ORM Basic
ORM即object relational mapping 对象关系映射程序,可以在操作数据库的时候使用自有的语言而不必使用数据库的语言。
在python中,最强大的ORM框架就是SQLAlchemy。基本构成如下:
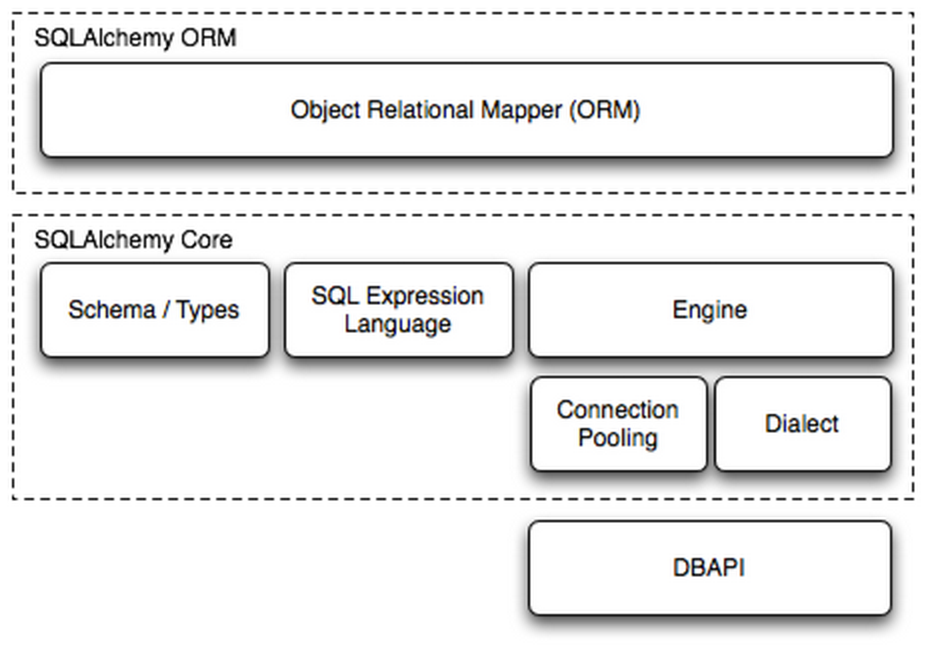
首先来看看SQL Alchemy的基本用法:
在使用SQL Alchemy的时候必须包子Mysql的字符集为utf-8(默认为Latin1),使用以下命令进入MySQL的配置
sudo vim /etc/mysql/my.cnf
插入信息:
[client] default-character-set = utf8 [mysqld] character-set-server = utf8 [mysql] default-character-set = utf8
下面开始正式连接数据库
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://root****@locahost:3306/blog#****为MySQLroot用户密码,此命令运行了默认在3306端口的blog数据库
下面开始描述表结构:
SQL alchemy有declarative系统来进行数据库中表的结构描述,以创建user为例:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/test2db?charset=utf8")
Base = declarative_base() # 生成基类
class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True)
def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.name)#
Base.metadata.create_all(engine)#创建表结构
创建了users的表,有三个字段(用Column语句描述),包括id,name和password,数据类型处理integer和string外还有text,Boolean,smallinteger和datetime,nullable=False表示不可为空,index=True表示在该列创建索引,并且用repr函数定义了返回输出格式
表的本质就是各种关系的集合,那么我们来看看这些关系的定义
一对多关系
用户跟文章肯定有一个关系,而且该关系还是一对多(一个作者对应多个文章)
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,Text
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
engine = create_engine("mysql+mysqldb://root:123456@localhost:3306/test2db?charset = utf8")
Base = declarative_base() # 生成基类
class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True)
articles = relationship('Article',backref = 'author')#连接User和Article在users中使用articles调用,在articles中使用users调用。
def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.name)
class Article(Base):
__tablename__ = 'articles'
article_id = Column(Integer, primary_key=True,nullable=False, index=True)
title = Column(String(255),nullable = False,index = True)
content = Column(Text)
user_id = Column(integer,ForeignKey('users.id'))
def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.title)
Base.metadata.create_all(engine)#创建表结构
一对一关系
如果需要储存一个更详细的个人资料User_Info,其与User的映射应该是一对一的。
#coding:utf8
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,Text
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
engine = create_engine("mysql+mysqldb://root:123456@localhost:3306/blog?charset = utf8")
Base = declarative_base() # 生成基类
class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True)
article = relationship('Article',backref = 'author')
userinfo=relationship('userinfo',backref='author',uselist=False)#只需要将此处uselist设为False便是一对一
class Article(Base):
__tablename__ = 'articles'
article_id = Column(Integer, primary_key=True,nullable=False, index=True)
title = Column(String(255),nullable = False,index = True)
content = Column(Text)
user_id = Column(Integer,ForeignKey('users.id'))
class Info_User(Base):
__tablename__='userinfo'
id=Column(Integer,primary_key=True,nullable=False,index=True)
qq=Column(String(32),nullable=False,index=True)
tel=Column(String(32),nullable=False,index=True)
user_id=Column(Integer,ForeignKey('users.id'))
Base.metadata.create_all(engine)#创建表结构
多对多的关系:
一个文章可能有多个标签,一个标签也可能对应多本文章,这就是多对多的关系。多对多不能直接定义,需要分解为两个一对多,并引入一张额外的表来协助完成。
article_tag = Table(
'article_tag', Base.metadata,
Column('article_id', Integer, ForeignKey('articles.id'),nullable=False,primary_key=True),
Column('tag_id', Integer, ForeignKey('tags.id'),nullable=False,primary_key=True)
)
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.name)
表结构已经搭好,现在开始往里面填充数据,此处我们使用faker模块来模拟数据。
import faker
faker = Factory.create()
Session = sessionmaker(bind=engine)
session = Session()#创建了一个可以与MySQL对话的实例
faker_users = [User(
username=faker.name(),
password=faker.word(),
email=faker.email(),
) for i in range(10)]
session.add_all(faker_users)
faker_categories = [Category(name=faker.word()) for i in range(5)]
session.add_all(faker_categories)
faker_tags= [Tag(name=faker.word()) for i in range(20)]
session.add_all(faker_tags)
for i in range(100):
article = Article(
title=faker.sentence(),
content=' '.join(faker.sentences(nb=random.randint(10, 20))),#10-20个不等长的sentence
author=random.choice(faker_users),
category=random.choice(faker_categories)
)
for tag in random.sample(faker_tags, random.randint(2, 5)):2-5个tags
article.tags.append(tag)
session.add(article)
session.commit()
通过以上代码创建了10个用户,5个分类,20个标签,100篇文章,使用 SQLAlchemy 往数据库中添加数据,我们只需要创建相关类的实例,调用 session.add() 添加一个,或者 session.add_all() 一次添加多个, 最后 session.commit() 就可以了。
查:使用get语法,filter_by按照某一特定格式筛选(使用=),filter按照一些格式筛选(使用==),all查询所有
article = session.query(Article).get(1)
改:
article.title = 'this is my first blog' session.add(article) session.commit()
增:
article.tag.append(Tag(name='python')) session.add(article) session.commit()
删:
session.delete(article) session.commit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号