 $.post({ //请求抢id为1的红包 //根据自己请求修改对应的url和大红包编号 url: "./userRedPacket/grapRedPacketByRedis.do?redPacketId=8&userId=" + i, //成功后的方法 success: function (result) { } }); } }); </script> </head> <body> </body> </html>
最后结果,在3万用户同时争抢2万个红包的场景下,Redis 只需要4秒,乐观锁需要33秒,而悲观锁需要54秒,可见Redis是多么的高效。
使用Redis的风险在于Redis的不稳定性,因为其事务和存储都存在不稳定的因素,所以更多的时候,应该使用独立的Redis服务器做高并发业务,一方面可以提高Redis的性能,另一个方面即使在高并发的场合,Redis服务器宕机也不会影响现有的其他业务,同时也可以使用备机等设备提高系统的高可用,保证网络的安全稳定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号