
Hive 2.3.2安装
一、安装mysql
- 安装MySQL服务器端和MySQL客户端;
•安装:
– yum install mysql
– yum install mysql-server
•启动:
– /etc/init.d/mysqld start
进入mysql:

5)给mysql的user用户表添加一个user 其中host为%允许任何ip访问,密码同上即可,添加语句如下:
5.1) update user set password = password(‘root’) where user = ‘root’;
5.2) GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘root’ WITH GRANT OPTION;
5.3) flush privileges;

6、mysql中表的中文乱码问题:
创建表结构:
create table userinfo(
uid int primary key auto_increment,
username varchar(20)
)engine=InnoDB DEFAULT CHARSET=utf8;
insert into userinfo(username)values('测试');
1)检查内部的编码:SHOW VARIABLES LIKE ‘character_set_%’;

SHOW VARIABLES LIKE ‘collation_%’;

2)修改编码:SET NAMES ‘utf8’;

效果如下:

二、安装Hive
1、下载、解压hive、在hive/conf 下 新建hive-site.xml,进行如下配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
2、在环境变量配置HIVE_HOME,并且让环境变量生效
source /etc/profile
三、安装MySQL链接工具
1、下载、解压
https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
2、复制数据库驱动到 hive的lib下
cp mysql-connector-java-5.1.47-bin.jar /home/bigdata/apache-hive-1.2.2-bin/lib
3、更新jline.jar包
cp jline-2.12.1.jar /home/bigdata/hadoop/share/hadoop/yarn/lib/
四、初始化元数据库(hive2.x之后必须手动初始化)
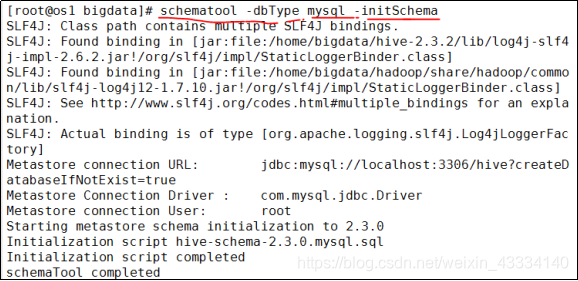
schematool -dbType mysql -initSchema
五、启动Hive (提前启动hdfs、mysql)
1、hive
2、hive --service cli

3、HiveServer2/beeline
3.1)修改hadoop的hdfs.site.xml文件:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
3.2)修改hadoop集群的core-site.xml配置文件
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 root 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
( 如果代理用户的组所属tong 则修改为:hadoop.proxyuser.tong.hosts
hadoop.proxyuser.tong.groups )
注意:启动之前,先启动hdfs,再启动hiveserver2,再beeline
3.3.1)先启动hiveserver2服务,启动后会多个【RunJar】进程

3.3.2)启动为后台:
nohup hiveserver2 1>/home/bigdata/hadoop/hiveserver.log 2>/home/bigdata/hadoop/hiveserver.err &
与地址有关系:
nohup hiveserver2 1>/opt/hadoop-2.7.5/hiveserver.log 2>/opt/hadoop-2.7.5/hiveserver.err &
//查看job hadoop job -list

解释:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,
默认的日志名称叫做: nohup.xxx
PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。
该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般
形式为:nohup command &
3.3.3) 启动beeline 客户端去连接
beeline -u jdbc:hive2//os1:10000 -n root
注意:u : 指定元数据库的链接信息 -n : 指定用户名和密码
3.3.4) 启动beeline ,然后输出!connect jdbc:hive2://os1:10000,输入用户名和密码
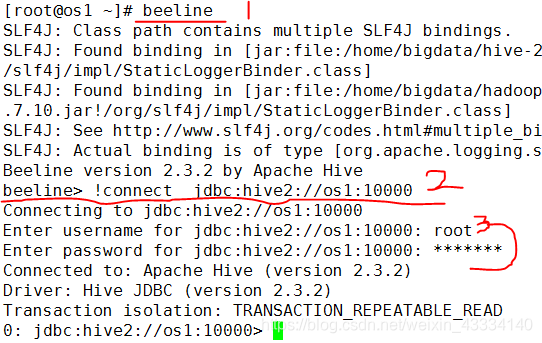
下面可以做hive操作。
本文来自博客园,作者:好事的猫,转载请注明原文链接:https://www.cnblogs.com/BeiJiuGuRen/p/15828591.html


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 上周热点回顾(2.17-2.23)
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 如何使用 Uni-app 实现视频聊天(源码,支持安卓、iOS)