Redis(三)Redis附加功能
一、慢查询分析
许多存储系统(例如MySql)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。
所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阈值,就将这条命令的相关信息(例如:发生时间、耗时、命令的详细信息)记录下来,Redis也提供了类似的功能。
Redis客户端执行一条命令分为如下4个部分:

慢查询只统计3.执行命令的时间,所以没有慢查询并不代表客户端没有超时问题。
1.慢查询的两个配置参数
对于慢查询需要明确两件事:预设阈值怎么设置?慢查询记录存放在哪里?
(1)slowlog-log-slower-than默认值是10 000微妙,如果执行一条“很慢”的命令(例如keys *),执行时间超过了10 000微妙,那么它将被记录在慢查询日志中。
(2)slowlog-max-len说明慢查询日志列表最多存储多少条
- 获取慢查询日志:slowlog get [n]
- 获取慢查询日志列表当前的长度:slowlog len
- 慢查询日志重置:slowlog reset
2.实际使用中要注意的问题
- slowlog-max-len配置建议:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
- slowlog-log-slower-than配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒。
- 慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
- 由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行slow get命令将慢查询日志持久化到其他存储中(例如MySQL),然后可以制作可视化界面进行查询。
二、Redis Shell
1.redis-cli详解
- -r:将命令执行多次
- -i:每隔几秒执行一次命令
- -x:从标准输入读取数据作为redis-cli的最后一个参数
- -c:连接Redis节点时使用
- -a:使用-a(auth)可以不用手动输入auth命令
- --scan和--pattern用于扫描指定模式的键
- --slave:把当前客户端模拟成当前Redis节点的从节点,可以用来获取当前Redis节点的更新操作。
- --rdb:请求Redis实例生成并发送RDB持久化文件,保存在本地。
- --pipe:将命令封装成Redis通信协议定义的数据格式,批量发送给Redis执行
- --bigkeys:使用scan命令对Redis的键进行采样,从中找到内存占用比较大的键值,这些键可能是系统的瓶颈。
- --eval:执行指定Lua脚本
- --latency:监测网络监测
- --stat:实时获取Redis的重要统计信息。
- --raw返回格式化后的结果,--no-raw返回结果必须是原始的格式
root@myubuntu:/home/workspace/JedisTest# redis-cli -r 3 ping PONG PONG PONG root@myubuntu:/home/workspace/JedisTest# redis-cli -r 5 -i 1 ping PONG PONG PONG PONG PONG root@myubuntu:/home/workspace/JedisTest# redis-cli -r 5 -i 1 info | grep used_memory_human used_memory_human:849.04K used_memory_human:849.04K used_memory_human:849.04K used_memory_human:849.04K used_memory_human:849.04K root@myubuntu:/home/workspace/JedisTest# echo "world" | redis-cli -x set hello OK root@myubuntu:/home/workspace/JedisTest# redis-cli get hello "world\n" root@myubuntu:/home/workspace/JedisTest# redis-cli --stat ------- data ------ --------------------- load -------------------- - child - keys mem clients blocked requests connections 2 849.10K 2 0 39 (+0) 14 2 849.10K 2 0 40 (+1) 14 2 849.10K 2 0 41 (+1) 14 2 849.10K 2 0 42 (+1) 14 2 849.10K 2 0 43 (+1) 14 2 849.10K 2 0 44 (+1) 14 2 849.10K 2 0 45 (+1) 14 2 849.10K 2 0 46 (+1) 14 2 849.10K 2 0 47 (+1) 14 2 849.10K 2 0 48 (+1) 14 ^C root@myubuntu:/home/workspace/JedisTest# redis-cli set command 命令 OK root@myubuntu:/home/workspace/JedisTest# redis-cli get command "\xe5\x91\xbd\xe4\xbb\xa4" root@myubuntu:/home/workspace/JedisTest# redis-cli --raw get command 命令 root@myubuntu:/home/workspace/JedisTest# redis-cli --no-raw get command "\xe5\x91\xbd\xe4\xbb\xa4"
2.redis-server详解
- redis-server --test-memory 1024:监测当前操作系统能否提供1G的内存给Redis
3.redis-benchmark详解
redis-benchmark可以为Redis做基准性能测试。
- -c:客户端的并发数量(默认是50)
- -n:客户端请求总量
root@myubuntu:/home/workspace/JedisTest# redis-benchmark -c 100 -n 20000 ====== PING_INLINE ====== 20000 requests completed in 0.42 seconds 100 parallel clients 3 bytes payload keep alive: 1 49.93% <= 1 milliseconds 92.40% <= 2 milliseconds 99.37% <= 3 milliseconds 100.00% <= 3 milliseconds 48076.92 requests per second ====== PING_BULK ====== 20000 requests completed in 0.43 seconds 100 parallel clients 3 bytes payload keep alive: 1 48.41% <= 1 milliseconds 93.08% <= 2 milliseconds 99.64% <= 3 milliseconds 100.00% <= 3 milliseconds 46620.05 requests per second ====== SET ====== 20000 requests completed in 0.41 seconds 100 parallel clients 3 bytes payload keep alive: 1 52.05% <= 1 milliseconds 92.39% <= 2 milliseconds 98.94% <= 3 milliseconds 99.26% <= 4 milliseconds 99.32% <= 5 milliseconds 99.46% <= 6 milliseconds 99.54% <= 7 milliseconds 99.68% <= 8 milliseconds 99.94% <= 9 milliseconds 100.00% <= 9 milliseconds 48426.15 requests per second ====== GET ====== 20000 requests completed in 0.41 seconds 100 parallel clients 3 bytes payload keep alive: 1 50.38% <= 1 milliseconds 93.24% <= 2 milliseconds 99.67% <= 3 milliseconds 99.91% <= 4 milliseconds 100.00% <= 4 milliseconds 48543.69 requests per second
...
redis-benchmark -c 100 -n 20000代表100个客户端同时请求Redis,一共执行20000次。测试结果以get命令为例:
在0.41秒一共执行了20000次get操作,每个请求数据量是3个字节,50.38%的命令执行时间小于1毫秒,Redis每秒可以处理48543.69次get请求。
- -q:仅显示redis-benchmark的每秒可以处理多少次请求信息:
root@myubuntu:/home/workspace/JedisTest# redis-benchmark -c 100 -n 20000 -q PING_INLINE: 48076.92 requests per second PING_BULK: 45871.56 requests per second SET: 46948.36 requests per second GET: 44543.43 requests per second INCR: 45766.59 requests per second LPUSH: 50251.26 requests per second RPUSH: 45871.56 requests per second LPOP: 50505.05 requests per second RPOP: 51546.39 requests per second SADD: 46403.71 requests per second HSET: 45977.01 requests per second SPOP: 46620.05 requests per second LPUSH (needed to benchmark LRANGE): 49140.05 requests per second LRANGE_100 (first 100 elements): 26246.72 requests per second LRANGE_300 (first 300 elements): 13717.42 requests per second LRANGE_500 (first 450 elements): 10689.47 requests per second LRANGE_600 (first 600 elements): 8550.66 requests per second MSET (10 keys): 66225.17 requests per second
- -r:向Redis插入更多随机的键:redis-benchma -c 100 -n 20000 -r 10000(插入10000个随机的键)
- -p:每个请求pipeline的数据量(默认为1)
- -k<Boolean>:客户端是否使用keepalive,1为使用,0为不使用,默认为1
- -t:对指定命令进行基准测试、
root@myubuntu:/home/workspace/JedisTest# redis-benchmark -t get,set -q SET: 47732.70 requests per second GET: 45330.91 requests per second
- --csv:将结果按照csv格式输出,便于后续处理
root@myubuntu:/home/workspace/JedisTest# redis-benchmark -t get,set -q --csv "SET","50530.57" "GET","50352.47"
三、Pipeline
Redis客户端执行一条命令分为如下四个过程:①发送命令 ②命令排队 ③命令执行 ④返回结果
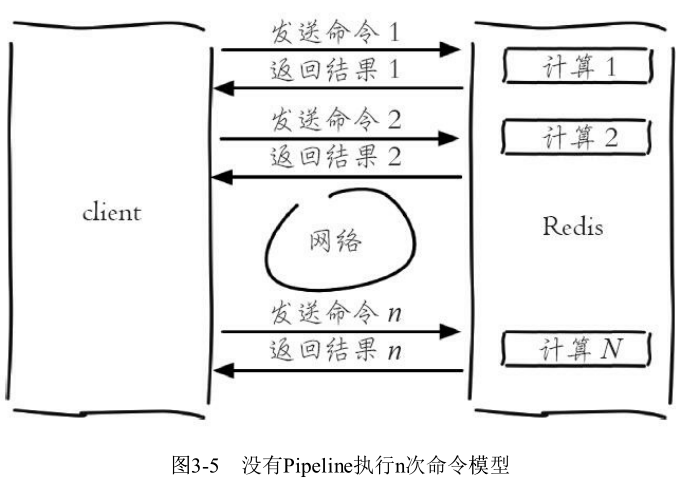
其中,①发送命令 + ④返回结果 称为Round Trip Time(RTT, 往返时间)
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。但大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有mhgettall命令存在,需要消耗n次RTT。当客户端和服务区部署在距离相差很远的两台机器上,由于RTT时间很长,那么在1秒内执行命令的次数就很少,这与Redis的高并发吞吐特性背道而驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端。
例如将set hello world和incr counter两条命令组装:
echo -en '*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\ n$7\r\ncounter\r\n' | redis-cli --pipe
Pipeline机制的要点是:
- Pipeline执行速度一般比逐条执行要快
- 客户端和服务端的网络延时越大,Pipeline的效果越明显。
Pipeline执行n条命令模型:

四、事务与Lua
Redis提供了简单的事务功能以及集成Lua脚本来保证多条命令组合的原子性。
1.事务
简单来说,事务就表示一组动作,要么全部执行,要么全部不执行。
Redis提供了简单的事务功能:将一组需要一起执行的命令放在multi和exec两个命令之间,它们之间的命令是原子顺序执行的。
以一个例子:社交网站上用于A关注了B,那么需要在用户A的关注列表中加入B,并且在B的粉丝表中添加A,这两个行为要么全部执行,要么全部不执行:
客户端1: 127.0.0.1:6379> multi OK 127.0.0.1:6379> sadd user:a:follow user:b QUEUED 127.0.0.1:6379> sadd user:b:fans user:a QUEUED 客户端2: 127.0.0.1:6379> sismember user:a:follow user:b (integer) 0 客户端1(停止事务的执行,可以使用discard命令代替exec命令即可): 127.0.0.1:6379> exec 1) (integer) 1 2) (integer) 1 127.0.0.1:6379> sismember user:a:follow user:b (integer) 1 127.0.0.1:6379> sismember user:b:fans user:a (integer) 1 客户端2: 127.0.0.1:6379> sismember user:a:follow user:b (integer) 1 127.0.0.1:6379> sismember user:b:fans user:a (integer) 1
如果事务中的命令出现错误,Redis的处理机制也不尽相同:
(1)命令错误(将set写成sett,属于语法错误,会造成整个事务无法执行):
127.0.0.1:6379> mset key hello counter 100 OK 127.0.0.1:6379> mget key counter 1) "hello" 2) "100" 127.0.0.1:6379> multi OK 127.0.0.1:6379> sett key world (error) ERR unknown command 'sett' 127.0.0.1:6379> incr counter QUEUED 127.0.0.1:6379> exec (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> mget key counter 1) "hello" 2) "100"
(2)运行时错误(运行时命令语法正确,误把sadd命令写成zadd命令)
127.0.0.1:6379> multi OK 127.0.0.1:6379> sadd user:a:follow user:b QUEUED 127.0.0.1:6379> zadd user:b:fans 1 user:a QUEUED 127.0.0.1:6379> exec 1) (integer) 0 2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 127.0.0.1:6379> sismember user:a:follow user:b (integer) 1
Redis不支持回滚功能,sadd user:a:follow user:b这条命令已经执行成功。
Redis提供了watch命令来确保事务中的key没有被其他客户端修改过,如果修改过就不执行事务(类似乐观锁):
客户端1: 127.0.0.1:6379> exists key (integer) 0 127.0.0.1:6379> set key java OK 127.0.0.1:6379> watch key OK 127.0.0.1:6379> multi OK 客户端2: 127.0.0.1:6379> append key python (integer) 10 客户端1: 127.0.0.1:6379> append key jedis QUEUED 127.0.0.1:6379> exec (nil) 127.0.0.1:6379> get key "javapython"
由于其他客户端修改过key值,所以append key jedis这条命令没有执行。
Redis提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算。相比之下Lua脚本同样可以实现事务的相关功能,但是功能要强大很多。
2.Lua语言简述
(1)Lua语言数据类型
Lua语言提供了几种数据类型:booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格)。
3.Redis与Lua语言
(1)在Redis使用Lua
- eval
192.168.131.130:6379> eval 'return "hello" .. KEYS[1] .. ARGV[1] ' 1 redis world
"helloredisworld"
- evalsha
加载脚本:script load命令可以将脚本内容加载到Redis内存中,例如下面将lua_get.lua加载到Redis中,得到SHA1为:"7413dc2440db1fea7c0a0bde841fa68eefaf149c" # redis-cli script load "$(cat lua_get.lua)" "7413dc2440db1fea7c0a0bde841fa68eefaf149c" 执行脚本:evalsha的使用方法如下,参数使用SHA1值,执行逻辑和eval一致。 evalsha 脚本 SHA1 值 key 个数 key 列表 参数列表 所以只需要执行如下操作,就可以调用lua_get.lua脚本: 127.0.0.1:6379> evalsha 7413dc2440db1fea7c0a0bde841fa68eefaf149c 1 redis world "hello redisworld"
(2)Lua的Redis API
Lua可以使用redis.call函数实现对Redis的访问
192.168.131.130:6379> eval 'return redis.call("set", KEYS[1], ARGV[1])' 1 Lua Redis
OK
192.168.131.130:6379> eval 'return redis.call("get", KEYS[1])' 1 Lua
"Redis"
4.Lua脚本语言功能的好处
- Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
- Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
- Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
5.Redis中使用Lua示例
(1)创建5个键,user:{id}:ratio中的id代表用户的id,对应的值代表用户的热度
192.168.131.130:6379> mset user:1:ratio 986 user:8:ratio 762 user:3:ratio 556 user:99:ratio 400 user:72:ratio 101 OK 192.168.131.130:6379> mget user:1:ratio user:8:ratio user:3:ratio user:99:ratio user:72:ratio 1) "986" 2) "762" 3) "556" 4) "400" 5) "101"
(2)创建一个记录着热门用户id的列表,即热度在100以上的5个用户
192.168.131.130:6379> rpush hot:user:list user:1:ratio user:8:ratio user:3:ratio user:99:ratio user:72:ratio (integer) 5 192.168.131.130:6379> lrange hot:user:list 0 -1 1) "user:1:ratio" 2) "user:8:ratio" 3) "user:3:ratio" 4) "user:99:ratio" 5) "user:72:ratio"
(3)现在要求将列表内所有的键对应热度做加1操作,并且保证是原子操作,此功能可以利用Lua脚本来实现。
创建Lua脚本并且将脚本内容写入脚本lrange_and_mincr.lua中:
--get all elements from the list you provide later, and give the result to 'mylist' local mylist = redis.call("lrange", KEYS[1], 0 , -1) --define variable 'count', this count represents the times of incr finally local count = 0 --everytime and everyone you do ,count plus 1, finally return count for index,key in ipairs(mylist) do redis.call("incr", key) count = count + 1 end return count
(4)新建窗口并执行脚本(返回结果5说明执行了5次incr操作):
root@myubuntu:/home/workspace# redis-cli -h 192.168.131.130 --eval lrange_and_mincr.lua hot:user:list (integer) 5
(5)查看结果
192.168.131.130:6379> mget user:1:ratio user:8:ratio user:3:ratio user:99:ratio user:72:ratio 1) "987" 2) "763" 3) "557" 4) "401" 5) "102"
6.Redis如何管理Lua脚本
(1)eval命令

客户端如果想执行Lua脚本,首先在客户端编写好Lua脚本代码,然后把脚本作为字符串发送给服务端,服务端会将执行结果返回给客户端。
(2)evalsha命令
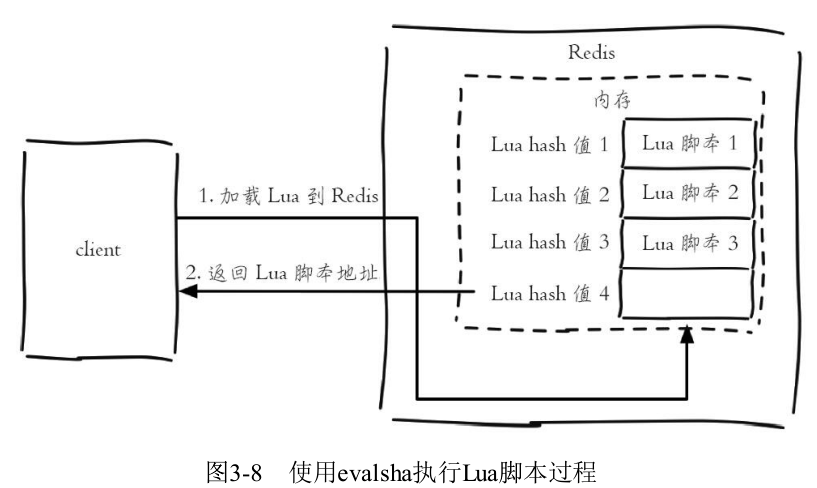
先要将Lua脚本加载到Redis服务端,得到该脚本的SHA1校验和,evalsha命令使用SHA1作为参数可以直接执行对应Lua脚本,避免每次发送Lua脚本的开销。这样客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。
(3)script load用于将Lua脚本加载到Redis内存中:
root@myubuntu:/home/workspace# redis-cli -h 192.168.131.130 script load "$(cat lrange_and_mincr.lua)" "f6b58b670c4384b409f42588877bc806cfae1ffa"
(4)script exists用于判断sha1是否加载到Redis内存中:
192.168.131.130:6379> script exists f6b58b670c4384b409f42588877bc806cfae1ffa 1) (integer) 1
(5)script flush用于清除Redis内存已经加载的所有Lua脚本
192.168.131.130:6379> script flush OK 192.168.131.130:6379> script exists f6b58b670c4384b409f42588877bc806cfae1ffa 1) (integer) 0
(6)script kill用于杀掉正在执行的Lua脚本,如果Lua脚本比较耗时,甚至Lua脚本存在问题,例如死循环,那么此时Lua脚本的执行会阻塞Redis,直到脚本执行完毕或者外部进行干预将其结束。
①利用script kill 杀掉正在执行的Lua脚本,该脚本会阻塞当前客户端
客户端1: 192.168.131.130:6379> eval 'while 1 == 1 do end' 0 客户端2: root@myubuntu:/home/workspace# redis-cli -h 192.168.131.130 192.168.131.130:6379> keys * (error) BUSY Redis is busy running a script. You can only call SCRIPT KILL or SHUTDOWN NOSAVE. 客户端2: 192.168.131.130:6379> script kill OK 客户端2: 192.168.131.130:6379> keys * 1) "hot:user:list" 2) "JSON" 客户端1: 192.168.131.130:6379> eval 'while 1 == 1 do end' 0 (error) ERR Error running script (call to f_feee71277bd43dee6eaf026037ed8d9d515da780): @user_script:1: Script killed by user with SCRIPT KILL... (90.26s)
②如果当前Lua脚本正在执行写操作(set),那么script kill将不会生效。
七、发布订阅
Redis提供了基于“发布/订阅”模式的消息机制,此种模式下,消息发布者和订阅者不进行直接通信,发布者客户端向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以收到该消息。
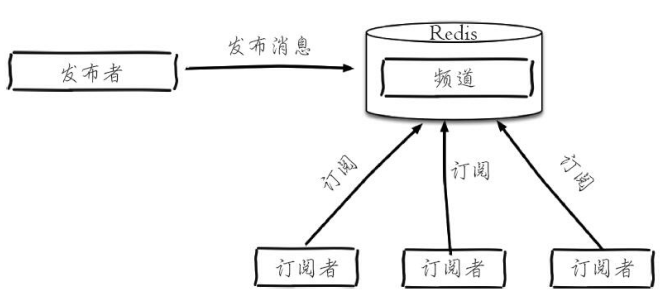
1.相关命令
(1)发布消息:publish channel message
客户端1:
127.0.0.1:6379> publish channel:sports "James Niubi" (integer) 0 返回结果为订阅者个数,因为此时没有订阅,所以返回结果为0
(2)订阅消息:subscribe channel [channel ...]
客户端2: 127.0.0.1:6379> subscribe channel:sports Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "channel:sports" 3) (integer) 1 客户端1: 127.0.0.1:6379> publish channel:sports "James Diao" (integer) 1 客户端2: 127.0.0.1:6379> subscribe channel:sports Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "channel:sports" 3) (integer) 1 1) "message" 2) "channel:sports" 3) "James Diao"
需要注意两点:
- 客户端在执行订阅命令之后进入了订阅状态。
- 新开启的订阅客户端,无法接收该频道之前的消息,因为Redis不会对发布的消息进行持久化。
(3)取消订阅:unsubscribe channel [channel ...]
127.0.0.1:6379> unsubscribe channel:sports 1) "unsubscribe" 2) "channel:sports" 3) (integer) 0
(4)按照模式订阅和取消订阅
订阅以it开头的所有频道:
psubscribe it*
(5)查询订阅
- 查看活跃的频道:pubsub channels (返回当前频道至少有一个订阅者的频道)
127.0.0.1:6379> pubsub channels 1) "channel:sports"
- 查看频道订阅数:pubsub numsub channel
127.0.0.1:6379> pubsub numsub channel:sports 1) "channel:sports" 2) (integer) 1
- 查看模式订阅数:pubsub numpat
客户端2: 127.0.0.1:6379> psubscribe ch* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "ch*" 3) (integer) 1 客户端3: 127.0.0.1:6379> pubsub numpat (integer) 1
2.使用场景
聊天室、公告牌、服务之间利用消息解耦都可以使用发布订阅模式,下面以简单的服务解耦进行说明。如图3-18所示,图中有两套业务,上面为视频管理系统,负责管理视频信息;下面为视频服务面向客户,用户可以通过各种客户端(手机、浏览器、接口)获取到视频信息。
假如视频管理员在视频管理系统中对视频信息进行了变更,希望及时通知给视频服务端,就可以采用发布订阅的模式,发布视频信息变化的消息到指定频道,视频服务订阅这个频道及时更新视频信息,通过这种方式可以有效解决两个业务的耦合性。
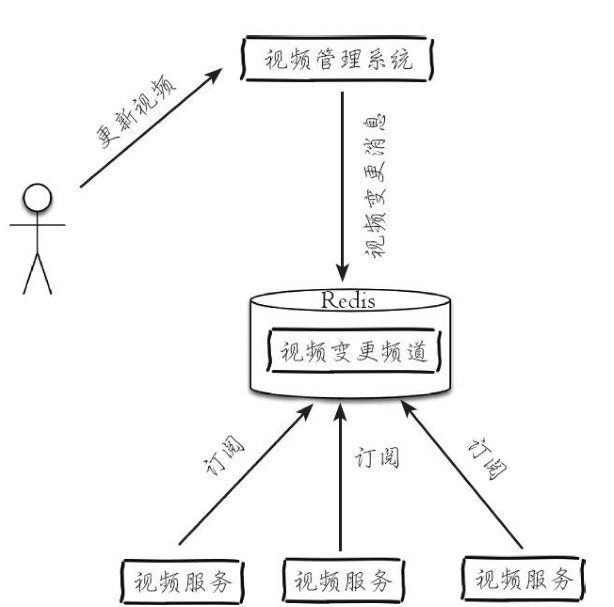
- 视频服务订阅video:changes频道如下:subscribe video:changes
- 视频管理系统发布消息到video:changes频道如下:publish video:changes "video1,video3,video5"
- 当视频服务收到消息,对视频信息进行更新,如下所示:for video in video1,video3,video5 update {video}
八、GEO
Redis提供了GEO(地理信息定位)功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能,对于需要实现这些功能的开发者来说是一大福音。
1.增加地理位置信息
geoadd key longitude latitude member [longitude latitude member ...]
longitude :经度
latitude :纬度
member :成员
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 0
127.0.0.1:6379> geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
(integer) 4
2.获取地理位置信息
geopos key member [member ...] 127.0.0.1:6379> geopos cities:locations tianjin 1) 1) "117.12000042200088501" 2) "39.0800000535766543"
3.获取两个地理位置的距离
geodist key member1 member2 [unit] unit代表返回结果的单位:m(米)、km(千米)、mi(英里)、ft(尺) 127.0.0.1:6379> geodist cities:locations tianjin beijing km "89.2061"
4.获取指定位置范围内的地理信息位置集合
127.0.0.1:6379> georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DES] [STORE key] [STOREDIST key]
127.0.0.1:6379> georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
计算五座城市中,距离北京150公里以内的城市:
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
5.获取geohash
geohash key member [member ...] 127.0.0.1:6379> geohash cities:locations beijing 1) "wx48ypbe2q0"
Redis使用geohash将二维经纬度转换为一维字符串。
geohash有以下特点:
- GEO的数据类型为zset(有序集合),Redis将所有地理位置信息的geohash存放在zset中。
- 字符串越长,表示的位置更精确。
- 两个字符串越相似,它们之间的距离越近,Redis利用字符串前缀匹配算法实现相关的命令
- geohash编码和经纬度是可以相互转换的。
6.删除地理位置信息
和有序集合删除成员的命令一致:zrem key member

 浙公网安备 33010602011771号
浙公网安备 33010602011771号