
窝窝第三次博客作业
窝窝第三单元总结
惯例会有剑三沙雕图
这是想要调戏天策的一周
JML理论基础
出现意义
记得在CO课上高老板提到过,我们设计系统必须强调层次。每个单元做好自己的事情,管理这些单元的上一级做好管理的事情,逐层管理,层次清晰,便于梳理。这就要求我们在设计的时候,给各个单元进行明确的分工,即明确它会接收的输入范围,以及输入输出之间的对应关系。在CO的时候我们的设计采用的是引脚、接口定义输入输出,通过自然语言描述输入输出之间的关系,这样显然有失严谨性。JML是一个规范的描述单元模块功能的语言,它没有自然语言的二义性,从而更加准确。
JML语法
本人觉得语法这个东西实在没必要死记硬背,用的时候查手册就好了。点击就送语法手册(嘻~
规格化设计与契约式编程
本单元工作
这一单元中,我们的工作主要是根据给定的JML规格描述,实现相应的接口。我认为,这是属于已经规格设计完成,契约已经订好之后的一个履行契约的过程,而不是契约的制定。(其实前两个单元能做到规格化设计,可以极大程度上避免出BUG)
为什么要契约式编程
这里,不谈那些神必的理论问题,姑且谈谈之前看别人代码的一些感想。
乱是最大的感受,一般情况下代码的混乱程度和BUG数量是正相关的。经常一个类写到一半就忘了自己这个类是要做什么的,和别的类应该怎么交互。
在OOP中,对类的功能设计是基本,如果写着写着就把类的功能给弄混了,整个工程基本上就是一坨混沌。
契约式编程等于说是在想好各个类的功能之后就明确的把这个功能给确定下来,立一个契约。接下来要做的就是按照先前立下的契约将模块各个击破。
当然如果本身的规格设计就有问题,那应该是救不了了。
作业梳理
第一次JML作业
结构图
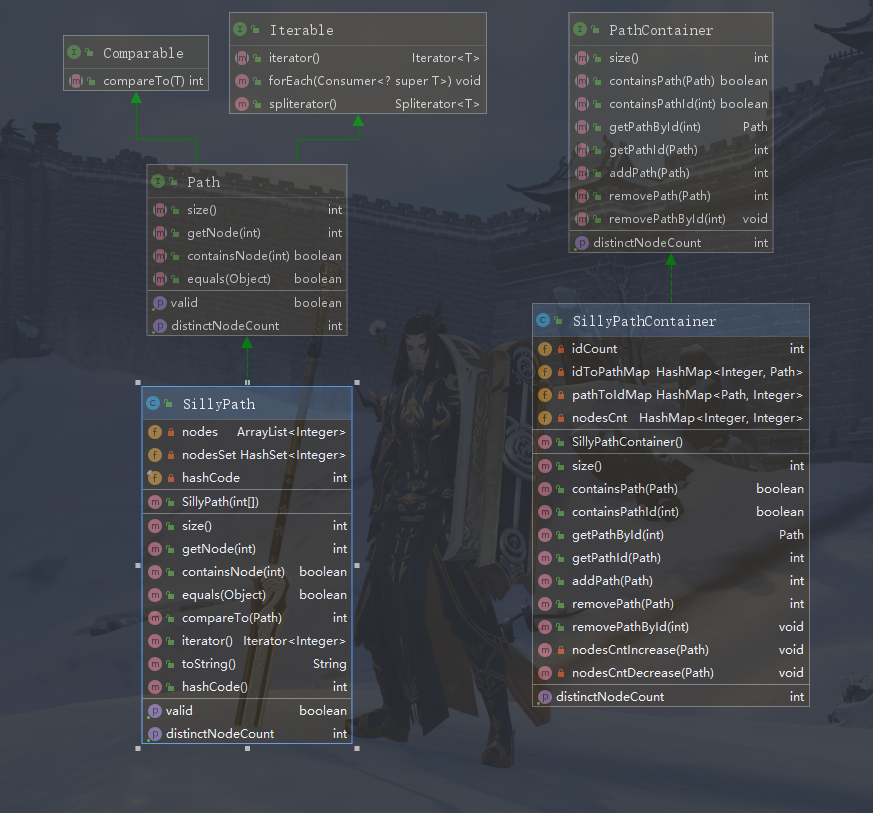
这次作业中,由于结构很简单,所以,我的设计非常的朴素,就实现了官方要求的两个类。通过三hash的方法管理路径和节点。
代码统计分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Main.main(String[]) | 1 | 1 | 1 |
| SillyPath.SillyPath(int[]) | 1 | 2 | 2 |
| SillyPath.compareTo(Path) | 3 | 4 | 4 |
| SillyPath.containsNode(int) | 3 | 2 | 3 |
| SillyPath.equals(Object) | 6 | 2 | 6 |
| SillyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| SillyPath.getNode(int) | 1 | 1 | 1 |
| SillyPath.hashCode() | 1 | 1 | 1 |
| SillyPath.isValid() | 1 | 1 | 1 |
| SillyPath.iterator() | 1 | 1 | 1 |
| SillyPath.size() | 1 | 1 | 1 |
| SillyPath.toString() | 1 | 1 | 1 |
| SillyPathContainer.SillyPathContainer() | 1 | 1 | 1 |
| SillyPathContainer.addPath(Path) | 3 | 2 | 4 |
| SillyPathContainer.containsPath(Path) | 1 | 1 | 1 |
| SillyPathContainer.containsPathId(int) | 1 | 1 | 1 |
| SillyPathContainer.getDistinctNodeCount() | 1 | 1 | 1 |
| SillyPathContainer.getPathById(int) | 2 | 1 | 2 |
| SillyPathContainer.getPathId(Path) | 4 | 1 | 4 |
| SillyPathContainer.nodesCntDecrease(Path) | 1 | 3 | 3 |
| SillyPathContainer.nodesCntIncrease(Path) | 1 | 3 | 3 |
| SillyPathContainer.removePath(Path) | 1 | 1 | 1 |
| SillyPathContainer.removePathById(int) | 2 | 1 | 2 |
| SillyPathContainer.size() | 1 | 1 | 1 |
| Class | OCavg | WMC | |
| Main | 1 | 1 | |
| SillyPath | 1.91 | 21 | |
| SillyPathContainer | 1.92 | 23 | |
| Package | v(G)avg | v(G)tot | |
| 1.96 | 47 | ||
| Module | v(G)avg | v(G)tot | |
| Project9 | 1.96 | 47 | |
| Project | v(G)avg | v(G)tot | |
| project | 1.96 | 47 |
由于这次对功能的需求比较简单,所以没怎么设计架构,但复杂度也很低。
BUG
我方
本次由于功能需求很简单,所以没有测出BUG
互测屋
一个互测屋的代码基本上一样,没有找出BUG

第二次JML作业
结构图
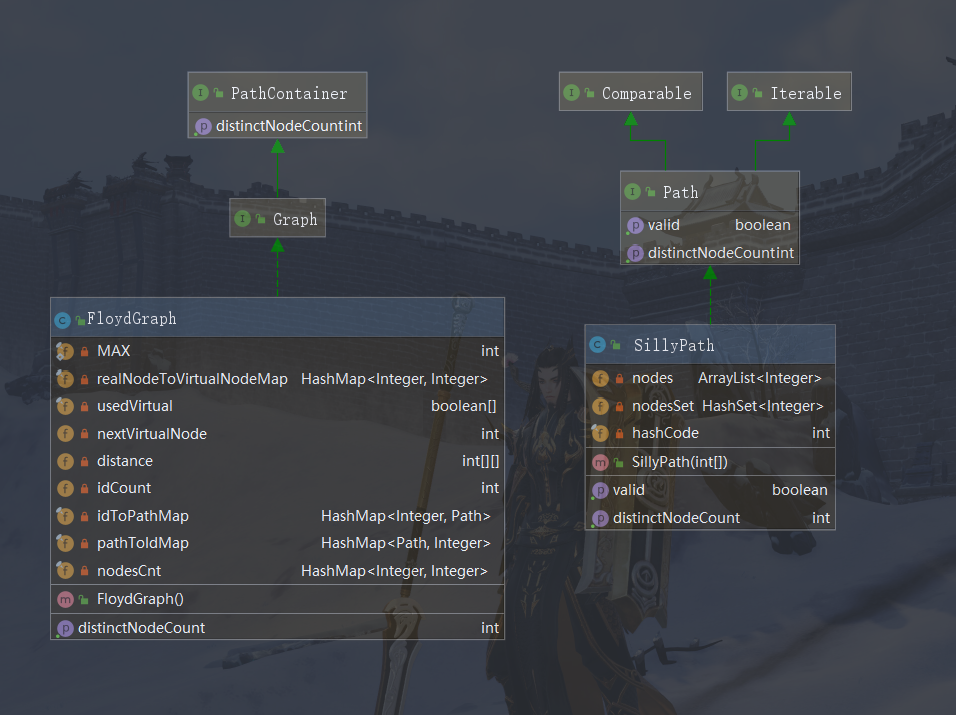
众所周知OO是一门代码重构课程(暴论
本次作业中,为了防止出现TLE的情况,选择了放弃架构的美观,通过面向数据的编程,追求规定数据范围内的更快速度。
架构上,SillyPath类照搬第九次作业。FloydGraph则通过直接在第九次作业的代码的基础上添加新功能代码来实现,所以架构很丑陋。
为了防止自己使用迪杰斯特拉算法实现cache的时候出现错误,本次作业选择用实现起来较为简单的Floyd算法规避算法难度。同时,由于本次作业数据量较小,加上我使用静态数组实现Floyd,所以其复杂度高的缺陷并没有暴露,反而其常数小、实现简单的优势在此次作业中表现出色。
代码统计分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| graph.BfsGraph.BfsGraph() | 1 | 1 | 2 |
| graph.BfsGraph.addPath(Path) | 2 | 3 | 4 |
| graph.BfsGraph.allocVirtualNode() | 1 | 1 | 2 |
| graph.BfsGraph.containsEdge(int,int) | 2 | 2 | 3 |
| graph.BfsGraph.containsNode(int) | 1 | 1 | 1 |
| graph.BfsGraph.containsPath(Path) | 1 | 1 | 1 |
| graph.BfsGraph.containsPathId(int) | 1 | 1 | 1 |
| graph.BfsGraph.getDistinctNodeCount() | 1 | 1 | 1 |
| graph.BfsGraph.getPathById(int) | 2 | 1 | 2 |
| graph.BfsGraph.getPathId(Path) | 4 | 1 | 4 |
| graph.BfsGraph.getShortestPathLength(int,int) | 3 | 1 | 3 |
| graph.BfsGraph.initVisited() | 1 | 1 | 2 |
| graph.BfsGraph.isConnected(int,int) | 3 | 1 | 3 |
| graph.BfsGraph.nodesCntDecrease(Path) | 1 | 3 | 3 |
| graph.BfsGraph.nodesCntIncrease(Path) | 1 | 3 | 3 |
| graph.BfsGraph.nodesMapDecrease(Path) | 1 | 4 | 4 |
| graph.BfsGraph.nodesMapIncrease(Path) | 3 | 2 | 3 |
| graph.BfsGraph.pathDecreaseUpdate(Path) | 1 | 1 | 1 |
| graph.BfsGraph.pathIncreaseUpdate(Path) | 1 | 1 | 1 |
| graph.BfsGraph.removePath(Path) | 1 | 1 | 1 |
| graph.BfsGraph.removePathById(int) | 2 | 1 | 2 |
| graph.BfsGraph.resetMatrix() | 1 | 4 | 9 |
| graph.BfsGraph.size() | 1 | 1 | 1 |
| graph.BfsGraph.updateDistance() | 1 | 2 | 2 |
| graph.BfsGraph.updateOneNodeShortestDistance(int) | 4 | 3 | 4 |
| graph.FloydGraph.FloydGraph() | 1 | 1 | 1 |
| graph.FloydGraph.addPath(Path) | 3 | 2 | 4 |
| graph.FloydGraph.allocVirtualNode() | 1 | 1 | 2 |
| graph.FloydGraph.containsEdge(int,int) | 3 | 2 | 4 |
| graph.FloydGraph.containsNode(int) | 1 | 1 | 1 |
| graph.FloydGraph.containsPath(Path) | 1 | 1 | 1 |
| graph.FloydGraph.containsPathId(int) | 1 | 1 | 1 |
| graph.FloydGraph.getDistinctNodeCount() | 1 | 1 | 1 |
| graph.FloydGraph.getPathById(int) | 2 | 1 | 2 |
| graph.FloydGraph.getPathId(Path) | 4 | 1 | 4 |
| graph.FloydGraph.getShortestPathLength(int,int) | 4 | 1 | 4 |
| graph.FloydGraph.isConnected(int,int) | 4 | 1 | 4 |
| graph.FloydGraph.nodesCntDecrease(Path) | 1 | 3 | 3 |
| graph.FloydGraph.nodesCntIncrease(Path) | 1 | 3 | 3 |
| graph.FloydGraph.nodesMapDecrease(Path) | 1 | 4 | 4 |
| graph.FloydGraph.nodesMapIncrease(Path) | 3 | 2 | 3 |
| graph.FloydGraph.pathDecreaseUpdate(Path) | 1 | 1 | 1 |
| graph.FloydGraph.pathIncreaseUpdate(Path) | 1 | 1 | 1 |
| graph.FloydGraph.removePath(Path) | 1 | 1 | 1 |
| graph.FloydGraph.removePathById(int) | 2 | 1 | 2 |
| graph.FloydGraph.resetMatrix() | 1 | 3 | 6 |
| graph.FloydGraph.size() | 1 | 1 | 1 |
| graph.FloydGraph.updateDistance() | 7 | 6 | 10 |
| graph.Main.main(String[]) | 1 | 1 | 1 |
| graph.SillyPath.SillyPath(int[]) | 1 | 2 | 2 |
| graph.SillyPath.compareTo(Path) | 3 | 4 | 4 |
| graph.SillyPath.containsNode(int) | 3 | 2 | 3 |
| graph.SillyPath.equals(Object) | 6 | 2 | 6 |
| graph.SillyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| graph.SillyPath.getNode(int) | 1 | 1 | 1 |
| graph.SillyPath.hashCode() | 1 | 1 | 1 |
| graph.SillyPath.isValid() | 1 | 1 | 1 |
| graph.SillyPath.iterator() | 1 | 1 | 1 |
| graph.SillyPath.size() | 1 | 1 | 1 |
| graph.SillyPath.toString() | 1 | 1 | 1 |
| Class | OCavg | WMC | |
| graph.BfsGraph | 2.36 | 59 | |
| graph.FloydGraph | 2.65 | 61 | |
| graph.Main | 1 | 1 | |
| graph.SillyPath | 1.91 | 21 | |
| Package | v(G)avg | v(G)tot | |
| graph | 2.5 | 150 | |
| Module | v(G)avg | v(G)tot | |
| Project10 | 2.5 | 150 | |
| Project | v(G)avg | v(G)tot | |
| project | 2.5 | 150 |
其中BfsGraph是我实现的一个测试版本,写的比较丑,故复杂度很高。
由上可见,Floyd在实现复杂度上也是比较低的。即使是我这种两次作业直接写一块的屎架构,仍然能将复杂度控制在可接受的范围内。
BUG
我方
由于Floyd实现非常简单,本次作业成功规避了算法实现上的错误。同时由于面向数据的编程,我的程序运行效率较高,没有出现TLE的情况。
互测屋
本次互测大家水平相近,代码功能要求不复杂,且时间比较宽松,故而大家都和平度过。
第三次JML作业
结构图
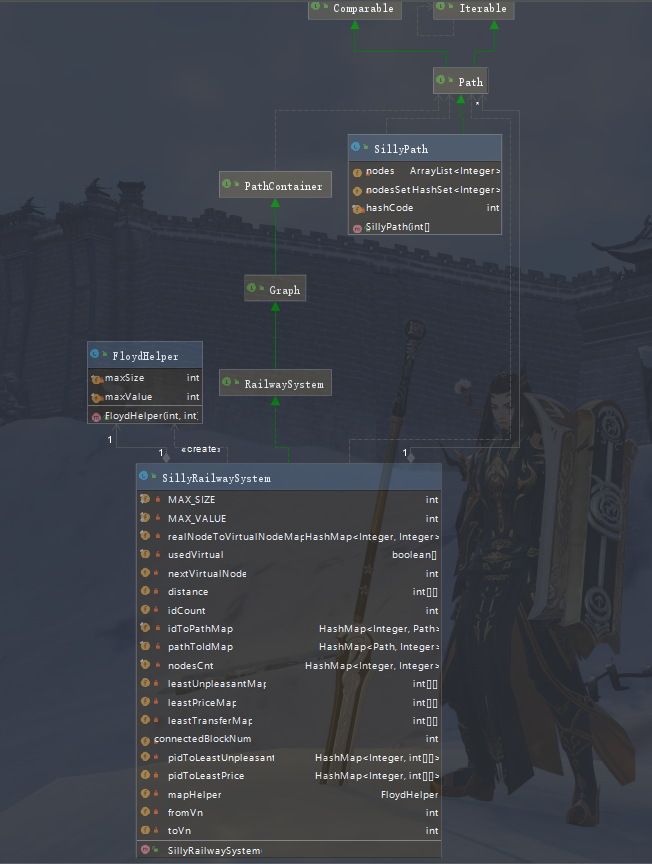
本次作业我采用的是分层Floyd的算法。由于这次需要计算的最短路径种类较多,每个各写一个Floyd过于麻烦,所以我实现了一个计算类FloydHelper用于封装Floyd算法。此次作业由于处于各种ddl的并发期,我没能很好地去设计架构,更多的是直接一股脑地塞进了一个SillyRailwaySystem类中,使得这个类的长度几近500行,这是设计上的失败。
代码统计分析
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| railway.FloydHelper.FloydHelper(int,int) | 1 | 1 | 1 |
| railway.FloydHelper.calculate(int[][]) | 5 | 6 | 8 |
| railway.Main.main(String[]) | 1 | 1 | 1 |
| railway.SillyPath.SillyPath(int[]) | 1 | 2 | 2 |
| railway.SillyPath.compareTo(Path) | 3 | 4 | 4 |
| railway.SillyPath.containsNode(int) | 3 | 2 | 3 |
| railway.SillyPath.equals(Object) | 6 | 2 | 6 |
| railway.SillyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| railway.SillyPath.getNode(int) | 1 | 1 | 1 |
| railway.SillyPath.getUnpleasantValue(int) | 2 | 1 | 2 |
| railway.SillyPath.hashCode() | 1 | 1 | 1 |
| railway.SillyPath.isValid() | 1 | 1 | 1 |
| railway.SillyPath.iterator() | 1 | 1 | 1 |
| railway.SillyPath.size() | 1 | 1 | 1 |
| railway.SillyPath.toString() | 1 | 1 | 1 |
| railway.SillyRailwaySystem.SillyRailwaySystem() | 1 | 2 | 2 |
| railway.SillyRailwaySystem.addPath(Path) | 4 | 2 | 4 |
| railway.SillyRailwaySystem.addPathTwoMapInformation(Path,int) | 1 | 3 | 3 |
| railway.SillyRailwaySystem.allocVirtualNode() | 1 | 1 | 2 |
| railway.SillyRailwaySystem.containsEdge(int,int) | 3 | 2 | 4 |
| railway.SillyRailwaySystem.containsNode(int) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.containsPath(Path) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.containsPathId(int) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.getConnectedBlockCount() | 1 | 1 | 1 |
| railway.SillyRailwaySystem.getDistinctNodeCount() | 1 | 1 | 1 |
| railway.SillyRailwaySystem.getGlabolMap(int[][],HashMap<Integer, int[][]>) | 1 | 6 | 6 |
| railway.SillyRailwaySystem.getLeastTicketPrice(int,int) | 2 | 1 | 2 |
| railway.SillyRailwaySystem.getLeastTransferCount(int,int) | 2 | 1 | 2 |
| railway.SillyRailwaySystem.getLeastUnpleasantValue(int,int) | 2 | 1 | 2 |
| railway.SillyRailwaySystem.getPathById(int) | 2 | 1 | 2 |
| railway.SillyRailwaySystem.getPathId(Path) | 4 | 1 | 4 |
| railway.SillyRailwaySystem.getShortestPathLength(int,int) | 4 | 1 | 4 |
| railway.SillyRailwaySystem.getUnpleasantValue(Path,int,int) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.isConnected(int,int) | 4 | 1 | 4 |
| railway.SillyRailwaySystem.nodesCntDecrease(Path) | 1 | 3 | 3 |
| railway.SillyRailwaySystem.nodesCntIncrease(Path) | 1 | 3 | 3 |
| railway.SillyRailwaySystem.nodesMapDecrease(Path) | 1 | 4 | 4 |
| railway.SillyRailwaySystem.nodesMapIncrease(Path) | 3 | 2 | 3 |
| railway.SillyRailwaySystem.pathDecreaseUpdate(Path) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.pathIncreaseUpdate(Path) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.removePath(Path) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.removePathById(int) | 2 | 1 | 2 |
| railway.SillyRailwaySystem.removePathTwoMapInformationById(int) | 1 | 1 | 1 |
| railway.SillyRailwaySystem.resetMatrix() | 1 | 3 | 6 |
| railway.SillyRailwaySystem.search(int,int) | 2 | 2 | 4 |
| railway.SillyRailwaySystem.size() | 1 | 1 | 1 |
| railway.SillyRailwaySystem.upDateConnectBlock() | 4 | 1 | 6 |
| railway.SillyRailwaySystem.upDatePriceMap() | 1 | 1 | 7 |
| railway.SillyRailwaySystem.upDateUnpleasantMap() | 1 | 1 | 7 |
| railway.SillyRailwaySystem.updateDistance() | 7 | 6 | 10 |
| railway.SillyRailwaySystem.updateTransferMap() | 1 | 5 | 5 |
| Class | OCavg | WMC | |
| railway.FloydHelper | 4.5 | 9 | |
| railway.Main | 1 | 1 | |
| railway.SillyPath | 1.92 | 23 | |
| railway.SillyRailwaySystem | 3.03 | 109 | |
| Package | v(G)avg | v(G)tot | |
| railway | 2.86 | 146 | |
| Module | v(G)avg | v(G)tot | |
| Project11 | 2.86 | 146 | |
| Project | v(G)avg | v(G)tot | |
| project | 2.86 | 146 |
如图可见,本次我的SillyRailwaySystem类由于是直接由上一次的FloydGraph强行塞进新功能得到的,所以复杂度极高,层次极差。
BUG
我方
由于Floyd隐式存在的正确性优势,所以这次我在正确性上面仍然没有出错。同时由于这次的图的节点数比第二次作业还要少,所以Floyd的常数小的优势更加明显,所以这次作业也没有出现TLE的情况。
互测屋
我们组的Lancer在各种对拍中比其他人慢许多,我意识到他的算法可能有问题,但是由于时间原因,这次并没有去构造一个强样例卡他的TLE,但是我们组确实有人做到了,只能说,我技不如人吧。

OpenJML初体验
总体感觉,体验较差,首先,资料太少,官方ReadMe写得比较屎。
其次,各种神秘的版本不兼容问题。
再者,idea上没有相应的、成熟的插件。
并且各种语法要求很神秘,课程组给的JML没办法直接运行上去。
体验
本着体验的态度,我装了个eclipse来运行OpenJML插件。
初始代码如下
public class Mult {
//@ ensures \result == a * b;
public static int mult(int a,int b) {
return a * b;
}
public static void main(String[] args) {
System.out.println(mult(2,7));
}
}
静态检查结果如下

可以看到,我们的代码出问题了。
问题在于 a == 1061067 && b == 1121128的时候出现了算术溢出的情况。
修改规格后,代码如下
public class Mult {
//@ requires ( a < 10 && a > -10 && b < 10 && b > -10 );
//@ ensures \result == a * b;
public static int mult(int a,int b) {
return a * b;
}
public static void main(String[] args) {
System.out.println(mult(2,7));
}
}
静态检查结果
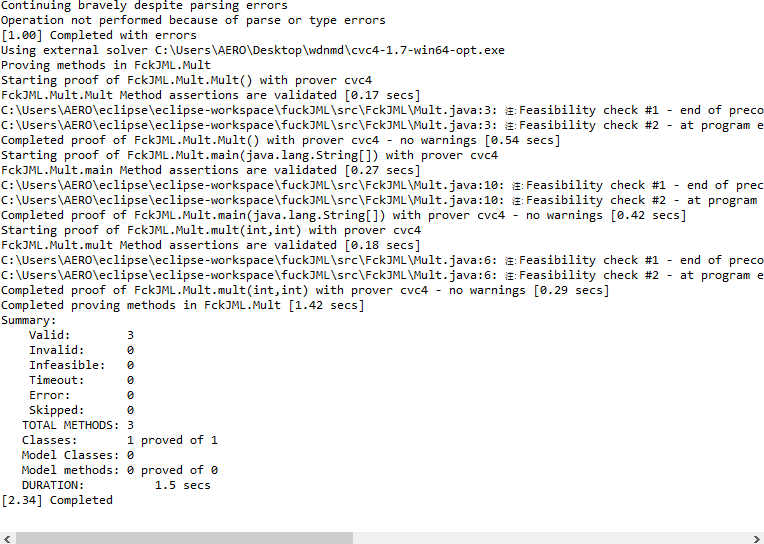
限制了数据范围后,能够通过测试。
小结
OpenJML这个工具本身非常有意义,用逻辑验证来验证正确性,是非常可靠的。
但是,这个工具在推广上尚有不足。使用过于繁琐,兼容性差,文档很迷。
作为一个用户,我是不太倾向于使用这么一个软件的。

JMLUnit初体验
由于课程组给的规格无法直接使用,本着体验工具的态度,我自己写了个非常简单的程序用以体验。
package Miao;
public class Main {
//@ requires true;
//@ ensures \result == a * b;
public static int mult(int a,int b) {
return a * b;
}
public static void main(String[] args) {
mult(2,7);
}
}
生成的样例如下

可以看出,JMLUnit的样例主要针对各种边界条件的检查。实际上,在一般的开发中,边界条件因为其容易出错,会被格外重视,反而不容易出错。
能够意识到的BUG都不会成为BUG,我们的测试更多地应该放在各种分支的遍历上。
评测机一些神必问题
这个单元中我的对拍器出现了神必问题。在往被测程序的进程中写入时会卡死,我认为可能是缓冲区写满的问题,但照理来说,被测程序也一直在读取,不应该出现这个问题。最后我无法解决。
于是我直接改成命令行重定向输入,从文本输入。问题得以解决。

单元感想
正面
- 规格化设计和契约式编程是非常好的一个教学重点。
OO不应该只教怎么设计各个对象的分工,也应该教导根据已有的分工去履行职责,这一点非常重要。 - 利用
JML语言描述功能一定程度上消除了自然语言的二义性。
负面
- 过于
DS。说实在话,这个单元我的重点已经不在规格和架构上了,更多的是在想算法和数据结构的问题,这个单元的DS难度确实有点大到喧宾夺主的地步了。不过这也是一个很矛盾的问题,课程需要一个区分度,如果把区分度加在JML的理解上,就必然要让JML变得复杂,这也就意味着这个类的功能设计的很复杂、很神必,这显然是个"屎"设计。那么区分度就只能在DS上了。 OpenJML这个工具固然是个很强大的工具,但是它的局限性和可用性并没有我们预期的效果。比起用一个很复杂的工具,我相信多数用户还是倾向于自己搭一个简易的对拍器同时自己通过逻辑分析来保证正确性。
遗憾
- 由于近期
ddl高发,没有时间充分地体验Junit的测试,甚是遗憾。
建议
- 希望课程平台增加在官方评测机上运行自己测试样例的功能,这样就解决了环境不一样带来的一些争议。

