深度学习常用的Attention操作(MHA/Casual Attention)以及内存优化管理(Flash Attention/Page Attention)
From:https://www.big-yellow-j.top/posts/2025/02/17/Attention.html
Attention操作以及内存优化管理
一、Attention操作
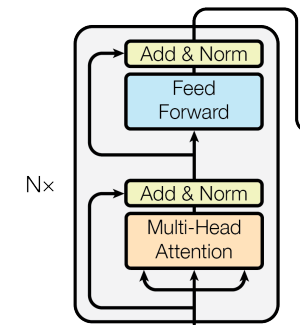
关于 Multi Head Attention网上有较多的解释了,这里主要记录如下几点
1、对于注意力计算公式的理解:
首先是对于Q、K、V如此计算缘由,论文最开始是用在NLP中,因此我们以 NLP 角度来解释。假设输入的 Q、K、V 形状为 \(n \times d_k\),其中 \(n\) 是文本 token 的数量,\(d_k\) 是键(Key)和查询(Query)的维度。通过线性变换,我们将 token 处理为 \(d_k\) 维的表示。计算 \(QK^T\) 后,得到一个 \(n \times n\) 的矩阵,可以理解为 token 之间的注意力权重。随后,我们用这些注意力权重加权求和 Value 矩阵 \(V\),从而更新 token 表示。
其次为什么在公式里面要除\(\sqrt{d_k}\)呢?1.防止内积值过大,保持稳定的梯度。假设 \(Q\) 和 \(K\) 的每个元素服从均值为 0,方差为 \(\sigma^2\) 的分布。\(QK^T\) 的每个元素是 \(d_k\) 个元素的内积,按照独立同分布假设,结果的方差会随着 \(d_k\) 增大而增大,大约是 \(\mathbb{V}[QK^T] \approx d_k \sigma^2\)。这样,\(QK^T\) 的值会随着 \(d_k\) 的增大而变大,导致 softmax 归一化后,梯度变得很小,训练变得不稳定。通过除以 \(\sqrt{d_k}\),可以让 \(QK^T\) 的方差大致保持在 1 的数量级,使 softmax 输出不会过于极端(接近 0 或 1),从而保持训练稳定性。2. 让 softmax 具有合适的分布,避免梯度消失softmax 计算的是 \(e^{x_i}\),如果 \(x_i\) 过大,会导致梯度消失,模型难以学习。通过 \(\sqrt{d_k}\) 归一化,控制 \(QK^T\) 的范围,使 softmax 输出不会过于极端,从而提高训练效果。
2、之所以要采用多头,这个理由也比较简单,在计算 \(QK^T\) 时,只能基于一个相同的查询-键表示来计算注意力分数,可能会偏向某一种关系模式,导致模型难以捕捉更多层次的语义信息
3、在模型结构里面的残差处理思路是:\(\text{Norm}(x+f(x))\)也就是说先通过MHA处理而后残差连接欸,但是残差会进一步放大方差 因此也有提出:\(x+\text{Norm}(f(x))\)前面提到的两种分别是Post Norm以及Pre Norm。对于那种好那种坏并没有很好的解释,与此同时有另外一种连接方式:\(x+ \alpha f(x)\)在后续训练中不断更新\(\alpha\),参考\(\alpha\)以固定的、很小的步长慢慢递增,直到增加到\(\alpha=1\)就固定下来。
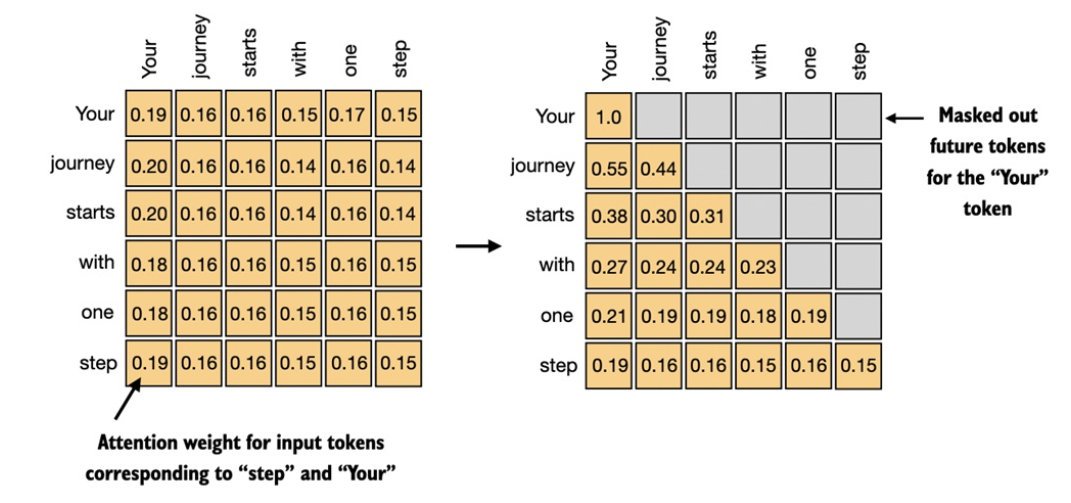
2、Casual Attention
因果注意力的主要目的是限制注意力的计算,使得每个位置的查询只能与当前和之前的位置计算注意力得分,而不能“窥视”未来的位置。具体来说:对于位置\(𝑖\),模型只能考虑位置 \(1,2,...,𝑖\)的信息,而不能考虑位置\(𝑖+1,𝑖+2,...,𝑛\)。因此,当计算每个位置的注意力时,键(key)和值(value)的位置会被限制在当前的位置及其之前的位置。实现方式也很简单直接最注意力矩阵进行屏蔽即可,比如说注意力矩阵为:
二、内存优化管理
1、Flash Attention
论文提出,是一种高效的注意力计算方法,旨在解决 Transformer 模型在处理长序列时的计算效率和内存消耗问题。其核心思想是通过在 GPU 显存中分块执行注意力计算,减少显存读写操作,提升计算效率并降低显存占用。
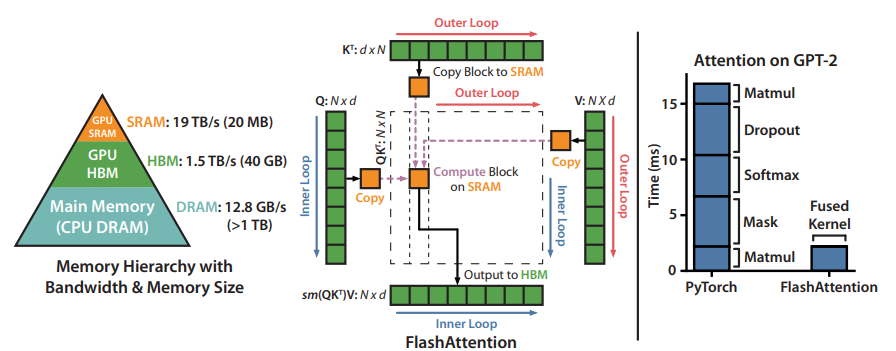
Flash Attention计算机制:
分块计算:传统注意力计算会将整个注意力矩阵 (N×N) 存入 GPU 内存(HBM),这对长序列来说非常消耗内存,FlashAttention 将输入分块,每次只加载一小块数据到更快的 SRAM 中进行计算,传统Attention计算和flash attention计算:

对比上:传统的计算和存储都是发生再HBM上,而对于flash attention则是首先会将Q,K,V进行划分(算法1-4:整体流程上首先根据SRAM的大小M去计算划分比例(\(\lceil \frac{N}{B_r} \rceil\))然后根据划分比例去对QKV进行划分这样一来Q(\(N\times d\)就会被划分为不同的小块,然后只需要去遍历这些小块然后计算注意力即可)),然后计算Attention(算法5-15),计算中也容易发现:先将分块存储再HBM上的值读取到SRAM上再它上面进行计算,不过值得注意的是:在传统的\(QK^T\)计算之后通过softmax进行处理,但是如果将上述值拆分了,再去用普通的softmax就不合适,因此使用safe softmax
1、HBM(High Bandwidth Memory,高带宽内存):是一种专为高性能计算和图形处理设计的内存类型,旨在提供高带宽和较低的功耗。HBM 常用于需要大量数据访问的任务,如图形处理、大规模矩阵运算和 AI 模型训练。
2、 SRAM(Static Random Access Memory,静态随机存取存储器):是一种速度极快的存储器,用于存储小块数据。在 GPU 中,SRAM 主要作为缓存(如寄存器文件、共享内存和缓存),用于快速访问频繁使用的数据。例如在图中 FlashAttention 的计算中,将关键的计算块(如小规模矩阵)存放在 SRAM 中,减少频繁的数据传输,提升计算速度。
3、不同softmax计算:
softmax:\(x_i=\frac{e^{x_i}}{\sum e^{x_j}}\)
safe softmax(主要防止输出过大溢出,就减最大值):\(x_i=\frac{e^{x_i-max(x_{:N})}}{\sum e^{x_j-max(x_{:N})}}\)
代码操作,首先安装flash-attn:pip install flash-attn。代码使用:
from flash_attn import flash_attn_func
import torch
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
q = torch.randn(32, 64, 8, int(1024/8)).to(device, dtype=torch.bfloat16)
out = flash_attn_func(q, q, q, causal= False)
print(out.shape)
flash_attn_func输入参数:
1、q,k,v:形状为:(batch_size, seqlen, nheads, headdim)也就是说一般文本输入为:(batch_size, seqlen, embed_dim)要根据设计的nheads来处理输入的维度,并且需要保证:headdim≤256,于此同时要保证数据类型为:float16 或 bfloat16
2、causal:bool判断是不是使用causal attention mask
2、Multi-head Latent Attention(MLA)
对于KV-cache会存在一个问题:在推理阶段虽然可以加快推理速度,但是对于显存占用会比较高(因为KV都会被存储下来,导致显存占用高),对于此类问题后续提出Grouped-Query-Attention(GQA)以及Multi-Query-Attention(MQA)可以降低KV-cache的容量问题,但是会导致模型的整体性能会有一定的下降。
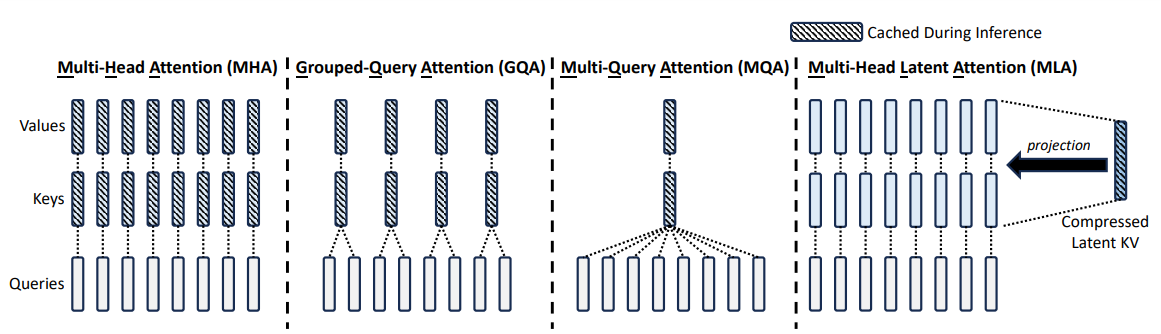
MHA: 就是普通的计算方法
GQA: 将多个Q分组,并共享相同的K和V
MQA: 所有Attention Head共享同一个K、V

对于MLA(DeepSeek-V2以及DeepSeek-V3中都用到)作为一种KV-cache压缩方法,原理如下:

对于上面完整的计算过程,对于Q之所以要计算两次(线降维而后升维)而不是只去计算一次,思路和LoRA的相似,将:\(xw\)中的\(w\)分解为两部分更加小的矩阵(对应上述图中的\(W^{DQ}\text{和}W^{UQ}\))
从上述公式也容易发现,在MLA中只是对缓存进行一个“替换”操作,用一个低纬度的\(C_t^{KV}\)来代替(也就是说:只需要存储\(c_t^{KV}\)即可)原本的KV(或者说将容量多的KV进行投影操作,这个过程和LoRA有些许相似),在进行投影操作之后就需要对attention进行计算。对于上述公式简单理解:
假设输入模型(输入到Attention)数据为\(h_t\)(假设为:\(n\times d\)),在传统的KV-cache中会将计算过程中的KV不断缓存下来,在后续计算过程中“拿出来”(这样就会导致随着输出文本加多,导致缓存的占用不断累计:\(\sum 2n\times d\)),因此在MLA中的操作就是:对于\(h_t\)进行压缩:\(n \times d \times d \times d_s= n \times d_s\)这样一来我就只需要缓存:\(n \times d_s\)即可(如果需要复原就只需要再去乘一下新的矩阵即可)

部分代码部分参数初始化值按照236B的设置中的设定:
class MLA(nn.Module):
def __init__(...):
super().__init__()
...
self.n_local_heads = args.n_heads // world_size # n_heads=128
self.q_lora_rank = args.q_lora_rank # q被压缩的维度 || 1536
self.kv_lora_rank = args.kv_lora_rank # KV被压缩的维度 || 512
# QK带旋转位置编码维度和不带旋转位置编码维度
self.qk_nope_head_dim = args.qk_nope_head_dim # 128
self.qk_rope_head_dim = args.qk_rope_head_dim # 64
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim # 192
self.v_head_dim = args.v_head_dim # 128
...
if self.q_lora_rank == 0:
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
self.softmax_scale = self.qk_head_dim ** -0.5
def forward(self, ...):
bsz, seqlen, _ = x.size() # 假设为:3, 100, 4096
...
if self.q_lora_rank == 0:
q = self.wq(x)
else:
q = self.wq_b(self.q_norm(self.wq_a(x))) # 3, 100, 192*128
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim) # 3, 100, 128, 192
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1) # (3, 100, 128, 128), (3, 100, 128, 64)
# 使用RoPE
q_pe = apply_rotary_emb(q_pe, freqs_cis)
kv = self.wkv_a(x) # 3, 100, 576
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1) # (3,100,512) (3,100,64)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
if attn_impl == "naive":
q = torch.cat([q_nope, q_pe], dim=-1) # 3, 100, 128, 192
kv = self.wkv_b(self.kv_norm(kv)) # 3, 100, 32768
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim) # 3, 100, 128, 256
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
# 设计到多卡集群start_pos:end_pos是多卡集群上的操作
self.k_cache[:bsz, start_pos:end_pos] = k
self.v_cache[:bsz, start_pos:end_pos] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
else:
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
if attn_impl == "naive":
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x
不过 MLA存在一个问题,不兼容 RoPE(旋转位置编码,因为你将KV进行压缩)从上述代码的角度除法理解如何使用RoPE,从上面代码上,无论是Q还是KV都是从压缩后的内容中分离除部分内容,然后计算结果
3、Page Attention(vLLM)
上述描述中:Flash Attention(加快速度)、MLA(优化KV-cache存储),而Page Attention也是一种优化方法(区别于MLA,page attention是对内存进行分配管理)。参考论文中描述,对于KV-cache存在3个问题:

1、预留浪费 (Reserved):为将来可能的 token 预留的空间,这些空间被保留但暂未使用,其他请求无法使用这些预留空间;
2、内部内存碎片化问题(internal memory fragmentation):系统会为每个请求预先分配一块连续的内存空间,大小基于最大可能长度(比如2048个token),但实际请求长度往往远小于最大长度,这导致预分配的内存有大量空间被浪费。
3、外部内存碎片化问题(external memory fragmentation):不同内存块之间的零散空闲空间,虽然总空闲空间足够,但因不连续而难以使用。
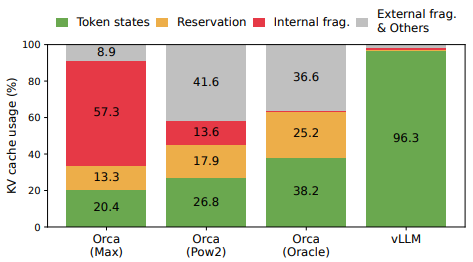
只有 20.4%-38.2% 的token是被使用的,大部分都被浪费掉了。Page Attention允许在非连续的内存空间中存储连续的 key 和 value 。具体来说,Page Attention将每个序列的 KV-cache 划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,Page Attention内核可以有效地识别和获取这些块。如何理解上面描述呢?还是借用论文中的描述:

比如说按照上面Prompt要输出(假设只输出这些内容):“fathers brought a car”,一般的套路可能是:比如说:“Four score and seven years ago our xxxxx”(xxx代表预留空间)因为实际不知道到底要输出多少文本,因此会提前预留很长的一部分空间(但是如果只输出4个字符,这预留空间就被浪费了),因此在page attention里面就到用一种“分块”的思想处理,以上图为例,分为8个Block每个Block只能存储4个内容,因此就可以通过一个Block Table来建立一个表格告诉那些Block存储了多少,存储满了就去其他Blobk继续存储。整个过程如下:
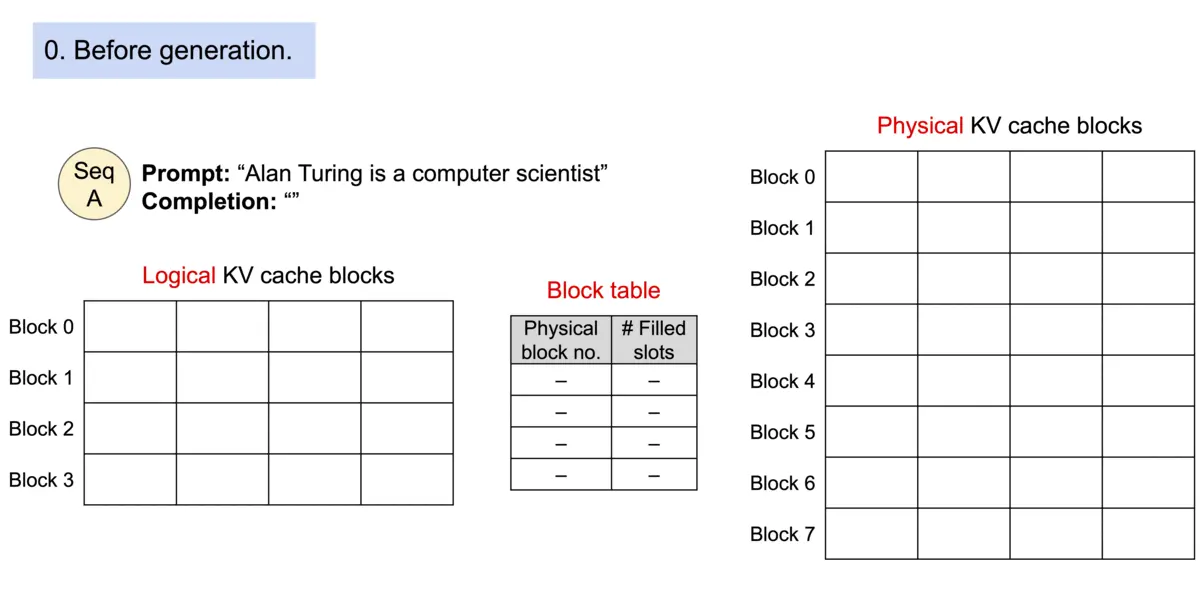
这样一来浪费就只会发生在最后一个Block中(比如说存储4个但是只存进去了1个就会浪费3个)
代码操作:
git lfs clone https://www.modelscope.cn/qwen/Qwen1.5-1.8B-Chat.git
from vllm import LLM, SamplingParams
import torch
# Sample prompts.
prompts = [
"Who're you?",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="./Qwen1.5-1.8B-Chat/", dtype= torch.float16, enforce_eager= True)
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
参考
1、https://mloasisblog.com/blog/ML/AttentionOptimization
2、https://github.com/vllm-project/vllm
3、https://arxiv.org/pdf/2205.14135
4、https://zhuanlan.zhihu.com/p/676655352
5、https://arxiv.org/pdf/2405.04434
6、https://spaces.ac.cn/archives/10091
7、https://zhuanlan.zhihu.com/p/696380978
8、https://dl.acm.org/doi/pdf/10.1145/3600006.3613165
9、https://zhuanlan.zhihu.com/p/638468472
10、https://mloasisblog.com/blog/ML/AttentionOptimization
11、https://github.com/vllm-project/vllm
12、https://docs.vllm.ai/en/latest/index.html
13、https://arxiv.org/pdf/2103.03493
14、https://www.cnblogs.com/gongqk/p/14772297.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号