

深度学习基础理论————"优化"方法(归一化/dropout)
深度学习基础理论————"优化"方法(归一化/dropout)
1、归一化方法(LayerNorm/BatchNorm/GroupNorm)
归一化层是深度神经网络体系结构中的关键,在训练过程中确保各层的输入分布一致,这对于高效和稳定的学习至关重要。归一化技术的选择(Batch, Layer, GroupNormalization)会显著影响训练动态和最终的模型性能。每种技术的相对优势并不总是明确的,随着网络体系结构、批处理大小和特定任务的不同而变化。
数据归一化:
定义如下计算公式:
\[\mu_i= \frac{1}{m}\sum_{k\in S_i}x_k \]\[\sigma_i= \sqrt{\frac{1}{m}\sum_{k\in S_i}(x_k- \mu_i)^2+\epsilon} \]4类标准化区别就在于对于参数\(S_i\)的定义!!!(也就是沿着哪个维度进行归一化处理)
如:对一组图片定义如下变量:\((N,C,H,W)\)分别代表:batch、channel、height、width
Bath-norm:\(S_i=\{k_C=i_C\}\)
Layer-norm:\(S_i=\{k_C=i_N\}\)
Instance-norm:\(S_i=\{k_C=i_C,K_N=i_N\}\)
Group-norm:\(S_i=\{k_N=i_N, \lfloor \frac{k_C}{C/G} \rfloor=\lfloor \frac{i_C}{C/G} \rfloor\}\)
\(G\)代表组的数量,\(C/G\)每个组的通道数量
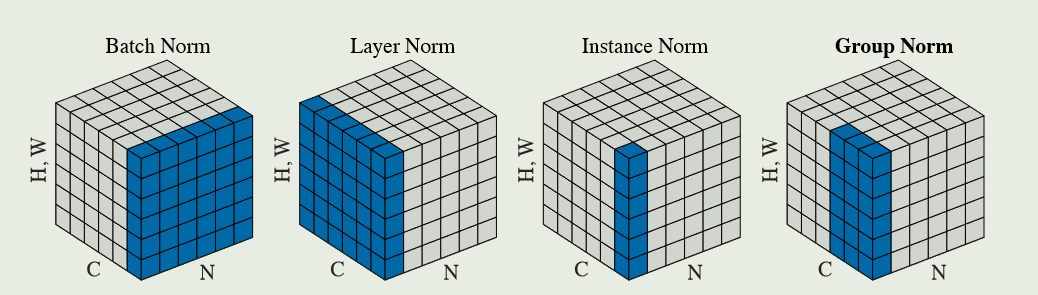
上图都是在image上做的例子
BatchNorm
BN应用于一批数据中的单个特征,通过计算批处理上特征的均值和方差来独立地归一化每个特征。它允许更高的学习率,并降低对网络初始化的敏感性。
这种规范化发生在每个特征通道上,并应用于整个批处理维度,它在大型批处理中最有效,因为统计数据是在批处理中计算的。
LayerNorm
LN计算用于归一化单个数据样本中所有特征的均值和方差。它应用于每一层的输出,独立地规范化每个样本的输入,因此不依赖于批大小。
LN有利于循环神经网络(rnn)以及批处理规模较小或动态的情况。
InstanceNorm
IN对每个样本的每个通道进行独立的归一化处理
GroupNorm
GN将通道道分成若干组,并计算每组内归一化的均值和方差。这对于通道数量可能很大的卷积神经网络很有用,将它们分成组有助于稳定训练。GN不依赖于批大小,因此适用于小批大小的任务或批大小可以变化的任务。
不同归一化对比:
| 方法 | 归一化范围 | 依赖 batch size | 应用场景 | 原因 |
|---|---|---|---|---|
| BatchNorm | Mini-batch 的每个维度 | 是 | 分类任务,CNN,较大 batch size | 1. 通过 mini-batch 的统计信息减少特征偏移,保持分布稳定。 2. 在分类任务中,特征分布的稳定性有助于提升模型收敛速度和最终性能。 |
| LayerNorm | 单个样本的所有特征 | 否 | NLP,RNN,Transformer | 1. 在 NLP 和序列建模中,训练的样本通常较小,不依赖 batch 统计量的 LayerNorm 更稳定。 2. 对整个样本归一化,使得模型对序列长度或上下文无关。 |
| InstanceNorm | 单个样本的每个通道独立 | 否 | 风格迁移,生成任务 | 1. 强调样本内部特征分布的一致性,适合强调局部特征(如风格迁移中的纹理)。 2. 不考虑全局或跨样本的统计信息,能更好保留样本特有的风格特性。 |
| GroupNorm | 分组特征 | 否 | 小 batch 或单样本 CNN | 1. 对小 batch 或单样本任务,避免了 BatchNorm 的统计不稳定问题。 2. 分组归一化平衡了跨通道信息的利用和归一化稳定性,适合卷积特征提取。 |
From: https://blog.csdn.net/qq_36560894/article/details/115017087
BatchNorm:batch方向做归一化,算NxHxW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。
LayerNorm:channel方向做归一化,算CxHxW的均值,主要对RNN(处理序列)作用明显,目前大火的Transformer也是使用的这种归一化操作;
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束,在分割与检测领域作用较好。
代码:(pytorch)
import torch
import torch.nn as nn
x = torch.randn(32, 64, 32, 32)
batch_norm = nn.BatchNorm2d(64)
layer_norm = nn.LayerNorm([64, 32, 32])
group_norm = nn.GroupNorm(8, 64) # 对64通道分8组
isins_norm = nn.InstanceNorm2d(64)
out_batch = batch_norm(x)
out_layer = layer_norm(x)
out_gropu = group_norm(x)
out_insta = isins_norm(x)
InstanceNorm2d、GroupNorm、LayerNorm、BatchNorm2d
假设输入形状:N,C,H,W
1、InstanceNorm2d和BatchNorm2d在代码实践上相似都是对C计算
2、LayerNorm对于输入为N,C,H,W(比如说图像)那么选择C,H,W,如果输入为N,Dim1,Dim2(比如说文本)那么对Dim2计算
3、GroupNorm则是对C分n个组
2、Dropout
在 Dropout 中,每个神经元在训练过程中有一定概率\(𝑝\), \(p\)被随机设置为 0(即被“丢弃”),这种行为可以用如下数学公式描述:
假设某一层神经元的输入表示为一个向量\(x=[x_1,... x_n]\)该层输出为:\(y=[y_1,...,y_n]\),那么Dropout计算过程:首先随机生成掩码向量:\(r_i \sim Bernoulli(p),i=1,...,n\)(\(P(r_i=1)=p, P(r_i=0)=1-p\)),对输入进行掩码得到:\(\tilde{x}=r \odot x\)其中\(\odot\)代表按元素相乘(其实整个过程也就是随机将神经元乘0)
反向传播过程中:对于被Dropout的神经元其梯度也会被置于0
