
MySQL函数学习
常见函数:
进阶4:常见函数
一、单行函数
1、字符函数
concat拼接
substr截取子串
upper转换成大写
lower转换成小写
trim去前后指定的空格和字符
ltrim去左边空格
rtrim去右边空格
replace替换
lpad左填充
rpad右填充
instr返回子串第一次出现的索引,如果找不到就返回0
length 获取字节个数
ifnull 判断是否为空
查看字符集编码show variables like '%char%';
mysql> select concat(upper(last_name),lower(first_name)) from employees;函数可以嵌套函数
mysql> select substr('李莫愁爱上了陆展元',7,3) out_put;索引从1开始,3表示截取长度
+-----------+
| out_put |
+-----------+
| 陆展元 |
+-----------+
mysql> select instr('杨不悔爱上了殷六侠','殷六侠') out_put ;
+---------+
| out_put |
+---------+
| 7 |
+---------+
mysql> select (trim('aa' from 'aaaaaaaa abc aaaaaa ')) as out_put;
+----------------+只会去掉开头和结尾的
| out_put |
+----------------+
| abc aaaaaa |
+----------------+
mysql> select lpad('aa',10,'bb');
+--------------------+
| lpad('aa',10,'bb') |
+--------------------+
| bbbbbbbbaa |
+--------------------+
mysql> select replace('abcd','ab','ll');
+---------------------------+
| replace('abcd','ab','ll') |
+---------------------------+
| llcd |
+---------------------------+
1 row in set (0.00 sec)
2、数学函数,第二个参数都是小数位数
round 四舍五入
rand 随机数
floor向下取整
ceil向上取整>=该数的整数
mod取余
truncate截断
mysql> select round(-1.55);
+--------------+
| round(-1.55) |
+--------------+
| -2 |
+--------------+
mysql> select round(-1.55,1);保留的小数位数
+----------------+
| round(-1.55,1) |
+----------------+
| -1.6 |
+----------------+
mysql> select ceil(1.01);
+------------+
| ceil(1.01) |
+------------+
| 2 |
+------------+
mysql> select ceil(-1.02);
+-------------+
| ceil(-1.02) |
+-------------+
| -1 |
+-------------+
mysql> select truncate(-1.02,1);
+-------------------+
| truncate(-1.07,1) |
+-------------------+
| -1.0 |
+-------------------+
1 row in set (0.00 sec)
mysql> select mod(10,-3);
+------------+
| mod(10,-3) |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> select mod(-10,-3);
+-------------+
| mod(-10,-3) |
+-------------+
| -1 |
+-------------+
3、日期函数
now当前系统日期+时间
curdate当前系统日期
curtime当前系统时间
str_to_date 将字符转换成日期
date_format将日期转换成字符
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2018-04-08 13:55:52 |
+---------------------+
1 row in set (0.02 sec)
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2018-04-08 |
+------------+
1 row in set (0.00 sec)
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 13:57:08 |
+-----------+
mysql> select year(now());
+-------------+
| year(now()) |
+-------------+
| 2018 |
+-------------+
1 row in set (0.00 sec)
mysql> select curtime('1998-1-1');
mysql> select year('1998-1-1');//month
+------------------+
| year('1998-1-1') |
+------------------+
| 1998 |
+------------------+
mysql> select month('1998-1-1');
+-------------------+
| month('1998-1-1') |
+-------------------+
| 1 |
+-------------------+
1 row in set (0.02 sec)
mysql> select monthname('1998-1-1');
+-----------------------+
| monthname('1998-1-1') |
+-----------------------+
| January |
日期字符转换
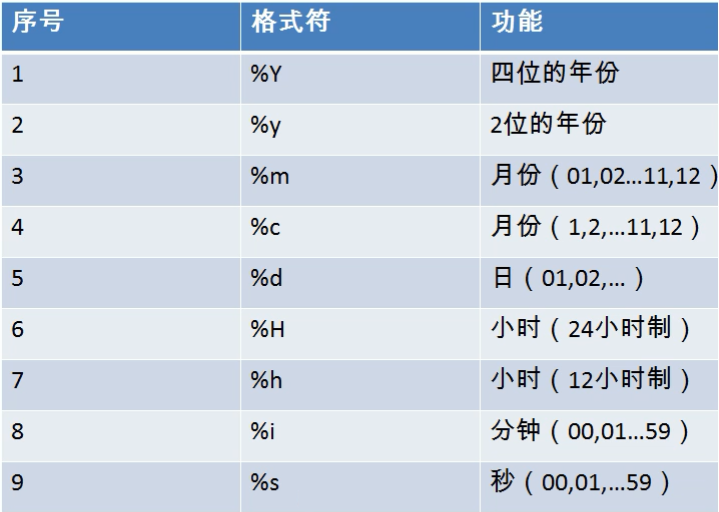
mysql> select str_to_date('1998-3-2','%Y-%c-%d') as out_put;
+------------+
| out_put |
+------------+
| 1998-03-02 |
+------------+
mysql> select* from employees where hiredate=str_to_date('4-3 1992','%c-%d %Y');
mysql> select date_format(now(),'%Y年%c月%d日') as out_put;
+------------------+
| out_put |
+------------------+
| 2018年4月08日 |
+------------------+
查询有奖金的员工名和入职日期(XX月/XX日 XX年)
mysql> select last_name,date_format(hiredate,'%c月%d日 %Y年') from employees where commission_pct is not null;
+------------+------------------------------------------+
| last_name | date_format(hiredate,'%c月%d日 %Y年') |
+------------+------------------------------------------+
| Russell | 12月23日 2002年 |
4、流程控制函数
if 处理双分支
case语句 处理多分支
case 判断的字段或表达式
when情况1 then语句1
when情况2 then语句n
…
Else 语句n
end
mysql> select if(10>5,'大','小') as out_put;
+---------+
| out_put |
+---------+
| 大 |
+---------+
mysql> select last_name,commission_pct,if(commission_pct is null,'没奖金,呵呵','有奖金,嘻嘻') from employees out_put;
+-------------+----------------+----------------------------------------------------------------------+
| last_name | commission_pct | if(commission_pct is null,'没奖金,呵呵','有奖金,嘻嘻') |
+-------------+----------------+----------------------------------------------------------------------+
| K_ing | NULL | 没奖金,呵呵 |
查询员工工资,要求
部门号=30,显示工资的1.1倍
部门号=40,显示工资的1.2倍
部门号=50,显示工资的1.3倍
其他部门,显示工资为原工资
mysql> select last_name,department_id,
-> case department_id
-> when 30 then salary*1.1
-> when 40 then salary*1.2
-> when 50 then salary*1.3
-> else salary
-> end as new_salary
-> from employees;
+-------------+----------+---------------+------------+
| last_name | salary | department_id | new_salary |
+-------------+----------+---------------+------------+
| K_ing | 24000.00 | 90 | 24000.00 |
| Kochhar | 17000.00 | 90 | 17000.00 |
查询员工工资情况
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>10000,显示C级别
否则,显示D级别
mysql> select last_name,salary,department_id, case
when salary>20000 then 'A'
when salary>15000 then 'B'
when salary>10000 then 'C'
else 'D' end as new_salary
from employees
order by department_id asc;
+-------------+----------+---------------+------------+
| last_name | salary | department_id | new_salary |
+-------------+----------+---------------+------------+
| Grant | 7000.00 | NULL | D |
| Whalen | 4400.00 | 10 | D |
| Hartstein | 13000.00 | 20 | C |
5、其他函数
version版本
database当前库
user当前连接用户
二、分组函数,统计,组函数,聚合函数
sum 求和
max 最大值
min 最小值
avg 平均值
count 计数
特点:
1、以上五个分组函数都忽略null值,除了count(*)
2、sum和avg一般用于处理数值型
max、min、count可以处理任何数据类型
3、都可以搭配distinct使用,用于统计去重后的结果
4、count的参数可以支持:
字段、*、常量值,一般放1
建议使用 count(*)
mysql> select sum(salary) from employees;
+-------------+
| sum(salary) |
+-------------+
| 691400.00 |
+-------------+
1 row in set (0.00 sec)
mysql> select avg(salary) from employees;
+-------------+
| avg(salary) |
+-------------+
| 6461.682243 |
+-------------+
1 row in set (0.00 sec)
mysql> select min(salary) from employees;
+-------------+
| min(salary) |
+-------------+
| 2100.00 |
+-------------+
1 row in set (0.00 sec)
mysql> select max(salary) from employees;
+-------------+
| max(salary) |
+-------------+
| 24000.00 |
+-------------+
1 row in set (0.00 sec)
mysql> select count(salary) from employees;
+---------------+
| count(salary) |
+---------------+
| 107 |
+---------------+
1 row in set (0.00 sec)
sum和avg一般支持数值型
max和min支持字符型,能排序的都行
数学的忽略null
可以和distinct搭配去重运算
mysql> select sum(distinct salary),sum(salary) from employees;
+----------------------+-------------+
| sum(distinct salary) | sum(salary) |
+----------------------+-------------+
| 397900.00 | 691400.00 |
+----------------------+-------------+
mysql> select count(*) from employees;
+----------+
| count(*) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
mysql> select count(1) from employees;相当于多了一列,都是1,实际也是统计多少行,写2也行
+----------+
| count(1) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
和分组函数一起查询有限制:要求是group by
mysql> select avg(salary),employee_id from employees;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'myemployees.employees.employee_id'; this is incompatible with sql_mode=only_full_group_by
查询最大入职时间和最小入职时间相差天数
mysql> select datediff(max(hiredate),min(hiredate)) diffience from employees;
+-----------+
| diffience |
+-----------+
| 8735 |
+-----------+
1 row in set (0.00 sec)
查询部门编号为90的员工个数
mysql> select count(*) nums from employees where department_id=90;
+------+
| nums |
+------+
| 3 |
+------+
1 row in set (0.00 sec)
进阶5:分组查询
语法:
select 查询的字段,分组函数
from 表
group by 分组的字段
特点:
1、可以按单个字段分组
2、和分组函数一同查询的字段最好是分组后的字段
3、分组筛选
针对的表 位置 关键字
分组前筛选: 原始表 group by的前面 where
分组后筛选: 分组后的结果集 group by的后面 having
4、可以按多个字段分组,字段之间用逗号隔开
5、可以支持排序
6、having后可以支持别名
查询每个工种最高工资
mysql> select max(salary),job_id from employees group by job_id;
+-------------+------------+
| max(salary) | job_id |
+-------------+------------+
| 8300.00 | AC_ACCOUNT |
| 12000.00 | AC_MGR |
| 4400.00 | AD_ASST |
添加筛选条件
邮箱包含a字符
mysql> select avg(salary),department_id from employees where email like '%a%' group by department_id;
+--------------+---------------+
| avg(salary) | department_id |
+--------------+---------------+
| 7000.000000 | NULL |
| 4400.000000 | 10 |
| 9500.000000 | 20 |
| 4460.000000 | 30 |
| 6500.000000 | 40 |
| 3496.153846 | 50 |
| 6200.000000 | 60 |
| 10000.000000 | 70 |
| 8535.294118 | 80 |
| 17000.000000 | 90 |
| 8166.666667 | 100 |
+--------------+---------------+
11 rows in set (0.00 sec)
查询那个部门的员工个数大于2
1.查询每个部门的员工个数
2.根据1的结果进行筛选
mysql> select count(*),department_id from employees group by department_id;
+----------+---------------+
| count(*) | department_id |
+----------+---------------+
| 1 | NULL |
| 1 | 10 |
| 2 | 20 |
| 6 | 30 |
+----------+---------------+
12 rows in set (0.01 sec)
Having用于分组后的筛选
mysql> select count(*),department_id from employees group by department_id having count(*)>2;
+----------+---------------+
| count(*) | department_id |
+----------+---------------+
| 6 | 30 |
| 45 | 50 |
分组前的筛选用where,筛选数据源是原来的表
分组后的筛选用having,筛选数据源是分组后的结果表
分组函数做条件肯定用having,例如最大值大于10的最大值
能用分组前当然用分组前,考虑性能
#按表达式或者函数分组
按员工姓名的长度分组,查询每一组的员工个数,并筛选长度大于5的
1. 查询每个长度的员工个数
2. 筛选
mysql> select count(*) num,length(last_name) len_name from employees group by len_name having num>5 order by num;
+-----+----------+
| num | len_name |
+-----+----------+
| 7 | 8 |
| 8 | 9 |
where后 不支持别名
group by 和order by支持
orical数据库不支持
#按多个字段分组
查询每个部门,每个工种的平均工资
mysql> select avg(salary),department_id,job_id from employees group by department_id,job_id; 顺序一样
+--------------+---------------+------------+
| avg(salary) | department_id | job_id |
+--------------+---------------+------------+
| 7000.000000 | NULL | SA_REP |
sum和avg一般支持数值型
max和min支持字符型,能排序的都行
数学的忽略null
可以和distinct搭配去重运算
mysql> select sum(distinct salary),sum(salary) from employees;
+----------------------+-------------+
| sum(distinct salary) | sum(salary) |
+----------------------+-------------+
| 397900.00 | 691400.00 |
+----------------------+-------------+
mysql> select count(*) from employees;
+----------+
| count(*) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
mysql> select count(1) from employees;相当于多了一列,都是1,实际也是统计多少行,写2也行
+----------+
| count(1) |
+----------+
| 107 |
+----------+
1 row in set (0.00 sec)
和分组函数一起查询有限制:要求是group by
mysql> select avg(salary),employee_id from employees;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'myemployees.employees.employee_id'; this is incompatible with sql_mode=only_full_group_by
查询最大入职时间和最小入职时间相差天数
mysql> select datediff(max(hiredate),min(hiredate)) diffience from employees;
+-----------+
| diffience |
+-----------+
| 8735 |
+-----------+
1 row in set (0.00 sec)
查询部门编号为90的员工个数
mysql> select count(*) nums from employees where department_id=90;
+------+
| nums |
+------+
| 3 |
+------+
1 row in set (0.00 sec)
进阶5:分组查询
语法:
select 查询的字段,分组函数
from 表
group by 分组的字段
特点:
1、可以按单个字段分组
2、和分组函数一同查询的字段最好是分组后的字段
3、分组筛选
针对的表 位置 关键字
分组前筛选: 原始表 group by的前面 where
分组后筛选: 分组后的结果集 group by的后面 having
4、可以按多个字段分组,字段之间用逗号隔开
5、可以支持排序
6、having后可以支持别名
查询每个工种最高工资
mysql> select max(salary),job_id from employees group by job_id;
+-------------+------------+
| max(salary) | job_id |
+-------------+------------+
| 8300.00 | AC_ACCOUNT |
| 12000.00 | AC_MGR |
| 4400.00 | AD_ASST |
添加筛选条件
邮箱包含a字符
mysql> select avg(salary),department_id from employees where email like '%a%' group by department_id;
+--------------+---------------+
| avg(salary) | department_id |
+--------------+---------------+
| 7000.000000 | NULL |
| 4400.000000 | 10 |
| 9500.000000 | 20 |
| 4460.000000 | 30 |
| 6500.000000 | 40 |
| 3496.153846 | 50 |
| 6200.000000 | 60 |
| 10000.000000 | 70 |
| 8535.294118 | 80 |
| 17000.000000 | 90 |
| 8166.666667 | 100 |
+--------------+---------------+
11 rows in set (0.00 sec)
查询那个部门的员工个数大于2
1.查询每个部门的员工个数
2.根据1的结果进行筛选
mysql> select count(*),department_id from employees group by department_id;
+----------+---------------+
| count(*) | department_id |
+----------+---------------+
| 1 | NULL |
| 1 | 10 |
| 2 | 20 |
| 6 | 30 |
+----------+---------------+
12 rows in set (0.01 sec)
Having用于分组后的筛选
mysql> select count(*),department_id from employees group by department_id having count(*)>2;
+----------+---------------+
| count(*) | department_id |
+----------+---------------+
| 6 | 30 |
| 45 | 50 |
分组前的筛选用where,筛选数据源是原来的表
分组后的筛选用having,筛选数据源是分组后的结果表
分组函数做条件肯定用having,例如最大值大于10的最大值
能用分组前当然用分组前,考虑性能
#按表达式或者函数分组
按员工姓名的长度分组,查询每一组的员工个数,并筛选长度大于5的
1. 查询每个长度的员工个数
2. 筛选
mysql> select count(*) num,length(last_name) len_name from employees group by len_name having num>5 order by num;
+-----+----------+
| num | len_name |
+-----+----------+
| 7 | 8 |
| 8 | 9 |
where后 不支持别名
group by 和order by支持
orical数据库不支持
#按多个字段分组
查询每个部门,每个工种的平均工资
mysql> select avg(salary),department_id,job_id from employees group by department_id,job_id; 顺序一样
+--------------+---------------+------------+
| avg(salary) | department_id | job_id |
+--------------+---------------+------------+
| 7000.000000 | NULL | SA_REP |

