根据时间戳,增量同步数据的解决办法
由于markdown的样式太丑了,懒得再调整了,我另外再贴一个github的博客该文的 github链接
前言
最近在工作中遇到一个比较棘手的问题,客户端从服务端同步数据的问题。
背景简介:客户端有N个,客户端上的同步时间,各不相同。同步的时候,是一次获取10条数据,多批次获取。即分页获取。
在代码中存在两种同步的方式:
- 全量同步。同步过程是从服务端拉取全部的数据;依赖具有
唯一约束的ID来实现同步。只适用于数据量小的表,浪费网络流量。 - 增量同步。从服务器拉取
大于客户端最新时间的数据;依赖于时间戳,问题时间戳不唯一存在相同时间点下面多条数据,会出现数据遗漏,也会重复拉取数据,浪费网络流量。
本文的所使用到的解决办法,就是结合了唯一ID和时间戳,两个入参来做增量同步。本文也只做逻辑层面的说明。
模拟场景
表结构:ID 具有唯一约束, Name 姓名, UpdateTime 更新时间;现在问题的关键是ID为3,4,这两条时间点相同的数据。
假如一次只能同步一条数据,如何同步完ID 2后,再同步 ID 3。
| ID | Name | UpdateTime |
|---|---|---|
| 1 | 张三 | 2018-11-10 |
| 2 | 李四 | 2018-12-10 |
| 3 | 王五 | 2018-12-10 |
| 4 | 赵六 | 2018-11-20 |
| 5 | 金七 | 2018-11-30 |
解决思路
生成新的唯一标识
通过 UpdateTime 和 ID 这两种数据,通过某种运算,生成新的数。而这个新的数具备可排序和唯一;同时还要携带有ID和UpdateTime的信息。
简单表述就是,具有一个函数f: f(可排序A,可排序唯一B) = 可排序唯一C 。 C 的唯一解是 A和B。RSA加密算法
我想出了一个方法,也是生活中比较常用的方法:
- 先把 UpdateTime 转变成数字。如: 字符串 2018-12-10 -> 数字 20181210;
- 然后 UpdateTime 乘以权重,这个
权重必须大于ID的可能最大值。如: 20181210 * 100 = 2018121000,Max(ID)<999 - 然后再把第二部的结果,加上唯一键
ID。如: 2018121000 + 3 = 2018121003。
这个时候,2018121003 这个数,既包含了UpdateTime和ID的信息,又具有可排序和唯一性。用它作为增量更新的判断点,是再好不过的了。
但是它具有很大的缺点:数字太大了,时间转化成数字,目前还是用的是天级别,如果换成毫秒级别呢。还有ID可能的最大值也够大了,如果是int64那就更没得搞了。
这个方法理论上可行,实际中不可用基本不可行,除非找到一种非常好的函数f;
PS: 我的直觉告诉我: 极可能存在这种函数,既满足我的需要,又可以克服数字很大这个问题。只是我目前不知道。
数据库表修改(不推荐)
修改数据内容
修改数据内容,使 UpdateTime 数据值唯一。缺点也比较明显:
- 脚本操作数据的情况下,或者直接sql更新。可能会,造成时间不唯一;
- 只是适用在数据量小,系统操作频率小的情况下。因为毫秒级别的时间,在绝大多数软件系统中,可以认为是唯一;
- 尤其是老旧项目,历史遗留数据如何处理。
增加字段
还有一种办法,就是在数据库中,增加一个新的字段,专门用来同步数据的时候使用。
比方说,增加字段 SyncData int 类型。如果 UpdateTime 发生了改变,就把它更新为 SyncData = Max(SyncData) + 1;
也就是说, SyncData 这个字段的最大值一定是最新的数据,SyncData的降序就是 更新时间的降序。SyncData是更新时间顺序的充分不必要条件。
总的来说,这种办法是比较好的,但缺点也比较明显:
- 需要修改表结构,并且额外维护这个字段;
- 新增或者更新的时候,会先锁表,找出这个表的最大值,再更新,资源浪费明显。
- 如果表的数据量比较大,或者更新比较频繁时候。时间消耗较大。
我的解决方法
分页提取数据的可能情况
首先,先来分析一下,一次提取10条数据,提取的数据,存在的可能情况。再次说明前提,先时间倒序,再ID倒序。Order By UpdateTime DESC, ID DESC
可能情况如下图,可以简化为三种:
- 情景1。当前获取的数据中包含了,所有相同时间点的数据;图1,图5
- 情景2。当前获取的数据中包含了,部分相同时间点的数据;图2,图3,图4,图6,图7
- 情景3。当前获取的数据中包含了,没有相同时间点的数据;图···
其中情景1和情景3,可以把查询条件变为:WHERE UpdateTime > sync_time LIMIT 10
但是情景2的情况不能使用大于>这个条件。假如使用了大于>这个条件,情景2就会变成情景1或情景3或图3这种情况。不是包含部分了,需要额外特别处理。
注:图3的结束点 ]不重要,下面情景5有解释。
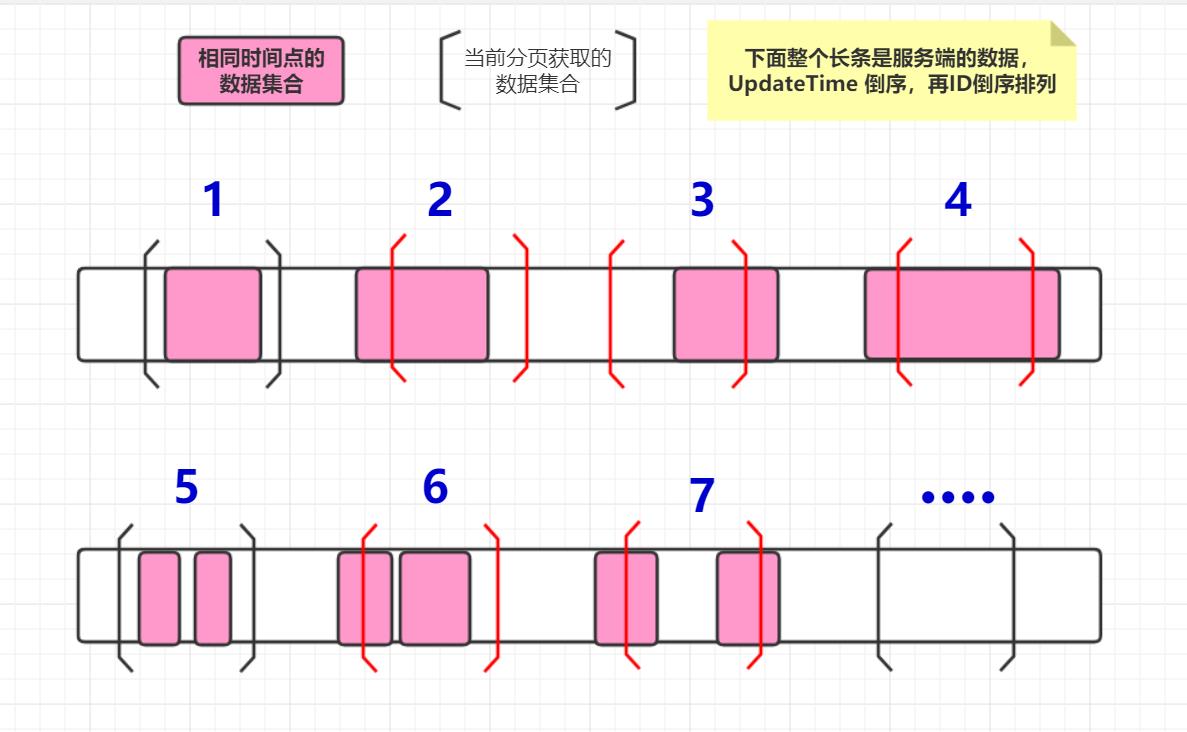
情景2部分情况,提取的起始点
提取的起始点:也就是说图中[左中括号的位置,需要准确定位这个位置。
至于结束点:图中]右中括号的位置是在哪里。这个就不重要了,因为下一次的分页提取的起始点,就是上一次的结束点。只需要关注起始点就足够了。
而根据起始点,又可以把情景2,再做一次简化:
- 情景4。起始点在相同时间点集合内的;图2,图4,图6,图7
- 情景5。起始点不在相同时间点集合内的;图3,
针对情景4。这个时候,时间戳sync_time一个入参就不够了,还额外需要唯一键ID来准确定位。可以把查询写作:WHERE UpdateTime = sync_time AND ID > sync_id LIMIT 10。
如果查询的行数 等于 10,则是图4;小于 10,则是图2,图6,图7的情况。
针对情景5。依旧可以使用:WHERE UpdateTime > sync_time LIMIT 10
完整的分页过程
完整的分页过程的步骤:
一、先用起始点来过滤:WHERE UpdateTime = sync_time AND ID > sync_id LIMIT 10,查询结果行数N。如果 N=10是图4的情况,则结束,并且直接返回结果。如果 0<= N <10 ,则进行第二步,其中N=0是图1,图3,图5,图···的情况;
二、再用时间戳查询:WHERE UpdateTime > sync_time LIMIT 10-N,查询结果行数 M ,0<= M <=10-N;这个阶段,是否同一个时间点都不重要了。只需要按着顺序取已排序的数据就可以了;
三、把一和二的结果集合并,一并返回。
四、重复步骤一二三,直到,分页获取的最后一条数据的ID,是服务端数据库中最新的ID;(防止存在,恰好这十条是所需要获取的最后十条)。
服务端中最新ID获取:Select Id From myTable Order by UpdateTime desc,ID desc Limit 1;
经验总结
寻找关键信息,以及具有指标意义的数据,或者数据的组合。
- 最开始,我只执着于 UpdateTime 这个数据,甚至提出去数据库中,修改历史数据,再把 UpdateTime 加上唯一约束(以前也没有听说过在 UpdateTime 这个字段上面加唯一约束)。并且这种办法,局限性有很强,不可以通用。
- 主键ID唯一,但是它不具有时间属性。只适用于全部更新。
- 把他们两个结合起来,才算是打开了新的思路。
拆分问题,简化问题
- 把 UpdateTime 和 ID 组合使用时。妄图在一个sql里面来实现。发现无论怎么改,都会存在逻辑上面的问题;
- 没有拆分化简的时候,如果用存储过程来写的话,会非常非常复杂;
- 直到,我在脑袋里面,模拟出来可能的情况后。也就是上面的图片
同步数据的可能性,慢慢归类,简化后;才发现。问题没有那么难,仅仅是起始点这一个小小的问题。
使用逻辑分析和哲学归纳
- 在分析数据的意义和性质的时候,偶然间使用到了归纳的方法;也就是
唯一和可排序;跳出了具体字段,使用场景的框架束缚,而去考虑这两种性质怎么结合的问题; - 在逻辑分析的时候,先用排列组合,算出多少种可能性;在脑中勾画出图形,把性质相同的可能性合并化简;
- 在化简的过程中,不要仅仅着眼于查询的对象,也要去化简
查询的方法;有点绕,打个比方,既要优化最终产品,也要去优化制作工艺;
最后,我认为我最近的逻辑分析能力,好像有比较大的提升。
- 直接得益于,常见的24种逻辑谬误的了解,【转】逻辑谬误列表(序言),在平常的生活中,说话做事,也就有了逻辑方面的意识;
- 间接可能得益于台大哲学系苑举正,苑老师讲话的视频。其实我很早以前,高中时候就喜欢哲学,《哲学的基本原理》这么枯燥的书,我居然认认真真仔仔细细的边读边想的看了三四遍。只是那时好多完全不懂,好多似懂非懂。十多年后虽然什么都不记得了,但是好像又懂了。。。感觉太玄了。。。
我们生而自由
却被后台种种
无形枷锁束缚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号