数据结构(二十七)Huffman树和Huffman编码
Huffman树是一种在编码技术方面得到广泛应用的二叉树,它也是一种最优二叉树。
一、霍夫曼树的基本概念
1.结点的路径和结点的路径长度:结点间的路径是指从一个结点到另一个结点所经历的结点和分支序列。结点的路径长度是指从根结点到该结点间的路径上的分支数目。
2.结点的权和结点的带权路径长度:结点的权是指结点被赋予一个具有某种实际意义的数值。结点的带权路径长度是该结点的路径长度与结点的权值的乘积。
3.树的长度和树的带权路径长度:树的长度就是从根结点到每一结点的路径长度之和。树的带权路径长度就是所有叶结点的带权路径长度之和。
4.最优二叉树:带权路径长度WPL最小的二叉树称为霍夫曼树(Huffman Tree)或最优二叉树。
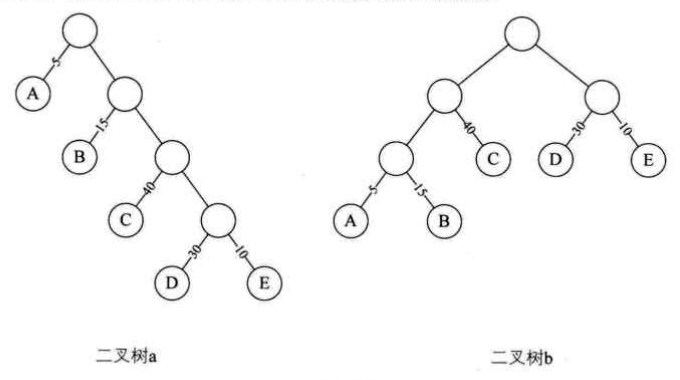
二叉树a的WPL = 5 x 1 + 15 x 2 + 40 x 3 + 30 x 4 + 10 x 5 = 315
二叉树b的WPL = 5 x 3 + 15 x 3 + 40 x 2 + 30 x 2 + 10 x 2 = 220
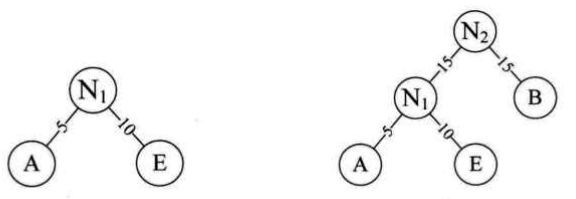
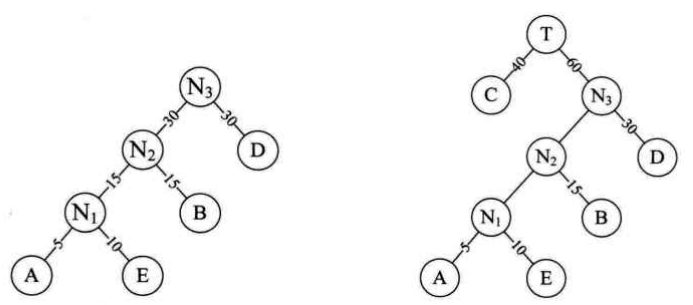
二、霍夫曼树的构造方法
- 由给定的n个权值{w1,w2,... ,wn}构成由n棵二叉树所构成的森林F={T1,T2,...,Tn},其中每棵二叉树只有一个根结点,并且根结点的权值对应于w1,w2,...,wn
- 在F中选取根结点的权值最小的两棵树,分别把它们作为左子树和右子树去构造一棵新的二叉树,新的二叉树的各结点的权值为左、右子树的权值之和
- 在F中删除上一步中选中的两棵树,并把新产生的二叉树加入到F中
- 重复第2步和第3步,直到F只含一棵树为止,这棵树就是霍夫曼树。
三、霍夫曼编码
霍夫曼树更大的目的是解决了当年远距离通信(电报)的数据传输的最优化问题。
霍夫曼编码的定义:设需要编码的字符集为(d1,d2,...,dn)各个字符在电文中出现的次数或者频率集合为{w1,w2,...,wn},以d1,d2,...,dn为叶子结点,w1,w2,...,wn作为相应叶子结点的权值来构造一棵霍夫曼树。规定霍夫曼树的左分支代表0,右分支代表1,则从根结点到叶子结点所经过的路径分支组成的0和1序列边为该结点对应字符的编码,这就是霍夫曼编码。
假设六个字母的频率为A 27,B 8,C 15, D 15, E 30, F 5,则对应的霍夫曼编码为:A 01, B 1001,C 101,D 00,E 11,F 1000
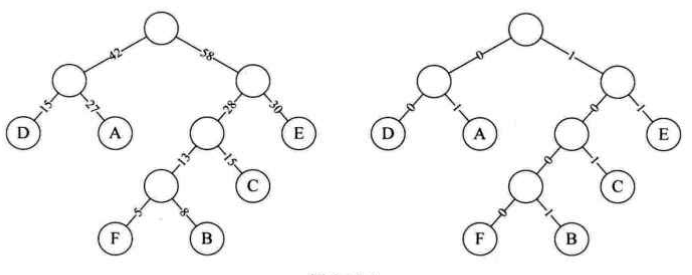
设计非等长码的时候,必须是任一字符的编码都不是另一个字符的编码的前缀,这种编码称为前缀编码。
四、构造霍夫曼树和霍夫曼编码的实现思路:
(1)算法思路
考虑到,在进行霍夫曼译码时,要求能方便地实现从双亲结点到左、右孩子结点的操作;而在霍夫曼编码时,又要求能够方便地从孩子结点到双亲结点的操作,因此,需要将霍夫曼树的结点存储结构设计为三叉链式(二叉链表结点结构加上双亲parent域(数据域data是weight权值域))存储结构。此外,每一个结点还要设置权值域。为了判断一个结点是否已经加入到霍夫曼树中,每个结点还需要设置一个标志域flag,当flag为0时,表示该结点尚未加入到霍夫曼树中;反之,表示该结点已经加入到霍夫曼树中。
综上,霍夫曼树的结点存储结构为:weight flag parent rchild lchild
(2)其中,最为关键的就是从结点当中选择两个权重最小和权重第二小的结点,算法如下:
// 在霍夫曼树结点数组的[0],[1]...[end]中选择不在霍夫曼树中且weight最小的两个结点 private HuffmanNode[] selectMinWeight(HuffmanNode[] HN, int end) { HuffmanNode[] min = {new HuffmanNode(100),new HuffmanNode(100)}; for (int i = 0; i <= end; i++) { HuffmanNode h = HN[i]; if (h.flag == 0 && h.weight < min[0].weight) { min[1] = min[0]; min[0] = h; } else if (h.weight < min[1].weight && h.flag == 0) { min[1] = h; } } return min; }
其中,flag==1说明该结点已经被选入到霍夫曼树当中了。
分析一下上述算法,为了从结点数组HN当中的下标为[0]...[end]选择权值最小的两个结点。首先建立了一个结点数组用来存储权值最小的两个结点,这两个结点的初始权值设为最大值100,是为了便于比较,然后min[0]作为权重最小的结点,而min[1]最为权重第二小的结点,算法思路是这样的:从数组下标为0开始:
- 如果新结点的权值小于min[0]的权值,那么将新结点赋值给min[0],并将之前最小的min[0]赋值给之前第二小的min[1]。
- 如果新结点的权值大于min[0]的权值而小于min[1]的权值,那么最小权值结点还是min[0],而将第二小的min[1]赋值为新结点。
(3)同时还需要注意的是,在霍夫曼树中求叶结点的霍夫曼编码,实际就是从叶结点到根结点的路径分支的逐个遍历,没经过一个分支就得到一位霍夫曼编码值。因此,霍夫曼编码需要保存在一个整型数组中,并且由于求每一个字符的霍夫曼编码是从叶结点到根结点的一个逆向处理过程,所以对获取到的霍夫曼编码,应该按位从数组的结尾位置开始进行存放。又由于是不等长的编码,所以还需要设置一个标识来表示每个霍夫曼编码在数组中的起始位置。
以六个字母的频率为A 27,B 8,C 15, D 15, E 30, F 5,则对应的霍夫曼编码为:A 01, B 1001,C 101,D 00,E 11,F 1000,为例
其霍夫曼编码在数组中的存储形式应该是:
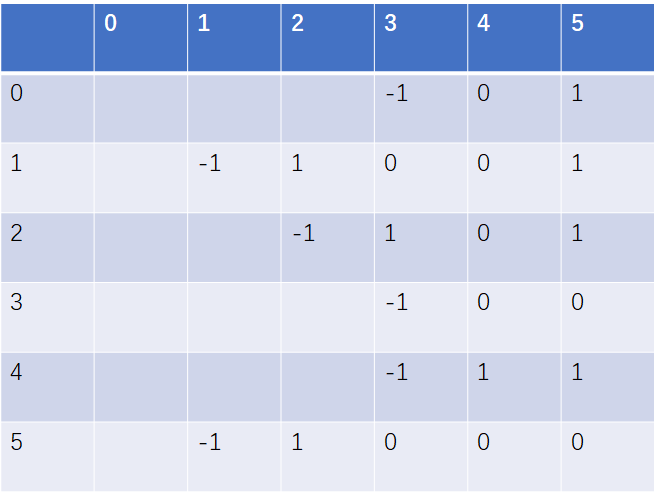
代码实现为(遍历的时候是从叶结点到根结点,而读序列的时候是从根结点到叶结点):
int[][] Huffcode = new int[n][n]; // 建立霍夫曼编码二维数组 for (int j = 0; j < n; j++) { // 一共n个结点 int start = n - 1; // 编码开始的位置,初始化为数组的结尾 // for (HuffmanNode c = HN[j], p = c.parent ; p != null ; c = p, p = p.parent) { if (p.lchild.equals(c)) { Huffcode[j][start--] = 0; // 左孩子编码为0 } else { Huffcode[j][start--] = 1; // 右孩子编码为1 } } Huffcode[j][start] = -1; // 编码的开始标识为-1,即从-1开始后面才是编码序列 } return Huffcode;
五、构造霍夫曼树和霍夫曼编码的Java语言实现
- 霍夫曼结点类:
package bigjun.iplab.huffmanTree; /** * Huffman Tree的结点存储结构 */ public class HuffmanNode { public int weight; // 结点权值 public short flag; // 结点是否加入到霍夫曼树的标识 public HuffmanNode parent, lchild, rchild; // 结点的双亲、左孩子和右孩子 public HuffmanNode() { // 构造一个空结点 this(0); } public HuffmanNode(int weight) { // 构造一个非空结点 this.weight = weight; flag = 0; parent = lchild = rchild = null; } }
- 霍夫曼树及霍夫曼编码实现类:
package bigjun.iplab.huffmanTree; public class HuffmanTree { public int[][] huffmanCoding(int[] W){ int n = W.length; // 权重数组的长度 int m = 2 * n - 1; // 霍夫曼树结点的总个数 HuffmanNode[] HN = new HuffmanNode[m]; // 霍夫曼树的结点数组 int i; // 霍夫曼树的结点数组的下标 for (i = 0; i < n; i++) { // 构造n个具有给定权值的结点,放在结点数组的前n个位置 HN[i] = new HuffmanNode(W[i]); } for (i = n; i < m; i++) { // 从数组下标n开始,存放其他的结点 HuffmanNode[] minNode = selectMinWeight(HN, i - 1); // 从结点数组中的[0],[1]...[i-1]中选择权值最小的一个 HuffmanNode min1 = minNode[0]; // 选出数组结点中权值最小的结点 HuffmanNode min2 = minNode[1]; // 选出数组结点中权值第二小的结点 min1.flag = 1; // 标记已经被选中到结点数组中 min2.flag = 1; HN[i] = new HuffmanNode(); // 新建霍夫曼结点,放在数组下标为i的位置 min1.parent = HN[i]; // 权值最小结点和第二小结点的双亲为新结点 min2.parent = HN[i]; HN[i].lchild = min1; // 新结点的左、右孩子为权值最小的两个结点 HN[i].rchild = min2; HN[i].weight = min1.weight + min2.weight;// 新结点的权重就是两个孩子的权值之和 } int[][] Huffcode = new int[n][n]; // 建立霍夫曼编码二维数组 for (int j = 0; j < n; j++) { // 一共n个结点 int start = n - 1; // 编码开始的位置,初始化为数组的结尾 // for (HuffmanNode c = HN[j], p = c.parent ; p != null ; c = p, p = p.parent) { if (p.lchild.equals(c)) { Huffcode[j][start--] = 0; // 左孩子编码为0 } else { Huffcode[j][start--] = 1; // 右孩子编码为1 } } Huffcode[j][start] = -1; // 编码的开始标识为-1,即从-1开始后面才是编码序列 } return Huffcode; } // 在霍夫曼树结点数组的[0],[1]...[end]中选择不在霍夫曼树中且weight最小的两个结点 private HuffmanNode[] selectMinWeight(HuffmanNode[] HN, int end) { HuffmanNode[] min = {new HuffmanNode(100),new HuffmanNode(100)}; for (int i = 0; i <= end; i++) { HuffmanNode h = HN[i]; if (h.flag == 0 && h.weight < min[0].weight) { min[1] = min[0]; min[0] = h; } else if (h.weight < min[1].weight && h.flag == 0) { min[1] = h; } } return min; } public static void main(String[] args) { int[] W = {27, 8, 15, 15, 30, 5}; HuffmanTree hTree = new HuffmanTree(); int[][] HN = hTree.huffmanCoding(W); for (int i = 0; i < HN.length; i++) { System.out.print(W[i] + "的霍夫曼编码为 "); for (int j = 0; j < HN[i].length; j++) { if (HN[i][j] == -1) { for (int k = j + 1; k < HN[i].length; k++) { System.out.print(HN[i][k]); } break; } } System.out.println(); } } }
- 输出:
27的霍夫曼编码为 01 8的霍夫曼编码为 1001 15的霍夫曼编码为 101 15的霍夫曼编码为 00 30的霍夫曼编码为 11 5的霍夫曼编码为 1000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号