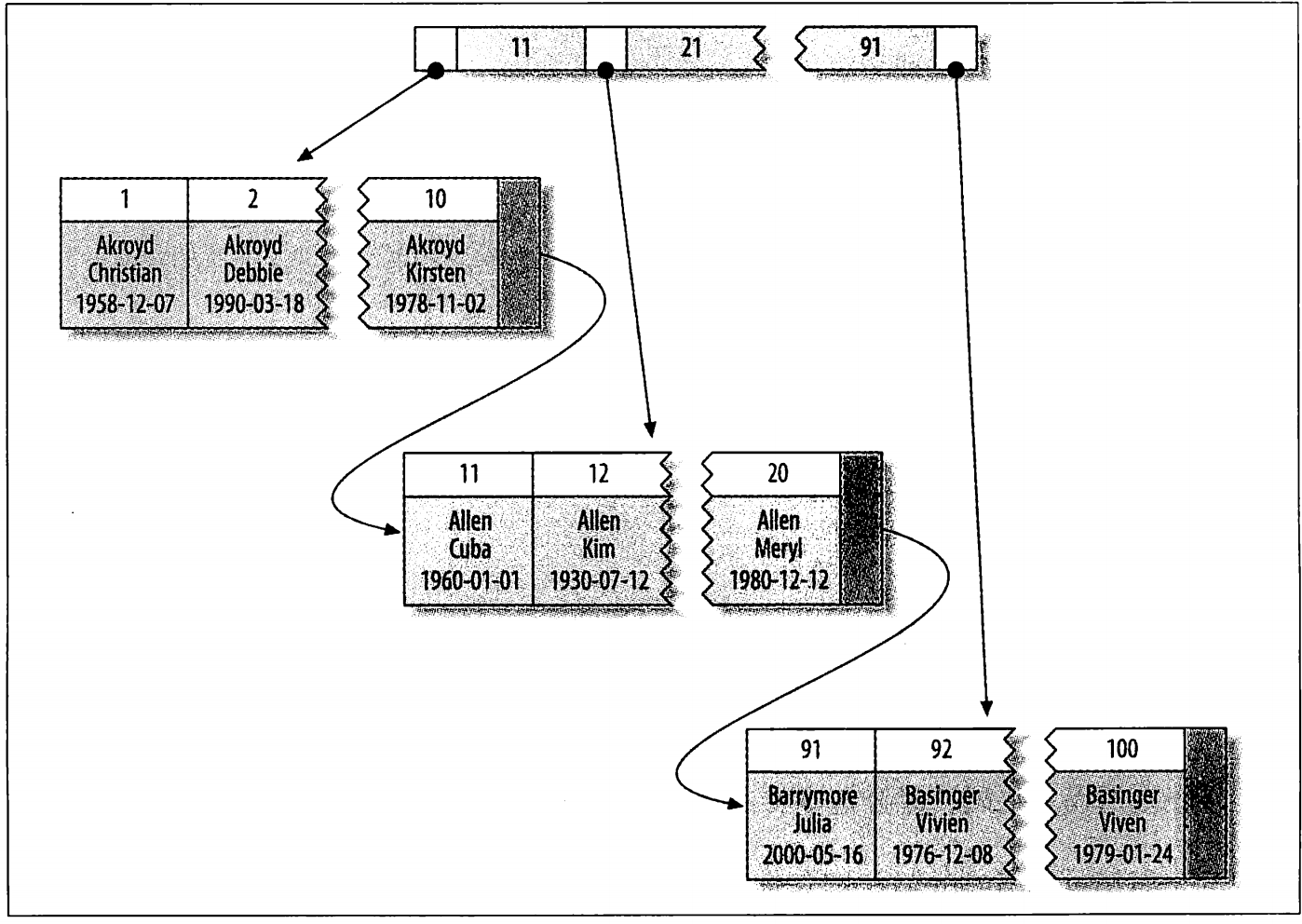
MySQL 聚簇索引
InnoDB的聚簇索引在统一结构中保存了B-Tree索引和数据行
叶子页包含行全部数据,节点页只包含了索引列
聚簇索引的优点
- 可以把相关数据保存在一起,减少磁盘IO
- 数据访问更快,聚簇索引将索引和数据保存在同一个B-Tree中,在聚簇索引中获取数据更快
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值
聚簇索引的缺点
- 聚簇索引最大限度提高了IO密集型应用性能,数据都在内存除外
- 插入速度严重依赖于顺序,按照主键顺序插入是加载数据到InnoDB表速度最快的方式,如果不是按主键顺序,加载完后用OPTIMIZE TABLE命令重新组织
- 更新聚簇索引列代价很高,会强制InnoDB移动更新行到指定位置
- 基于聚簇索引的表在插入新行或者主键被更新导致需要移动,可能面临"页分裂"问题
- 聚簇索引可能导致全标扫描变慢,原因为行稀疏或者页分裂导致存储不连续
- 二级索引可能更大,二级索引访问需要两次索引查找,而不是一次,因为二级索引保存的是行的主键值,不是指向行的物理位置
- 然后根据这个主键值去聚簇索引中查找对应的行
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号