
一:文中几个概念
h:统称索引的高度;
h1:主键索引的高度;
h2:辅助索引的高度;
k:非叶子节点扇区个数。
二:索引结构
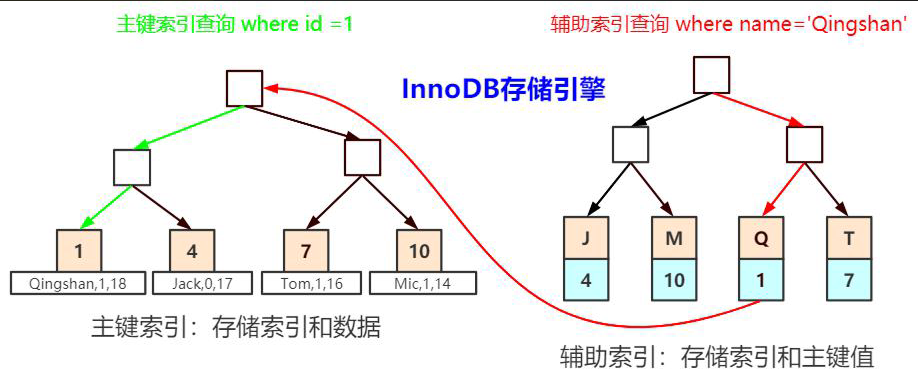
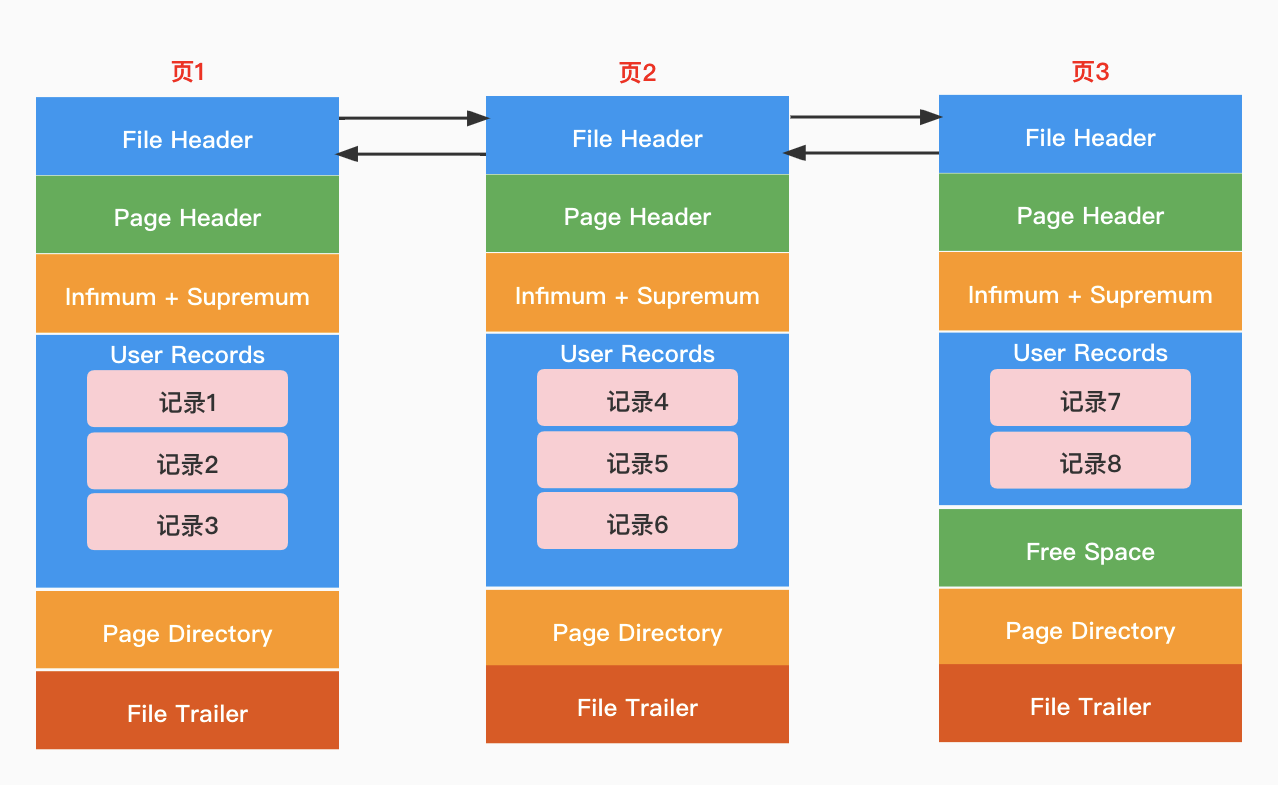
叶子节点其实是双向链表,而叶子节点内的行数据是单向链表,该图未体现。
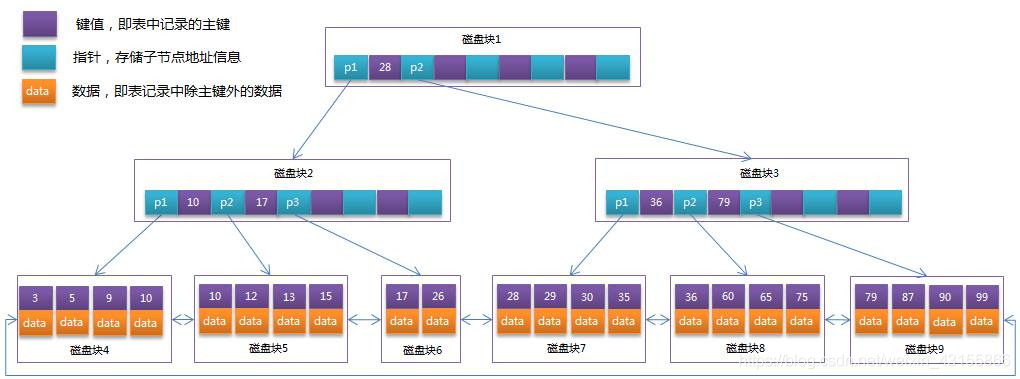
磁盘块其实是页,用操作系统中的术语来表达而已。
InnoDB中使用的是B+树聚集索引,主键索引叶子节点有整行的数据,辅助索引有主键值(用于回表查询)和索引值。
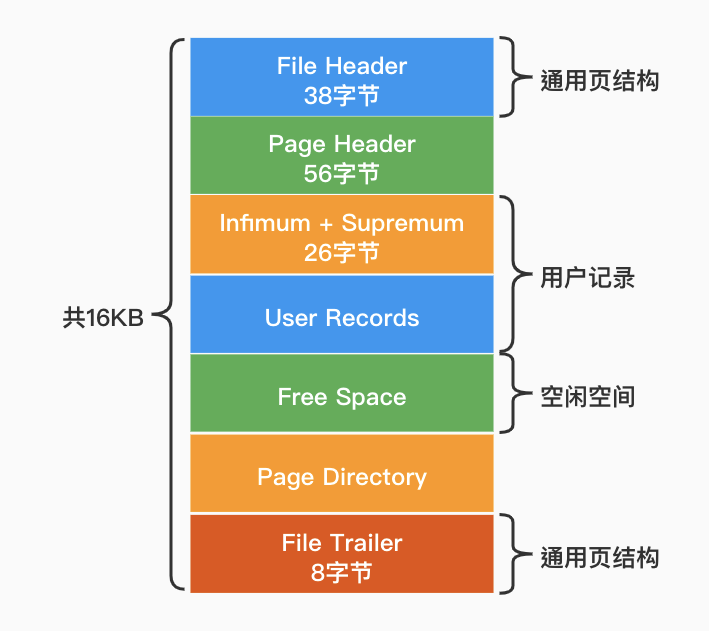
2.1 页的概念
Mysql的InnoDB是以页为存储单位的,每个B+Tree的节点都是一个页的大小,默认一页的大小是16K(与操作系统数据读取相关)。
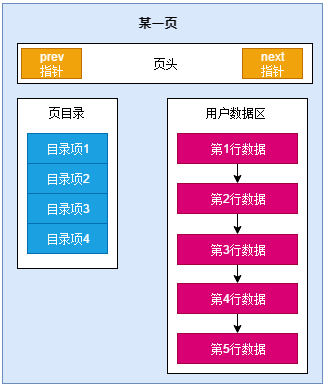
数据页(即叶子节点)
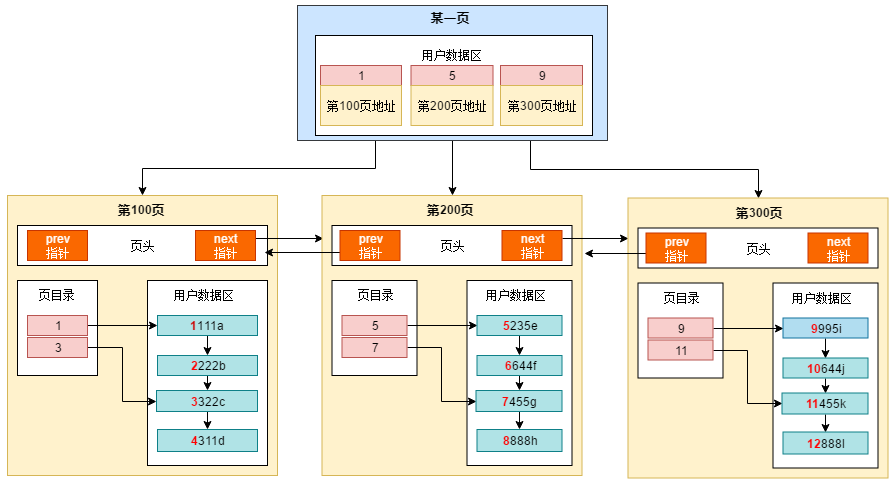
2.2 索引高度h与页面I/O数的关系
每次查询都要访问到叶子结点,其访问的页面数正好就是索引的高度h。例如,一次主键上的点查询SELECT * FROM USER WHERE id=1,那么要查询h1个页面才能找到叶子结点里的行数据,也即进行h1次页面I/O。(另外,二级索引基本都加载在内存里了,这里我们暂忽略这种情况。)
综上,查询对应的页面I/O数跟利用的索引有关,主要分为以下几种情况:
- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,但跟点查询的原理类似,读者可自行分析;
- 全表查询:B+树的叶子结点是通过链表连接起来的,对于全表查询,需要从头到尾将所有的叶子结点访问一遍。
2.3 索引高度理论计算
索引页(非叶子节点)中可以分割为多个扇区,每个扇区再指向某子节点(某页)。
假设非叶子节点扇区数为k个、高度h、叶子结点的行记录数为n,则叶子结点数为k(h-1),总记录数为k(h-1)*n。
InnoDB每个页面默认16KB,假设主键是4B的int类型。对于非叶子节点,每个主键值后有个页号4B,还有6B的其他数据(参考《MySQL技术内幕:InnoDB存储引擎》),那么扇区个数k=16KB/(4B+4B+6B)≈1170。
假设每行记录大小为1KB,则每个叶子结点可以容纳的记录数n=16KB/1KB=16。
在高度h=3时,叶子结点数=1170^2 ≈137W,总记录数=1170^2*16=2190W!!也就是说,InnoDB通过三次索引页面的I/O,即可索引2190W行记录。
同理,在高度h=4时,总行数=1170^3*16≈256亿条!
三、动手查看索引真实高度
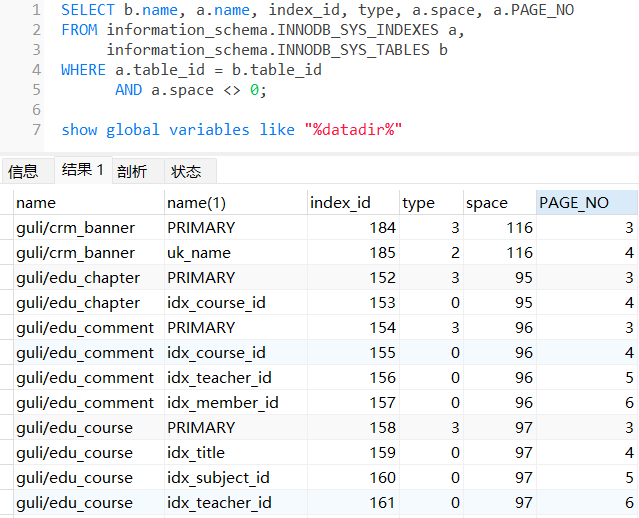
SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO
FROM information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE a.table_id = b.table_id
AND a.space <> 0;
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 01 00 00 00 00 00 00 00 9a |..........|
0000c04a
这里,49216表示的是16384*3+64,即从第3个页内偏移量64位置开始读取10个字节,前两个字节为PAGE_LEVEL,后8个字节是index_id,就是上图中看到的index_id=154(0x9a(十六进制) = 154(十进制))的主键索引,这里PAGE_LEVEL为00 01,那么索引树的高度就为2。
四、插入10w条数据查看索引的高度
delimiter;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
INSERT INTO `guli`.`edu_comment` (`id`, `course_id`, `teacher_id`,
`member_id`, `nickname`, `avatar`, `content`, `is_deleted`,
`gmt_create`, `gmt_modified`)
VALUES (i, '1192252213659774977', '1189389726308478977', '1', '小三123',
'ht', '课程很好', 0, '2019-11-13 14:16:08', '2019-11-13 14:16:08');
set i=i+1;
end while;
end;;
delimiter;
经过1分多钟的插入,edu_comment表中的数据已经达到了10w条,再次查看主键索引的高度。
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 02 00 00 00 00 00 00 00 9a |..........|
0000c04a
可以看到主键索引的高度来到了3层,由于服务器硬盘容量较小,插入了1900w条数据。主键索引在数据量达到3w左右会从2层高度上升到3层(辅助索引会在数据量为数万到数十万时上升到3层高度,因为仅含主键值和索引值,没有整行数据)。根据网上资料,数据量在2000w左右时,树的高度会达到4层,数据库性能下降较为明显,2000w分库分表的由来。
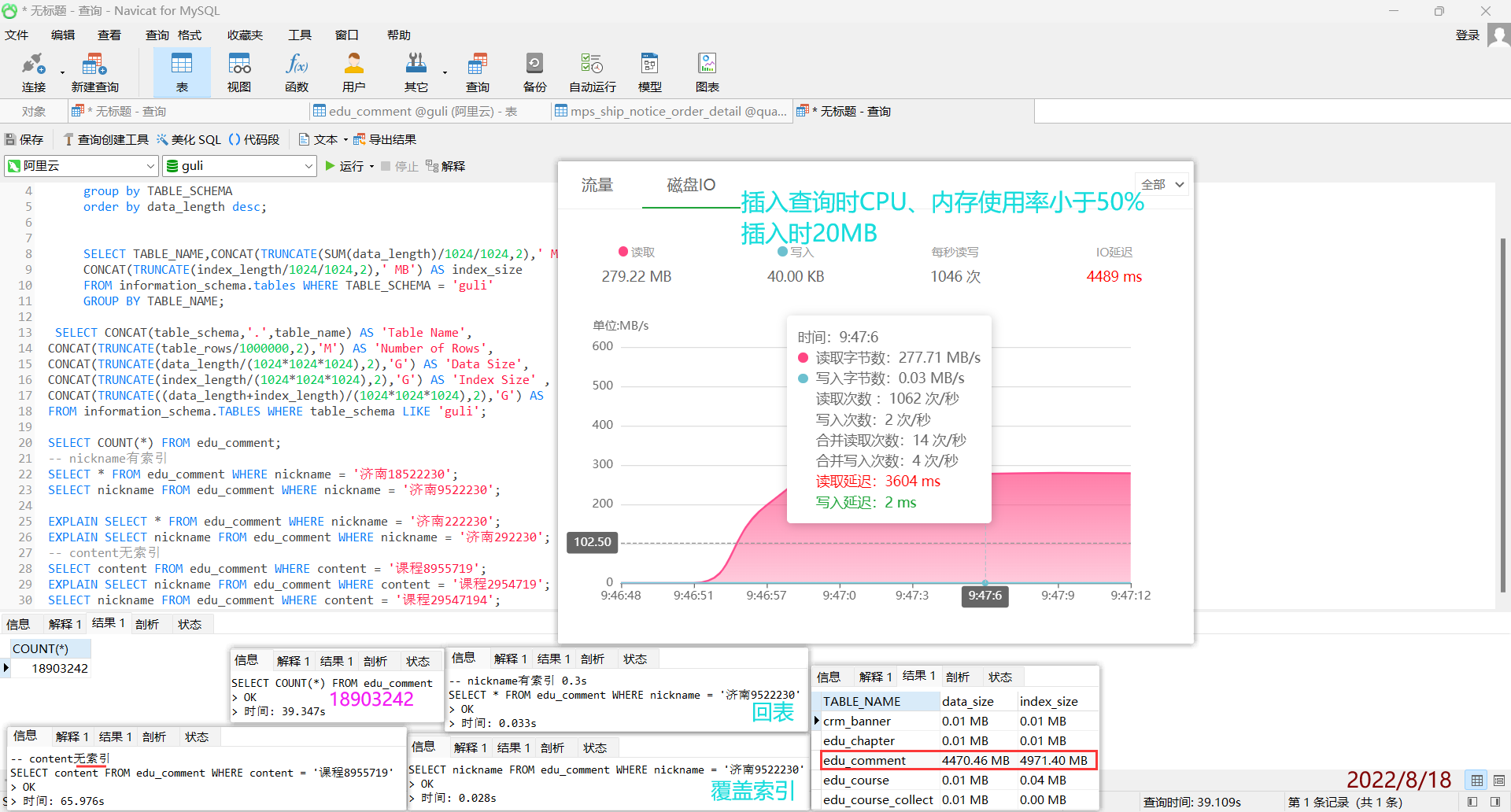
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 03 00 00 00 00 00 00 00 9a |..........|
0000c04a
主键索引高度来到了4层,主键类型为char(19)。
索引高度h也跟索引字段的数据类型有关。如果是int或short,扇区多,索引效率更好,整个索引看起来属于“矮胖”型;而如果是varchar(32)等,那扇区少,整个索引看起来属于“瘦高”型,索引效率自然要低些。所以我们在字段选取类型时,其类型越简单效率越好。
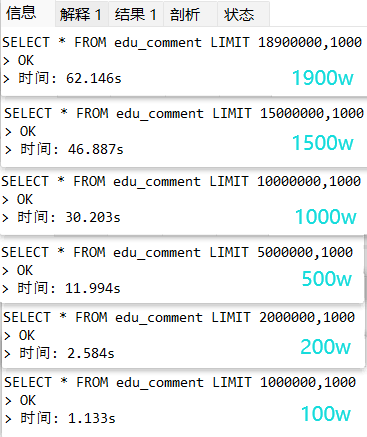
分页查询效率:
参考资料:
[1]MySQL索引的B+树到底有多高?
https://mp.weixin.qq.com/s/VmgpA3fZlv0JxERYB2tt5g
[2]面试官:MYSQL单表数据达2000万性能严重下降,为什么?
https://mp.weixin.qq.com/s/7_Wv3wZX5sOxF17iSM436A
[3]一文搞懂MySQL索引页结构
http://www.cppcns.com/shujuku/mysql/463625.html
[4]再有人问你为什么MySQL用B+树做索引,就把这篇文章发给她
https://mp.weixin.qq.com/s/8nx4yLOg542p_fmqjKDrKw
[5]http://blog.codinglabs.org/articles/theory-of-mysql-index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号