【bioinfo】生物信息学——代码遇见生物学的地方
注:从进入生信领域到现在,已经过去快8年了。生物信息学包含了我最喜欢的三门学科:生物学、计算机科学和数学。但是如果突然问起,什么是生物信息学,我还是无法给出一个让自己满意的答案。于是便有了这篇博客。
起源
据说在1970年,荷兰科学家Paulien Hogeweg和Ben Hesper最早在荷兰语中创造了"bioinformatica"一词,英语中的"bioinformatics" 在1978年首次被使用。这两位科学家当时使用该词来表示:
The study of information processes in biotic systems.
该定义中有两个关键词:生物系统(biotic systems)和信息过程(information processes)。但是这里的"信息过程"不太好理解。
此外,从该领域的著名期刊——"bioinformatics"期刊名称的变化也可以从另一个角度来考证"生物信息学"这个词的接受程度。"bioinformatics"创立于1985年,改名前的期刊名为:Computer Applications in the Biosciences (CABIOS)同时也是国际计算生物学会(the International Society for Computational Biology, ISCB)的会刊,在1998年改为现在的名字。
各个不同时期的定义
wiki
【定义1】首先看一下维基百科对生物信息学的解释:
Bioinformatics /ˌbaɪ.oʊˌɪnfərˈmætɪks/ (About this soundlisten) is an interdisciplinary field that develops methods and software tools for understanding biological data. As an interdisciplinary field of science, bioinformatics combines biology, computer science, information engineering, mathematics and statistics to analyze and interpret biological data. Bioinformatics has been used for in silico analyses of biological queries using mathematical and statistical techniques.
Bioinformatics and computational biology involve the analysis of biological data, particularly DNA, RNA, and protein sequences. The field of bioinformatics experienced explosive growth starting in the mid-1990s, driven largely by the Human Genome Project and by rapid advances in DNA sequencing technology.
The primary goal of bioinformatics is to increase the understanding of biological processes.
这里的定义强调交叉学科以及对生物学数据的理解,认为最主要的生物学数据是DNA、RNA和蛋白质的序列数据。并指出生物信息学最重要的目标是增加对生物过程的理解。
2000年
【定义2】下面是NIH Biomedical Information Science and Technology Initiative在2000年给出的定义:
Research, development, or application of computational tools and approaches for expanding the use of biological, medical, behavioral or health data, including those to acquire, store, organize, archive, analyze, or visualize such data.
该定义强调计算工具和方法(相当于软件和算法),以及数据的采集、存储、组织、存档、分析和可视化。该定义在2012年还被冷泉港实验室的一个下属机构在一篇介绍生物信息学的博客中引用过。
2001年
【定义3】2001年,人类基因组计划还没有完成。下面是2001年发表的一篇标题为"What is bioinformatics? A proposed definition and overview of the field"的论文中的解释:
Bioinformatics is conceptualizing biology in terms of macromolecules (in the sense of physical-chemistry) and then applying “informatics” techniques (derived from disciplines such as applied maths, computer science, and statistics) to understand and organize the information associated with these molecules, on a large-scale.
Analyses in bioinformatics predominantly focus on three types of large datasets available in molecular biology: macromolecular structures, genome sequences, and the results of functional genomics experiments (eg expression data). Additional information includes the text of scientific papers and “relationship data” from metabolic pathways, taxonomy trees, and protein-protein interaction networks.
这里的定义强调生物大分子和数据的规模。认为生物学数据主要包括大分子的结构数据、基因组序列和功能基因组学实验数据(如表达数据等),此外还包括科学论文数据(可以进行文本挖掘)以及来自pathway等地方的关系数据(相互作用)。
该文章的作者从宽度(数据量的变化)和深度(不同生物学过程中的不同大分子)两个维度对生物信息学中包含的主要问题进行了分类:
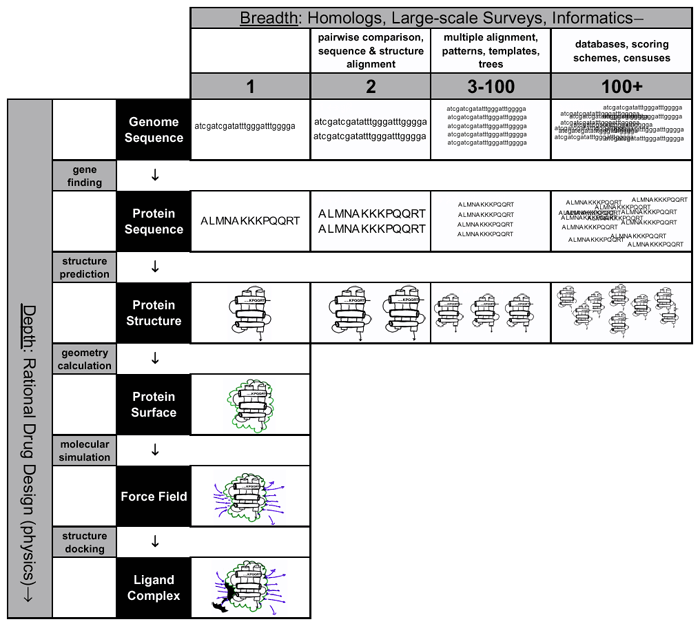
图1:The Bioinformatics Spectrum, from http://bioinfo.mbb.yale.edu/what-is-it/
从宽度(信息学的角度)上来说,随着数据量的增加(从一条序列到多条序列),提出的问题也不一样,需要用到的算法和工具也不一样;从深度(物理学的角度)上来说,不同的生物学对象(DNA、蛋白质序列)在各个生物过程(蛋白质的折叠,发生于蛋白质表面的相互作用等)中执行着不同的功能。
该文章的作者还定义了"组学"的概念:
A key approach in genomic research is to divide the cellular contents into distinct sub-population, each given an -omic term. Broadly, these 'omes can be divided into those that represent a population of molecules, and those that define their actions. For example, the proteome is the full complement of proteins encoded by the genome, and the secretome is the part of it secreted from the cell.
各种不同的组学列表(OMES TABLE):http://bioinfo.mbb.yale.edu/what-is-it/omes/
【定义4】下面是网站bioplanet在2001年给出的定义:
Bioinformatics is the application of computer technology to the management of biological information. Computers are used to gather, store, analyze and integrate biological and genetic information which can then be applied to gene-based drug discovery and development.
该定义中的生物信息(biological information)可以理解为生物数据,强调数据的采集、存储、分析和整合。最后还给出了生物信息学的应用:基于基因的药物开发。该定义直到2017年,还有其他网站引用。
2005年
【定义5】以下是网站TechTarget给出的定义:
Bioinformatics is the science of developing computer databases and algorithms for the purpose of speeding up and enhancing biological research.
New academic programs are training students in bioinformatics by providing them with backgrounds in molecular biology, engineering, ethics and computer science, including database design and analytical approaches to data mining.
该定义强调数据库和算法,且提到了伦理学。
【定义6】下面是英属哥伦比亚大学THE SCIENCE CREATIVE QUARTERLY上面的一篇文章给出的定义:
Bioinformatics involves the integration of computers, software tools, and databases in an effort to address biological questions.
Many scientists today refer to the next wave in bioinformatics as systems biology, an approach to tackle new and complex biological questions. Systems biology involves the integration of genomics, proteomics, and bioinformatics information to create a whole system view of a biological entity.
The genes involved in the pathway, how they interact, and how modifications change the outcomes downstream, can all be modeled using systems biology. Any system where the information can be represented digitally offers a potential application for bioinformatics. Thus bioinformatics can be applied from single cells to whole ecosystems.
Genome sequence by itself has limited information. To interpret genomic information(基因组信息的解释), comparative analysis of sequences needs to be done and an important reagent for these analyses are the publicly accessible sequence databases. Without the databases of sequences (such as GenBank), in which biologists have captured information about their sequence of interest, much of the rich information obtained from genome sequencing projects would not be available(公共数据库的重要性).
The same way developments in microscopy foreshadowed discoveries in cell biology, new discoveries in information technology and molecular biology are foreshadowing discoveries in bioinformatics.
In many ways, bioinformatics provides the tools for applying scientific method to large-scale data and should be seen as a scientific approach for asking many new and different types of biological questions.
Although technology enables bioinformatics, bioinformatics is still very much about biology. Biological questions drive all bioinformatics experiments. Important biological questions can be addressed by bioinformatics and include understanding the genotype-phenotype connection for human disease, understanding structure to function relationships for proteins, and understanding biological networks.
这篇文章的定义也强调了数据库的重要性并给出了原因:一段基因组序列本身的信息是有限的,需要与其他已注释序列进行比较来研究其功能(例如利用Blast软件在公共数据库GenBank中注释一段新的DNA序列)。在当时(05年)已经有许多科学家提出"系统生物学"是下一个阶段的生物信息学。此外,文中提到:"对于任何系统(从单个细胞到整个生态系统),只要其信息可以数字化,生物信息学在该系统就可能有用武之地"。生物信息学之于分子生物学,就像显微镜之于细胞生物学。
这篇文章还给出了很多有价值的观点:
- 生物信息学不仅仅可以作为工具来解决问题,也应该被当成一种科学方法来提出新的和不同类型的生物学问题;
- 尽管生物信息学依赖于技术,但是所有的生物信息学实验还是被生物学问题所驱动;
- 一些可以用生物信息学来处理的重要生物学问题:理解基因型-表型在人类疾病中的关联,理解蛋白质结构与功能之间的关系,理解生物网络;
- 生物信息学的进步也依赖于生产数据的工具和技术(例如新的更便宜的测序技术,高通量生物芯片技术,更精确的质谱技术等)的进步。
2010年
【定义7】下面两个定义收录于圣地亚哥州立大学(San Diego State University)计算机科学与生物学教授Dr. Robert Edwards的一篇博客中:
“Bioinformatics is the application of statistics and computer science to the field of molecular biology. It includes computational biology, algorithm development, statistics techniques, data modeling and visualization.” – Owen White (2010)
“Bioinformatics is a science where we integrate computer science, genetics and genomics.” – Atul Butte (2010)
上面的定义中提到了统计学和计算机科学在分子生物学领域的应用,以及数据模型和可视化。生物信息学领域早期的前辈们有很多都是从遗传学转过来的。
2011年
【定义8】据说是生物信息学领域最大的专业网站Bioinformatics.org,按照生物信息学发展的不同阶段,对生物信息学的研究内容作了介绍:
生物信息学最宽泛的定义会包含DNA序列或乳房X光片等数据,因此也可以包含医学图像处理的内容。但是平时用到的生物信息学指定的范围要窄的多:主要是指计算分子生物学。
It is debatable whether bioinformatics and the discipline computational biology, literally "biology that involves computation," are the same or distinct. To some, both bioinformatics and computational biology are defined as any use of computers for processing any biologically-derived information, whether DNA sequences or breast X-rays. Therefore, there are other fields, e.g. medical imaging / image analysis, that might be considered part of bioinformatics. This would be the broadest definition of the term. But, in practice, the definition used by most people is even narrower; bioinformatics to them is a synonym for computational molecular biology: any use of computers to characterize the molecular components of living things.
从信息学的角度来看,会强调包含在生物数据中的信息(数据 - 信息 - 知识):
To others, bioinformatics is a grammatical contraction of "biological informatics" and is therefore related to the computer science disciplines of information science and/or information technology. This definition would thus emphasize the information contained within the biological data, also implying that large amounts of data would be managed and/or analyzed.
前基因组时代的生物信息学基本上就是指序列分析:
Most biologists talk about "doing bioinformatics" when they use computers to store, retrieve, analyze or predict the composition or the structure of biomolecules. As computers become more powerful you could probably add simulate to this list of bioinformatics verbs. "Biomolecules" include your genetic material---nucleic acids---and the products of your genes: proteins. These are the concerns of pre-genomic or "classical" bioinformatics, which deal primarily with sequence analysis.
Fredj Tekaia at the Institut Pasteur offers this definition of bioinformatics:
"The mathematical, statistical and computing methods that aim to solve biological problems using DNA and amino acid sequences and related information."
后基因组时代的生物信息学发生了很大的变化:研究重点从基因本身到基因产物的转移,以及对生物医学实验数据的分析。
The greatest achievement of bioinformatics methods, the Human Genome Project, is practically complete. Because of this the nature and priorities of bioinformatics research and applications have changed. People often talk portentously of our living in the "post-genomic" era. This affects bioinformatics in several ways:
Now that we possess multiple whole genomes, we can look for differences and similarities between all the genes of multiple species. From such studies we can draw particular conclusions about species and general ones about evolution. This kind of science is often referred to as comparative genomics.
There are now technologies designed to measure the relative number of copies of a genetic message (levels of gene expression) at different stages in development or disease or in different tissues. Such technologies, such as DNA microarrays will grow in importance(新的检测技术).
Other, more direct, large-scale ways of identifying gene functions and associations (for example yeast two-hybrid methods) will grow in significance and with them the accompanying bioinformatics of functional genomics.
There will be a general shift in emphasis (of sequence analysis especially) from genes themselves to gene products.
This will lead to:
- attempts to catalog the activities and characterize interactions between all gene products (in humans): proteomics );
- attempts to crystallography and or predict the structures of all proteins (in humans): structural genomics.
What some people refer to as research or medical informatics, the management of all biomedical experimental data associated with particular molecules or patients---from mass spectroscopy, to in vitro assays to clinical side-effects---will move from the concern of those working in drug company and hospital I.T. (information technology) into the mainstream of cell and molecular biology and migrate from the commercial and clinical to academic sectors.
It is worth noting that all of the above post-genomic areas of research depend upon established, pre-genomic sequence analysis techniques.
此外该网站还特别提到了生物学与计算机科学之间奇妙的关系:生物大分子通常由结构简单的单体聚合而成(这点与计算机中用一些简单的语法编写一个具有独立功能的软件非常相似);以及生物学对计算机科学的启发,例如遗传算法、(人工)神经网络的结构等。
It is a mathematically interesting property of most large biological molecules that they are polymers; ordered chains of simpler molecular modules called monomers. Think of the monomers as beads or building blocks which, despite having different colors and shapes, all have the same thickness and the same way of connecting to one another. Monomers that can combine in a chain are of the same general class, but each kind of monomer in that class has its own well-defined set of characteristics. And many monomer molecules can be joined together to form a single, far larger, macromolecule. Macromolecules can have exquisitely specific informational content and/or chemical properties. According to this scheme, the monomers in a given macromolecule of DNA or protein can be treated computationally as letters of an alphabet, put together in pre-programmed arrangements to carry messages or do work in a cell.
There are also whole other disciplines of biologically-inspired computation, e.g. genetic algorithms, AI, and neural networks. Often these areas interact in strange ways. Neural networks, inspired by crude models of the functioning of nerve cells in the brain, are used in a program called PHD to predict, surprisingly accurately, the secondary structures of proteins from their primary sequences.
2013年
【定义9】阿肯色大学小石城分校(University of Arkansas at Little Rock, UALR)在BIOINFORMATICS PROGRAM中对生物信息的解释:
- As a discipline that builds upon the fields of computer and information science, bioinformatics relies heavily upon strategies to acquire, store, organize, archive, analyze, and visualize data.
- As a discipline that builds upon computational biology, bioinformatics encompasses the development and application of data-analytical and theoretical methods, mathematical modeling and computational simulation techniques to the study of biological, behavioral, and social systems.
- As a discipline that builds upon the life, health, and medical sciences, bioinformatics supports medical informatics; gene mapping in pedigrees and population studies; functional-, structural-, and pharmaco-genomics; proteomics, and dozens of other evolving “-omics.”
- As a discipline that builds upon the basic sciences, bioinformatics depends on a strong foundation of chemistry, biochemistry, biophysics, biology, genetics, and molecular biology which allows interpretation of biological data in a meaningful context.
- As a discipline whose core is mathematics and statistics, bioinformatics applies these fields in ways that provide insight to make the vast, diverse, and complex life sciences data more understandable and useful, to uncover new biological insights, and to provide new perspectives to discern unifying principles.
In short, bioinformaticians (or bioinformaticists) bring a multidisciplinary perspective to many of the critical problems facing the health-science profession today.
该定义从5个不同的方面,对生物信息学进行了解释:
- 建立在计算机和信息学科之上的生物信息学,侧重于数据的采集、存取、分析及可视化;
- 建立在计算生物学之上的生物信息学,侧重于数据分析和理论方法的开发,以及数学模型和计算机模拟技术在生物学研究中的应用;
- 建立在生命科学和医学之上的生物信息学,侧重于医学信息数据和各种不同的组学数据的分析;
- 建立在基础科学之上的生物信息学,侧重于在更基础的层面(化学结构、生化过程等)对生物学数据进行解释;
- 建立在数学和统计学之上的生物信息学,侧重于对大量、不同类型的复杂数据(例如高维数据或高度异质性的数据)进行分析;
从上面的定义来看,更加凸显了生物信息学的交叉学科属性。
2017年
【定义10】生物信息学家Dr. Maria Nattestad用下面的话向非科学家介绍自己的工作:
I use computers to analyze biological data.
在一篇博客中,她将生物信息学与数据科学进行了比较,发现它们非常相似:

图2:生物信息学 vs 数据科学
按照上图的理解,生物信息学就是一种特别的数据科学。Dr. Maria Nattestad认为生物信息学非常有趣的原因之一是:该学科聚集了不同领域的人,这些人带着不同的背景和倾向,使用不同的方式来思考生物学问题。她将生物信息学分成了以下三个部分:
- Data analysis is the most natural starting point for biologists and involves the most domain expertise because it specifically involves interpreting the data. The ability to detect oddities or interesting patterns in the data can heavily depend on your knowledge of the biological system the data comes from.
- Bioinformatics software development is an approach to bioinformatics that I see computer scientists naturally take on. They may also do data analysis, but will have a hard time resisting building real software products. The software they develop can take many forms, from command-line tools to web applications.
- Modeling is very fashionable with physicists and mathematicians. You can tell their work apart by the fact that it’s full of equations and written in LateX.
2018年
【定义11】2018年是瑞士生物信息学研究所(Swiss Institute of Bioinformatics, SIB)建立20周年。在其官网上对生物信息学的定义如下:
The application of computer technology to the understanding and effective use of biological and clinical data. It is the discipline that stores, analyses and interprets the ‘big data’ generated by life science experiments, or clinical data, using computer science.
相对于其他定义,这里强调对数据的高效利用,以及对生命科学大数据的处理。
下面是SIB定义的生物信息学的研究内容:
Databases and knowledgebases for storing, retrieving and organizing biological information to maximize the value of biological data;
Software tools for modelling, visualizing, analysing, interpreting and comparing biological data;
Computing and storage infrastructure to process large amounts of data;
Analysis of complex biological datasets or systems in the context of particular research projects;
Research in a wide variety of biological fields using computer- and data science and leading to applications in diverse areas, from agriculture to precision medicine.
Bioinformatics is thus a multidisciplinary field bringing together biologists, computer scientists and mathematicians, as well as statisticians and physicists.
【定义12】下面是宾夕法尼亚州立大学的生物信息学教授István Albert,在他的书《The Biostar Handbook: A Beginner's Guide to Bioinformatics》中对生物信息学的定义:
Bioinformatics is a data science that investigates how information is stored within and processed by living organisms.
上面的定义非常简洁,将生物信息学看做是数据科学,研究生物体中的信息如何保存和处理。
该书的介绍部分,讲了生物信息学的变化过程:
In its early days––perhaps until the beginning of the 2000s––bioinformatics was synonymous with sequence analysis. Scientists typically obtained just a few DNA sequences, then analyzed them for various properties. Today, sequence analysis is still central to the work of bioinformaticians, but it has also grown well beyond it.
In the mid-2000s, the so-called next-generation, high-throughput sequencing instruments (such as the Illumina HiSeq) made it possible to measure the full genomic content of a cell in a single experimental run. With that, the quantity of data shot up immensely as scientists were able to capture a snapshot of everything that is DNA-related.
These new technologies have transformed bioinformatics into an entirely new field of data science that builds on the "classical bioinformatics" to process, investigate, and summarize massive data sets of extraordinary complexity.
2005年左右,二代测序仪的出现,让生物信息学进入了大数据时代。
下面是作者的进一步追问:到底什么是生物信息学?
But what is bioinformatics, really?
So now that you know what bioinformatics is all about, you're probably wondering what it's like to practice it day-in-day-out as a bioinformatician. The truth is, it's not easy. Just take a look at this "Biostar Quote of the Day" from Brent Pedersen in Very Bad Things:
I've been doing bioinformatics for about 10 years now. I used to joke with a friend of mine that most of our work was converting between file formats. We don't joke about that anymore.Jokes aside, modern bioinformatics relies heavily on file and data processing. The data sets are large and contain complex interconnected information. A bioinformatician's job is to simplify massive datasets and search them for the information that is relevant for the given study. Essentially, bioinformatics is the art of finding the needle in the haystack.
看到同样有人在该领域工作快10年,但还是搞不清楚什么是生物信息学,我就放心了。这里特别强调了数据量,并且最后说生物信息学就是在大海捞针的艺术。
这里推荐一下给作者的这本书,可以作为生物信息学的入门书来看,而且不止我一个人推荐该书,微信公众号"生信媛"的创建人得到授权后翻译了本书,在下面的文章中可以找到所有内容的链接:
英文版:https://www.biostarhandbook.com/
中文版目录:http://blog.sciencenet.cn/blog-3334560-1078097.html
我的定义
上面介绍了自生物信息学这个词诞生后,从2000年到2018年之间的12个不同的定义。从总体上来看,最开始的定义更强调数据的采集、存储和获取等过程,更偏向于计算机科学;随着相关检测技术和生物数据分析基础平台的发展和完善,现在的定义更多的强调从整体上对数据进行整合分析以及高通量实验带来的大数据的挑战,更偏向于系统生物学。
下面是我基于自己的理解,给生物信息学下的定义:
生物信息学是围绕生物数据展开的,因此与数据科学有着天然的紧密联系。生物数据是各种检测仪器(测序仪、质谱和电镜等)对不同的生物过程进行量化时产生的。生物过程以各类生物大分子(DNA、RNA、蛋白质、多糖等)或小分子代谢物以及肠道菌群等与人体共生的微生物为基本的结构和功能单位,主要包括这些基本单位的新陈代谢(合成与分解,物质与能量的相互转化)和相互作用(信息的交流,即调控)。生物信息学就是利用统计或机器学习等数据科学领域的方法对生物数据进行分析和解释,从静态(结构和功能,细胞内的定位等)和动态(调控,转运等)两个方面来研究生物过程的科学。
为了完成上述任务,大致可以分为三个步骤:数据的管理(已有数据的注释、存储、检索和数据交换,以及新数据的提交);数据分析工具的开发;工具的使用以及对结果生物学意义的解释。我非常认同Dr. Raunak Shrestha在他的博客中的说法:生物信息学的终极目标是在分子水平理解一个活细胞是如何工作的。
如果要问我最喜欢哪个定义,除了我自己的定义之外,我最喜欢在一段视频中看到的定义:Bioinformatics: Where code meets biology.
Reference
https://en.wikipedia.org/wiki/Bioinformatics
http://bioinfo.mbb.yale.edu/what-is-it/
https://searchoracle.techtarget.com/definition/bioinformatics
https://edwards.sdsu.edu/research/what-is-bioinformatics/
https://www.scq.ubc.ca/what-is-bioinformatics/
https://tse3.mm.bing.net/th?id=OIP.G1tK2zPG0f3T71ITT84G3wHaHo&pid=15.1
https://www.bioinformatics.org/wiki/Bioinformatics
http://omgenomics.com/what-is-bioinformatics/
https://www.sib.swiss/about-sib/what-is-bioinformatics
https://www.sib.swiss/about-sib/what-we-do
https://raunakms.wordpress.com/2010/06/05/what-is-bioinformatics-%E2%80%93-a-general-perspective/
https://www.youtube.com/watch?v=mWbuVlIX5jg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号