索引优化
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机io变成顺序io
索引的用处
- 快速查找匹配WHERE子句的行
- 从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
索引的分类
- 主键索引
- 唯一索引
- 普通索引
- 全文索引
- 组合索引
索引匹配方式
全值匹配
和索引中的所有列进行匹配
explain select * from staffs where name = 'July' and age = '23' and pos = 'dev';

匹配最左前缀
只匹配前面几列
explain select * from staffs where name = 'July' and age = '23';

匹配列前缀
匹配某一列的值的开头部分
explain select * from staffs where name like 'J%';
type变为range,ref没了,不知道该引用哪列索引

explain select * from staffs where name like '%J%';
如果通配符放在了开头,那就变成了全文扫描,索引失效

匹配范围值
查找某一个范围的值
explain select * from staffs where name > 'Mary";
范围匹配

精确匹配某一列并范围匹配另一列
查询第一列的全部和第二列的部分
explain select * from staffs where name = 'Mary' and age > 18;

explain select * from staffs where name = 'Mary' and pos > 18;
跳过了中间的age,pos是一个无关条件,所以pos列索引不会匹配

只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引
explain select name,age,pos from staffs where name = 'July' and age = '23' and pos = 'dev';
Extra出现Using index,即是索引覆盖

哈希索引
基于哈希表的实现,只有精确匹配索引所有列的查询才有效
不能使用范围匹配
在mysql中,只有memory的存储引擎显式支持哈希索引
哈希索引自身只需存储对应的hash值,所以索引的结构十分紧凑,这让哈希索引查找的速度非常快
哈希索引的限制
- 哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以无法进行排序
- 哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
- 哈希索引支持等值比较查询,也不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突的时候,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行
- 哈希冲突比较多的话,维护的代价也会很高
组合索引
当包含多个列作为索引,需要注意的是正确的顺序依赖于该索引的查询,同时需要考虑如何更好的满足排序和分组的需要
建立组合索引a,b,c
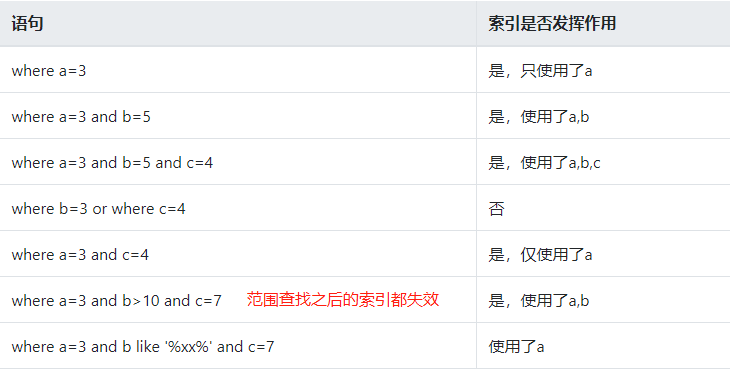
聚簇索引
不是单独的索引类型,而是一种数据存储方式,指的是数据行跟相邻的键值紧凑的存储在一起
优点
- 可以把相关数据保存在一起
- 数据访问更快,因为索引和数据保存在同一个树中
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值
缺点
- 聚簇数据最大限度地提高了IO密集型应用的性能,如果数据全部在内存,那么聚簇索引就没有什么优势
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式
- 更新聚簇索引列的代价很高,因为会强制将每个被更新的行移动到新的位置
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临页分裂的问题
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候
非聚簇索引
数据文件跟索引文件分开存放
覆盖索引
如果一个索引包含所有需要查询的字段的值,我们称之为覆盖索引
- 不是所有类型的索引都可以称为覆盖索引,覆盖索引必须要存储索引列的值
- 不同的存储实现覆盖索引的方式不同,不是所有的引擎都支持覆盖索引,memory不支持覆盖索引
优点
- 索引条目通常远小于数据行大小,如果只需要读取索引,那么mysql就会极大的减少数据访问量
- 因为索引是按照列值顺序存储的,所以对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少的多
- 一些存储引擎如MYISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用,这可能会导致严重的性能问题
- 由于INNODB的聚簇索引,覆盖索引对INNODB表特别有用
在explain的extra列可以看到using index的信息,此时就使用了覆盖索引
explain select storeid,filmid from inventory\G
*************************** 1. row *************************** id: 1 selecttype: SIMPLE table: inventory partitions: NULL type: index possiblekeys: NULL key: idxstoreidfilmid key_len: 3 ref: NULL rows: 4581 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.01 sec)
在大多数存储引擎中,覆盖索引只能覆盖那些只访问索引中部分列的查询
使用innodb的二级索引来覆盖查询优化
例如:actor使用innodb存储引擎,并在lastname字段有二级索引,虽然该索引的列不包括主键actorid,但也能够用于对actor_id做覆盖查询
explain select actorid,lastname from actor where lastname='HOPPER'\G
*************************** 1. row *************************** id: 1 selecttype: SIMPLE table: actor partitions: NULL type: ref possiblekeys: idxactorlastname key: idxactorlastname keylen: 137 ref: const rows: 2 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec)
索引优化
当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层
select actor_id from actor where actor_id=4; select actor_id from actor where actor_id+1=5;
尽量使用主键查询,而不是其他索引,因此主键查询不会触发回表查询
使用前缀索引
参考文章:https://www.cnblogs.com/YC-L/p/14461559.html
使用索引扫描来排序
参考文章:https://www.cnblogs.com/YC-L/p/14461561.html
union all,in,or都能够使用索引,但是推荐使用in
- union all 不会过滤重复数据
- union会过滤重复数据
范围列可以用到索引
- 范围条件是:<、<=、>、>=、between
- 范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列
强制类型转换会全表扫描
不会触发索引,全表扫描
explain select * from user where phone=13800001234;
触发索引,不会全表扫描
explain select * from user where phone='13800001234';
更新十分频繁,数据区分度不高的字段上不宜建立索引
- 更新会变更B+树,更新频繁的字段建议索引会大大降低数据库性能
- 类似于性别这类区分不大的属性,建立索引是没有意义的,不能有效的过滤数据
- 一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算
MySQL索引长度和区分度,参考文章:https://www.cnblogs.com/YC-L/p/14461567.html
创建索引的列,不允许为null,可能会得到不符合预期的结果
当需要进行表连接的时候,最好不要超过三张表,因为需要join的字段,数据类型必须一致
能使用limit的时候尽量使用limit
单表索引建议控制在5个以内
单索引字段数不允许超过5个(组合索引)
创建索引的时候应该避免以下错误概念
- 索引越多越好
- 过早优化,在不了解系统的情况下进行优化
索引监控
show status like 'Handler_read%';
参数
- Handler_read_first:读取索引第一个条目的次数
- Handler_read_key:通过index获取数据的次数
- Handler_read_last:读取索引最后一个条目的次数
- Handler_read_next:通过索引读取下一条数据的次数
- Handler_read_prev:通过索引读取上一条数据的次数
- Handler_read_rnd:从固定位置读取数据的次数
- Handler_read_rnd_next:从数据节点读取下一条数据的次数
全值匹配指的是和索引中的所有列进行匹配
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号