慢查询优化
是否向数据库请求了不需要的数据
- 查询求情超过了实际需要的数据,多余的数据会被应用程序丢弃
- 对MySQL服务器增加了网络开销,消耗了应用服务器的CPU和内存资源
常见的错误,MySQL执行查询,查询出全部结果集,客户端应用程序接收全部结果集数据,抛弃大部分数据
- 最简单的处理方式是加limit
拒绝SELECT *,指定字段
避免重复查询相同的数据,对重复的数据进行缓存
MySQL是否在扫描额外的记录
- 响应时间
- 扫描的行数
- 返回的行数
三项指标都会记录到MySQL的慢日志中
响应时间 = 服务时间 + 排队时间
- 服务时间,数据库处理这个查询花了多少时间
- 排队时间,比如IO等待时间和锁的等待时间
扫描的行数和返回的行数,理想情况下扫描的行数和返回的行数相同,但实际比率在 1:1和10:1之间
扫描的行数和返回的类型,使用explain语句,查看访问列和索引等信息
添加一个合适的索引可以有效避免全表扫描
WHERE的使用方式(由好到坏)
- 索引中使用where过滤不匹配的记录,在存储引擎层完成
- 使用索引覆盖扫描返回记录,直接从索引中过滤不需要的记录,在MySQL服务层完成(Extra中出现Using Index)
- 从数据表中返回数据,然后过滤不满足条件的记录,先从表读记录再过滤(Extra中出现Using Where)

重构查询的方式
是否需要将一个复杂查询分解为多个简单查询
切分查询,采用"分治"思想,比如把一个大的DELETE语句拆分为小的DELETE语句

每次删除数据时,稍微暂停一下,可以大大减少删除时对锁的持有时间
分解关联查询

- 让缓存效率更高
- 查询分解后,执行单个查询可以减少锁的竞争
- 在应用层做关联查询,意味着对于某条记录应用只需要查询一次,数据库中做关联,可能重复访问某部分数据,这种重构可以减少网络和内存消耗
- 相当于哈希关联,提高了效率
查询执行的基础
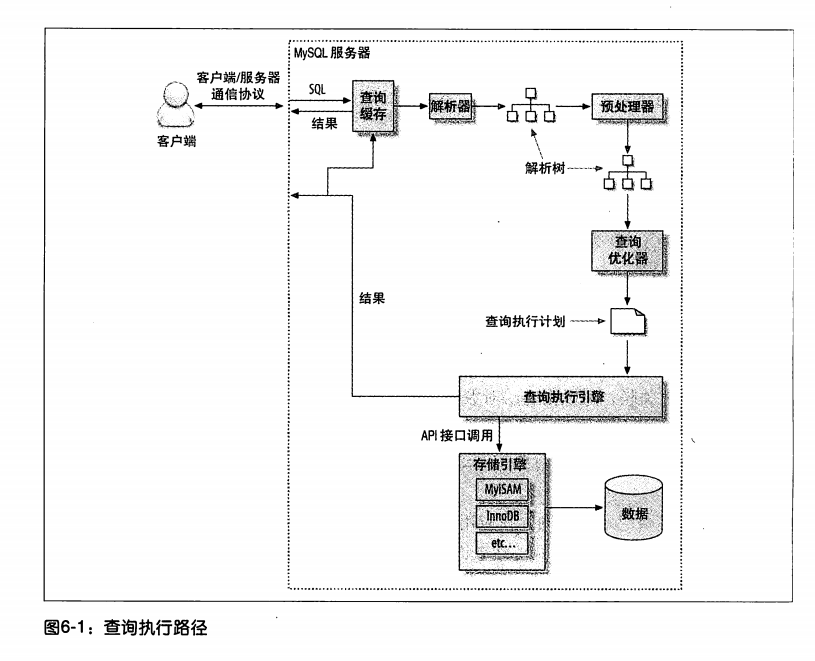
MySQL客户端/服务器通信协议
- 半双工,双向但是不能同时执行,即客户端发送数据以后,只能等待MySQl服务器回应
- max_allowed_packet十分重要
- MySQL库函数,缓存查询结果,取结果的时候是从库函数的缓存中取

查询状态(MySQL连接的查询状态)
- Sleep,线程在等待客户端发送
- Query,线程在执行查询或者将结果发送给客户端
- Locked,该线程在等待表锁,存储引擎级别实现的锁,InnoDB的行锁,不会体现在线程状态中
- Analyzing and statistics,收集存储引擎的统计信息,生成查询的执行计划
- Copying to tmp table[on disk],执行查询过程中,将结果复制到一个临时表中
- Sending data,在多个状态之间传送数据,或者生成结果集或者向客户端返回数据
查询缓存
- 通过对一个大小写敏感的哈希查找实现
- 即使只有一个字节不匹配,也不会匹配缓存结果
语法解析器和预处理
- 通过关键子将SQL语句进行解析,生成一颗对应的"解析树"
- 使用语法规则验证和解析查询
- 验证是否使用错误的关键子
查询优化器
- 通过查询当前会话的Last_query_cost的值来得知MySQL计算的当前查询成本

MySQL能够处理的优化类型
- 重新定义关联表的顺序
- 将外连接转化成内连接,WHERE和库表结构可能会让外连接等价于一个内连接
- 等价变换规则,(a<b AND b=c) AND a=5,改写为 b>5 AND b=c AND a=5
- 优化COUNT(),MIN()和MAX(),索引和列是否围空可以帮助这类优化,例如要找最小值,只需要查询B-Tree索引最左端的记录,MySQL可以直接获取索引的第一行记录
- 预估并转化为常数表达式

- 覆盖索引扫描,索引中的列包含所有查询中需要使用的列,MySQl会返回索引需要的数据,无须查询对应的数据行
- 子查询优化
- 提前终止查询,例如使用LIMIT,使用不成立的条件


- 等值传播,通过等值关联的两个列,能把其中一个列的WHERE条件传递到另一个列上

- IN()的比较,在MySQL中,IN()先排序,然后二分查找,这是一个O(log n)复杂度,等价转换为OR查询复杂度为O(n),所以IN()的速度更快
论读书
睁开眼,书在面前 闭上眼,书在心里
睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号