HE X, CAI D, NIYOGI P. Laplacian Score for Feature Selection[C/OL]//Advances in Neural Information Processing Systems: 卷 18. MIT Press, 2005[2023-07-07].
详细代码
```python
import numpy as np
from scipy.sparse import *
from sklearn.metrics.pairwise import pairwise_distances
def lap_score(X, **kwargs):
"""
This function implements the laplacian score feature selection, steps are as follows:
1. Construct the affinity matrix W if it is not specified
2. For the r-th feature, we define fr = X(:,r), D = diag(W*ones), ones = [1,...,1]', L = D - W
3. Let fr_hat = fr - (fr'*D*ones)*ones/(ones'*D*ones)
4. Laplacian score for the r-th feature is score = (fr_hat'*L*fr_hat)/(fr_hat'*D*fr_hat)
Input
-----
X: {numpy array}, shape (n_samples, n_features)
input data
kwargs: {dictionary}
W: {sparse matrix}, shape (n_samples, n_samples)
input affinity matrix
Output
------
score: {numpy array}, shape (n_features,)
laplacian score for each feature
Reference
---------
He, Xiaofei et al. "Laplacian Score for Feature Selection." NIPS 2005.
"""
# if 'W' is not specified, use the default W
if 'W' not in kwargs.keys():
W = construct_W(X)
# construct the affinity matrix W
W = kwargs['W']
# build the diagonal D matrix from affinity matrix W
D = np.array(W.sum(axis=1))
L = W
tmp = np.dot(np.transpose(D), X)
D = diags(np.transpose(D), [0])
Xt = np.transpose(X)
t1 = np.transpose(np.dot(Xt, D.todense()))
t2 = np.transpose(np.dot(Xt, L.todense()))
# compute the numerator of Lr
D_prime = np.sum(np.multiply(t1, X), 0) - np.multiply(tmp, tmp)/D.sum()
# compute the denominator of Lr
L_prime = np.sum(np.multiply(t2, X), 0) - np.multiply(tmp, tmp)/D.sum()
# avoid the denominator of Lr to be 0
D_prime[D_prime < 1e-12] = 10000
# compute laplacian score for all features
score = 1 - np.array(np.multiply(L_prime, 1/D_prime))[0, :]
return np.transpose(score)
def feature_ranking(score):
"""
Rank features in ascending order according to their laplacian scores, the smaller the laplacian score is, the more
important the feature is
"""
idx = np.argsort(score, 0)
return idx
def construct_W(X, **kwargs):
"""
Construct the affinity matrix W through different ways
Notes
-----
if kwargs is null, use the default parameter settings;
if kwargs is not null, construct the affinity matrix according to parameters in kwargs
Input
-----
X: {numpy array}, shape (n_samples, n_features)
input data
kwargs: {dictionary}
parameters to construct different affinity matrix W:
y: {numpy array}, shape (n_samples, 1)
the true label information needed under the 'supervised' neighbor mode
metric: {string}
choices for different distance measures
'euclidean' - use euclidean distance
'cosine' - use cosine distance (default)
neighbor_mode: {string}
indicates how to construct the graph
'knn' - put an edge between two nodes if and only if they are among the
k nearest neighbors of each other (default)
'supervised' - put an edge between two nodes if they belong to same class
and they are among the k nearest neighbors of each other
weight_mode: {string}
indicates how to assign weights for each edge in the graph
'binary' - 0-1 weighting, every edge receives weight of 1 (default)
'heat_kernel' - if nodes i and j are connected, put weight W_ij = exp(-norm(x_i - x_j)/2t^2)
this weight mode can only be used under 'euclidean' metric and you are required
to provide the parameter t
'cosine' - if nodes i and j are connected, put weight cosine(x_i,x_j).
this weight mode can only be used under 'cosine' metric
k: {int}
choices for the number of neighbors (default k = 5)
t: {float}
parameter for the 'heat_kernel' weight_mode
fisher_score: {boolean}
indicates whether to build the affinity matrix in a fisher score way, in which W_ij = 1/n_l if yi = yj = l;
otherwise W_ij = 0 (default fisher_score = false)
reliefF: {boolean}
indicates whether to build the affinity matrix in a reliefF way, NH(x) and NM(x,y) denotes a set of
k nearest points to x with the same class as x, and a different class (the class y), respectively.
W_ij = 1 if i = j; W_ij = 1/k if x_j \in NH(x_i); W_ij = -1/(c-1)k if x_j \in NM(x_i, y) (default reliefF = false)
Output
------
W: {sparse matrix}, shape (n_samples, n_samples)
output affinity matrix W
"""
# default metric is 'cosine'
if 'metric' not in kwargs.keys():
kwargs['metric'] = 'cosine'
# default neighbor mode is 'knn' and default neighbor size is 5
if 'neighbor_mode' not in kwargs.keys():
kwargs['neighbor_mode'] = 'knn'
if kwargs['neighbor_mode'] == 'knn' and 'k' not in kwargs.keys():
kwargs['k'] = 5
if kwargs['neighbor_mode'] == 'supervised' and 'k' not in kwargs.keys():
kwargs['k'] = 5
if kwargs['neighbor_mode'] == 'supervised' and 'y' not in kwargs.keys():
print ('Warning: label is required in the supervised neighborMode!!!')
exit(0)
# default weight mode is 'binary', default t in heat kernel mode is 1
if 'weight_mode' not in kwargs.keys():
kwargs['weight_mode'] = 'binary'
if kwargs['weight_mode'] == 'heat_kernel':
if kwargs['metric'] != 'euclidean':
kwargs['metric'] = 'euclidean'
if 't' not in kwargs.keys():
kwargs['t'] = 1
elif kwargs['weight_mode'] == 'cosine':
if kwargs['metric'] != 'cosine':
kwargs['metric'] = 'cosine'
# default fisher_score and reliefF mode are 'false'
if 'fisher_score' not in kwargs.keys():
kwargs['fisher_score'] = False
if 'reliefF' not in kwargs.keys():
kwargs['reliefF'] = False
n_samples, n_features = np.shape(X)
# choose 'knn' neighbor mode
if kwargs['neighbor_mode'] == 'knn':
k = kwargs['k']
if kwargs['weight_mode'] == 'binary':
if kwargs['metric'] == 'euclidean':
# compute pairwise euclidean distances
D = pairwise_distances(X)
D **= 2
# sort the distance matrix D in ascending order
dump = np.sort(D, axis=1)
idx = np.argsort(D, axis=1)
# choose the k-nearest neighbors for each instance
idx_new = idx[:, 0:k+1]
G = np.zeros((n_samples*(k+1), 3))
G[:, 0] = np.tile(np.arange(n_samples), (k+1, 1)).reshape(-1)
G[:, 1] = np.ravel(idx_new, order='F')
G[:, 2] = 1
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
elif kwargs['metric'] == 'cosine':
# normalize the data first
X_normalized = np.power(np.sum(X*X, axis=1), 0.5)
for i in range(n_samples):
X[i, :] = X[i, :]/max(1e-12, X_normalized[i])
# compute pairwise cosine distances
D_cosine = np.dot(X, np.transpose(X))
# sort the distance matrix D in descending order
dump = np.sort(-D_cosine, axis=1)
idx = np.argsort(-D_cosine, axis=1)
idx_new = idx[:, 0:k+1]
G = np.zeros((n_samples*(k+1), 3))
G[:, 0] = np.tile(np.arange(n_samples), (k+1, 1)).reshape(-1)
G[:, 1] = np.ravel(idx_new, order='F')
G[:, 2] = 1
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
elif kwargs['weight_mode'] == 'heat_kernel':
t = kwargs['t']
# compute pairwise euclidean distances
D = pairwise_distances(X)
D **= 2
# sort the distance matrix D in ascending order
dump = np.sort(D, axis=1)
idx = np.argsort(D, axis=1)
idx_new = idx[:, 0:k+1]
dump_new = dump[:, 0:k+1]
# compute the pairwise heat kernel distances
dump_heat_kernel = np.exp(-dump_new/(2*t*t))
G = np.zeros((n_samples*(k+1), 3))
G[:, 0] = np.tile(np.arange(n_samples), (k+1, 1)).reshape(-1)
G[:, 1] = np.ravel(idx_new, order='F')
G[:, 2] = np.ravel(dump_heat_kernel, order='F')
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
elif kwargs['weight_mode'] == 'cosine':
# normalize the data first
X_normalized = np.power(np.sum(X*X, axis=1), 0.5)
for i in range(n_samples):
X[i, :] = X[i, :]/max(1e-12, X_normalized[i])
# compute pairwise cosine distances
D_cosine = np.dot(X, np.transpose(X))
# sort the distance matrix D in ascending order
dump = np.sort(-D_cosine, axis=1)
idx = np.argsort(-D_cosine, axis=1)
idx_new = idx[:, 0:k+1]
dump_new = -dump[:, 0:k+1]
G = np.zeros((n_samples*(k+1), 3))
G[:, 0] = np.tile(np.arange(n_samples), (k+1, 1)).reshape(-1)
G[:, 1] = np.ravel(idx_new, order='F')
G[:, 2] = np.ravel(dump_new, order='F')
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
# choose supervised neighborMode
elif kwargs['neighbor_mode'] == 'supervised':
k = kwargs['k']
# get true labels and the number of classes
y = kwargs['y']
label = np.unique(y)
n_classes = np.unique(y).size
# construct the weight matrix W in a fisherScore way, W_ij = 1/n_l if yi = yj = l, otherwise W_ij = 0
if kwargs['fisher_score'] is True:
W = lil_matrix((n_samples, n_samples))
for i in range(n_classes):
class_idx = (y == label[i])
class_idx_all = (class_idx[:, np.newaxis] & class_idx[np.newaxis, :])
W[class_idx_all] = 1.0/np.sum(np.sum(class_idx))
return W
# construct the weight matrix W in a reliefF way, NH(x) and NM(x,y) denotes a set of k nearest
# points to x with the same class as x, a different class (the class y), respectively. W_ij = 1 if i = j;
# W_ij = 1/k if x_j \in NH(x_i); W_ij = -1/(c-1)k if x_j \in NM(x_i, y)
if kwargs['reliefF'] is True:
# when xj in NH(xi)
G = np.zeros((n_samples*(k+1), 3))
id_now = 0
for i in range(n_classes):
class_idx = np.column_stack(np.where(y == label[i]))[:, 0]
D = pairwise_distances(X[class_idx, :])
D **= 2
idx = np.argsort(D, axis=1)
idx_new = idx[:, 0:k+1]
n_smp_class = (class_idx[idx_new[:]]).size
if len(class_idx) <= k:
k = len(class_idx) - 1
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx, (k+1, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = 1.0/k
id_now += n_smp_class
W1 = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
# when i = j, W_ij = 1
for i in range(n_samples):
W1[i, i] = 1
# when x_j in NM(x_i, y)
G = np.zeros((n_samples*k*(n_classes - 1), 3))
id_now = 0
for i in range(n_classes):
class_idx1 = np.column_stack(np.where(y == label[i]))[:, 0]
X1 = X[class_idx1, :]
for j in range(n_classes):
if label[j] != label[i]:
class_idx2 = np.column_stack(np.where(y == label[j]))[:, 0]
X2 = X[class_idx2, :]
D = pairwise_distances(X1, X2)
idx = np.argsort(D, axis=1)
idx_new = idx[:, 0:k]
n_smp_class = len(class_idx1)*k
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx1, (k, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx2[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = -1.0/((n_classes-1)*k)
id_now += n_smp_class
W2 = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W2) > W2
W2 = W2 - W2.multiply(bigger) + np.transpose(W2).multiply(bigger)
W = W1 + W2
return W
if kwargs['weight_mode'] == 'binary':
if kwargs['metric'] == 'euclidean':
G = np.zeros((n_samples*(k+1), 3))
id_now = 0
for i in range(n_classes):
class_idx = np.column_stack(np.where(y == label[i]))[:, 0]
# compute pairwise euclidean distances for instances in class i
D = pairwise_distances(X[class_idx, :])
D **= 2
# sort the distance matrix D in ascending order for instances in class i
idx = np.argsort(D, axis=1)
idx_new = idx[:, 0:k+1]
n_smp_class = len(class_idx)*(k+1)
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx, (k+1, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = 1
id_now += n_smp_class
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
if kwargs['metric'] == 'cosine':
# normalize the data first
X_normalized = np.power(np.sum(X*X, axis=1), 0.5)
for i in range(n_samples):
X[i, :] = X[i, :]/max(1e-12, X_normalized[i])
G = np.zeros((n_samples*(k+1), 3))
id_now = 0
for i in range(n_classes):
class_idx = np.column_stack(np.where(y == label[i]))[:, 0]
# compute pairwise cosine distances for instances in class i
D_cosine = np.dot(X[class_idx, :], np.transpose(X[class_idx, :]))
# sort the distance matrix D in descending order for instances in class i
idx = np.argsort(-D_cosine, axis=1)
idx_new = idx[:, 0:k+1]
n_smp_class = len(class_idx)*(k+1)
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx, (k+1, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = 1
id_now += n_smp_class
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
elif kwargs['weight_mode'] == 'heat_kernel':
G = np.zeros((n_samples*(k+1), 3))
id_now = 0
for i in range(n_classes):
class_idx = np.column_stack(np.where(y == label[i]))[:, 0]
# compute pairwise cosine distances for instances in class i
D = pairwise_distances(X[class_idx, :])
D **= 2
# sort the distance matrix D in ascending order for instances in class i
dump = np.sort(D, axis=1)
idx = np.argsort(D, axis=1)
idx_new = idx[:, 0:k+1]
dump_new = dump[:, 0:k+1]
t = kwargs['t']
# compute pairwise heat kernel distances for instances in class i
dump_heat_kernel = np.exp(-dump_new/(2*t*t))
n_smp_class = len(class_idx)*(k+1)
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx, (k+1, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = np.ravel(dump_heat_kernel, order='F')
id_now += n_smp_class
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
elif kwargs['weight_mode'] == 'cosine':
# normalize the data first
X_normalized = np.power(np.sum(X*X, axis=1), 0.5)
for i in range(n_samples):
X[i, :] = X[i, :]/max(1e-12, X_normalized[i])
G = np.zeros((n_samples*(k+1), 3))
id_now = 0
for i in range(n_classes):
class_idx = np.column_stack(np.where(y == label[i]))[:, 0]
# compute pairwise cosine distances for instances in class i
D_cosine = np.dot(X[class_idx, :], np.transpose(X[class_idx, :]))
# sort the distance matrix D in descending order for instances in class i
dump = np.sort(-D_cosine, axis=1)
idx = np.argsort(-D_cosine, axis=1)
idx_new = idx[:, 0:k+1]
dump_new = -dump[:, 0:k+1]
n_smp_class = len(class_idx)*(k+1)
G[id_now:n_smp_class+id_now, 0] = np.tile(class_idx, (k+1, 1)).reshape(-1)
G[id_now:n_smp_class+id_now, 1] = np.ravel(class_idx[idx_new[:]], order='F')
G[id_now:n_smp_class+id_now, 2] = np.ravel(dump_new, order='F')
id_now += n_smp_class
# build the sparse affinity matrix W
W = csc_matrix((G[:, 2], (G[:, 0], G[:, 1])), shape=(n_samples, n_samples))
bigger = np.transpose(W) > W
W = W - W.multiply(bigger) + np.transpose(W).multiply(bigger)
return W
import pandas as pd
from sklearn.model_selection import train_test_split #数据集划分
data = pd.read_excel(r'path')
data = data.drop(data[data['PM10']=='—'].index) #去除缺失数据
data.head()
x = data.iloc[:,7:]
y = data['AQI']
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=40)
kwargs_W = {"metric":"euclidean","neighbor_mode":"knn","weight_mode":"heat_kernel","k":5,'t':1}
W = construct_W(x, **kwargs_W)
score = lap_score(x.values, W=W)
idx = feature_ranking(score)
score, idx
```
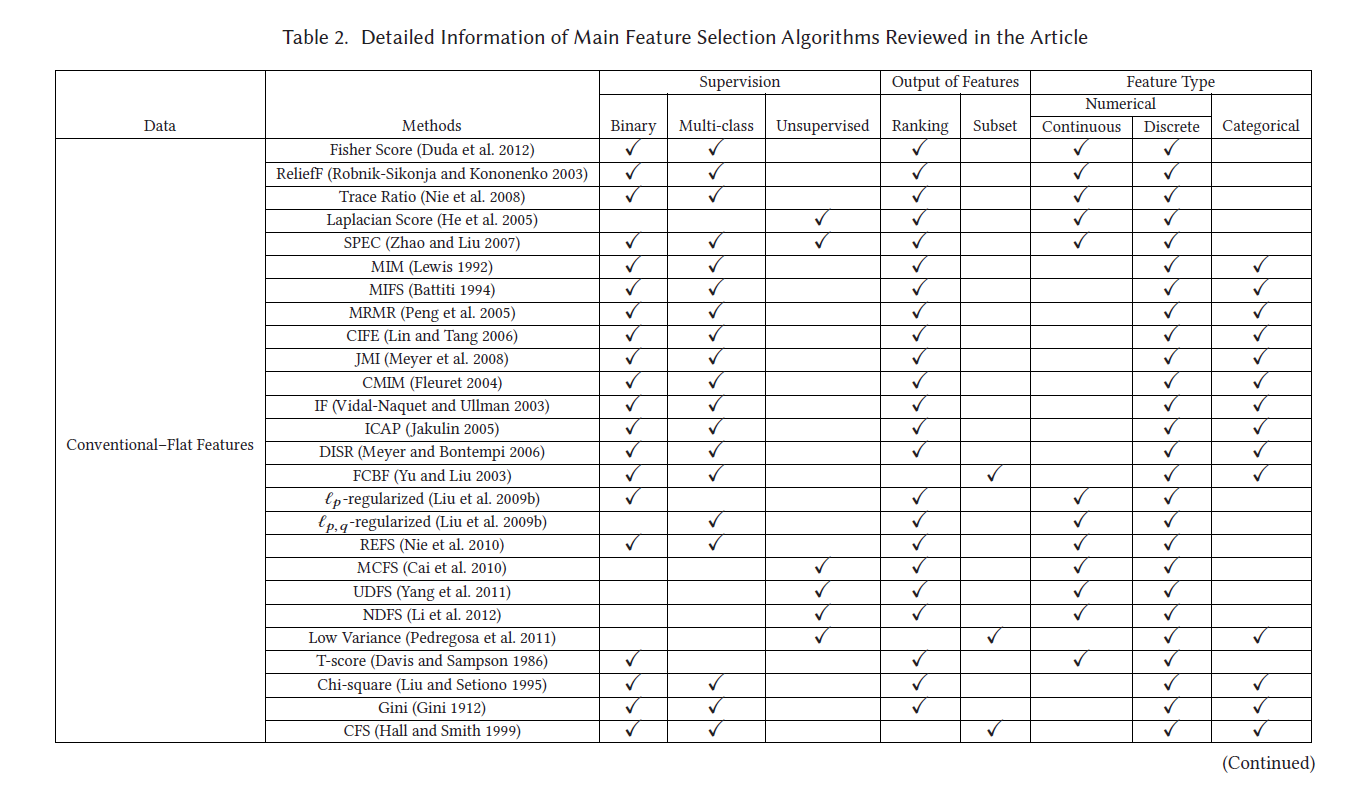
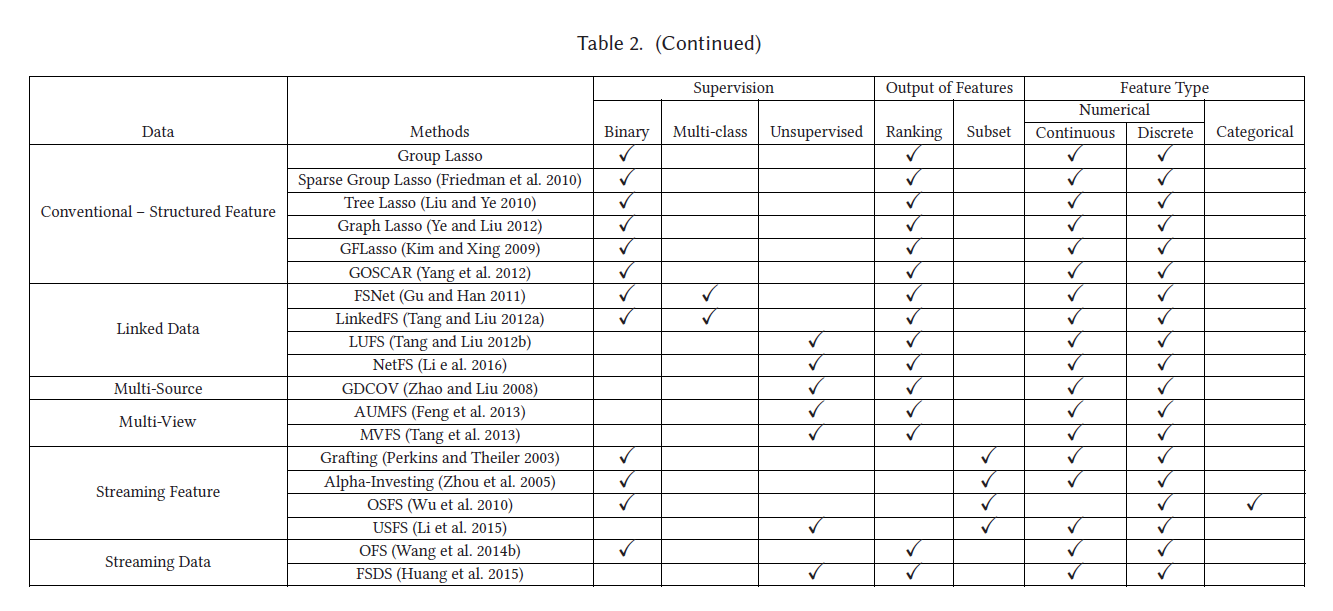
[1] LI J, CHENG K, WANG S, 等. Feature Selection:A Data Perspective[J/OL]. ACM Computing Surveys, 2018, 50(6): 1-45. https://doi.org/10.1145/3136625.
[2]CHANDRASHEKAR G, SAHIN F. A survey on feature selection methods[J/OL]. Computers & Electrical Engineering, 2014, 40(1): 16-28. DOI:10.1016/j.compeleceng.2013.11.024.
[3]https://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/
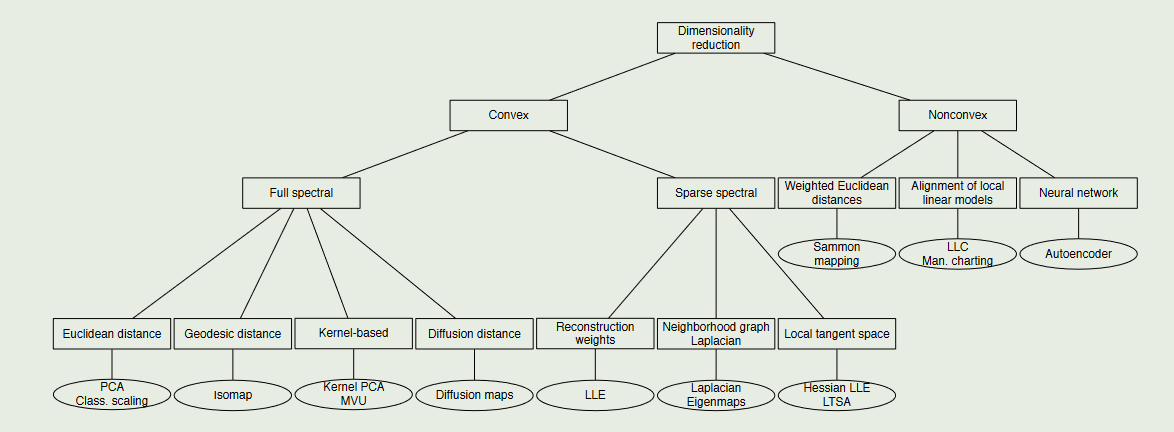
[4]Van Der Maaten, Laurens, Eric Postma, and Jaap Van den Herik."Dimensionality reduction:a comparative." J Mach Learn Res 10.66-71 (2009).
[5]HE X, CAI D, NIYOGI P.Laplacian Score for Feature Selection[C/OL]//Advances in Neural Information Processing Systems: 卷 18. MIT Press, 2005[2023-07-07].
推荐阅读
⭐⭐⭐LI J, CHENG K, WANG S, 等. Feature Selection: A Data Perspective[J/OL]. ACM Computing Surveys, 2018, 50(6): 1-45. https://doi.org/10.1145/3136625.
⭐⭐Van Der Maaten, Laurens, Eric Postma, and Jaap Van den Herik."Dimensionality reduction:a comparative." J Mach Learn Res 10.66-71 (2009).




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix