
人工智能
人工智能的英文全称是 (Artificial Intelligence,AI)
是一门以计算机科学为基础,融合了数学、神经学、心理学、控制学等多个科目的交叉学科。
人工智能的目的是让计算机模拟人类的思维,从而解决一些不能用代码描述的问题,比如判断一只动物是不是小狗、通过 CT 照片检测一个人的病情等。由于这个定义只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法和分支
这些问题不能用传统的编程方法解决,因为没有一个确定的公式,或者说没有一个确定的算法。但是我们人类就很容易解决这些问题,因为人类大脑不是根据固定的算法来推导的,而是根据以往的认知或者经验来推理。
人工智能的目的也是如此,不给计算机编写固定的算法,让它自己形成一套模型,然后利用这套模型来帮助人们解决问题。这里的模型,就可以看做计算机的“经验”或者“认知”。由于这个定义只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法和分支
机器学习
机器学习(Machine Learning,ML)
人工智能只是一种美好的愿景,但是具体如何才能实现人工智能呢?答案就是机器学习。
计算机原本只是一张白纸,没有任何“阅历”,我们必须喂给他大量的数据,让它从数据中积累经验,逐渐形成自己的认知。这是一个让计算机不断学习的过程,所以称为机器学习。
机器学习的实现
机器学习的实现可以分成两步:训练和预测,类似于归纳和演绎:
·归纳:从具体案例中抽象一般规律,机器学习中的训练"亦是如此。从一定数量的样本(已知模型输入X和模型输出Y)中,学习输出Y与输入X的关系(可以想象成是某种表达式)。
·演绎:从一般规律推导出具体案例的结果,机器学习中的"预测"亦是如此。基于训练得到的Y与X之间的关系,如出现新的输入X计算出输出Y通常情况下,如果通过模型计算的输出和真实场景的输出一致,则说明模型是有效的。
如何确定模型参数?
假设机器通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数u),并期望用学习到的知识所代表的模型H(u, z),回答不知道答案的考试题(未知样本)。最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。参数w和输入α组成公式的基本结构称为假设。在牛顿第二定律的案例中,基于对数据的观测,我们提出了线性假设,即作用力和加速度是线性关系,用线性方程表示。由此可见,模型假设、评价函数(损失/优化目标)和优化算法是构成模型的三个关键要素。
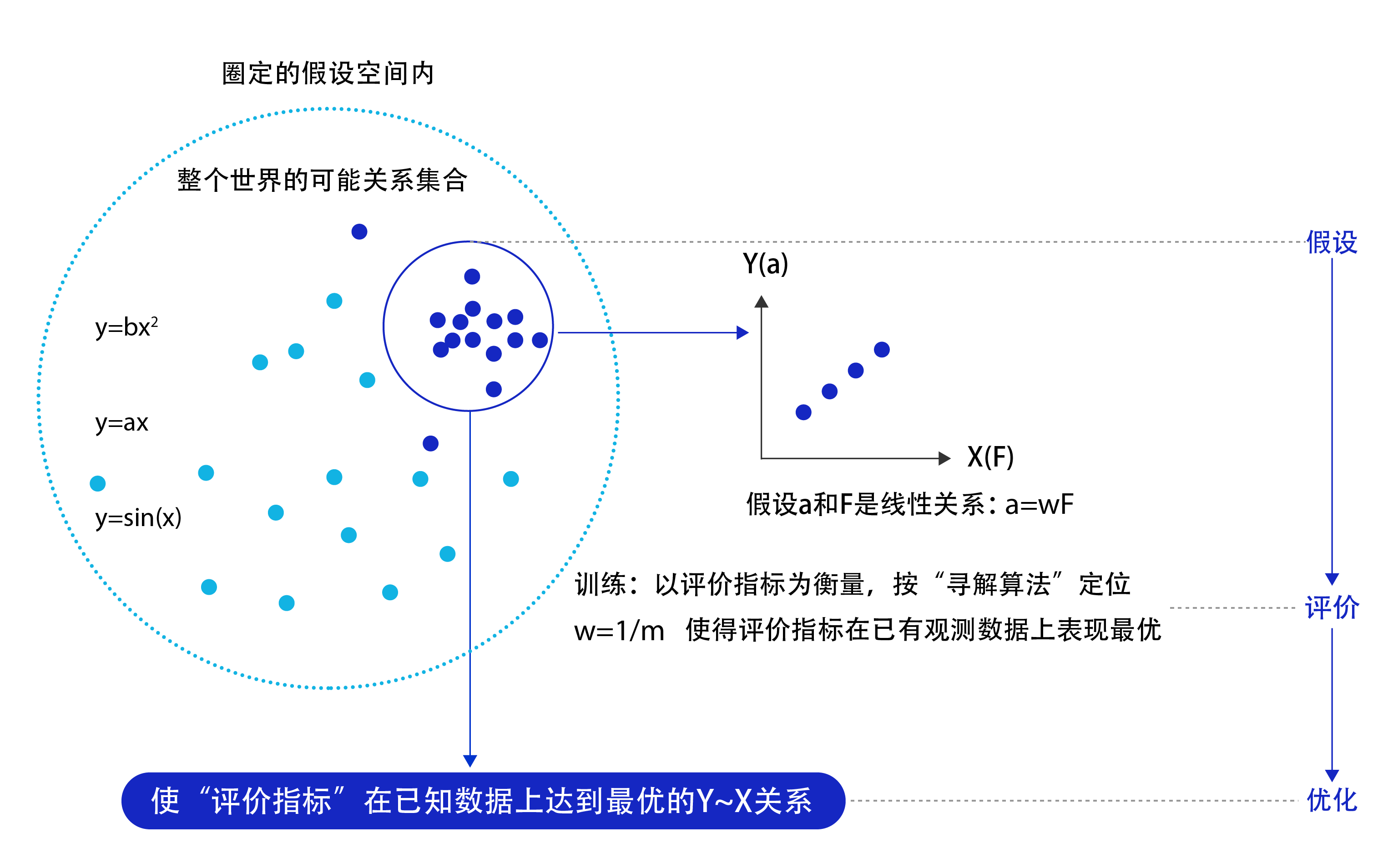
·模型假设:世界上的可能关系千千万,漫无目标的试探Y~X之间的关系显然是十分低效的。因此假设空间先圈定了一个模型能够表达的关系可能,如蓝色圆圈所示。机器还会进一步在假设圈定的圆圈内寻找最优的Y~X关系,即确定参数w。
·评价函数:寻找最优之前,我们需要先定义什么是最优,即评价一个Y~X关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
·优化算法:设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小最拟合已有观测样本)的Y~X关系找出来,这个寻找最优解的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每一个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果。
从上述过程可以得出,机器学习的过程与牛顿第二定律的学习过程基本一致,都分为假设、评价和优化三个阶段:
1.假设:通过观察加速度α和作用力F的观测数据,假设a和F是线性关系,即a = w·F。
⒉评价:对已知观测数据上的拟合效果好,即w·F计算的结果要和观测的a尽量接近。
3.优化:在参数w的所有可能取值中,发现w = 1/m可使得评价最好(最拟合观测样本)。
机器执行学习任务的框架体现了其学习的本质是”参数估计”(Learning is parameter estimation)。

机器学习就是拟合一个“大公式”
机器学习是一件很麻烦的事情,需要先搭建一个模型,这个模型包含了很多参数,然后把准备好的数据(包括正确的结果)输入到模型中,不断调整模型的参数,直到它非常接近或者完全符合正确的结果,这个时候我们就说模型训练好了。
机器学习的模型有很多种,已经有人帮我们开发好了,也就是各种成熟的算法,包括决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、随机森林、支持向量等。
实际开发中,我们根据自己的需求从中选择一个模型即可,这个不用担心。最要命的是数据,机器学习需要大量的数据才能训练好模型。人类看一两张猫的照片就认识猫了,但是机器学习需要看成千上万张照片。
如何收集大量有效的数据,是机器学习的重中之重,所以才有了爬虫,有了数据挖掘,有了数据清洗等分支。
深度学习
深度学习(Deep Learning,DL)
机器学习的模型是一个不断发展的过程,后来人们逐渐研究出了一种更加智能和通用的模型,就是卷积神经网络(CNN)。CNN 模拟人类大脑神经突触之间的连接,通过调整参数来模拟突触连接的强弱,如下图所示。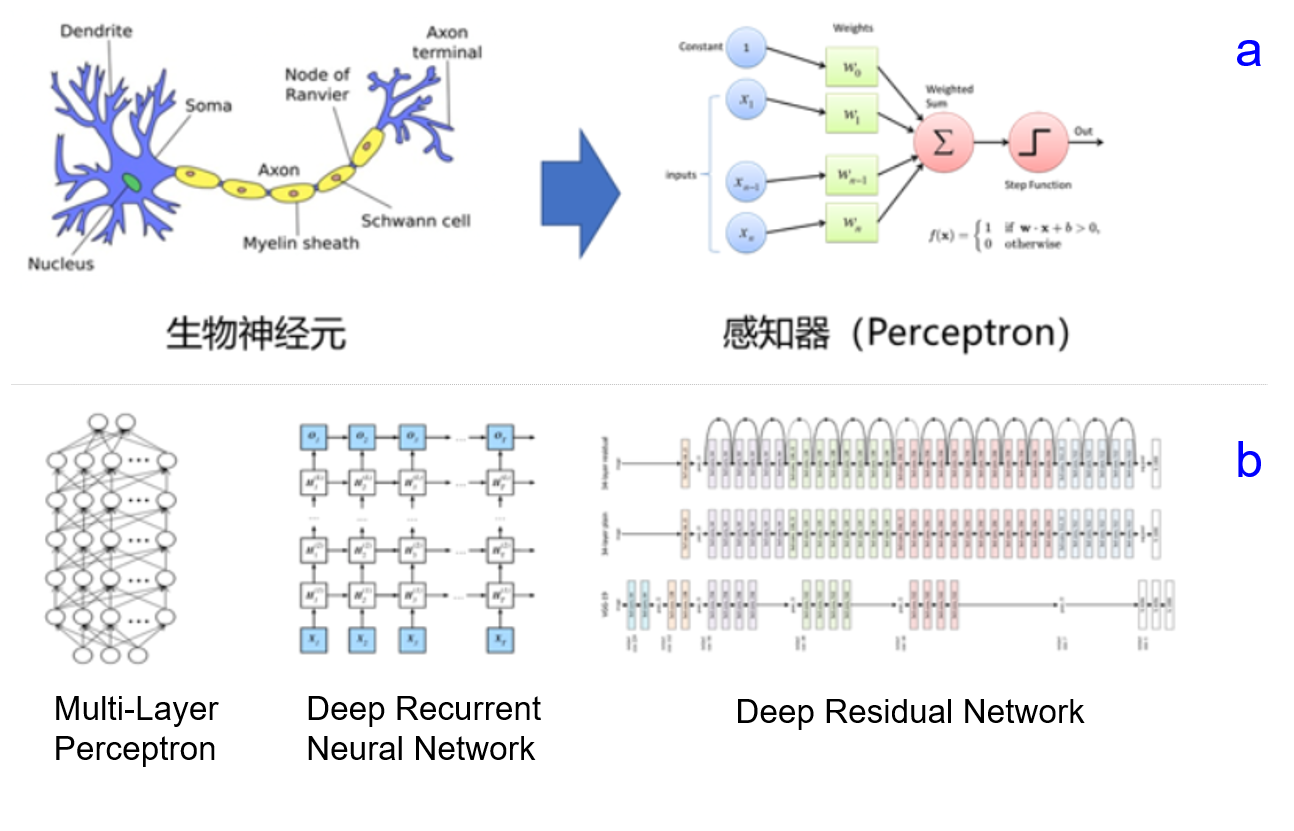
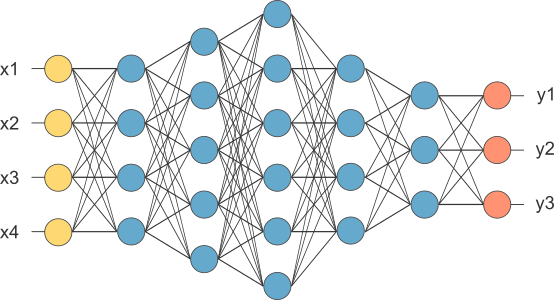
CNN 包含很多层,每一层又包含多个节点。除了第一层和最后一层,中间的那些统称为隐藏层(蓝色部分)。隐藏层可以多达数百层,每一层的输入都是上一层的输出,同时每一层的输出都可以作为下一层的输入,它们交织在一起就形成了一个很深的网络,所以称为“深度学习”。
深度学习是机器学习的一个重要分支,它是机器学习的高级玩法,更加接近真正的人工智能。
目前深度学习已经被应用在人工智能的各个领域,其中最显著的应用是计算机视觉和自然语言处理领域,我们所熟知的语音识别、机器翻译、无人驾驶、人脸识别等等,都是基于对深度学习算法的应用。
除了 CNN,深度学习还有很多其它的衍生模型(算法),比如循环神经网络(RNN)、深度置信网络(DBN)、长短期记忆模型(LSTM)、生成对抗网络(GAN)、受限玻尔兹曼机(RBM)等。
人工智能(ArtificialIntelligence,AI)只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法。机器学习(MachineLearning,ML)是当前比较有效的一种实现人工智能的方式。深度学习(DeepLearning,DL)是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。
https://c.biancheng.net/view/1in7gl.html
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3520300

 浙公网安备 33010602011771号
浙公网安备 33010602011771号