


TF-IDF算法确定文章主题词
网络新闻复杂多样,人们都喜欢看感兴趣的新闻,对于英文新闻也是如此,我们希望能够将长篇的英文文章例如新闻的主题关键词提取出来,以便于读者对新闻兴趣点进行快速选择,提高阅读效率。我们从网络上摘取大量的英文新闻文章进行调研,找到相关特征,进行主题关键词提取,提供给读者,进行阅读选择。
1. 模型建立

2. 特征选择
我们选择的是三个特征,一个词是否能成为这篇文章的主题词与其在这篇文章的频率成正比,与其在其他文章的出现成反比,也就是说主题词具有区分此篇文章与其他文章的特性,最后我们还根据英文新闻的特点将是否首尾段作为主题权重的重要构成部分。
3. 采用算法
前两个特征采用TF-IDF算法来实现。
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。

#include <windows.h>
#include <math.h>
#include <time.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
#define N 5269 //文献数目
#define textN 10 //题目数目
#define ERROR 1
#define OK 0
const int WORD_LENGTH = 30;//定义单个单词最大长度
char temp[WORD_LENGTH];//定义用以临时存放单词的数组
typedef struct Node {
char word[WORD_LENGTH] = { '\0' };
int time = 0;
int textnum = 0;
double weight = 0;
}wordNode, *wordLink;
char Libword[900][WORD_LENGTH] = { 0 }; //900条停用词库
int wordleng = 0; //词库中实际词条数目
wordNode sumWord[1000];//文章词表
int wordNum = 0;//文章中的非重单词数
int sumWordNum = 0;//文章总词数
int DoLibStop(char *name, char memory[][WORD_LENGTH])
{
FILE *cp = fopen(name, "r");//词库位置
char ch;
while (!feof(cp)) //读取词库
{
ch = fgetc(cp);
for (int i = 0; ch != 13 && i<22 && ch != 10; i++)//回车区分词
{
Libword[wordleng][i] = ch;
ch = fgetc(cp);
}
// std::cout<<(word[wordleng]); //屏幕输出。临时
wordleng++;
}
fclose(cp); //关闭停用词库
return wordleng;
}
void wordDelSpe(char word[]) //去掉特殊字符
{
int i, k, j;
char *specialChar = ",.;:'“”?!><+=|*&^%$#@\"[](){}0123456789";//定义特殊字符集
for (i = 0; i<strlen(word); i++)
{
//筛选并去除字符串中的特殊字符
for (k = 0; k<strlen(specialChar); k++)
{
if (word[i] == specialChar[k])
{
j = i;
while (j<strlen(word))
{
word[j] = word[j + 1];
j++;
}
i--;
break;
}
}
}
}
bool wordCmpStop(char *word)//将人称代词及其他常用词去掉
{
int simNum = wordleng;
for (int i = 0; i<strlen(word); i++)//筛选并将字符串中的大写字母转化为小写字母
if (word[i] >= 'A'&& word[i] <= 'Z')
word[i] += 32;
for (int i = 0; i<simNum; i++)
if (strcmp(word, Libword[i]) == 0)
return true;
return false;
}
void wordSearch(char *word, int &wordnum) {
int i = 0;
while (i < wordnum && (strcmp(sumWord[i].word, word) != 0))
{
i++;
}
if (i < wordnum)
sumWord[i].time++;
if (i == wordnum)
{
strcpy(sumWord[i].word, word);
wordnum++;
sumWord[i].time = 1;
}
sumWordNum += 1;
}
void doArticle(char *file0)
{
FILE *file;
if ((file = fopen(file0, "r")) == NULL) {
//这里是绝对路径,基于XCode编译器查找方便的需求
printf("%s文件读取失败!", file0);
system("pause");
exit(1);
}
while ((fscanf(file, "%s", temp)) != EOF)
{
wordDelSpe(temp);
if (wordCmpStop(temp) == true)
{
sumWordNum += 1;
continue;
}
wordSearch(temp, wordNum);
}
fclose(file);//关闭文件
}
void copyNode(wordNode& node1, wordNode &node2)//node2复制到node1
{
strcpy(node1.word, node2.word);
node1.time = node2.time;
node1.textnum = node2.textnum;
node1.weight = node2.weight;
}
void sortWord()//直接插入排序
{
wordNode t;
int i, j;
/*cout << wordNum << endl;*/
for (i = 1; i < wordNum; i++)
{
copyNode(t, sumWord[i]);
for (j = i - 1; j >= 0 && sumWord[j].weight<t.weight; j--)
{
copyNode(sumWord[j + 1], sumWord[j]);
}
copyNode(sumWord[j + 1], t);
}
}
void fileCount(char file[N][50])
{
int i, j;
FILE *f;
for (i = 0; i <N; i++)
{
f = fopen(file[i], "r");
if (!f)
{
printf("%s文件读取失败!", file[i]);
/*system("pause");
exit(1);*/
continue;
}
while ((fscanf(f, "%s", temp)) != EOF)
{
wordDelSpe(temp);
j = 0;
while (j < wordNum && (strcmp(sumWord[j].word, temp) != 0))
{
j++;
}
if (j < wordNum)
sumWord[j].textnum++;//文章数++
}
fclose(f);//关闭文件
}
}
void calWeight(wordNode *sumWord, int wordNum)//计算权重
{
int i;
for (i = 0; i < wordNum; i++)
sumWord[i].weight = (sumWord[i].time * 1.0 / sumWordNum)*log((N*1.0) / (sumWord[i].textnum + 1));
}
int numWei(int n)//计算数据位数
{
if (n / 10 == 0)
return 1;
else if (n / 100 == 0)
return 2;
else if (n / 1000 == 0)
return 3;
else
return 4;
}
void fileNameMake(char file[][50], int n)//批量生成文件地址和名字
{
int i = 0, j = 0, i1, num;
for (i = 0; i < n; i++)
{
strcpy(file[i], "fileLib\\\\txt");
num = numWei(i + 1);
//cout << num << endl;
i1 = i + 1;
for (j = num - 1; j >= 0; j--)
{
*(file[i] + 12 + j) = i1 % 10 + 48;
i1 = i1 / 10;
}
strcpy(file[i] + 12 + num, ".txt");
/*cout << file[i] << endl;*/
/*if (strcmp(file[i] , "txt\\\\txt00.txt")==0)
cout << i << endl;*/
}
}
void saveNameMake(char savefile[][50], int n)//批量生成中间存储文件地址和名
{
int i = 0, j = 0, i1, num;
for (i = 0; i < n; i++)
{
strcpy(savefile[i], "savefile\\\\save");
num = numWei(i + 1);
//cout << num << endl;
i1 = i + 1;
for (j = num - 1; j >= 0; j--)
{
*(savefile[i] + 14 + j) = i1 % 10 + 48;
i1 = i1 / 10;
}
strcpy(savefile[i] + 14 + num, ".txt");
}
}
void textNameMake(char textfile[][50], int n)
{
int i = 0, j = 0, i1, num;
for (i = 0; i < n; i++)
{
strcpy(textfile[i], "textfile\\\\text");
num = numWei(i + 1);
//cout << num << endl;
i1 = i + 1;
for (j = num - 1; j >= 0; j--)
{
*(textfile[i] + 14 + j) = i1 % 10 + 48;
i1 = i1 / 10;
}
strcpy(textfile[i] + 14 + num, ".txt");
//cout << textfile[i] << endl;
/*if (strcmp(file[i] , "txt\\\\txt00.txt")==0)
cout << i << endl;*/
}
}
void clearSumWord()//清空数组
{
for (int i = 0; i < 1000; i++)
{
sumWord[i].weight = 0;
sumWord[i].time = 0;
sumWord[i].textnum = 0;
strcpy(sumWord[i].word, "");
}
}
void doArticleLocal(char *file0)//首尾关键字权重增加
{
FILE *file;
int i;
if ((file = fopen(file0, "r")) == NULL) {
//这里是绝对路径,基于XCode编译器查找方便的需求
printf("%s文件读取失败!",file0);
system("pause");
exit(1);
}
while ((fscanf(file, "%s", temp)) != EOF)
{
if (temp[strlen(temp) - 1] == '#')
{
/*cout << "遇到了#" << endl;*/
break;
}
wordDelSpe(temp);
for (i = 0; i<strlen(temp); i++)//筛选并将字符串中的大写字母转化为小写字母
if (temp[i] >= 'A'&& temp[i] <= 'Z')
temp[i] += 32;
for (i = 0; i < wordNum; i++)
{
if (!strcmp(temp, sumWord[i].word))
{
sumWord[i].weight *= 1.5;
/*cout << "改了" << endl;*/
}
}
}
while ((fscanf(file, "%s", temp)) != EOF&&temp[0] != '#') {}//再次遇到#号,最后一段
while ((fscanf(file, "%s", temp)) != EOF)
{
if (temp[0] == '*')
{
/*cout << "遇到了*" << endl;*/
break;
}
wordDelSpe(temp);
for (i = 0; i<strlen(temp); i++)//筛选并将字符串中的大写字母转化为小写字母
if (temp[i] >= 'A'&& temp[i] <= 'Z')
temp[i] += 32;
for (i = 0; i < wordNum; i++)
{
if (!strcmp(temp, sumWord[i].word))
sumWord[i].weight *= 1.5;
}
}
fclose(file);//关闭文件
}
void doArticleAll(char *file0,char file[][50],char *savefile,int id)
{
/*cout << "correctNum" << correctNum << endl;*/
int i;
char ans; //答案
doArticle(file0); //处理题目文本
fileCount(file); //统计文件库中单词出现次数
calWeight(sumWord, wordNum); //计算权重
sortWord(); //排序
FILE *p = fopen(savefile, "w"); //文本输出
fprintf(p, " word \t词频\t文章数\t权重\n"); //输出到文档结果
fprintf(p, "本文共%d个词,%d个不重复词\n", sumWordNum, wordNum);
doArticleLocal(file0);//根据位置调整权值
for (i = 0; i < wordNum; i++)
{
fprintf(p, "%-16s\t%d\t%d\t%f\n", sumWord[i].word, sumWord[i].time, sumWord[i].textnum, sumWord[i].weight);
}
fclose(p);
std::cout << "第"<<id+1<<"题结果成功输出到文件:" << savefile << endl;
std::cout << "本文得到的五个关键词:" << endl;
for (i = 0; i < 5; i++)
cout << sumWord[i].word << " ";
cout << endl<<endl;
}
void main(int n, char *arg[])
{
char textfile[textN][50] = { '\0' }; //题目名字
char savefile[textN][50] = { '\0' }; //保存文件
char file[N][50] = { '\0' }; //需要检索的文献
//char *savefile1 = "savefile\\save.txt"; //结果存放文档
char *LibStop = "stopLib\\stop.txt"; //停用词库
//char *file0 = "textfile\\text1.txt";
//char *file0 = "text2.txt";
clock_t start0, finish0; //程序运行时间
double sftime0;
start0 = clock();
fileNameMake(file, N);
textNameMake(textfile, textN);
saveNameMake(savefile, textN);
cout << endl;
wordleng = DoLibStop(LibStop, Libword);//停用词处理
/*cout << file0 << "hah" << endl;*/
for (int k = 0; k < textN; k++)
{
doArticleAll(textfile[k], file, savefile[k], k);
clearSumWord();
}
/*cout << "correctNum" << correctNum << endl;
cout << "answerNum" << answerNum << endl;*/
finish0 = clock();
sftime0 = (double)(finish0 - start0) / CLOCKS_PER_SEC;//计算用时
std::cout << endl<< "共用时间:" << sftime0 << "秒." << endl;
system("pause");
}
fileLib 是语料库 共5269个英文文档,stopLib 是停用词库,savefile 是权重输出文档,textfile 是实验用例(第一段结尾和最后一段开头添加#)。

实验输出每篇实验用例的五个关键词
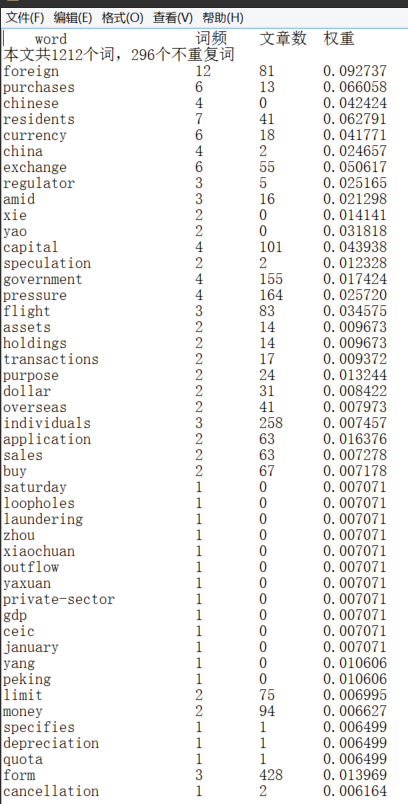
一篇文章的权重输出表

