877 CO 小笔记
补码和移码的关系,求补关系(求补包括符号位要反转)
移码
[x]移 = x + 2n ,n是数据长度

对阶,小对大
算术移位,带符号位移动
逻辑移位,不带符号位移动
DRAM比SRAM集成度低
RISC指令集特点
1. 选取使用频度较高的一些简单指令以及一些很有用但又不复杂的指令,让复杂指令的功能由频度高的简单指令的组合来实现。 2. 指令长度固定,指令格式种类少,寻址方式种类少。 3. 只有取数/存数指令访问存储器,其余指令的操作都在寄存器内完成。 4. CPU中有多个通用寄存器。 5. 采用流水线技术,大部分指令在一个时钟周期内完成。采用超标量和超流水线技术,可使每条指令的平均执行时间小于一个时钟周期。 6. 控制器采用组合逻辑控制,不用微程序控制。 7. 采用优化的编译程序


为什么说计算机系统中硬件、软件在逻辑上功能等效?
软件的功能可以用硬件实现,硬件的功能可以用软件实现
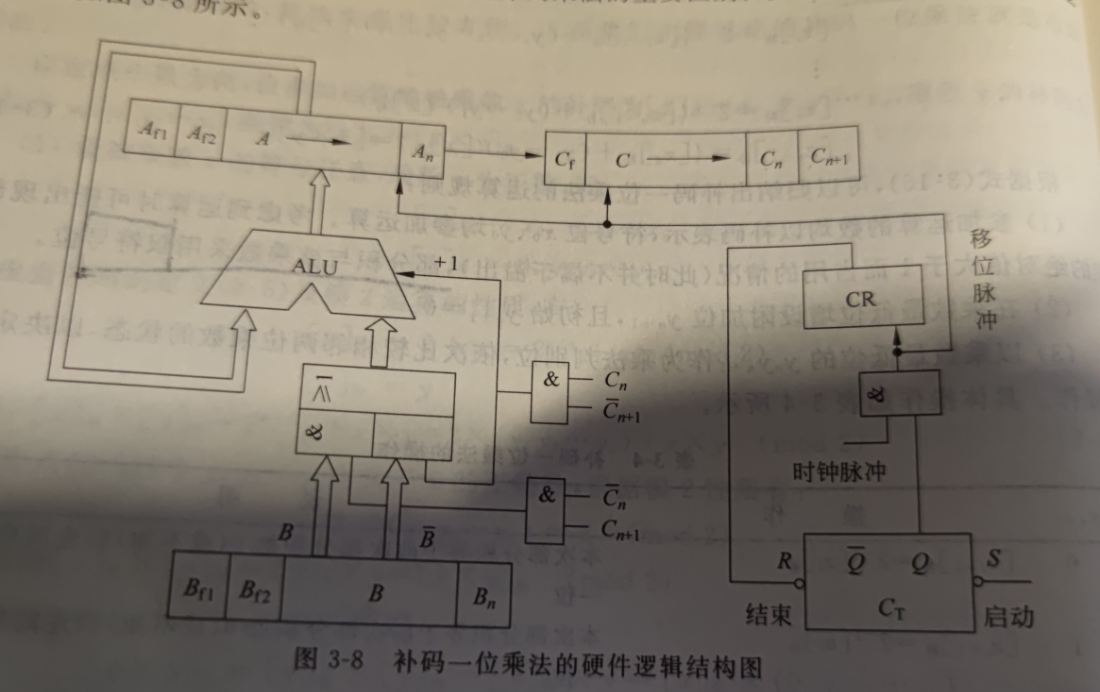
补码一位乘法的规则
- 均以补码表示,符号位参与运算,采用双符号位
- 乘数最低为增设yn+1,且初始为0
- yn和yn+1作为乘法判别位,0 0,部分积+0右移,1 1,部分积+0右移,0 1,部分积+[x]补 右移,1 0, 部分积-[x]补 左移
- 重复n+1次,最后只运算,不作积
通过迭代法可以提高乘法运算速度
CPU响应中断后,中断响应周期内完成的操作
- 关中断
- 保存断点
- 转向中断程序
- 保护现场和屏蔽字
- 开中断
- 执行中断服务程序
- 关中断
组成指令流水线的各功能段执行时间最好是 尽量相等
总线的主、从设备(总线操作的对象)
- 总线的主设备是指获得总线控制权的设备
- 总线的从设备是指只能被主设备访问的设备,只能响应从指设备发来的总线命令


设机器字长为8位,[x]补=10101100,[y]补=01000110,则[x]补-[y]补的运算结果是

多体交叉存储器主要是为了提高存取速度,增加带宽
Cache的功能均由硬件实现
挂接在总线上的多个部件,分时向总线发送数据,同时从总线接收数据
取指周期从内存读出的信息流称为指令,它是从内存流向CPU的
解决存储器在容量、价格和速度三者之间的矛盾
程序局部性原理,是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分
存储系统中Cache-主存层次和主存-辅存层次均采用了程序访问的局部性原理
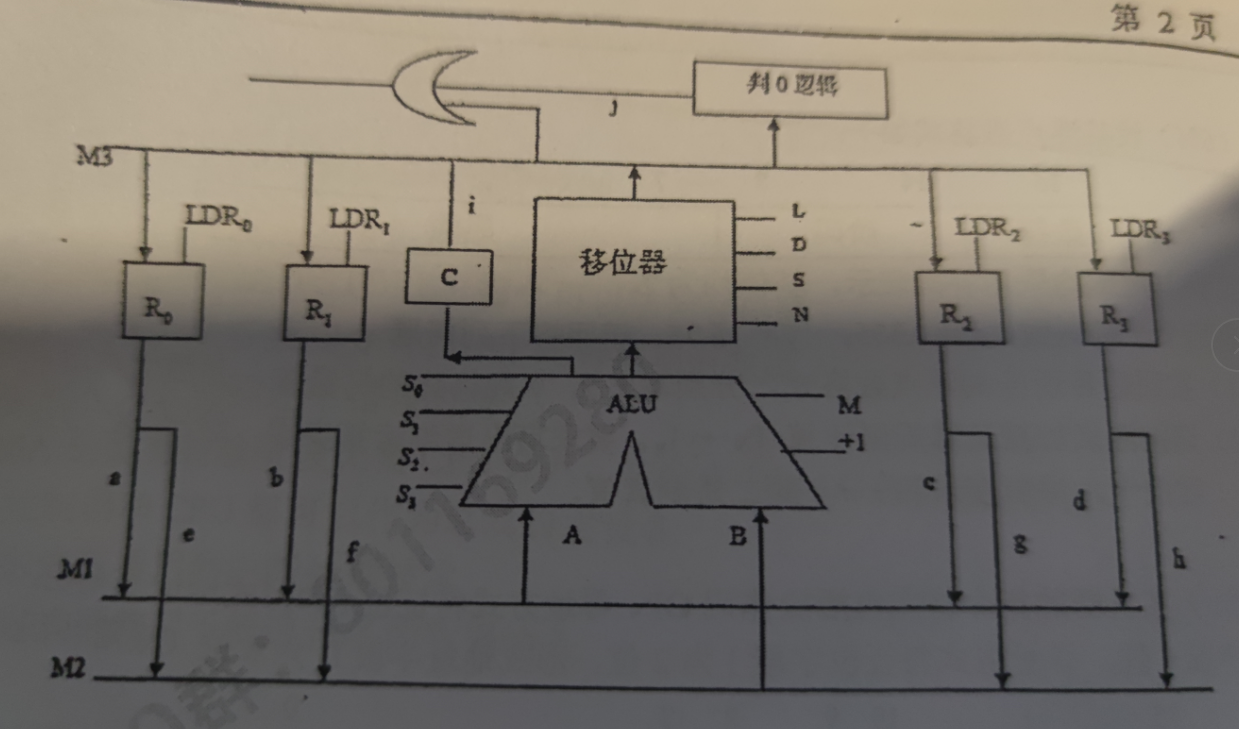
算编码时,ALU观察是信号还是功能,功能则+1<=2^n,信号直接数,寄存器有输入则各算+1<=2^n。移位器编码按字段直接编码功能+1<=2^n
硬布线控制器
- 硬布线控制器是将控制部件做成产生专门固定时序控制信号的逻辑电路,产生各种控制信号,因而又称为组合逻辑控制器
- 这种逻辑电路以使用最少元件和取得最高操作速度为设计目标,因为该逻辑电路由门电路和触发器构成的复杂树型网络,所以称为硬布线控制器
微程序控制器
- 微程序控制器由指令寄存器IR,程序计数器PC,程序状态字寄存器PSW,时序系统,控制存储器CM,微指令寄存器以及微地址形成电路
- 用存储逻辑实现,微操作信号代码化,然后每条机器指令转成一段微程序存入专门的存储器

可以提高乘法运算速度的方法是,先行进位加法和阵列乘法
存储周期,存储器连续启动两次读操作所需间隔的最短时间
Cache是介于主存和CPU之间的高速缓冲存储器,它根本不属于内存,所以Cache不计算进存储系统的容量
寄存器间接寻址,要寻找的操作数位于内存,通用寄存器中保存的是操作数的地址
浮点运算中,结果向右规格化的规则是,尾数向右移一位,阶码加1
Cache-主存系统中,主存任意一块映射到Cache特定块,称为直接映像
Cache-主存系统中,主存任意一块映射到Cache任意块,称为相联映像
微程序控制器的核心部件是存储微程序的 控制存储器;通常由 只读存储器
CPU中主要的寄存器以及主要作用
- 指令寄存器IR,存放当前正在执行的指令。指令从主存取出后,经过MDR传送到IR中
- 程序计数器PC,保证程序按固定序列正确运行,提供将要执行指令的指令地址
- 累加寄存器AC,暂存操作数据和操作结果
- 程序状态寄存器PSW,存放程序的工作状态和指令执行的结果特征
- 地址寄存器MAR,存放所要访问的主存单元地址,接受PC的指令地址,接受来自地址形成部件的操作数地址
- 数据缓冲寄存器MDR,存放向主存写入的信息或从主存读出信息
DMA方式的特点,说明DMA方式能否代替程序中断
- 响应随机请求的方式,实现主存与IO设备间的快速数据传送
- 采用DMA方式,仅需占用系统总线,不切换程序,不存在保护断点,保护现场,恢复现场,恢复断点等操作
- DMA传送的插入不影响CPU程序执行状态,除了访问主存的冲突外,CPU可以继续执行自己的程序,提高CPU利用率
- DMA方式只能处理简单的数据传送,难以识别与处理复杂的情况
- DMA不能处理复杂事态,DMA不能代替程序中断


组合逻辑控制器比微程序控制器执行速度快
动态流水线,允许同一时间内不同功能段组合具有多种功能的流水子线
非线性流水线,有反馈回路,功能段可通过反馈回路多次使用
集中式的总线仲裁方式中,对总线请求响应速度最快的是独立请求方式,链式查询对电路故障最敏感
码距d和要求校验码检错个数e的关系,d >= e + 1
十六进制形式表示的IEEE754标准32位单精度浮点数的规格化最大负数的机器数为

补充:对于32位规格化浮点数,真正的指数值e为-126~+127
Cache三种映射方式

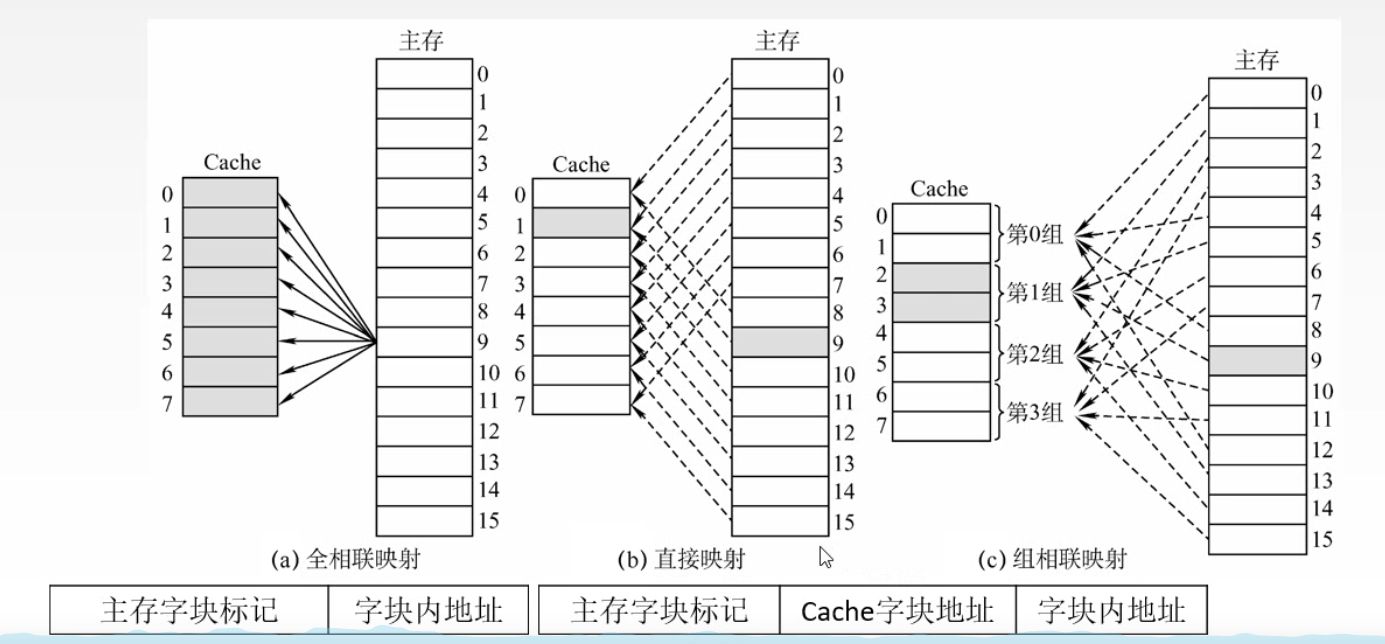
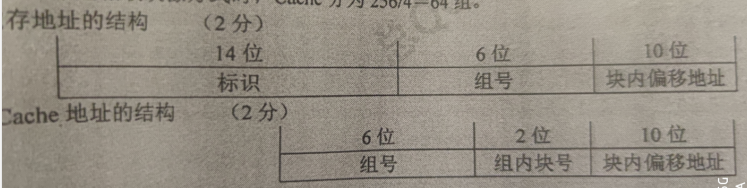
组相联的地址结构


主存的地址结构,每个cache块大小为8B,块内偏移3位;256/8 = 32块,32/4 = 8组,组号3位,64KB= 2^16
去掉组号和块内偏移的6位,剩下10位即内存对应2^10个cache(主存的组内块号)
Cache的地址结构,去掉区号即可
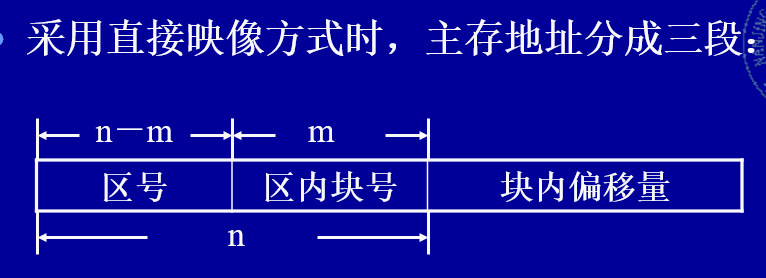

直接映像方式,0E6AH = 0000 1110 0110 1010,区号 00001110,块号 01101010,块内偏移 010,Cache地址编号,01101010 = 6AH
Cache命中率,4000 / (4000 + 300) ≈ 0.93
一个四路组相联(Cache每组内有4个块)的Cache共有64块,主存有8192块,每块32个字,则主存地址中字块标记,组地址,块内地址为多少?
每块32个字,块内偏移5位,64/4 = 16组,组号4位,8192 / 64 = 128,主存容量64KB = 2^16,占16位,剩余7位做主存标识

4路组相联,一组有4个块,一块大小4 * 4B = 16B,8KB / 4*16B = 2^7 = 128,Cache共分为8组
组号占7位,块内偏移占4位,主存标识,16MB = 2^24,占24位,剩余13位做主存标识
按照流水的级别,可以把流水线划分为
- 部件级流水线,运算器流水线
- 处理机级流水线,指令流水线
- 处理机间流水线,宏流水线
某计算机字长32位,其存储容量为256MB,若按单字节编址,它的寻址范围是
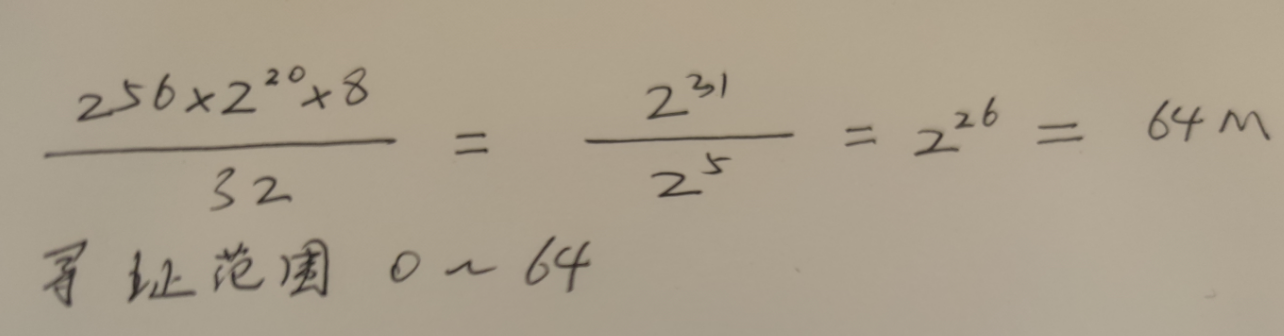
设机器数字长位16位(含1位符号位),若用补码表示定点小数,则最大正数为 1 - 2-15
循环冗余码
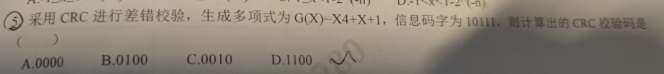
浮点数运算


海明码

某计算机指令字长为16位,指令有双操作数、单操作数和无操作数3种格式,每个操作数字段均有6位二进制表示,该指令系统共有m条(m<16)双操作数指令,并存在无操作数指令。若采用扩展操作码技术,那么最多还可设计出单操作数指令的条数是______。
A.26
B.(24-m)×26-1
C.(24-m)×26
D.(24-m)×(26-1)
双操作数指令操作码字段占4位,单操作数指令操作码字段占10位,无操作数指令操作码字段占16位。现指令系统中有m条双操作数指令,则给单操作数和无操作数指令留下了(24-m)个扩展窗口。因为存在着无操作数指令,所以单操作数指令必须要给无操作数指令留下一个扩展窗口,最终最多可以设计出单操作数指令的数目为(24-m)×26-1。

多重中断的中断服务程序包括
- 保护现场
- 开中断
- 设备服务



控制器的三种控制方式
同步控制方式,任何指令或各个微操作的执行均由具有统一基准时标的时序信号控制
异步控制方式,区分不同指令对应的微操作序列的长短,不再有统一的周期、节拍,各个操作之间采用应答方式衔接,前一操作完成后给出回答信号,启动下一操作
联合控制方式,同步控制和异步控制相结合,功能部件内部进行同步,功能部件之间采用异步
相对寻址

相对寻址,PC当前内容一般为现行指令的下一单元的地址,取指令之后PC的内容2002H,执行指令之后的内容,2002+40=2042H
相对寻址的偏移量可正可负,一般用补码表示,例如,偏移量为8,则寻址范围是 (PC)- 128 到 (PC) + 127
通用寄存器的位数取决于机器的存储字长


动态RAM每ms刷新100次,每次刷新需100ns,一个存储周期需要200ns,异步刷新方式下,刷新占存储器总操作时间百分比是
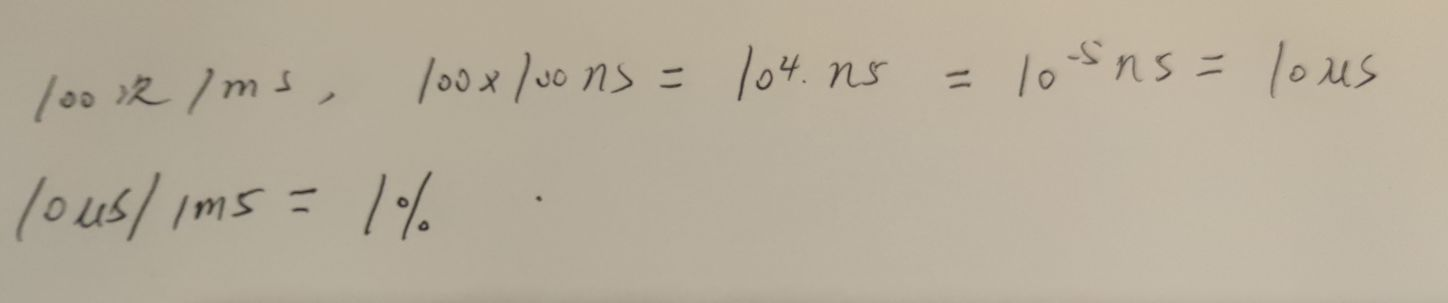
寻址方式按操作数物理位置不同,多使用R-R型号和R-S型,前者比后者运行速度快
R-R型,寄存器-寄存器,比R-S型,寄存器-存储器运行速度快

某一RAM芯片,其容量为1024*8位,不采用地址复用技术,除电源和接地外,连同片选和读/写信号该芯片引脚最小数目
1024=2^10,10根地址线,8位,8根数据线,+ 片选1根和读/写1根,共20根
地址复用,对半开,行列选通


存储器的四种刷新方式
集中刷新,单独拿出2ms做刷新
分散刷新,刷新周期=读写周期
异步刷新,单元刷新时间间隔/行数,然后取存储周期的整数倍
透明刷新,利用取指周期的译码时间,存储器空闲,进行刷新操作

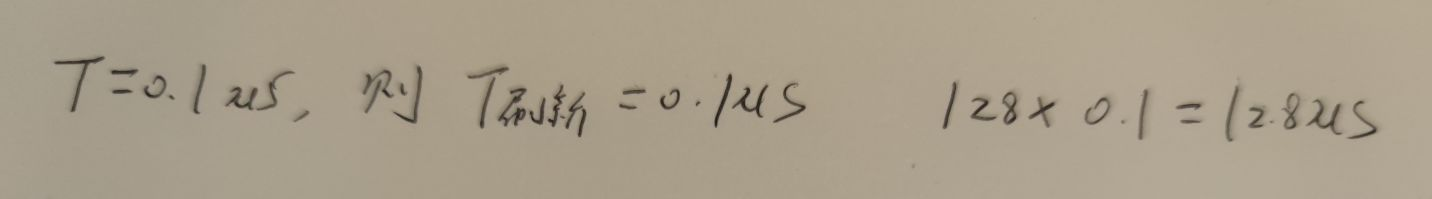


CPU通用寄存器的位数不取决于通用寄存器
中断向量地址:存储中断向量的存储单元地址,中断服务例行程序入口地址的指示器
中断向量:中断服务程序的入口地址
在某些计算机中,中断向量的位置存放一条跳转到中断服务程序入口地址的跳转指令
产生后继微指令地址的方法:下地址,增量计数法,网络测试
整数补码减法 [A]补 - [B]补 = [A-B]补 = [A]补 + [-B]补



动态存储器的刷新通常按行进行
组合逻辑控制器,优点速度快,缺点是设计与实现比较复杂,不易于修改和扩充
微程序控制器,优点设计规整,易于修改和扩充,缺点是速度较慢
IEEE754,单精度浮点数的取值范围

冯诺伊曼思想
计算机由输入设备、输出设备、运算器、存储器和控制器五大部件组成
采用二进制形式表示数据和指令
采用存储程序方式
支持实现程序浮动的寻址方式称为 相对寻址
存放微程序的控制器通常是 ROM
10000000看作原码时真值为 0或-0,看作补码时对应的真值为 -128
变址寄存器寻址方式中,若变址寄存器的内容是4E3CH,给出的偏移量是63H,它对应的有效地址,4E9FH
原码中0有两种不同的表示方法,+0:00000000,-0:10000000
机器字长一定的情况下,单精度浮点数的尾数越多表示的数越精确,阶码决定数的范围
DRAM存储器的集中式刷新、分散式刷新和异步式刷新三种刷新方法,最合理的异步式刷新
在浮点数的加减法运算中,当所求和/差尾数发生溢出时,计算机会置溢出标志但不会做相应的处理
按存取方式对存储器分类,广泛使用的硬盘属于随机存取存储器
对于同步控制方式的控制器来说,任何指令的运行或指令中各个微操作的执行均由确定的具有统一基准时标的时序信号控制
硬盘的存储密度可以用位密度和道密度衡量,因为磁盘每条磁道长度不同,所以位密度也不同

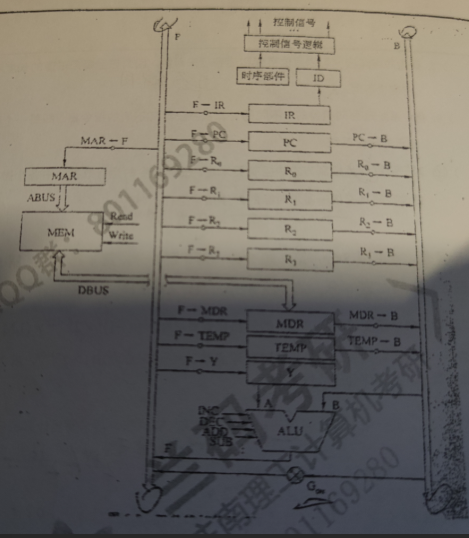
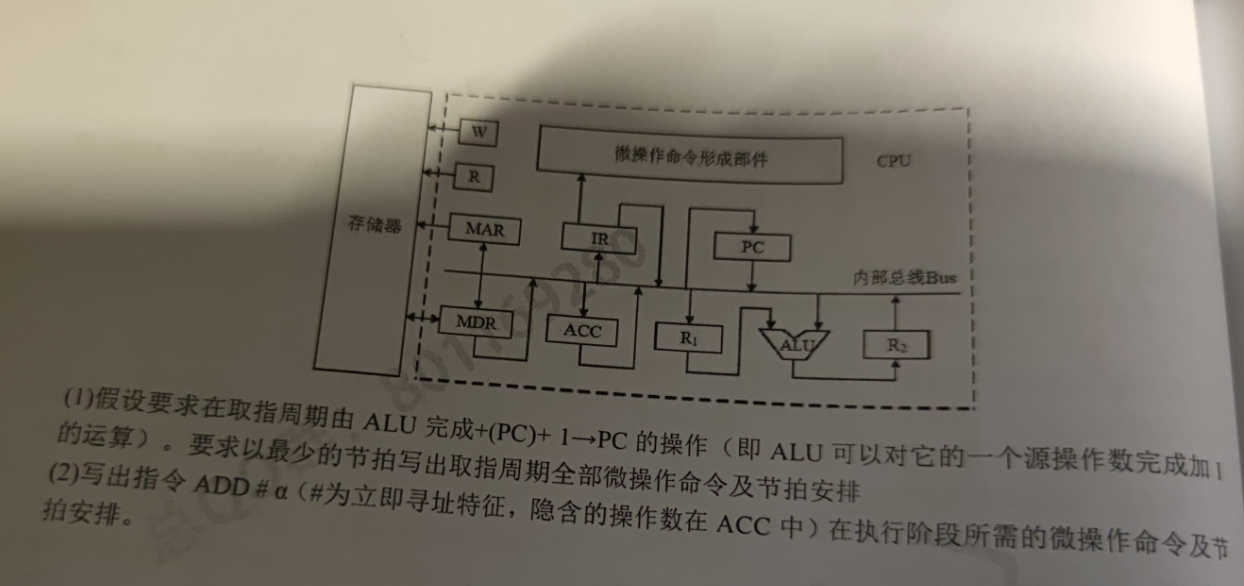
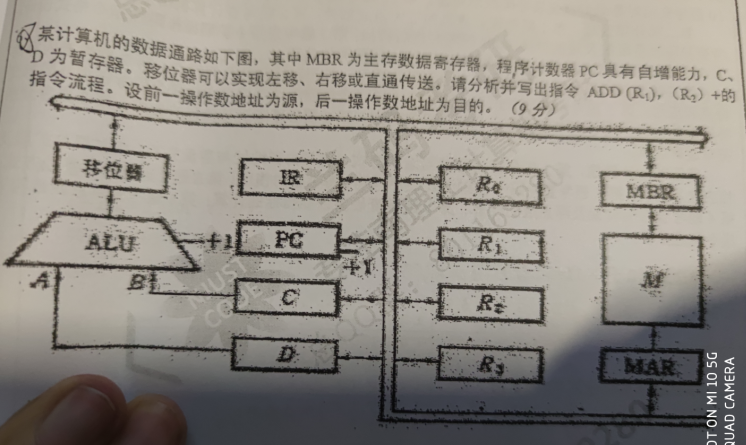
指令流程 控制信号序列
(PC)->MAR,Read PC->B,Gon,F->MAR,Read,F->Y
(PC) + 1 -> PC INC,F->PC
M->MDR->IR MDR->B,Gon,F->IR
(R1)->MAR,Read R1->B,Gon,F->MAR,Read
M->MDR->Y MDR->B,Gon,F->Y
(Y) + (R0)->R0 R0->B,ADD,F->R0
机器字长32位,其中1位符号位,31位表示尾数,用定点小数,最大正小数是 1 - 2^-31
每一条机器指令由一段用微指令编程的微程序来解释执行
某DRAM芯片,其存储容量位512K*8位,该芯片的地址线和数据线数目是 512K=2^19,所以19根地址线,8位就是8根数据线
单地址指令中为了完成两个数的算术运算,除地址码指明的一个操作数外,另一个数常需采用隐含寻址方式
程序控制类指令的功能是改变程序执行的顺序
CPU和通用寄存器的长度是由机器字长决定
机器字长:CPU一次能处理数据的位数,通常与CPU的寄存器位数有关。
存储字长:存储器中一个存储单元(存储地址)所存储的二进制代码的位数,即存储器中的MDR的位数。
指令字长:计算机指令字的位数。
数据字长:计算机数据存储所占用的位数。
设某机字长为32位,CPU有32个32位通用寄存器,有8种寻址方式,包括直接寻址、间接寻址、立即寻址、变址寻址等,采用R-S型单字长指令格式,共有120条指令
试问该机直接寻址的最大存储空间为多少?
在32位地址中,由于指令条数为120条,所以用于指令操作码至少为7位,由于具有32个通用寄存器,需要用5位对寄存器编号
指令为R-S型指令,第一操作数只能为寄存器直接寻址,无需表明寻址方式,而第二操作数有8种寻址方式,需要用3位表示具体的寻址方式
所以,该机直接寻址的最大存储空间为2^(32-7-5-3)=2^17=128K
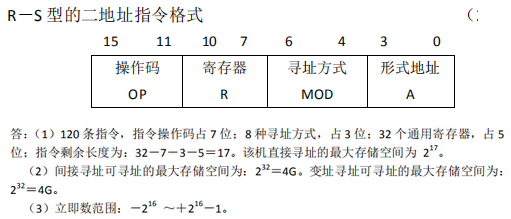
若用64K*4位的DRAM芯片组成该存储器,则需多少芯片?2^22*16/2^16*4 = 256
在该存储器的22位地址中,16位用于片内寻址,6位用于选片寻址
若采用一级间接寻址,则可寻址的最大存储空间为多少?如果采用变址寻址呢?
如果采用一级间接寻址,则可寻址的最大存储空间为2^32=4G,用变址寻址也一样
若立即数为带符号的补码整数,试写出立即数范围,立即数为17位的补码,-2^16 ~ 2^16 - 1(符号占一位)
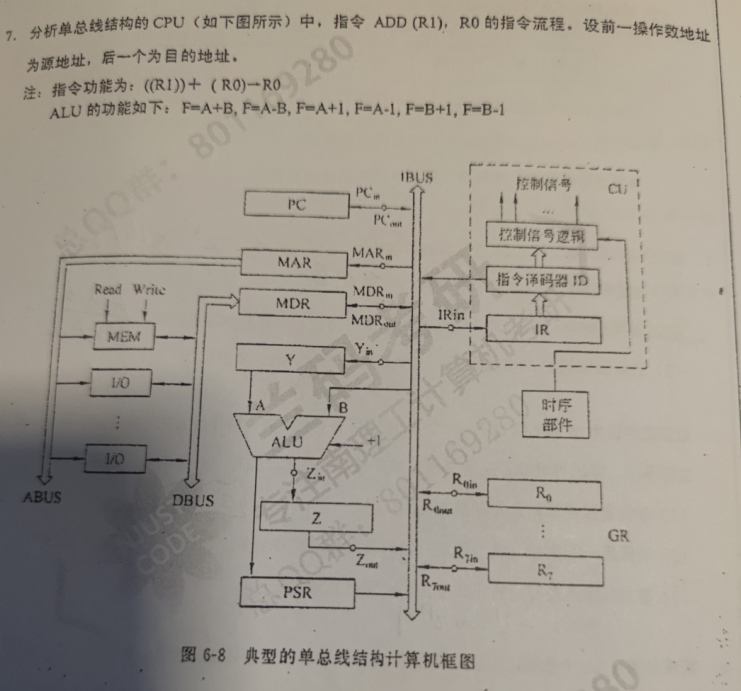
指令流程 控制信号序列
(PC)->MAR,Read PC->PCout->1BUS->MARin,F->MAR,MAR->ABUS,Read,PC->Y
(PC) + 1 -> PC (Y) + 1 -> Zin->Z,(Z)->Zout->1BUS->PC
M->MDR->IR MDR->MDRout->1BUS->IRin->IR
(R1)->MAR,Read R1->B,Gon,F->MAR,Read
M->MDR->Y MDR->B,Gon,F->Y
(Y) + (R0)->Z R0->B,ADD,F->R0
(Z)->R0
在浮点数的表示中,用移码表示阶码的好处是能提高运算精度

微程序通常存放在CPU的控制寄存器中
在浮点运算时,当尾数绝对值大于1时,右规
为了减少指令中的地址个数,有效的办法是采用 隐地址
同步控制由统一时序信号控制的方式
相对寻址中,若偏移量为8,则寻址范围是 -128~(PC) + 127
冯诺伊曼设计原则,硬件是由 输入设备、输出设备、存储器、运算器、控制器






从缩短程序长度、编程方便、提高操作并行性方面看,三地址指令最优
从缩短指令长度、减少访存次数、简化硬件设计等方面看,一地址指令较好
小微型计算机指令字长较短,广泛用二地址指令和一地址指令
三地址和多地址指令,功能强,便于编程,多用于指令字长较大的大、中型机使用
定长编码,所有指令操作码长度一致,集中位于指令字的固定字段,指令译码简单,有利于简化硬件设计
变长编码,有效压缩指令操作码的平均长度,便于用较短指令字长表示更多的操作类型,寻址更大的存储空间,指令译码与分析难度增加,使硬件设计复杂化
某计算机指令字长为16位,其中操作码OP,第一地址A1,第二地址A2,第三地址A3各占4位,采用了扩展操作码技术,最多可设计出 16 条指令
操作码占4位,所以 2^4 - 1 = 15,最后一条指令的形式是 1110 A1A2A3
无论X是整数还是负数,对其补码进行求补运算,其结果均为 -X 的补码
分段编码方式中,互斥指令划分在同一字段,相容指令划分在不同字段
对二进制串取反,可以用1进行异或
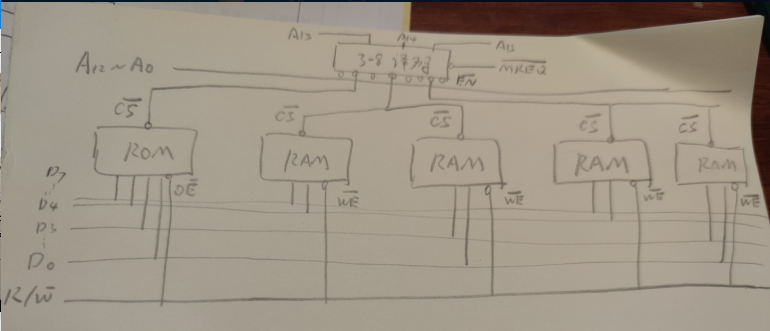
地址总线A15~A0,数据总线D7~D0, 存储器地址空间为 4000H~6FFFFH,按字节编址,其中4000H~5FFFH为ROM区,选用EPROM芯片(4K * 8bit)
6000H ~ 6FFFH,为RAM区,选用SRAM(2K * 4bit)
4000H~5FFFH,为ROM区,为2^13=8KB,8KB / 4K * 8 b = 2,所以需要2片EPROM
6000H~6FFFH,为RAM区,为2^12 = 4KB,4KB / 2K * 4b = 4,所以需要4片SRAM
EPROM,应该连入A12 ~ A0,进行片内寻址,SRAM应该连入A11 ~ A0
EPROM,连入A15~A14片选,选片信号,EPROM1为01选中,EPROM2为11选中
1片SRAM4位,数据总线8根,有8位,所以需要进行位扩展,4片SRAM芯片位扩展后分为2组,选片信号位 第一组:A15~A12 为1100选中,A15~A11为1101选中
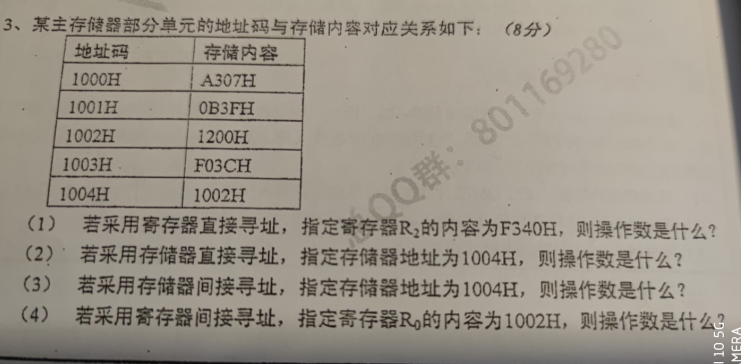
寄存器直接寻址,F340,存储器直接寻址,1004H对应1002H,存储器间接寻址1004H对应1002H对应1200H,寄存器间接寻址,1002H对应1200H
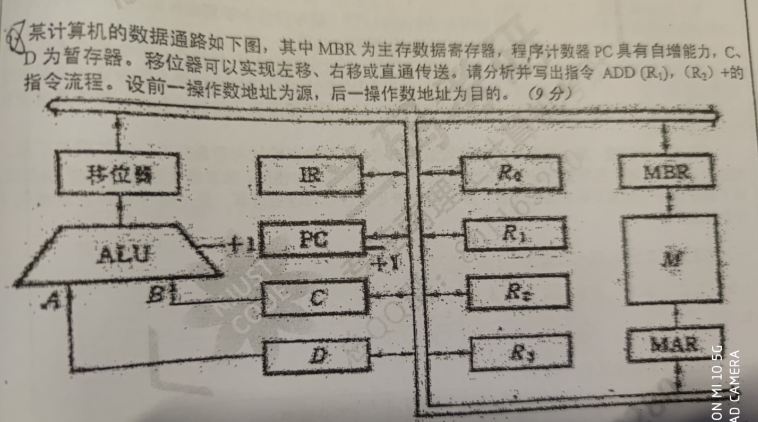
指令流程
(PC)->MAR,Read
(PC) + 1 -> PC
M->MBR->IR
(R1)->MAR,Read
M->MBR->C
(R2)->MAR,Read
M->MBR->D
(C) + (D)->MBR,write
(R2)->C,C+1->R2
CPU对不可屏蔽中断必须响应
每一条机器指令由一段微指令编成的微程序来解释执行
某一RAM芯片,其容量为1024*8位,若不采用地址复位技术,除电源端和接地端之外,连同片选和读/写信号该芯片引脚的最小数目为
1024=2^10,地址线10根,8位,数据线8根,片选1根,读/写1根,一共20根
CPU从主存取出一条指令并执行该指令的所有时间称为指令周期
CPU主要包括 控制器、运算器、cache

每道存储容量 = 内层位密度 * 内层周长 = 52400*Π2.36 = 48563B
盘组总存储容量 = 每盘记录面 * 每面容量 = 10*2*0.075 = 1.5GB
每面容量 = 道数 * 每道容量 = 1650 * 48563 = 0.075GB
道数 = 道密度 * (外直径 - 内直径)/ 2 = 1250 * (5-2.36)/ 2 = 1650 道
数据传输率 = 一道容量 * 一秒的转数 = 48563*(2400/60) = 1.85MB/S
磁道数 1650,需要11位,盘面数 22,需要5位,扇区数=48563B/2KB = 24,需要5位,一共需要11+5+5 = 21位
应该记录在同一柱面上
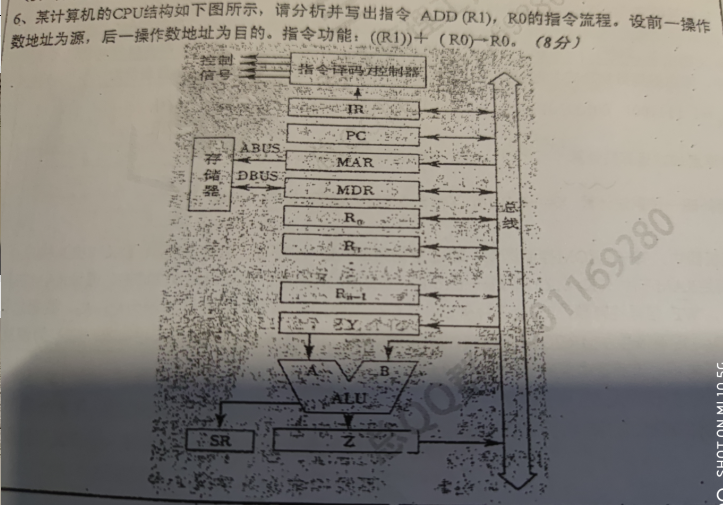
指令流程
(PC)->MAR,Read
(PC) + 1 -> PC
M->MDR->IR
(R1)->MAR,Read
M->MDR->Y
(Y) -> A
(R0) -> B
(A) + (B) -> Z
(Z)->R0
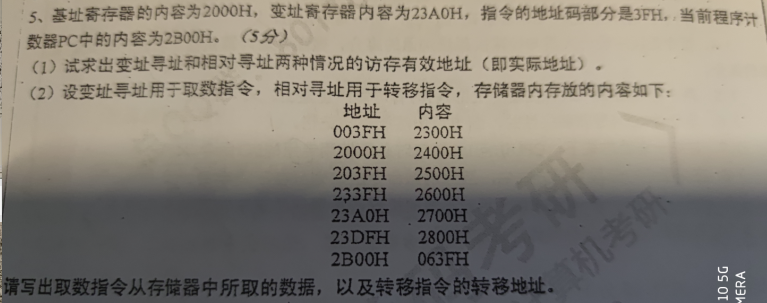
变址寻址,变址寄存器,23A0H,23A0H + 3FH = 23DFH
相对寻址,PC当前内容,2B00H,2B00H + 3FH = 2B3FH
变址寻址用于取数指令,23DFH取的是2800H,相对寻址转移指令,条件转移指令为 JNZ 40H,则相对寻址天转到 PC + 40H = 2B40H
若采用直接寻址,存储器取出的是地址 003FH对应的2300H

0000H~1FFFH,2^13 = 8KB,8K * 8/ 8K * 8 = 1,ROM芯片需要1片
RAM区域,16K * 8 / 8K * 4 = 4,RAM芯片需要4片
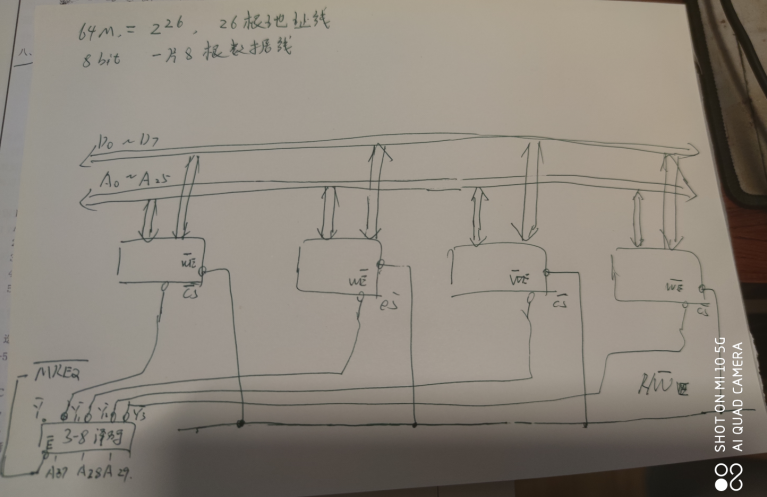
画图题的端口字母意义
- CS,片选
- 控制读写 #WE /#OE#WE
单信号控制读写 #WE(低电平写,高电平读)双信号控制读写 #OE(允许读) #WE(允许写)- 访存控制信号MREQ,直接连接到译码器的其中一个低电平选通端
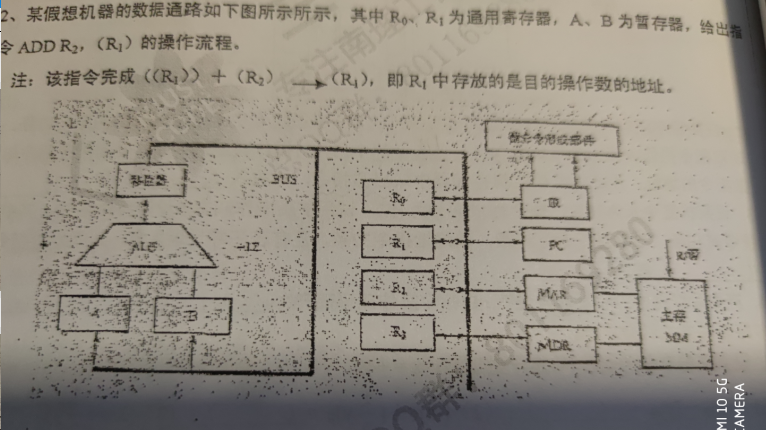
(PC)->MAR, Read
M->MDR->IR
(PC) + 1 -> PC
(R1)->MAR,Read,
M->MDR->A
(R2)->B
(A) + (B)->MDR, write
更新磁盘上全部数据的重要题目!



2^24 * 16 = 2^28 bit = 2^25B = 32MB
32MB / 64K * 4 bit = 2^28 / 2^18 = 2^10 = 1024 片
16位用来片内寻址,剩余8位用来选片寻址
补码的判断是否是规格化的方法,数符和尾数最高位是否相异
寄存器间接寻址,要寻找的操作数在主存中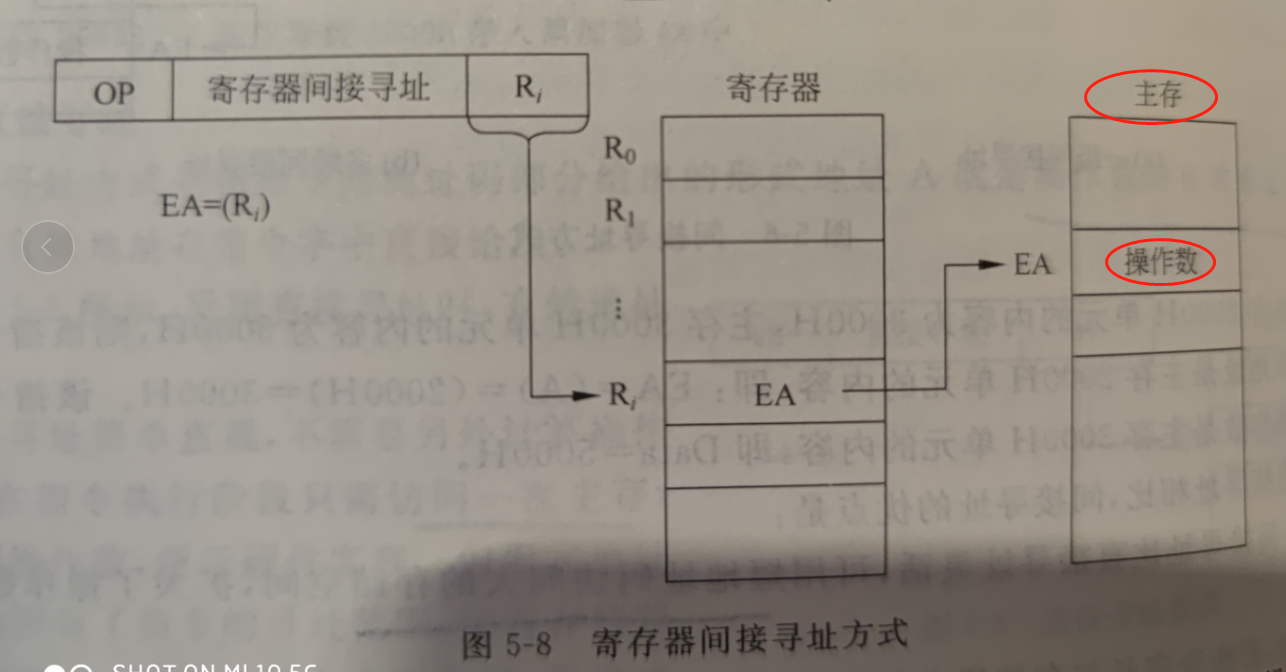
中断屏蔽的作用,是暂时禁止某些中断源向CPU提出中断请求
MIPS,million Instructions per second,每秒执行几百万
MFLOPS,million Float-point operations per second,每秒执行几百万浮点
主机字长32位,变址寻址,现变址寄存器Rx的值 12340000H,16位形式地址的值为 ABE9H,采用补码表示,操作数有效地址为 1234ABE9H
计算机使用总线结构的主要优点足便于实现积木化,其缺点是( )。
A.地址信息、数据信息和控制信息不能同时出现
B.地址信息与数据信息不能同时出现
C.两种信息源的代码在总线中不能同时传送
D.前面都不正确
中断响应周期中,CPU完成的操作顺序是:关中断,保存断点地址,和程序状态字,转入中断服务器程序入口
DMA方式可以用于控制主机和高速外设之间的信息传送,但不能代替中断传送方式
硬件和软件逻辑上等价是指,原理上,软件的功能可以由硬件或固件实现,硬件的功能可以用软件模拟完成,但是两者性价比和难易度不同
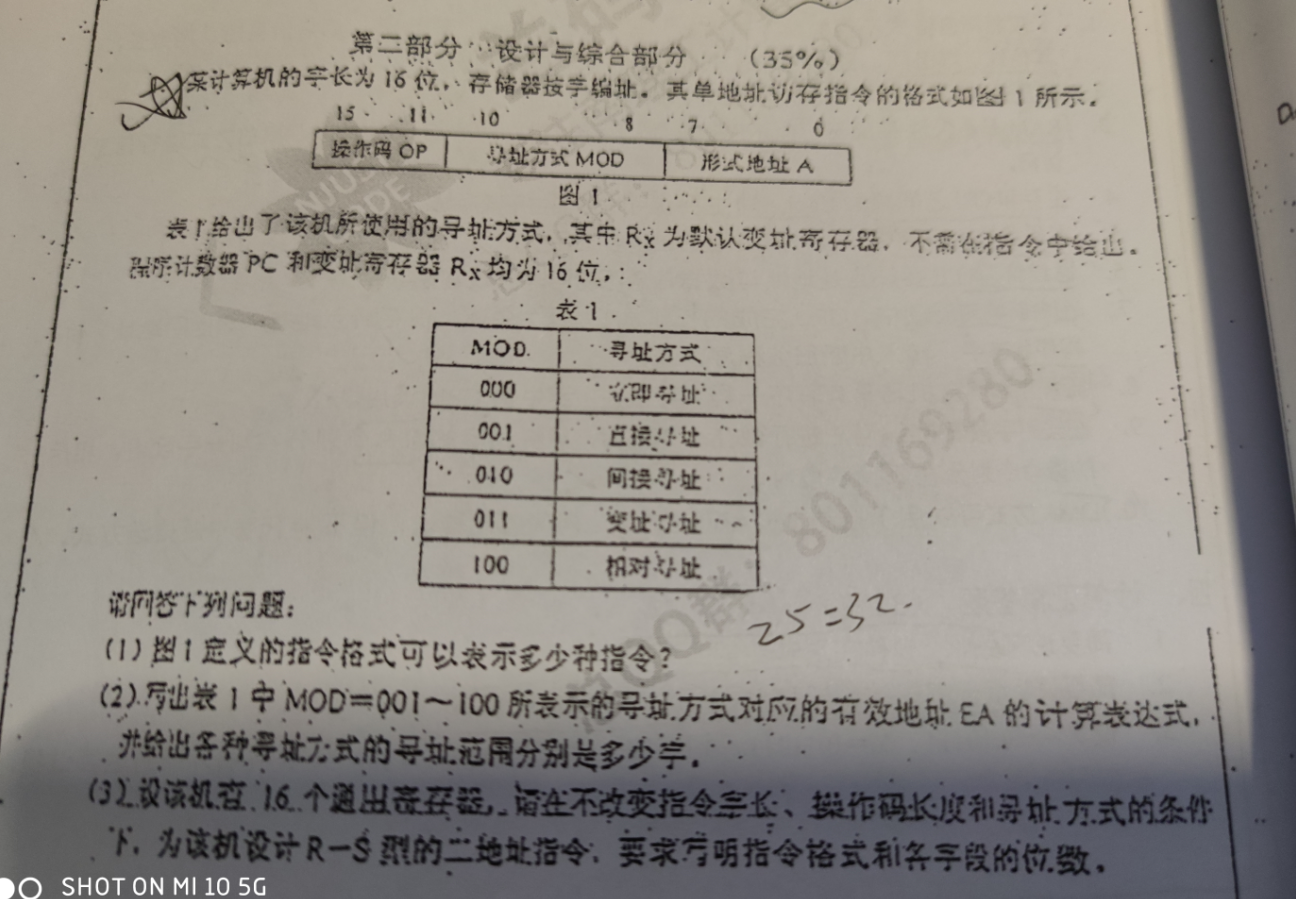
OP一共5位,2^5 = 32 种指令
- 001,直接寻址,EA = A
- 010,间接寻址,EA = (A)
- 011,变址寻址,EA = (Rx) + A
- 100,相对寻址,EA = (PC) + A
机器字长16位,存储器按字编址,8位的形式地址,直接寻址的可寻址范围是 2^8 个字
间接寻址的范围是 2^8 * 2^8 = 2^16 个字
相对寻址是PC附近的(+-)2^8个地址,故寻址范围是 2^8 个字
变址寻址原理类似于相对寻址,变址寻址的范围由Rx的位数决定,这个位数是由用户设定的
- 5位OP
- 源操作数分为寄存器和寻址方式,分别占4位和3位
- 目的操作数分为寻址方式和地址,寻址方式有3位,地址只剩下1位
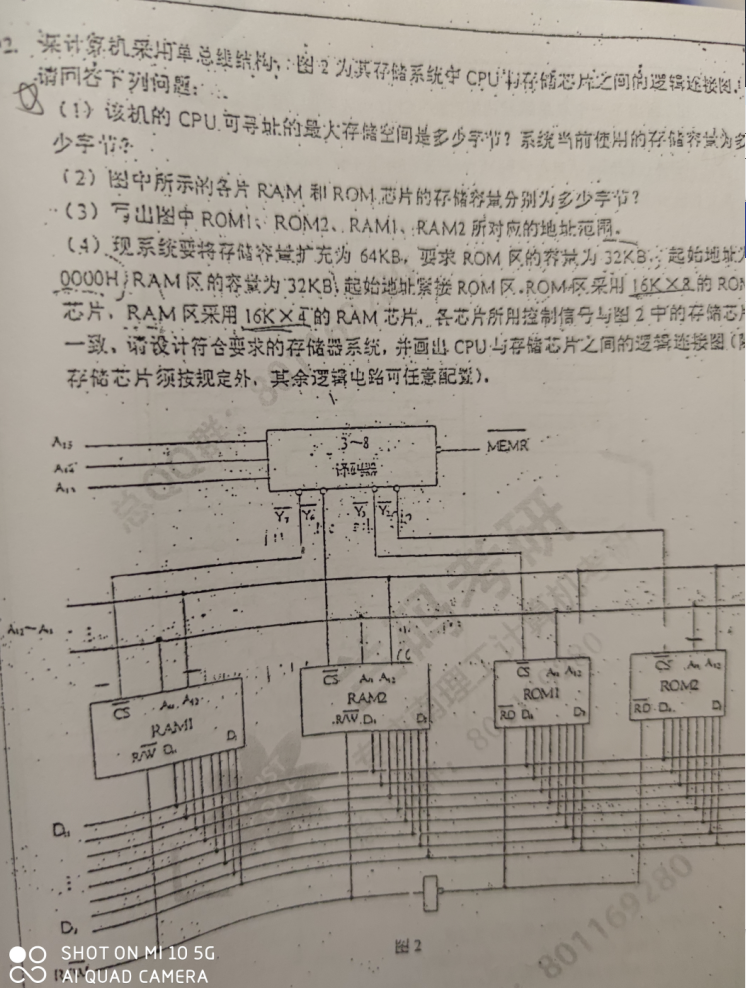
一共16根地址线,8根数据线,存储空间 2^16 * 8 bit
每个芯片13根地址线,8根数据线,2^13 * 8 bit = 8KB,一共4个芯片,所以一共32KB
RAM的存储容量,8KB,ROM的存储容量,8KB


(PC)->MAR,Read
(PC)->Y,(Y)+1->PC
(M)->MDR->IR
(SP)->Y,(Y) - 1 -> SP,(Y) - 1 -> MAR
(PC)->MDR,Write
(Y) + (IR) -> PC (IR里面的内容就是D)
PC+1后送入堆栈,栈顶为2FFFH
JSR需访问存储器 2 次
互斥信号放一组,相容信号分开来
- ALU,有6个功能,所以需要3位
- B总线,IR->B,PC->B,MDR->B,R0~R3->B,SP->B,TEMP->B,有9个功能,需要4位
- F到11个寄存器的输入,4位
一共11位
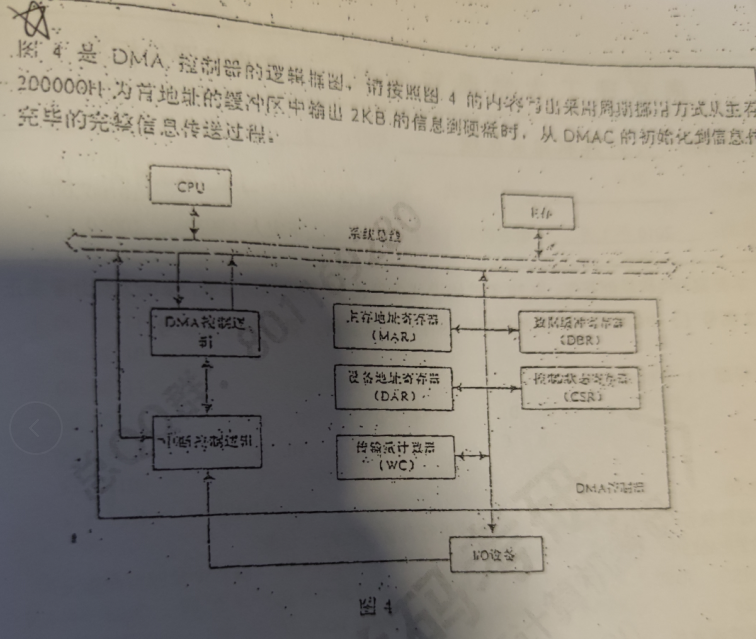
初始化阶段
- CSR->PM,控制字送DMA控制器
- 200000H->MAR->MBR,预置数据在缓冲区首地址
- 置DAR外设的地址
- 2KB->WC,传送数据位2KB
传送阶段
外设准备好一次数据传送后,DMA接口向主机发送DMA请求,CPU执行完成当前存取周期后,响应DMA请求,将总线权限让给DMA控制器,DMA控制器控制源和目的端口,传送数据
外设向CPU发出DMA请求时,CPU将在当前总线周期结束予以响应
CPU通常在当前机器周期结束时响应DMA提出的总线请求
连接在字节多路通道上的多个设备可以同时进行数据传输操作
存储器系统采用多级层次结构的目的是 解决存储器容量、速度与价格之间的矛盾
采用微程序控制的控制器,微程序存放在控制存储器中
CPU进入中断响应周期后第一步要完成的操作是关中断
在集中式串行仲裁和集中式并行仲裁两种总线仲裁方式中,对电路故障最敏感的是集中式串行仲裁方式
光调制器件

电光器件

CRT显示器是一种使用阴极射线管(CathodeRayTube)的显示器
液晶显示器是一种借助于薄膜晶体管(TFT)驱动的有源矩阵液晶显示器,它主要是以电流刺激液晶分子产生点、线、面配合背部灯管构成画面。IPS、TFT、SLCD都属于LCD的子类。
布斯除法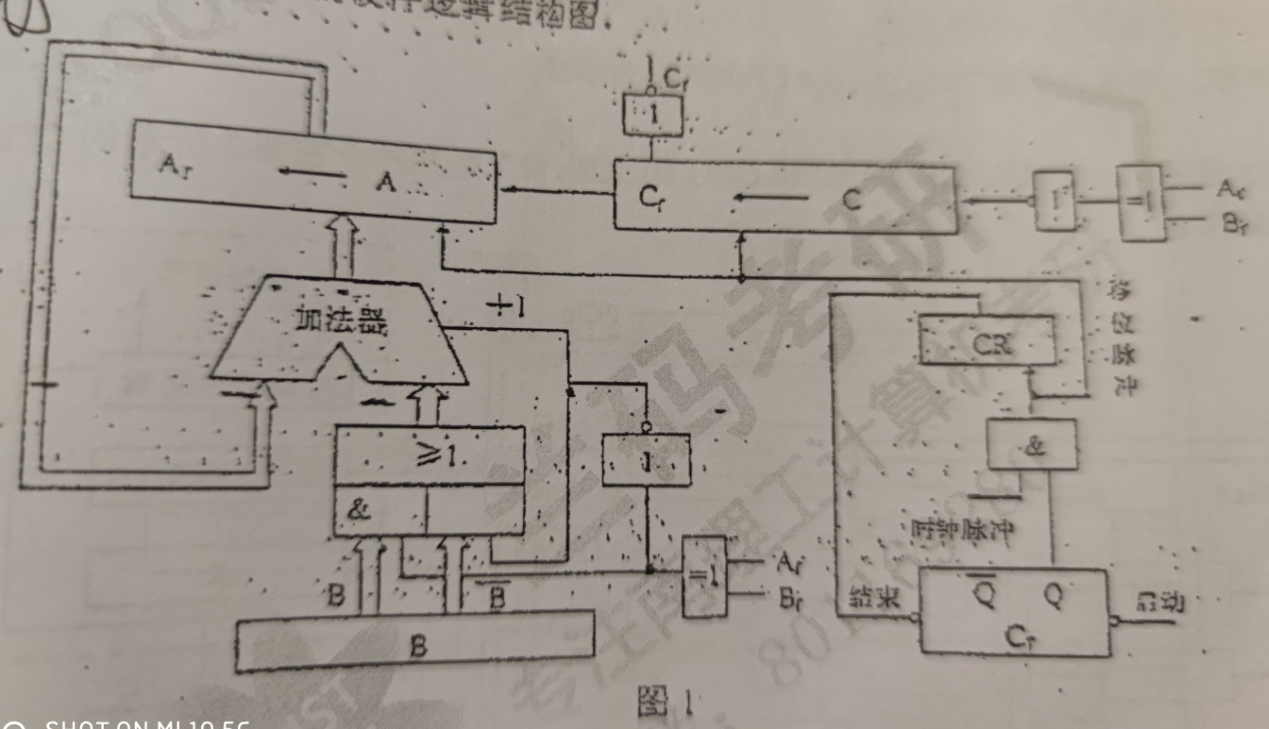
寄存器A存放被除数,B存放除数,C初始值为0;除法计算结束后,A存放余数,B存放除数,C存放商
Af 被除数的符号,Bf 除数的符号
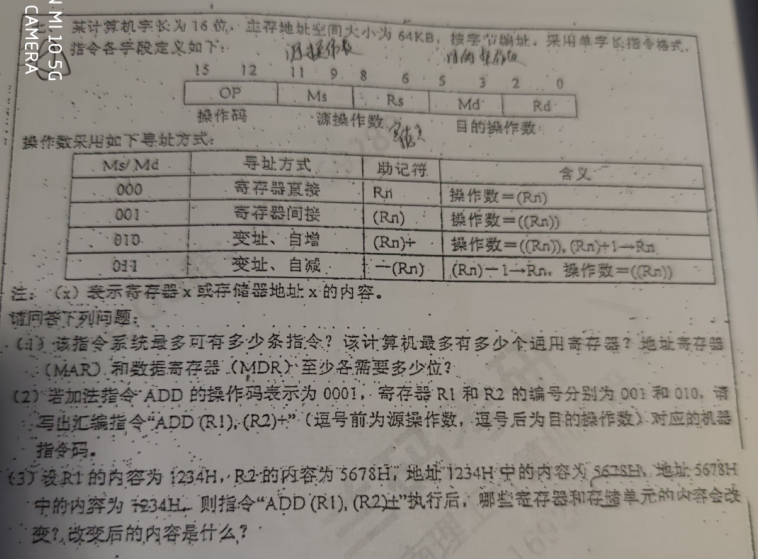
OP一共4位,2^4 = 16条指令 Rs一共3位,2^3 = 8 个通用寄存器,MDR和MAR至少各需要16位,因为字长16位
0001 001 001 010 010 = 1252H
R2自增,5678H更新为5679H;内存 5679H,5678H单元两个字节单元的内容变为加法指令计算得到的值 5678H + 1234H = 68ACH
PC提供指令在内存中的地址,并保存下一条将要执行的指令地址
主机与设备传送数据时,采用中断方式,主机与设备是串行工作的
微程序控制器所产生的所有控制信号称为微指令
DMA传送方式是实现内存与外设之间信息高速传送的一种方式
在CPU中跟踪指令后继地址的寄存器是 程序计数器
动态RAM依靠电容电荷存储信息
指令系统中采用不同寻址方式的目的主要是 缩短指令长度,扩大寻址空间,提高编程灵活性

地址码占6位,则有两个地址码,一个OP码占4位 OP(4位) A1(6位) A2(6位)
15条二地址指令,则留下一位给1地址指令,2^6 = 64,因为没有零地址,所以不用留下一位给零地址,最多可以有64条一地址指令
半导体存储器采用随机存取方式
-0的8位二进制补码 00000000

300FH,相对寻址,PC + 2 = 3012H,3012H - 3004H = 13D(十进制), -13D = 1000 1101,取补码为 1111 0011 = F3H
程序控制类指令主要包括转移指令,循环控制指令,子程序调用与返回指令,中断指令
半导体存储器芯片内部组织一般有字片式(一维译码)和位片式(二维译码)结构,其中位片式结构可以减少译码驱动电路的数量

- ROM区,4KB,EPROM 4K*4bit/片,4KB / 4K * 4 bit = 2片
- RAM区5KB,SRAM 4K * 8bit/片 和 1K * 4bit/片,RAM区分为4KB和1KB,4KB / 4K * 8bit = 1片,1KB / 1K * 4bit = 2片
- EPROM,4KB = 2^12B,EPROM = 0000H ~ 0FFFH,SRAM 4KB = 2^12B,1000H ~ 1FFFH,SRAM 1KB = 2^10,2000H ~ 23FF
- 地址线已经占用了14位,剩余2位做片选,EPROM 00 SRAM1 01 SRAM2 10
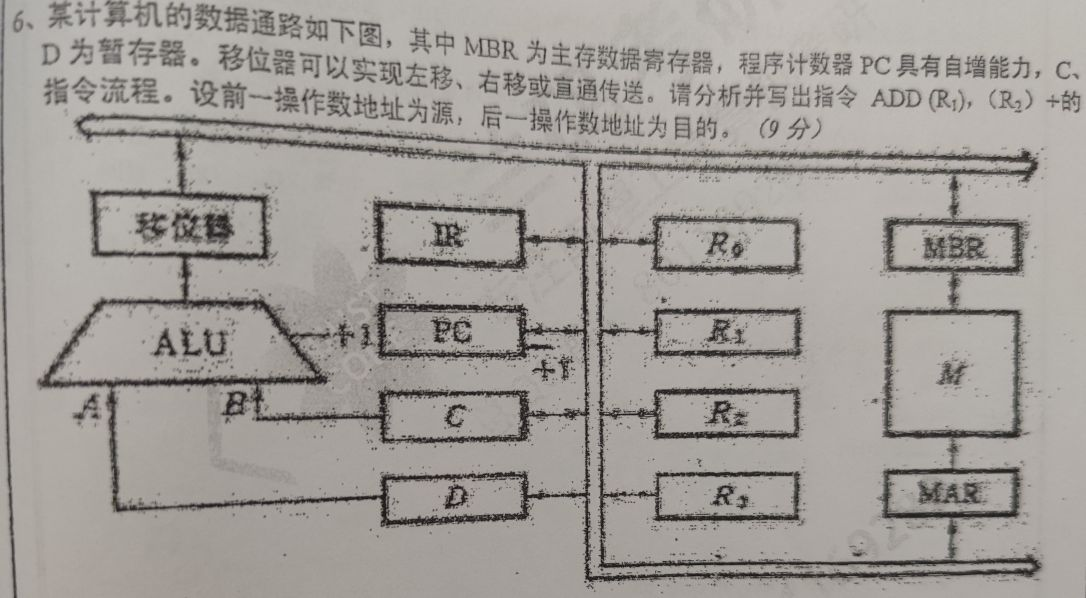
(PC)->MAR,Read
(PC)->C,(C) + 1->PC
(M)->MBR->IR
(R1)->MAR,Read
(M)->MBR->C
(R2) ->D,(D) + 1->R2
(R2)->MAR,Read
(M)->MBR->D决定计算机运算精度的主要技术指标是计算机的字长
冯诺伊曼计算机中,指令和数据均后二进制形式存放在存储器中,CPU区分他们的依据是指令周期的不同阶段
采用变形补码进行加减运算时,运算结果中两个符号位相异,则表示运算发生了溢出
EPROM,DRAM,SRAM和EEPROM,需要定时刷新的存储芯片是 DRAM
对于IEEE754标准,32位单精度浮点数N,若E=255,且M=0,则N= (-1)^s * ∞
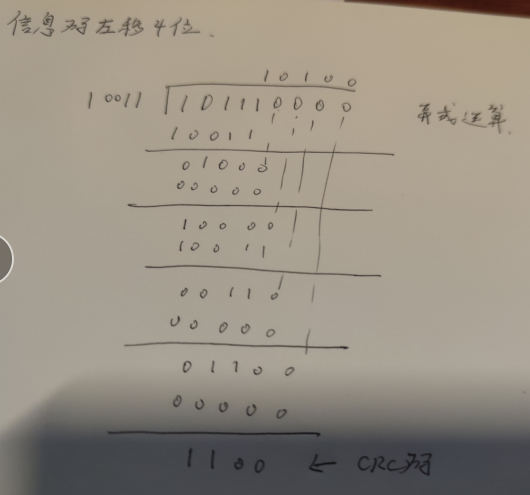
采用CRC校验时,若CRC校验码中发生错误,在与生成多项式G(x)作模2除时了,会使余数 不为0
在进行DMA传送之前,CPU必须先根据传送要求对DMA进行初始化操作
在同一时间内只能以一种方式工作的流水线称为 静态流水线
零地址算数运算指令中,采用堆栈寻址方式进行操作数寻址(指令所需操作数约定隐含在堆栈中,结果也写回堆栈)
0具有唯一表示的方法,移码和补码
大端模式,是指数据的高字节保存在内存的低地址中
小端模式,是指数据的高字节保存在内存的高地址中
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符.标准 ASCII 码也叫基础ASCII码,使用 7 位二进制数来表示所有的大写和小写字母,数字 0 到 9、标点符号,以及在美式英语中使用的特殊控制字符

一个字符,一个字节,4在从低到高的第2个字符,所以在第1位,内存单元的地址是 1001H
寄存器传送指令完成的是寄存器之间的数据传送
CPU执行条件转移指令时,通常根据PSR的内容来判断是否实现转移
- 硬件中断:外设发出的中断请求,如:键盘中断、打印机中断、定时器中断等。外部中断是可以屏蔽的中断,也就是说,利用中断控制器可以屏蔽这些外部设备的中断请求。
- 硬件出错(如突然掉电、奇偶校验错等)或运算出错(除数为零、运算溢出、单步中断等)所引起的中断。内部中断是不可屏蔽的中断。
- 软件中断其实并不是真正的中断,它们只是可被调用执行的一般程序软件中断:其实并不是真正的中断,它们只是可被调用执行的一般程序。
- 例如:ROM BIOS中的各种外部设备管理中断服务程序(键盘管理中断、显示器管理中断、打印机管理 中断等,)以及DOS的系统功能调用(INT 21H)等都是软件中断

- 16位的数据缓冲器,采用中断方式进行IO操作,2B进行一次中断,中断请求的时间间隔为:2B / 20kBps = 1/10k = 1 / 10000 s = 100us
- 中断响应加中断服务的执行时间为:500 / 500M s = 1us
- 中断响应时间相对于中断服务程序的执行时间很短,整个中断响应加中断服务的时间约为 1us,远远小于中断请求的时间间隔,可以用中断方式进行该外设的输入输出
- 最大数据传输率改为20MBps,2B / 20MBps = 1us,整个中断响应加中断服务的时间约为1us,一次中断处理未完,新的中断请求就来到,不可以用中断方式控制该设备进行IO
- 设备的最大数据传输率为20Mps,最好才哦那个DMA方式及逆行输入输出

至少能容纳8*2^8 = 2^11 = 2048条微指令
下地址字段至少需要11位
机器指令与所对应的微程序初始地址之间的对应关系,可以采用一级功能转移的方法,将机器指令的8位操作码作为11位微地址中的高8位,微地址中的低3位用事先规定的固定值

转子指令 JSR D的指令流程和控制信号序列
(PC)->MAR,Read PC->B,Gon,F->MAR,Read
(PC)->Y,(Y)+1->PC PC->B,Gon,F->Y,A+1,F->PC
MDR->IR MDR->B,Gon,F->IR
(SP)->Y SP->B,Gon,F->Y
(Y) - 1 -> SP,(Y) - 1 -> MAR A-1,F->SP,F->MAR
(PC)->MDR,Write PC->B,Gon,F->MDR,F->Y,Write
(Y) + (IR) -> PC (IR里面的内容就是D) IR->B,A+B,F->PC
设转子指令为JSR 200H,指令所在内存单元地址为 2012H,内存按字编址,执行转子指令后PC的值是 2013H + 200H = 2213H
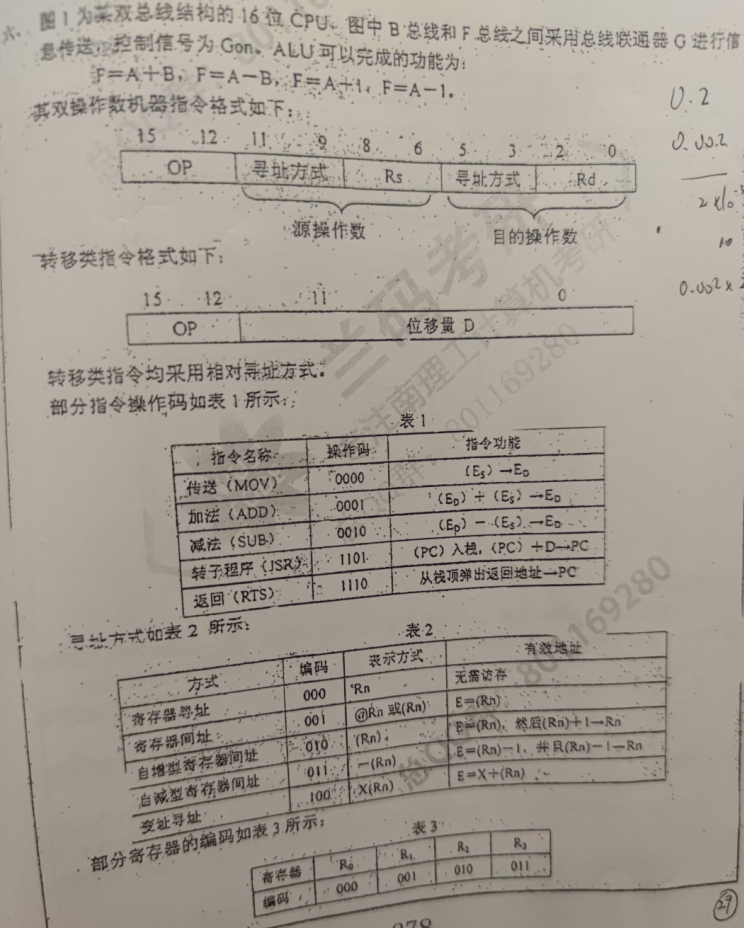
现有指令SUB R2,(R3)+,写出机器指令码,0010 000 010 010 011
设指令SUB,R2,(R3)+,所在的内存单元的地址是 2000H,寄存器R2的内容为ABCDH,R3的内容为1000H,地址1000H中的内容为1234H,地址ABCDH中的内容为5678H,则指令 SUB R2,(R3)+执行后,哪些寄存器和存储单元内容会变
PC取值+1,2001H,R3自增,1001H,中1000H对应的内容是1234H,1000H对应 ????

设中断源编号为N,则中断源编号与中断向量地址之间的关系:(N - 1)*2 + 1000H
中断源P3对应的中断服务程序入口地址:30A0H
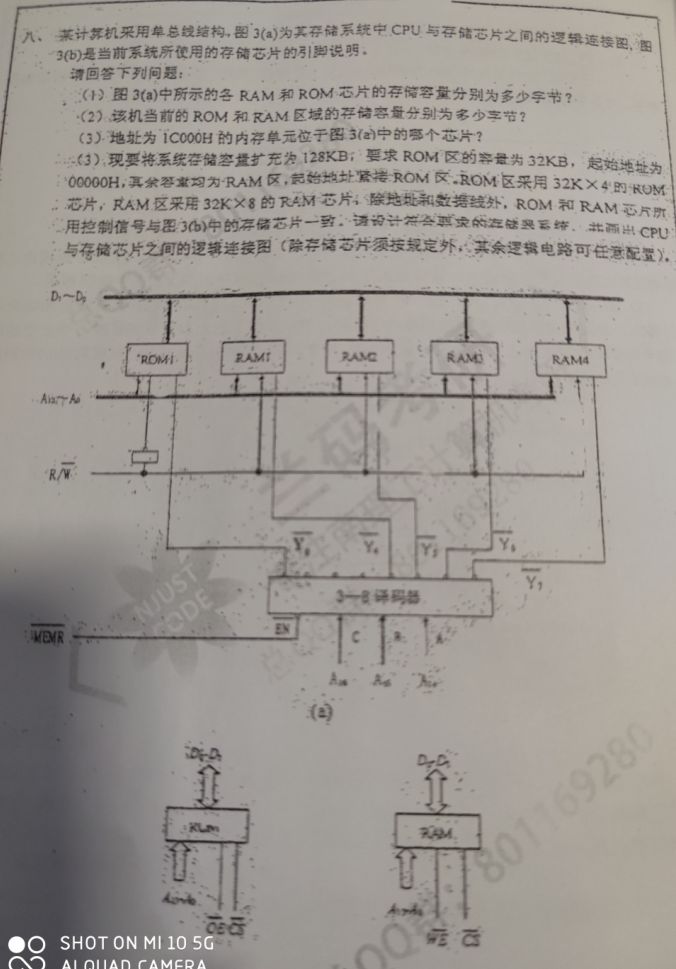
数据线 D0 ~ D7,地址线 A0 ~ A13,ROM和RAM的存储容量都是 2^14 = 16KB
该机当前的ROM和RAM区域的存储容量,ROM 16KB,RAM 64KB
地址1C000H = 0001 1100 0000 0000 0000,片选,111H = 7D,所以是3-8译码器最后一位,Y7,即RAM4
128K,ROM32K,RAM96K,一片ROM 32K * 4 bit,需要2片ROM进行位扩展;一片RAM 32K * 8 bit,需要3片RAM进行字扩展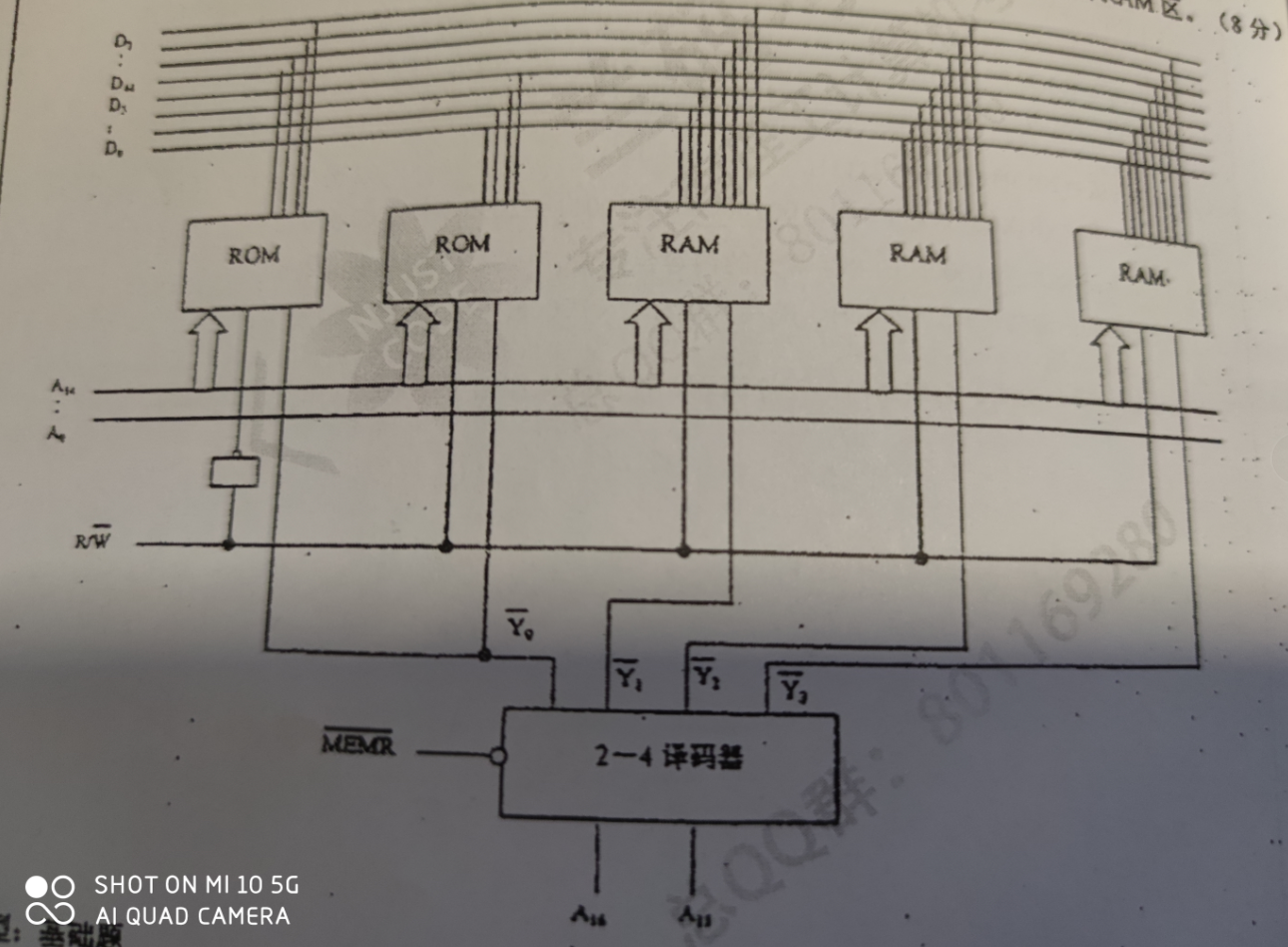
判断原码是否为规格化数的依据,尾数最高位为1,其余位相同
规格化数,绝对值在 1/R ~ 1

绝对值大于1/4,小于1
定点小数补码除法运算过程中,要求|被除数| < |除数|
组成指令流水线的各功能段执行时间最好是尽量相等
采用微程序控制方式时,微指令中的微地址是指后继微指令地址
计算机使用总线结构主要优点是便于实现模块化,同时减少了信息传输线的数目
校验码的检错,纠错能力取决于 最小码间距离
采用微程序控制方式的控制器中,每一条机器指令由一段用微指令组成的一段微程序来解释执行
IEEE754单精度浮点数,阶码为0,尾数不为0,则数的表达式是:N = (-1)^s * 2^-126 * 0.M
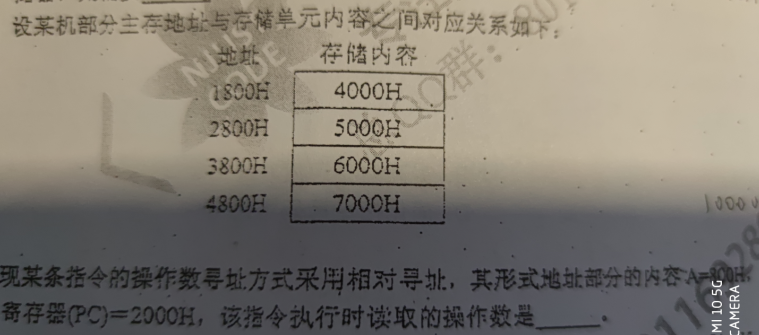
地址码是补码,800H,负数,那么 2000H + F800H = 0010 0000 0000 0000 - 0000 1000 0000 0000 = 0001 1000 0000 0000 = 1800H,1800H对应的是4000H
F800H原 = 1111 1000 0000 0000 - 1 = 1111 0111 1111 1111 然后取反 = 1000 1000 0000 0000

直接映象方式,矩阵首地址 1024,每个元素32位,占4个字节,元素A[1][31]所在单元主存地址为 1024 + (256 + 31)*4 = 2172B,对应的主存地址为 2172 / 64 = 33,所以主存块号为33
一个Cache可以放 512/64 = 8块内存,33 % 8 = 1
Cache命中率:2000 / 2050 ≈ 0.976
主存-Cache系统的平均访问时间:Ta = 0.976*50ns + (1 - 0.976)*200 = 53.6ns
256MB / 64M * 8 bit = 256/64 = 4片,8位,需要8根数据线,64M=2^26,需要26根地址线

(PC)->MAR,Read PC->B,F=B,F->MAR,read,F->Y
(PC) + 1 -> PC F = A + 1,F->PC
M->MDR->IR MDR->B,F=B,F->IR
(R1)->MAR,Read R1->B,F=B,F->MAR,F->Y,Read
(R1) + 1 -> R1 F = A + 1,F->R1
M->MDR->Y MDR->B,F=B,F->Y
(Y) + (R0) -> MDR,Write R0->B,F = A+B,F->MDR,Write
执行该指令,访存3次
PC: 2FFFH,(R0):A000H,(R1):1001H,(1000H):(A000H):2000H,(1000H):5000H,因为A+B溢出,所以剩下一个5
操作码一共占4位,最多可以有16位,16-12 = 4,则单操作数指令最多可以有 4 * 2^6 = 256条,80/256 = 0,零操作数指令要占用一条单操作数指令,所以最多可以有255条零操作数指令

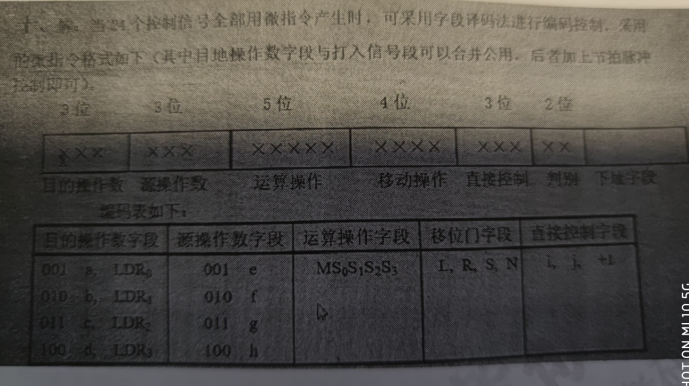
微操作编码中10个微命令采用直接控制方式编码,占10位;30个微命令,4个相斥位,各占一个字段,分别占 3,5,4,2,一共14位;判断条件有4个,占4位
字长是40位,40 - 24 - 4 = 12位,剩余12位给下地址字段长度
下地址字段长度位12位,可寻址的存储空间 2^12 = 4096bit,微指令字长40位,所以控制存储器的容量可以达到:4096 * 40bit
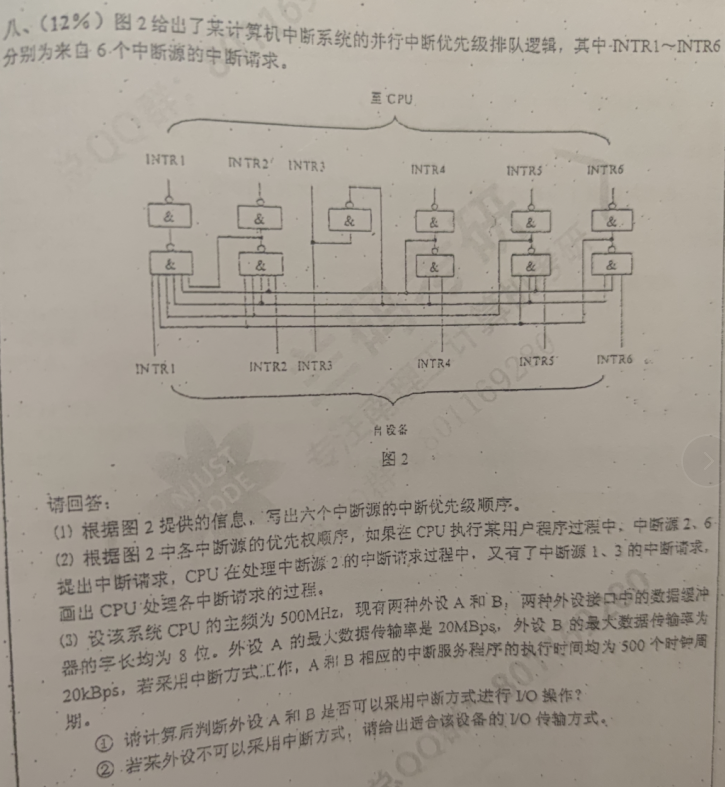
数地址线的条数即可,线越少,优先级越高,3 > 4 > 6 > 5 > 2 > 1

中断服务程序执行时间 500/500MHz = 1us
数据缓冲字长8位,1B,外设A的中断请求时间间隔是:1B / 20MBps = 0.05 us,外设A的中断请求时间间隔是:1B / 20kBps = 50us
外设A的请求间隔小于中断程序执行时间,所以A不能用中断方式进行IO操作;而外设B请求间隔大于中断服务程序执行时间,所以B可以用中断方式进行IO操作
外设A最好采用DMA或者通道方式进行IO操作
IEEE754标准中并不是所有浮点数都使用隐藏位技术,只有单精度和双精度使用隐藏位技术
指令系统中,程序控制类指令的功能是改变程序执行顺序
在指令执行过程中,不可以修改指令寄存器IR的内容

Cache有256块,大小1KB,所以一个数据Cache 256KB
主存地址空间1GB=2^30B,256KB = 2^18B,1GB / 256KB = 2^12 标识cache需要12位,加上1位有效位,一共13位,数据cache有256个块,256 * 13 = 416B
Cache总量 = 256KB + 416B = 256.40625KB
4路组相联映像方式,Cache一共有 256 / 4 = 64组,组号 6 位,块内偏移 10位, 1GB = 2^30,去掉组号和块内偏移,剩下14位
主存标识有14位,这里的2是4路占有的位数,即编号 0 1 2 3
123ABCDFH = 0001 0010 0011 1010 1011 1100 1101 1111,偏移 00 1101 1111 ,组号 1011 11,主存标识 0001 0010 0011 1010
偏移是不变的, 组号也是不变的,但是组内号是可以改变的,可能放到 1011 11 **00 1101 1111 补齐,0010 1111 **00 1101 1111
即 2F*DF,*可以取0~3,所以可能放到 2F0DF 2F1DF 2F2DF 2F3DF
从计算机系统发展过程看,早期的计算机组织结构,是以运算器为中心的,近代的计算机组织结构是以存储器为中心的
主机与IO设备进行数据传输时,CPU效率最低的是 程序查询方式
双端口存储器之所以能高速进行读写,是因为采用 两套相互独立的读写电路
便于实现数组、向量、字符串处理的寻址方式是 变址寻址
CRC码生成多项式的条件

PCI总线
- PCI总线是一个与处理器无关的高速外围设备
- PCI总线的基本传输机制是促发式传送
- PCI设备有主设备和从设备
DMA
- 在DMA的数据传输阶段无需CPU介入,完全由DMAC控制数据传输
- DMA控制器和CPU都可以作为总线的主设备
- DMA方式下要用到中断处理技术
USB3.0总线采用串行总线模式传输数据
USB全称为 Universal Serial Bus, 即通用串行总线,所有的USB都采用串行总线模式传送数据
IO缓冲buffer主要是为了增加数据的读写效率
指令执行过程中,不允许修改指令寄存器IR中的内容
通道有自己的通道程序,所以通道适合慢速外设的数据传输
程序中断会影响处理器流水线的执行,产生全局相关



主存128KW,
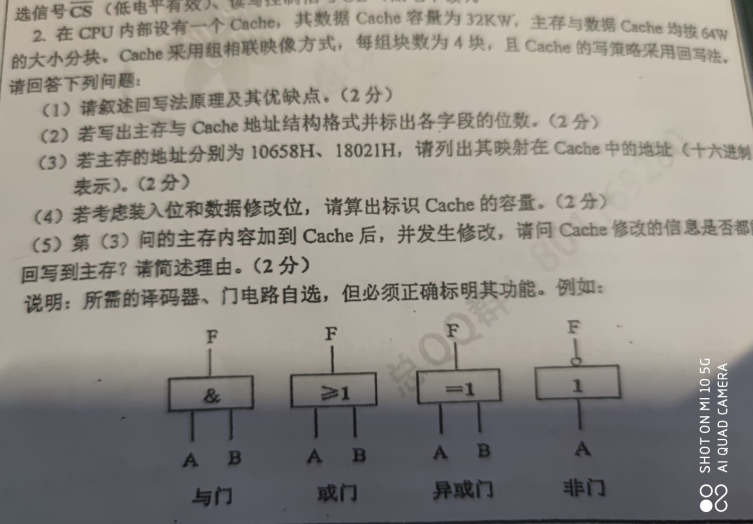
回写法的原理:当CPU对Cache写命中时,只修改Cache内容而不修改主存,只有当此行被换出Cache时才会写回主存
优点:显著减少访存次数,提高CPU利用率
缺点:Cache/主存的不一致性
4路组相联,32KW / 64W = 2^9块,2^9 / 4 = 2^7 组,即 128组,组号占7位,一块大小64W,64W = 2^6 W,块内偏移 占6位,128KW / 32KW = 4 = 2^2,占2位,组内块号2位,主存标识占4位
主存地址:4位主存标识,7位组号,6位块内偏移 Cache地址:7位组号,2位组内块号,6位块内偏移
10658H = 0001 0000 0110 0101 1000 ,块内偏移 01 1000,块号 0 0110 01,中间有2位组内块号,0 0110 01 ** 01 1000,整理格式,0001 1001 **01 1000= 19*8,可以取 1918,1958,1998,19D8
128KW / 32KW = 4块Cache, 若考虑装入位和数据修改位,512 * ()????????
只有等对应的块被换出才写回
总线仲裁方法按照仲裁控制机构的设置方式可以分为集中仲裁和分布式仲裁
便于实现浮动程序设计的寻址方式是相对寻址
键盘可分为功能键和字符键(控制键)

CPI CPU每执行一条指令所需的时钟周期数
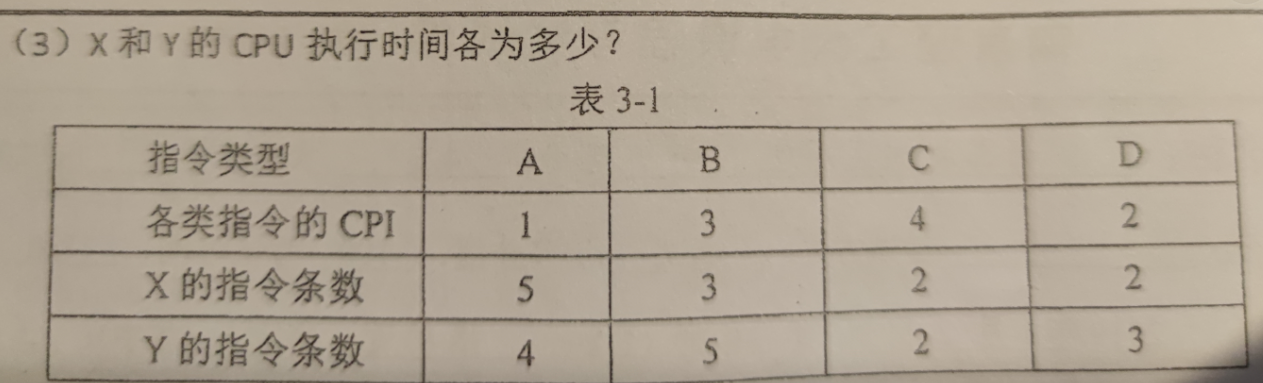
X和Y各有 12条和14条指令
X和Y所含的时钟周期各为 5 + 9 + 8 + 4 = 26,4 + 15 + 8 + 6 = 33
一个时钟周期为 1/2GHz = 0.5 * 10^-9 = 0.5ns,X的CPU执行时间为 0.5 * 26 = 13ns,0.5 * 33 = 16.5ns

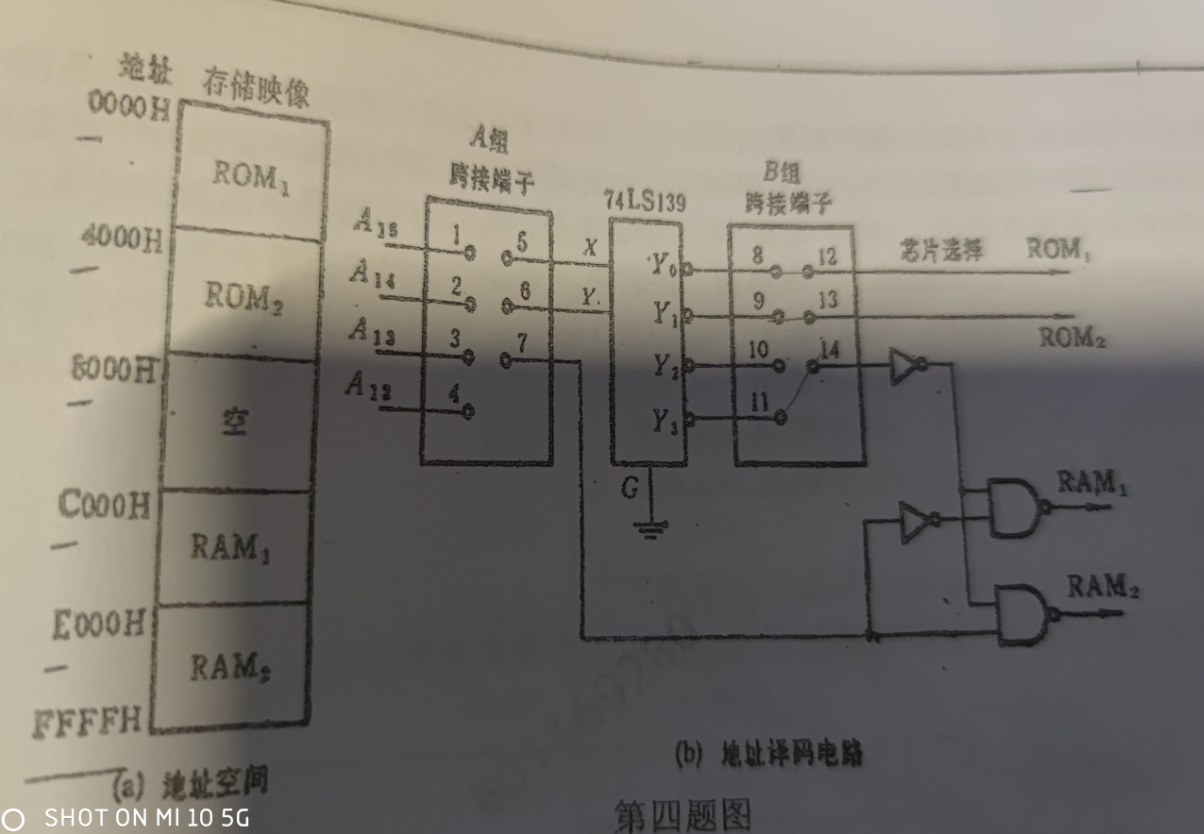
存储器字长16位,16位 2B,2^16*2B = 128KB
2 4 译码器,00 ROM1,01 ROM2,11 RAM,A13找RAM,但是无法确定是那一片RAM,1接5,2接6,3接7,8接12,9接13,11接14

MOV指令,RR(寄存器-寄存器),寄存器寻址
STA指令,RS(寄存器-存储器),基址寻址 + 变址寻址
LDA指令,RS,直接寻址
CPU完成MOV花费时间最短,完成STA花费时间最长
(20010H) = 1111 0000 1111 0001,OP = 111100,执行LDA指令,目标寄存器 1111H = 15,R15,PC取值完后+1,所以PC指向20011H,将此时内存中 3CD2H送入R15
(20012H) = 0010 1000 0101 0110,OP = 001010,指令MOV指令,目标寄存器 0101H = 5,R5,源寄存器 0110H = 6,R6,将R6的内容送入R5
(20013H) = 0110 1111 1101 0110,OP = 011011,执行STA指令,源寄存器 1101H = R13,变址寄存器 0110H = 6,R6
基值 + 变址偏移量 + 后继地址变址偏移量 = 3H + (R6) + 2019H = (R6) + 201CH
基址寻址
计算公式:EA = (BR) + A
有效地址是将CPU中基址寄存器BR的内容加上指令字中形式地址A
变址寻址
计算公式:EA = (IX) + A
有效地址是将CPU中变址寄存器IX的内容加上指令字中有效地址A。
流水线处理技术
- 顺序方式,控制简单,节省设备,执行速度慢,机器效率低
- 重叠方式,前一条指令解释执行完成之后,就开始下一条指令的解释执行,加快程序运行速度,对系统频宽要求很高,一般要求存储器多存储器交叉工作
- 流水方式,流水线各功能部件并行工作,同时进行多条指令的解释执行,机器处理速度大大提高
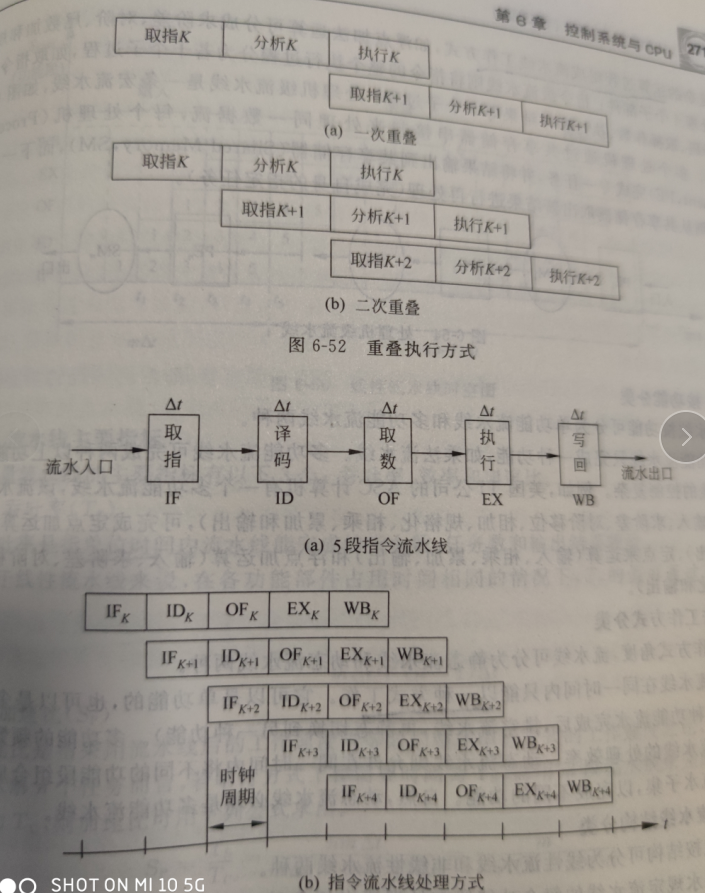
流水线分类(处理级别)
- 操作部件级,将复杂的运算过程组成流水线的工作方式
- 指令级,将指令的整个执行过程分为若干个子过程,取指、译码、取操作数、执行和存结果
- 处理机级,宏流水线,多个处理机共享存储处理同一数据流
流水线分类(功能)
- 单功能流水线,只完成一种功能
- 多功能流水线,完成两种以上功能,控制复杂
流水线分类(工作方式)
- 静态流水线,既可以单功能也可以多功能,必须一种流水完成后,静态切换到另一种功能
- 动态流水线,允许同一时间内将不同功能段组合成具有多种功能的流水子集
流水线分类(结构)
- 线性流水线,最多只经过一次,无反馈回路
- 非线性流水线,通过反馈回路多次被使用
流水线相关问题
资源相关
有多条指令进入流水线后在同一机器周期内争用同一功能部件导致流水不能继续运行
解决方案
- 后续相关指令延迟一节拍进入流水线
- 增加缓冲部件,将指令提前预取到缓冲区
数据相关
多条指令进入流水线后,各条指令的操作重叠进行,使得原来对操作数的访问顺序发生了变化
产生了错误的运行结果,导致数据相关冲突
解决方案
- 后续相关指令延迟进入流水线(推后法)
- 增加快速直接通道(0延迟量)
- 数据旁路技术
控制转移相关
有分支指令,转子指令和中断等引起的相关。当转移类指令进入流水时,引起转移的状态还未形成,无法确定后续指令的进入
解决方案
- 加快和提前形成条件码
- 预取转移成功或不成功两个分支序列的指令
- 采用延迟转移技术
通过编译器调整指令执行顺序可解决部分控制冒险
流水线主要指标




Mux,2选1
执行完上述指令后,r8的值变成了66
会出现数据相关,r8的值可能会是 -36

总运行时间:5t + 999t = 1004t = 10040ns
吞吐率(单位时间内完成的指令数,任务数,输出结果):1000 / 10040 ≈ 100条/ns
加速比(采用流水线后工作速度与等效的顺序串行方式工作速度之比,亦即串行工作时间/流水线工作时间):50000 / 10040 = 4.98
时空比(n个任务占用的时空区/m段总的时空区 或者 加速比/m 或者 吞吐率*功能段周期),50000 / 5*10040 = 99.6%
解决中断引起的流水线断流的方法 精确断点法和不精确断点法
阶码与尾数均采用原码表示的范围

阶码与尾数均采用补码表示的范围

算编码时,ALU观察是信号还是功能,功能则+1<=2^n,信号直接数,寄存器有输入则各算+1<=2^n。移位器编码按字段直接编码功能+1<=2^n
从本质上讲,U盘(闪存)是一种只读存储器
PC的位数取决于存储容量,MDR的位数取存储字长,CPU的通用寄存器位数取决于机器字长,IR的位数取决于指令字长
在DMA方式中,CPU和DMA控制器通常采用三种方法使用主存
- 停止CPU访问主存
- 周期挪用
- CPU和DMA交替访问
常用的虚拟存储器寻址系统由主存-辅存两级存储器组成
RAID将多个物理盘组成单个逻辑盘
DMA方式下,数据从内存传送到外设经过的路径,内存->数据总线->DMAC->外设
用变形补码进行加减运算时,可依据运算结果双符号位判断如下四种
- -----运算结果为负数,无溢出
- 00
- -----运算结果为正数,无溢出
- 10
- -----运算结果下溢(负数溢出)
- 01
- -----运算结果上溢(正数溢出)
低正高负
计算机中信息以二进制方式表示是由物理器件的性能决定
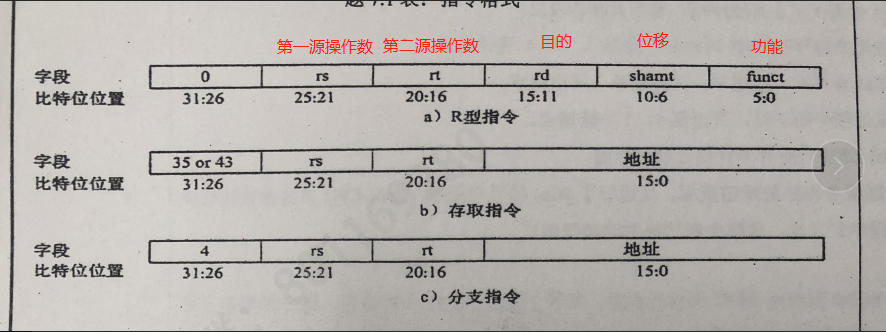
MIPS指令地址格式
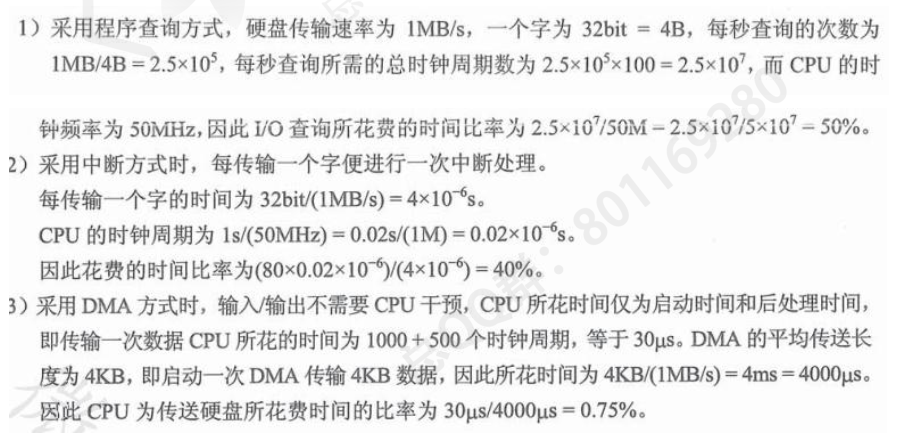
进程A在计算机运行时间80s,60s是CPU时间,其余为IO时间,CPU速度提高50%,若CPU速度提高50%,IO不变,进程A所耗费的时间
60 / 150% = 40s,所以60s
堆栈计算机,零地址运算类指令,参加的两个操作数是堆栈的栈顶和次栈顶单元
从CPU运行的程序特性来说,中断具有随机性、异步性和不可再现性
动态半导体,利用电容存储电荷,电容会充放电,每隔一段时间玉原存内容重新写入一遍,刷新放大器集成在RAM上,只进行一次访存,占用一个存取周期
微程序控制器,除公共指令外有32条指令,公共取指令微程序包含2条微指令,各指令微程序有4条微指令组成断定法确定下条微指令地址,字段位数至少为8位
32*4 + 2 = 130,130 > 2^7 = 128
组相联映像是直接映像和全相联映像的普遍形式
三总线结构IO总线,主存总线和DMA总线
磁盘传输和传输速率的题目

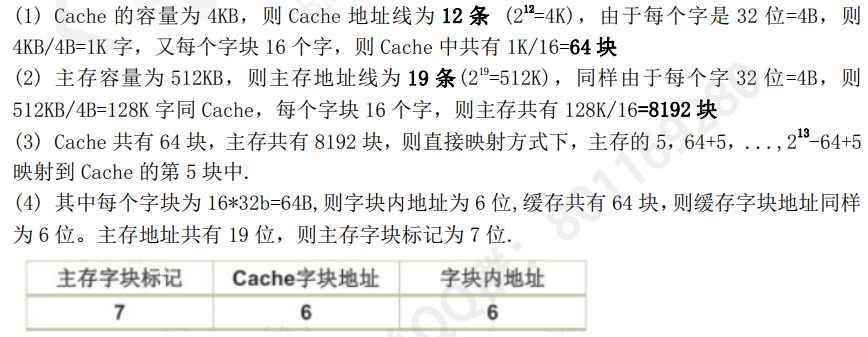
Cache的题目

Cache的速度比

睁开眼,书在面前 闭上眼,书在心里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号