JMM(Java Memory Model),乱序执行和指令重排
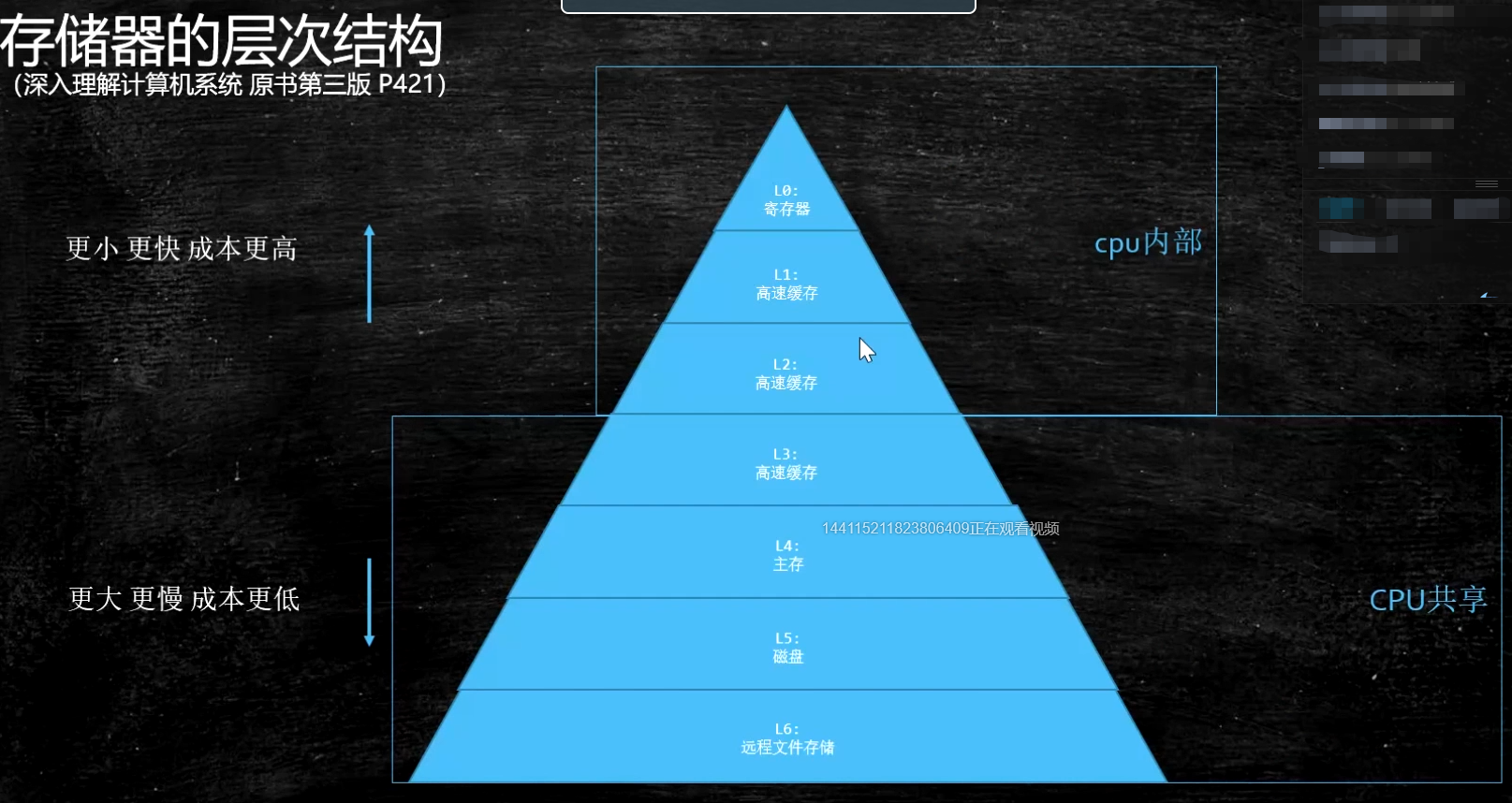
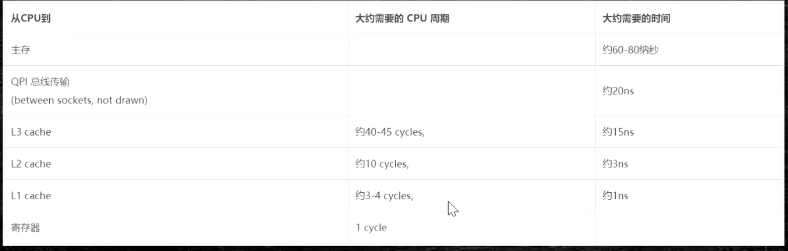
存储器层次结构
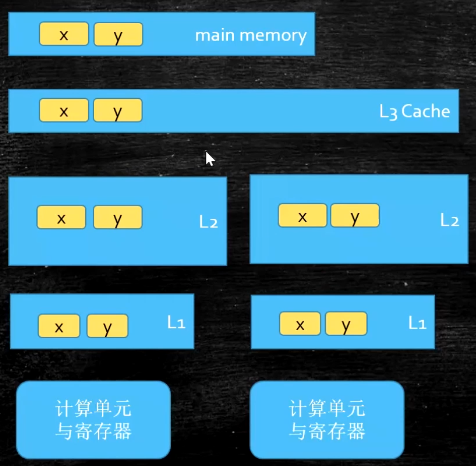
Cache line的概念,缓存行对齐,伪共享
多线程一致性的硬件层支持

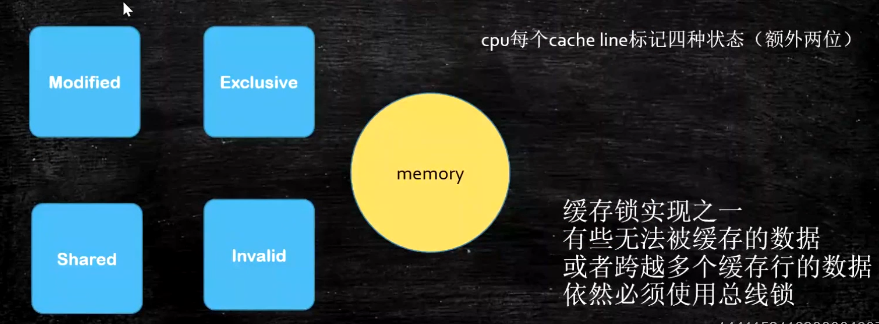
MESI Cache一致性协议(重点)
- 在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
- M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
- E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
- S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
- I(Invalid):这行数据无效。
通俗一点说,就是如果Core0和Core1都在使用一个共享变量变量A,则0,1都会在自己的Cache里有一份A的副本,分布在不同的CacheLine。
如果大家都没有修改A,则Core0和Core1里变量A所在的Cache Line的状态都是S。
如果Core0修改了A的值,则此时Core0的Cache Line变为M,Core1 的Cache Line变为I。
这样CPU就可以通过CacheLine的状态,来决定是删除缓存,还是直接读取什么的。
FalseSharing(伪共享)
static volatile boolean flag = true; public static void main(String[] args) { for (int i = 0; i < 10; i++) { new Thread(() -> { Integer count = 0; while (flag) { ++count; System.out.println(Thread.currentThread().getName() + ":" + count); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); } new Thread(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } flag = false; }).start(); }
这段代码会声明一个flag为true,然后有10个工作线程会在flag为true时没100ms对count做个自增操作,然后输出。当flag为false时,就会结束线程
还有一个线程A,会在1000ms后将flag置为false
这里就是volatile的一个经典用法,可以保证多个线程对flag的可见性,不会因为线程A修改了flag的值,但是工作线程读取到的不是最新值而额外执行一些工作
这段代码看起来是没有任何问题的,实际上跑起来也没有问题
但是结合之前的背景知识,考虑一下flag所在的cache line,肯定还会有其他的变量(cache line 64字节,bool无法完整填充一个CacheLine)
如果 flag 所在的 CacheLine 里还有一个频繁修改的共享变量,这时会发生什么?
很简单,就是flag所在的CacheLine被频繁置为不可用,需要清除缓存重新读取。flag在工作状态并没有被修改,但是仍然会被其他频繁修改的共享变量所影响
这样就会带来一个问题,即使flag并没有被修改,但我们的工作线程很多时间都等于是在主存中读取flag的值,这样在高并发时会带来很大的效率问题
以上就是所谓的 “FalseSharing” 问题。
The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
百度发号器中的 PaddedAtomicLong
/** * Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p> * * The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br> * 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value) * * @author yutianbao */ public class PaddedAtomicLong extends AtomicLong { private static final long serialVersionUID = -3415778863941386253L; /** Padded 6 long (48 bytes) */ public volatile long p1, p2, p3, p4, p5, p6 = 7L; /** * Constructors from {@link AtomicLong} */ public PaddedAtomicLong() { super(); } public PaddedAtomicLong(long initialValue) { super(initialValue); } }
CacheLine一般是64字节,64 = 8(对象字节头,32位下8字节)+ 6*8(long占用8个字节) + 8 (AtomicLong本身带有一个long)
写了这6个看着无效的变量后,PaddedAtomicLong 就会占用64个字节,正好填满一个 CacheLine,这样就会被独自分配到一个 CacheLine,这样就不存在 FalseSharing 问题了
需要注意的是本来 AtomicLong 仅占用不到20字节,但是为了解决 FalseSharing 做了填充之后就占用64字节了,这样就会导致空间会膨胀
Java8 以上伪共享
public class Point { int x; @Contended int y; }
@Contended 注解会增加目标实例大小,要谨慎使用。默认情况下,除了 JDK 内部的类,JVM 会忽略该注解。要应用代码支持的话,要设置 -XX:-RestrictContended=false,它默认为 true(意味仅限 JDK 内部的类使用)。当然,也有个 –XX: EnableContented 的配置参数,来控制开启和关闭该注解的功能,默认是 true,如果改为 false,可以减少 Thread 和 ConcurrentHashMap 类的大小
使用缓存行的对齐能够提高效率
Disrupter
使用了缓存行对齐

乱序问题
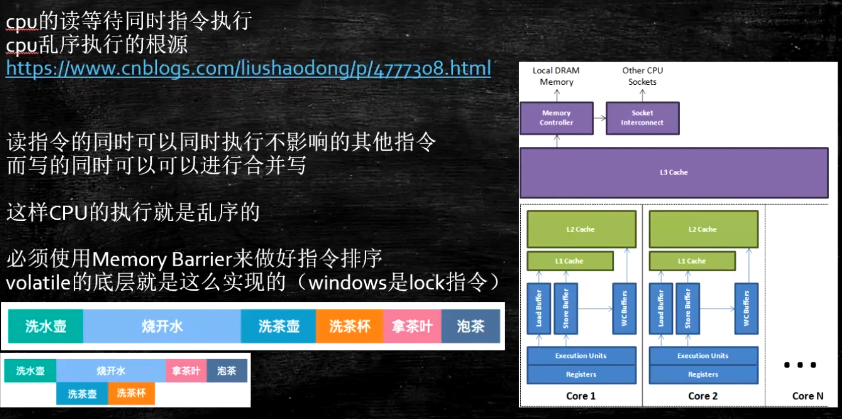
保证有序
volatile 关键字
加锁可以保证一致性,但是效率不够高
内存屏障


如何保证特定情况下不乱序
硬件内存屏障 X86
- sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
- lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
- mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
- 原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。
- Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)(原语级别)
LoadLoad屏障: 对于这样的语句Load1; LoadLoad; Load2
- 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2
- 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2
- 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕
StoreLoad屏障: 对于这样的语句Store1; StoreLoad; Load2
- 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见
volatile的实现细节
字节码层面:ACC_VOLATILE:这是一个标志位
JVM 层面,volatile内存区的读写:都加屏障
- StoreStoreBarrier
- volatile 写操作
- StoreLoadBarrier
- LoadLoadBarrier
- volatile 读操作
- LoadStoreBarrier

OS和硬件层面,hsdis - HotSpot Dis Assembler windows lock 指令实现 | MESI实现
文章地址:https://blog.csdn.net/qq_26222859/article/details/52235930
synchronized实现细节
- 字节码层面 ACC_SYNCHRONIZED monitorenter monitorexit
- JVM层面 C C++ 调用了操作系统提供的同步机制
- OS和硬件层面 X86 : lock cmpxchg / xxx
文章地址:https://blog.csdn.net/21aspnet/article/details/88571740
java并发内存模型
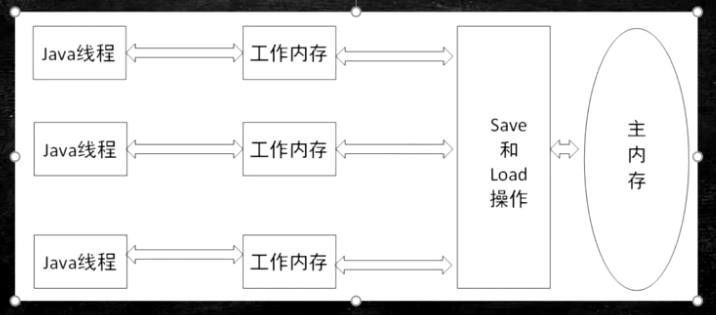
JVM规定的重排序规则
JLS17.4.5

无论如何排序,单线程执行结果不变
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号