Redis(十四)Redis 在Java Web 中的应用
在传统的 Java Web 项目中,使用数据库进行存储数据,但是有一些致命的弊端,这些弊端主要来自于性能方面。
由于数据库持久化数据主要是面向磁盘,而磁盘的读/写比较慢,在一般管理系统中,由于不存在高并发,因此往往没有瞬间需要读/写大量数据的要求,这个时候使用数据库进行读/写时没有太大的问题的,但是在互联网中,往往存在大数据量的需求,比如,需要在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,导致服务宕机的严重生产问题。
为了克服这些问题,Java Web 项目往往就引入了 NoSQL 技术,NoSQL 工具也是一种简易的数据库,它主要是一种基于内存的数据库,并提供了一定的持久化功能。比如Redis和MongoDB。
Redis 的性能十分优越,可以支持每秒十几万次的读/写操作,其性能远超数据库,并且支持集群、分布式、主从同步等配置,原则上可以无限扩展,同时还支持一定的事务能力。
Redis 性能优越主要来自于3个方面:
- 基于ANSI C 语言编写,接近于汇编语言的机器语言,运行十分快速
- 基于内存的读/写。
- 数据库结构只有6种数据类型,数据结构比较简单,因此规则较少,而数据库则是范式,完整性、规范性需要考虑的规则比较多,处理业务会比较复杂。\
NoSQL为什么不能代替数据库:
- NoSQL 的数据主要存储在内存中,而数据库主要是磁盘。
- NoSQL 数据库结构比较简单,虽然能处理很多的问题,但是其功能毕竟有限,不如数据库的SQL语句强大,支持更为复杂的计算
- NoSQL 并不完全安全稳定,由于它基于内存,一旦停电或者机器故障数据就很容易丢失,其持久化能力也是有限的,而基于磁盘的数据库则不胡出现这样的问题
- NoSQL 其数据完整性、事务能力、安全性、可靠性以及可扩展性都远不及数据库。
一、Redis 在 Java Web 中的应用
一般而言 Redis 在 Java Web 应用中存在两个主要的场景:一个是缓存常用的数据,另一个是在需要高速读/写的场合使用它快速读写。
1.缓存
在对数据库的读/写操作中,读操作远超写操作,一般是9:1到7:3的比例,所以需要读的可能性比写的可能性多得多。
当发送SQL去数据进行读取时,数据库就会去磁盘把对应的数据索引回来,而索引磁盘是一个相对缓慢的过程。如果把数据直接放在运行在内存中的Redis服务器上,那么就不需要去读/写磁盘了,而是直接读取内存,显然速度会快得多,而且会极大减轻数据库的压力。
而使用内存进行存储数据开销也是比较大的,应该考虑在Redis中存储哪些数据,需要从3个方面进行考虑:
- 业务数据常用与否以及命中率大小。如果命中率很低,就没有必要写入缓存。
- 该业务数据是读操作多,还是写操作多,如果写操作多,频繁需要写入数据库,也没有必要使用缓存
- 如果要存储几百兆字节的文件,会给缓存带来很大的压力,没有必要。
(1)读操作流程
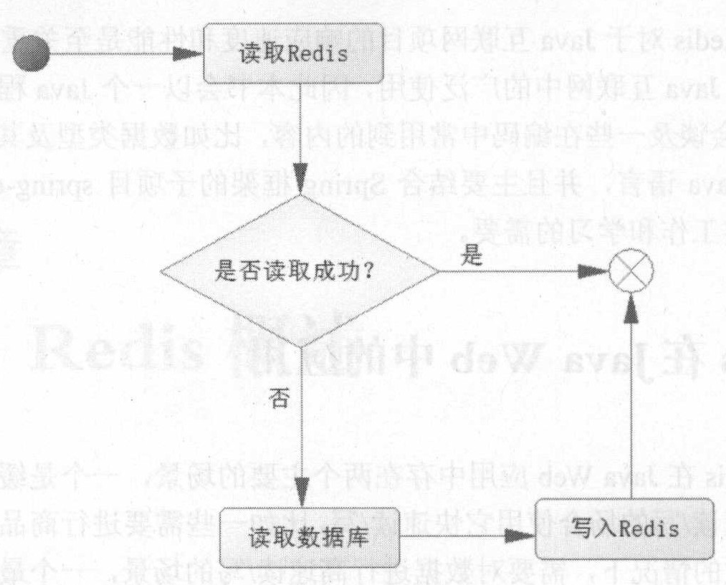
- 当第一次读取数据的时候,读取Redis的数据就会失败,此时会触发程序读取数据库,把数据读取出来,并且写入Redis
- 当第二次以及以后读取数据时,就直接读取Redis,读到数据后就结束了流程,这样速度就大大提高了。
(2)写操作流程
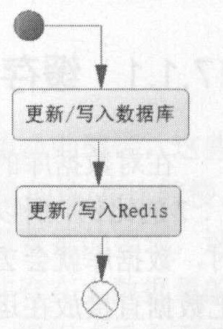
如果业务数据写操作次数远远大于读操作次数,那么没有必要使用 Redis。
2.高速读/写场合
高速读/写场合例如:秒杀商品、抢红包、抢票等。这类场合在一瞬间成千上万的请求就会达到服务器,如果使用的数据库,很容易造成数据库瘫痪。
解决办法是异步写入数据库,即在高速读/写的场合单单使用 Redis 去应对,把这些需要高速读/写的数据缓存到 Redis 中,而在满足一定的条件下,触发这些缓存的数据写入数据库中。
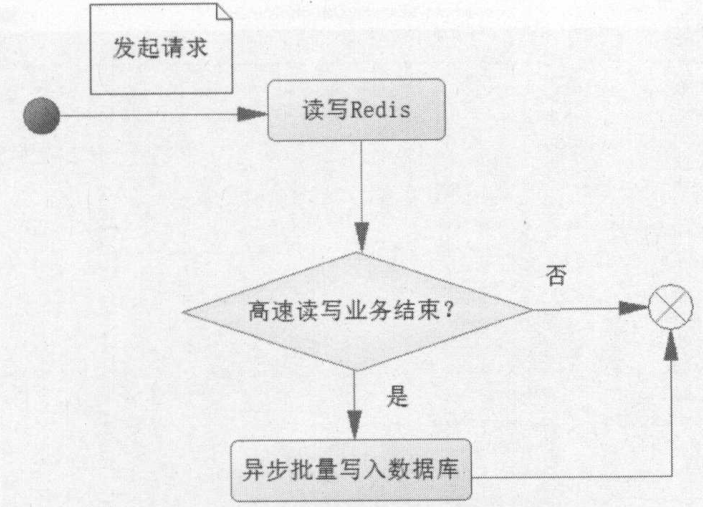
当一个请求到达服务器,只是把业务数据先在 Redis 读/写,而没有进行任何对数据库的操作。
由于一般缓存不能持久化,或者所持久化的数据不太规范,因此需要把这些业务数据存入数据库,所以在一个请求操作完 Redis 的读/写后,会去判断该高速读/写业务是否结束,这个判断的条件往往就是秒杀商品剩余个数为0,抢红包金额为0,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 缓存的数据以批量的形式一次性写入数据库,从而完成持久化操作。
二、在 Java 中使用 Redis
1.下载 jedis.jar、spring-data.redis.jar 和 commons-pool2-2.5.0.jar
2.在 Java 中使用 Redis,一般采用连接池方式获取连接


package com.ssm.chapter17.jedis; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class JedisTest { public void testJedis() { // 从连接池中获取Redis连接 Jedis jedis = testPool().getResource(); int i = 0;// 记录操作次数 try { long start = System.currentTimeMillis();// 开始毫秒数 while (true) { long end = System.currentTimeMillis(); if (end - start >= 1000) {// 当操作1秒时,结束操作 break; } i++; jedis.set("test" + i, i + ""); } } finally {// jedis.close(); } System.out.println("redis 每秒操作: " + i + "次");// 打印1秒内对 Redis 的操作次数 } private JedisPool testPool() { JedisPoolConfig poolCfg = new JedisPoolConfig(); // 设置最大空闲数 poolCfg.setMaxIdle(50); // 设置最大连接数 poolCfg.setMaxTotal(100); // 设置最大等待毫秒数 poolCfg.setMaxWaitMillis(20000); // 使用配置创建连接池 JedisPool pool = new JedisPool(poolCfg, "localhost"); return pool; } public static void main(String[] args) { new JedisTest().testJedis(); } }
3.在 Spring 中使用Redis
(1)先用 Spring 配置一个 JedisPoolConfig 对象
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!--最大空闲数 --> <property name="maxIdle" value="50" /> <!--最大连接数 --> <property name="maxTotal" value="100" /> <!--最大等待时间 --> <property name="maxWaitMillis" value="20000" /> </bean>
(2)在使用 Spring 提供的RedisTemplate之前需要配置Spring所提供的连接工厂,在 Spring Data Redis 方案中有4种工厂模型:选择其中的一种,JedisConnectionFactory
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory"> <property name="hostName" value="localhost" /> <property name="port" value="6379" /> <property name="poolConfig" ref="poolConfig" /> </bean>
(3)普通的连接使用没有办法把 Java 对象直接存入 Redis,可以使用 Spring 内部提供的 RedisSerializer 接口和一些实现类实现序列化和反序列化。
JdkSerializationRedisSerializer是使用 JDK 的序列化器进行转换,而StringRedisSerializer使用字符串进行序列化
<bean id="jdkSerializationRedisSerializer" class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" /> <bean id="stringRedisSerializer" class="org.springframework.data.redis.serializer.StringRedisSerializer" />
(4)由于需要配置key和value两个不同的序列化方式,那么可以指定各自使用的序列化器。至此,就可以得到一个Spring提供的RedisTemplate来进行操作Redis
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate"> <property name="connectionFactory" ref="connectionFactory" /> <property name="keySerializer" ref="stringRedisSerializer" /> <property name="valueSerializer" ref="jdkSerializationRedisSerializer" /> </bean>
(5)创建POJO类,必须实现Serializable接口
package com.ssm.chapter17.pojo; import java.io.Serializable; public class Role implements Serializable { private static final long serialVersionUID = 6977402643848374753L; private long id; private String roleName; private String note; /*****************************getter and setter**************************************/ }
(6)使用RedisTemplate操作Redis
private static void testSpring() { ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml"); RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class); Role role = new Role(); role.setId(1L); role.setRoleName("role_name_1"); role.setNote("note_1"); redisTemplate.opsForValue().set("role_1", role); Role role1 = (Role) redisTemplate.opsForValue().get("role_1"); System.out.println(role1.getRoleName()); }
然而,这样的方式可能存在问题:执行set和get方法的Redis连接对象可能来自同一个Redis连接池的不同Redis的连接。为了使得set和get操作都来自同一个连接,可以使用SessionCallback
(7)使用SessionCallback来将多个命令放入到同一个 Redis 连接中执行
这里使用匿名类的方式,还可以使用 Lambda 的方式进行编写SessionCallback的业务逻辑。
由于前后使用的都是同一个连接,因此对于资源损耗就比较小,在使用Redis操作多个命令或者使用事务的时候也会用到它。
private static void testSessionCallback() { ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml"); RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class); Role role = new Role(); role.setId(1); role.setRoleName("role_name_1"); role.setNote("role_note_1"); SessionCallback callBack = new SessionCallback<Role>() { @Override public Role execute(RedisOperations ops) throws DataAccessException { ops.boundValueOps("role_1").set(role); return (Role) ops.boundValueOps("role_1").get(); } }; Role savedRole = (Role) redisTemplate.execute(callBack); System.out.println(savedRole.getId()); }
例如,简化成Lambda表达式为:
private static void testSessionCallback() { ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml"); RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class); Role role = new Role(); role.setId(1); role.setRoleName("role_name_1"); role.setNote("role_note_1"); Role savedRole = (Role) redisTemplate.execute((RedisOperations ops) -> { ops.boundValueOps("role_4").set(role); return (Role) ops.boundValueOps("role_4").get(); }); System.out.println(savedRole.getId()); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号