JVM G1
设计架构的重要思想
- 分治
- 分层
官方地址:https://www.oracle.com/technical-resources/articles/java/g1gc.html

吞吐量G1比PS降低10%~15%
追求耗时少,200ms内有响应,用G1
追求throughput,用Parallel
G1原理模型
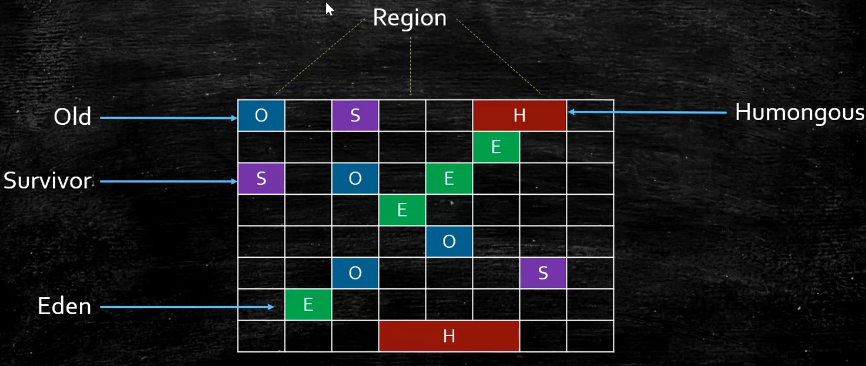
humongous object
- 超过单个region50%

GC何时触发
YGC
- Eden空间不足
- 多线程并行执行
FGC
- Old空间不足
- system.gc()
G1特点
- 并发收集
- 压缩空闲空间不会延长GC的暂停时间
- 更易预测的GC暂停时间
- 适用不需要实现很高的吞吐量的场景
- 动态新老年代比例:5%~60%,不需要手工指定
- G1预测停顿时间的基准
Card Table

- YGC的时候,需要扫描整个Old区域,效率非常低,所以Jvm设计了CardTable
- 如果一个CardTable中有对象指向Y区,将其设置为Dirty,下次扫描时,只需要扫描Dirty的Card Table
- 在结构上,Card Table用Bitmap实现
G1的内存区域不是固定的Eden或者Old

G1基本概念
CSet
CSet = Collection Set
- 一组可被回收的分区的集合
- 在CSet中存活的数据会在GC过程中被移动到另一个可用分区
- CSet中的分区可以来自Eden空间、survivor空间或者老年代
- Cset会占用不到整个堆空间的1%大小
Rset
RememberedSet(G1高效回收的关键)
- Region中都有一个HashSet(Rset),记录其他对象对本对象的引用
- 回收高效,占用空间变大,空间换时间

G1中的MixedGC
相当于一个CMS
XX:InitiatingHeapOccupacyPercent
- 默认值45%
- 当O超过这个值时,启动MixedGC
MixedGC过程
- 初始标记stw
- 并发标记
- 最终标记(重新标记)
- 筛选回收stw(并行)
初始标记
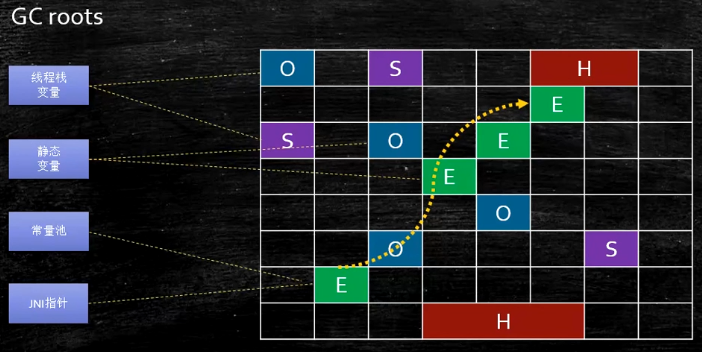
并发标记

最终标记
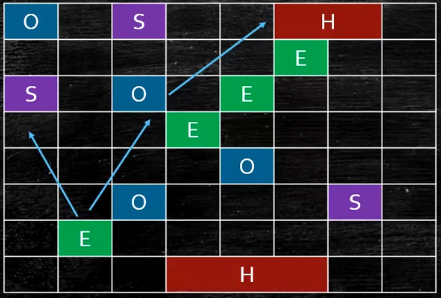
并行筛选回收(筛选垃圾最多的region进行回收)
如果G1产生FCG,应该怎么做
- 扩内存
- 提高CPU性能(回收得快,业务逻辑产生对象速度固定,垃圾回收快,内存空间大)
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认45%)
阿里多租户Jvm
- 每租户空间
- session based GC
并发标记算法
在标记对象过程中,对象的引用关系正在发生改变
三色标记
- 白色,未被标记的对象
- 灰色,自身被标记,成员变量未被标记
- 黑色,自身和成员变量均已标记完成

漏标

A指向D,B指向D的引用消失了
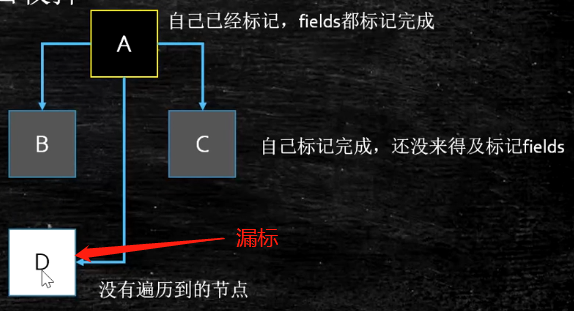
产生漏标
漏标指的是,live object,由于没有遍历到,被当成garbage回收
- 标记进行时增加了一个黑到白的引用,如果不重新处理黑色,会漏标
- 标记进行时删除了灰对象对白对象的引用,这个白对象可能被漏标
漏标解决方法
incremental update(CMS采用方案)
- 增量更新,关注应用的增加,把黑色重新标记为灰色,下次重新扫描属性
SATB snapshot at the beginning(G1采用方案)
- 关注引用删除,当B->D消失时,要把这个引用推到GC的堆栈,保证D还能被GC扫描到
为什么G1使用SATB
- 灰色->白色,引用消失时,如果没有黑色指向白色
- 引用会被push到堆栈,下次扫描时拿到这个引用,由于RSet的存在
- 不需要扫描整个堆区查找指向白色的引用,效率比较高
- SATB配合RSet,完美搭配
Rset与赋值效率
- 由于RSet的存在,每次给对象赋引用时候,就得做一些额外操作
- 在Rset中做一些额外的记录(在GC中称为写屏障)
写屏障(不是内存屏障)
No Sivler Bullet
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号