切分查询和分解关联查询和查询基础
采用分治思想,将大查询切分成小查询
比如将大数据量的删除分批进行
分解关联查询优势
- 缓存效率更高,拆分后如果某个表很少改变,基于该表的查询就可以重复利用查询缓存结果了
- 将查询分解后,执行单个查询可以减少锁的竞争
- 在应用层做关联,容易对数据库拆分
- 查询本身效率有所提升
- 减少冗余记录的查询,在应用层关联查询意味着对于某条记录只需要查询一次,在数据库关联查询,可能需要重复访问一部分数据
- 在应用中使用哈希关联效率更高
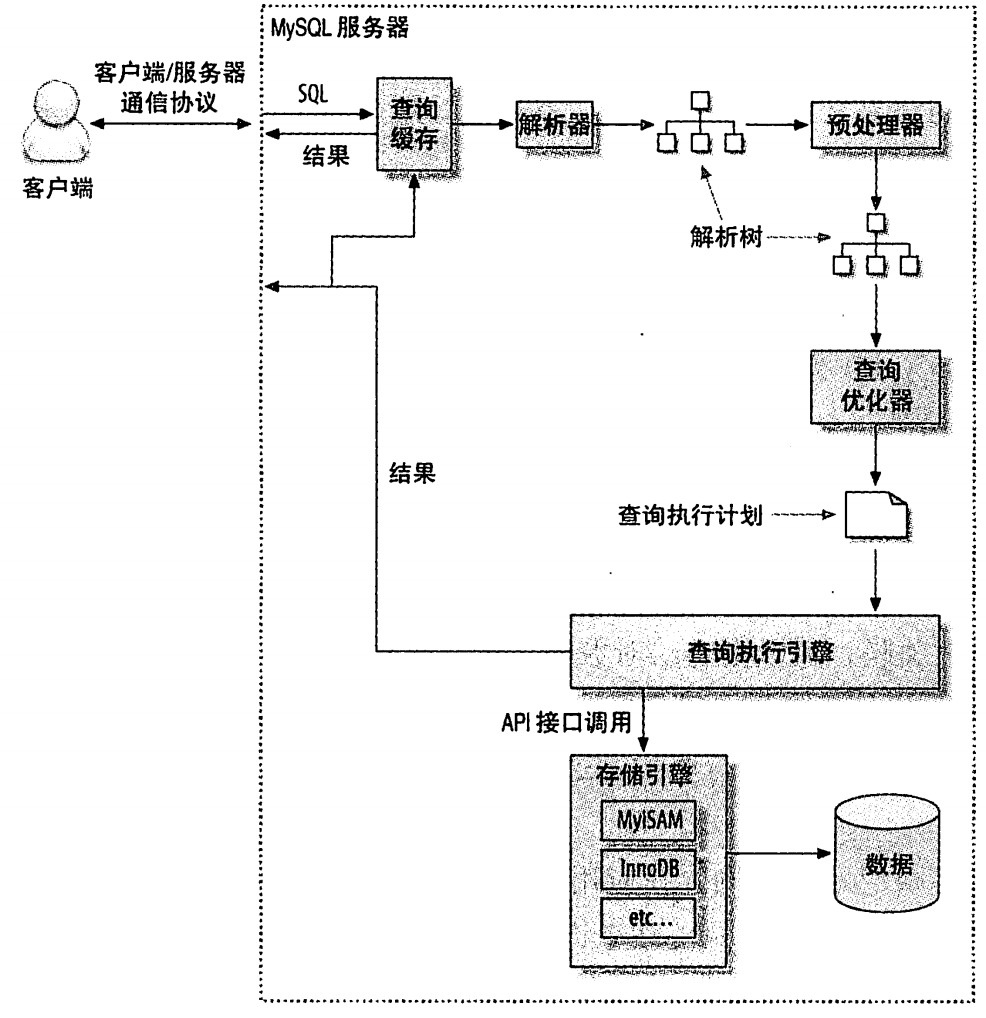
查询执行的基础
MySQL客户端和服务器之间的通信协议是半双工(两个人做抛球游戏)
客户端从服务器取数据时,看起来是一个拉数据的过程,实际上是MySQL向客户端推送数据的过程(从消防管喝水)
MySQL通常需要等所有的数据都已经发送给客户端才能释放这条查询所占用的资源,库函数会缓存全部资源
查询状态
show full processlist
- Sleep,线程等待客户端发送新请求
- Query,线程正在执行查询或者将结果发送给客户端
- Locked,在MySQL服务层,线程等待表锁;存储引擎级别的锁不会体现
- Analyzing and statistics,线程正在收集存储引擎的统计信息,生成查询的执行计划
- Copying to tmp table,GROUP BY、文件排序或者是UNION操作后
- Sorting result
- Sending data
查询缓存
通过一个对大小写敏感的哈希查找
查询优化处理
将一个SQL转换成一个执行计划,MySQL按照这个计划和存储引擎进行交互
语法解析器和预处理
MySQL 通过关键字解析SQL语句,生成一棵解析树,MySQL解析器用语法规则验证和解析查询
查询优化器
当前查询成本
show status like 'Last_query_cost'
导致MySQL优化器选择错误的执行计划
统计信息不准确,MySQL 依赖存储引擎提供的统计信息评估成本
执行计划中成本估算不等同于实际执行的成本
静态优化(编译时优化)
- 直接对解析树分析完成优化
- 不依赖于特定数值,在第一次完成后一直有效
动态优化(与查询上下文有关,运行时优化)
- WHERE 条件取值,索引中条目对应的数据行数
- 每次查询都要重新评估
优化类型
重新定义关联表的顺序
数据表的关联不总是按照在查询中指定的顺序进行
将外连接转换为内连接
通过 WHERE 条件、库表结构让外连接等价于一个内连接
使用等价变换规则
尽量使用常量,合并和减少一些比较,移除恒成立和恒不成立
优化COUNT、MIN、MAX
要找到某一些最小值,只需要查询对应B-Tree索引最左端的记录
如果要查找一个最大值,只需要读取B-Tree索引的最后一条记录
在 explain 中的 Extra 有 Select tables optimized away 字样
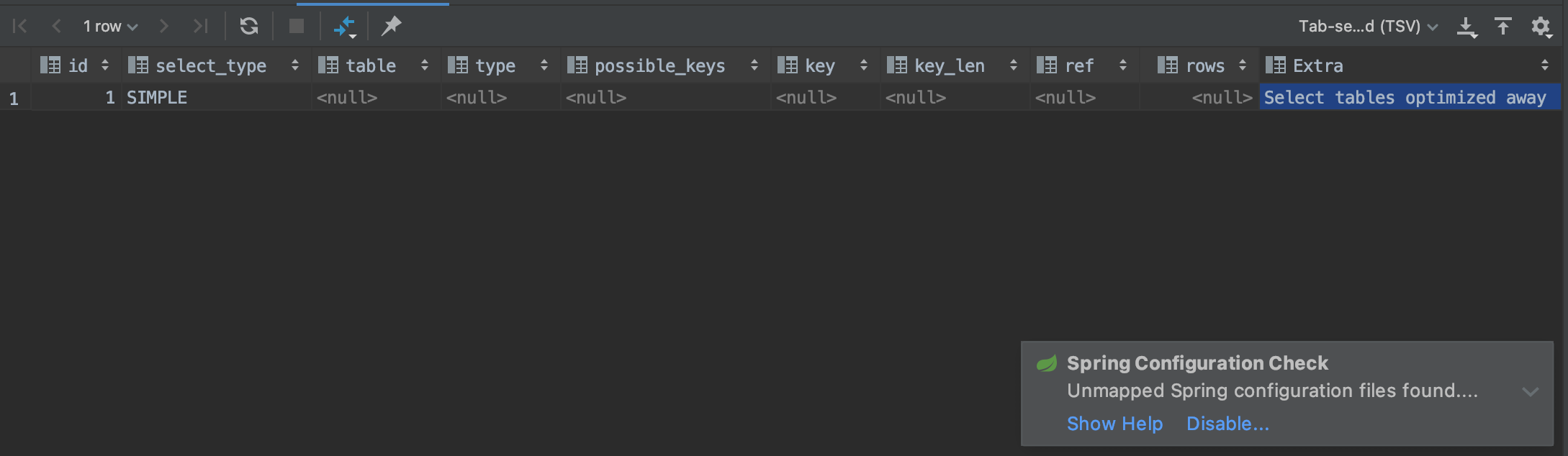
它表示优化器已经从执行计划中移除了该表,并以一个常数代替
预估表达式转换为常数
- 用户自定义变量在查询中没有发生变化可以转换为一个常数
- 在优化阶段,若 WHERE 子句中使用了索引的常数条件,查询开始阶段先查找这些值,优化器将表达式转换为常数
- 等式将常数值从一个表传递到另一个表,通过 using、where 或 on 限制某列取值为常量
覆盖索引
自查询优化
提前终止查询
- 使用limit
- 使用 dinsinct、not exist 或者 left join
等值传播
如果两个列的值通过等式关联,MySQL 把其中一列的 WHERE 条件传递到另一列上
select table1.id from table1 inner join db2.table2 using(id) where table1.id > 500;
这里通过 id 字段等值关联,where 条件对两个表都适用
列表IN的比较
MySQL 将 IN 列表中数据先进行排序,然后通过二分查找确定列表中的值是否满足条件,复杂度O(log n)
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号