一个问烂了的问题--数据量大的情况下分页查询很慢,有什么优化方案(各blog集合)
我自己有一张表,有100w条数据
limit分页时间对比
同一起始位置,不同的偏移量
类似下图

select * from poison.poison_users limit 10000, 10;
468 ms
select * from poison.poison_users limit 10000, 100;
515 ms
select * from poison.poison_users limit 10000, 1000;
541 ms
select * from poison.poison_users limit 10000, 10000;
2772 ms
select * from poison.poison_users limit 10000, 100000;
84059 ms
同样偏移不同起始位置
类似下图
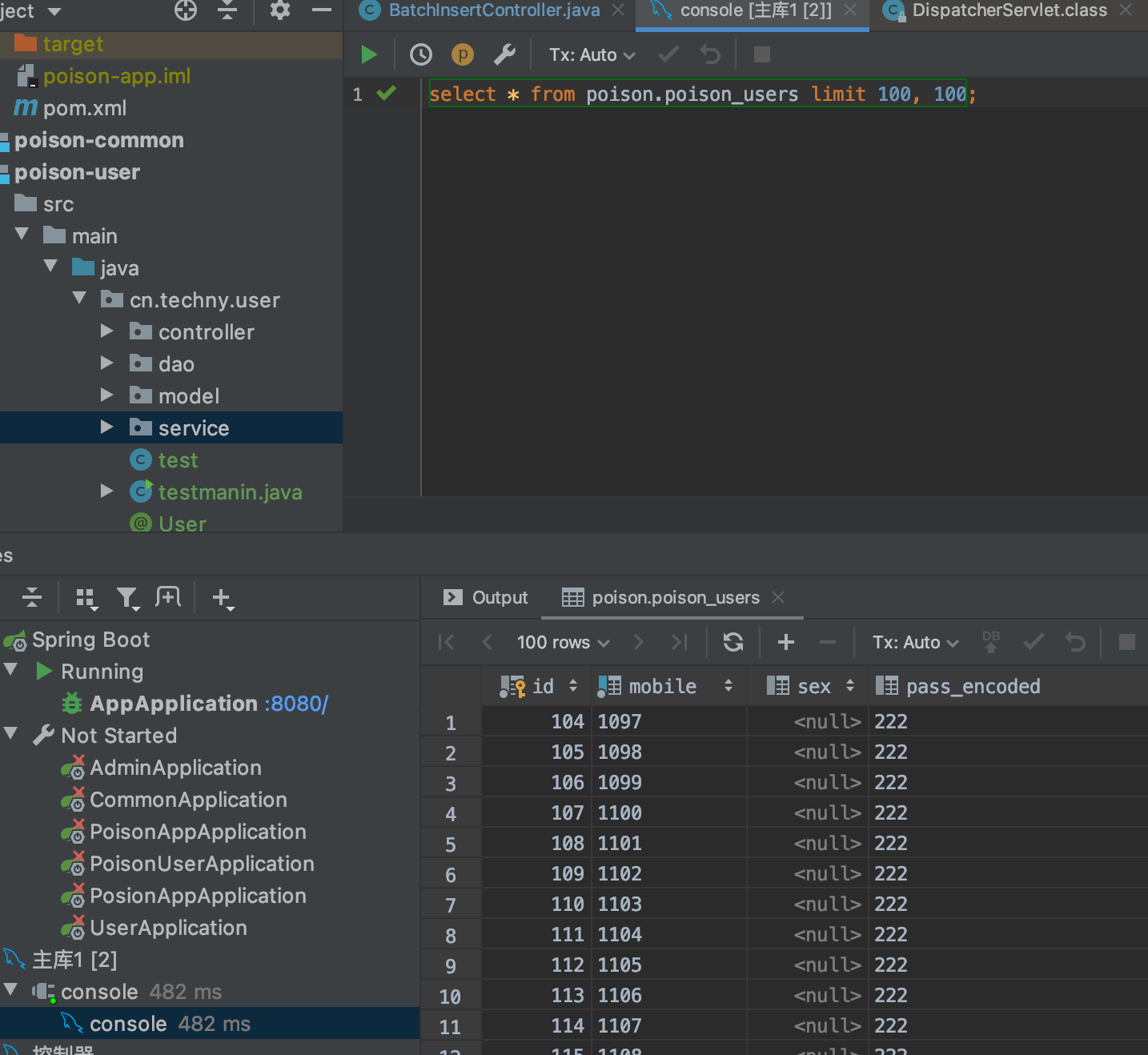
select * from poison.poison_users limit 100, 100;
482 ms
select * from poison.poison_users limit 1000, 100;
533 ms
select * from poison.poison_users limit 100000, 100;
555 ms
select * from poison.poison_users limit 1000000, 100;
3568 ms
limit 初始位置和偏移量都对查询速度都有影响
在无过滤条件下
分库分表,采用独立的中间件 mycat 或者 sharding-jdbc 或者 全套的ShardingSphere
在有过滤条件下
使用子查询优化
不用子查询的情况
select * from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' limit 100000,100; select * from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' limit 100000,1;

1261 ms
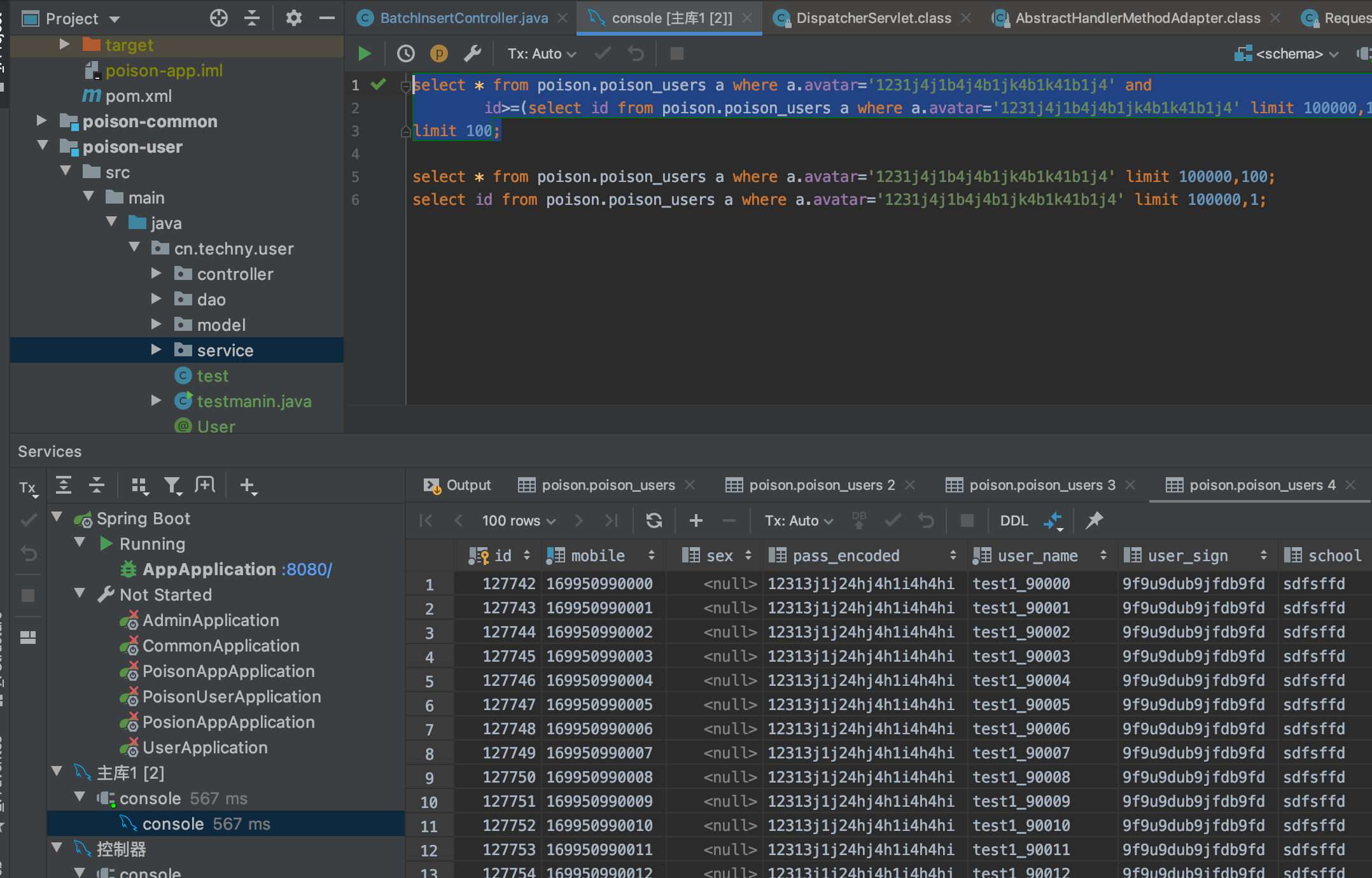
select * from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' and id>=(select id from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' limit 100000,1) limit 100;
470 ms
限定id范围
select * from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' and id between 1000000 and 1000100;
490 ms
子查询中使用limit
由于一些mysql一些版本中不支持子查询中limit,可以嵌套一层实现
select * from poison.poison_users a where id in (select u.id from
(select id from poison.poison_users a where a.avatar='1231j4j1b4j4b1jk4b1k41b1j4' limit 100000,100) as u);
470 ms
临时表优化
根据条件提前查出分页id范围,记录到临时表,使用其进行in查询
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号