

跟着大彬读源码 - Redis 7 - 对象编码之简单动态字符串
Redis 没有直接使用 C 语言传统的字符串表示(以空字符串结尾的字符数组),而是构建了一种名为简单动态字符串(simple dynamic string)的抽象类型,并将 SDS 用作 Redis 的默认字符串表示。
在 Redis 中,C 字符串只会作为字符串字面量用在一些无需对字符串进行修改的地方,比如打印日志:
serverLog(LL_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
当 Redis 需要的不仅仅是一个字符串字面量,而是一个可以被修改的字符串值时,Redis 就会适应 SDS 来表示字符串。比如在数据库中,包含字符串值的键值对在底层都是由 SDS 实现的。
还是拿简单的 SET 命令举例,执行以下命令
redis> SET msg "hello world"
ok
那么,Redis 将在数据中创建一个新的键值对,其中:
- 键值对的键是一个字符串对着,对象的底层实现是一个保存着字符串 "msg" 的 SDS。
- 键值对的值也是一个字符串对象,对象的底层实现是一个保存着字符串 "hello world" 的 SDS。
除了用来保存数据库中的字符串值之外, SDS 还被用作缓冲区。AOF 模块中的 AOF 缓冲区,以及客户端状态中的输入缓冲区,都是由 SDS 实现的。
接下来,我们就来详细认识下 SDS。
1 SDS 的定义
在 sds.h 中,我们会看到以下结构:
typedef char *sds;
可以看到,SDS 等同于 char * 类型。这是因为 SDS 需要和传统的 C 字符串保存兼容,因此将其类型设置为 char *。但是要注意的是,SDS 并不等同 char *,它还包括一个 header 结构,共有 5 中类型的 header,源码如下:
struct __attribute__ ((__packed__)) sdshdr5 { // 已弃用
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 { // 长度小于 2^8 的字符串类型
uint8_t len; // SDS 所保存的字符串长度
uint8_t alloc; // SDS 分配的长度
unsigned char flags; // 标记位,占 1 字节,使用低 3 位存储 SDS 的 type,高 5 位不使用
char buf[]; // 存储的真实字符串数据
};
struct __attribute__ ((__packed__)) sdshdr16 { // 长度小于 2^16 的字符串类型
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 长度小于 2^32 的字符串类型
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 { // 长度小于 2^64 的字符串类型
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
之所以会有 5 种类型的 header,是为了能让不同长度的字符串使用对应大小的 header,提高内存利用率。
一个 SDS 的完整结构,由内存地址上前后相邻的两部分组成:
- header:包括字符串的长度(len),最大容量(alloc)和 flags(不包含 sdshdr5)。
- buf[]:一个字符串数组。这个数组的长度等于最大容量加 1,存储着真正的字符串数据。
图 1-1 展示了一个 SDS 示例:
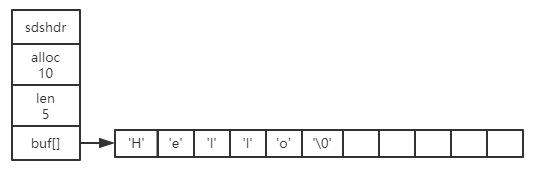
示例中,各字段说明如下:
- alloca:SDS 分配的空间大小。图中表示分配的空间大小为 10。
- len:SDS 保存字符串大小。图中表示保存了 5 个字节的字符串。
- buf[]:这个数组的长度等于最大容量加 1,存储着真正的字符串数据。图中表示数字的前 5 个字节分别保存了 'H'、'e'、'l'、'l'、'o' 五个字符,而最后一个字节则保存了空字符串 '\0'。
SDS 遵循 C 字符串以空字符结尾的惯例,保存空字符的大小不计算在 SDS 的 len 属性中。此外,添加空字符串到字符串末尾等操作,都是由 SDS 函数(sds.c 文件中的相关函数)自动完成的。
而且,遵循空字符结尾的惯例,还可以直接重用一部分 C 字符串函数库中的函数。
例如,我们可以直接使用 printf() 函数打印 s->buf:
printf("%s", s->buf);
这样,我们可以直接使用 C 函数来打印字符串 "Redis",无需为 SDS 编写转码的打印函数。
2 SDS 对比 C 字符串有哪些优势
在 C 语言中,使用长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符数组的最后一个元素总是空字符 "\0"。
C 语言使用的这种字符串表示方式,并不能满足 Redis 对字符串再安全性、效率及功能方面的要求。因此,Redis 设计出了 SDS,来满足自己的相关需求。接下来,我们从以下几方面来认识 SDS 对比 C 字符串的优势:
- 获取字符串长度;
- 缓冲区溢出;
- 修改字符串时的内存重分配次数;
- 二进制安全;
2.1 常数复杂度获取字符串长度
由于 C 字符串并不记录自身的长度信息,所以在 C 语言中,为了获取一个 C 字符串的长度,程序必须遍历整个字符串,直到遇到代表字符串结尾的空字符为止,这个操作的复杂度为 O(N)。
这个复杂度对于 Redis 而言,一旦碰上非常长的字符串,使用 STRLEN 命令时,很容易对系统性能造成影响。
和 C 字符串不同的是,因为 SDS 在 len 属性中记录了 SDS 保存的字符串的长度,所以获取一个 SDS 长度的复杂度仅为 O(1)。
而且设置和更新 SDS 长度的工作都是由 SDS 的 API 在执行时自动完成的,所以使用 SDS 无需进行任何手动修改长度的工作。
通过使用 SDS,Redis 将获取字符串长度所需的复杂度从 O(N) 降低到了 O(1),确保了获取字符串长度的工作不会成为 Redis 的性能瓶颈。
2.2 杜绝缓冲区溢出
C 字符串不记录自身长度,不仅使得获取字符串长度的复杂度较高,还容易造成缓冲区溢出(buffer overflow)。
C 语言中的 strcat() 函数可以将 src 字符串中的内容拼接到 dest 字符串的末尾:
char *strcat(char *dest, const char *src);
因为 C 字符串不记录自身的长度,所以 strcat 函数执行时,假定用户已经为 dest 分配了足够多的内存,可以容纳 src 字符串中的所有内容。而一旦这个假定不成立,就会产生缓冲区溢出。
举个例子,假设程序里有两个在内存中紧邻着的 C 字符串 s1 和 s2,其中 s1 保存了字符串 "redis",s2 保存了字符串 "mysql",存储结构如图 2-1 所示:

如果我们执行下面语句:
strcat(s1, " 666");
将 s1 的内容修改为 "redis 666",但却没有在执行 strcat() 之前为 s1 分配足够的空间,那么在执行 strcat() 之后,s1 的数据将移除到 s2 所在的空间,导致 s2 保存的内容被意外修改,如图 2-2 所示:

与 C 字符串不同的是,SDS 的空间分配策略完全杜绝了发生缓冲区溢出的可能性:当 SDS 的 API 需要对 SDS 进行修改时,API 会先检查 SDS 的空间十分满足修改所需的要求,如果不满足的话,API 会自动将 SDS 的空间扩展至执行修改所需的大小,然后再执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出问题。
2.3 减少内存重分配次数
由于 C 字符串的长度 slen 和底层数组的长度 salen 总存在着下述关系:
salen = slen + 1; // 1 是空字符的长度
因此,每次增长或缩短一个 C 字符串,总要对 C 字符串的数组进行一次内存重分配操作:
- 增长字符串。程序需要通过内存重分配来扩展底层数组的空间的大小,如果漏了这步,就可能会产生缓冲区溢出。
- 缩短字符串。程序需要通过内存重分配来释放底层数组不再使用的空间,如果漏了这步,就可能会产生内存泄漏。
而内存重分配涉及复杂的算法,并且可能需要执行系统调用,所以内存重分配是一个较为耗时的过程。
对于 Redis 而言,一切耗时的操作都要优化。基于此,SDS 对于字符串的增长和缩短操作,通过空间预分配和惰性空间释放两种方式来优化。
2.3.1 空间预分配
空间预分配是指:在需要对 SDS 的空间进行扩展时,程序不是仅仅分配所必需的的空间,还会为 SDS 分配额外的未使用空间。
关于 SDS 的空间扩展,源码如下:
# sds.c/sdsMakeRoomFor()
...
newlen = (len+addlen); // SDS 最新长度
if (newlen < SDS_MAX_PREALLOC) // 预分配最大值 SDS_MAX_PREALLOC 在 sds.h 中定义,值为 1024*1024
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
...
由源码可以看出,空间扩展分为两种情况:
- 新长度小于预分配最大值。此时,程序将直接为 SDS 新增最新长度大小的未使用空间。举个栗子,现有一个长度为 10 字节的字符串 s1,当给 s1 追加字符串 "redis",那么,程序将除了分配足够 s1 使用的空间,还会为 s1 再分配最新长度大小的预使用空间。所以,s1 的实际长度就变为:
15 + 15 + 1 = 31个字节。 - 新长度大于预分配最大值。此时,由于最新字符串较大,程序不会预分配这么多空间,只会给预分配最大值的空间。举个栗子,现有长度为 3M 的字符串 s2,当给 s1 追加一个 2M 大小的字符串,那么程序除了新增 2M 来存储新增的长度,还会为 s2 再分配 1M(SDS_MAX_PREALLOC)的预使用空间。所以,s2 的实际长度就变为:
3M + 2M +1M + 1byte。
正是通过预分配的策略,Redis 减少了执行字符串增长操作所需的内存重分配次数,保证了 Redis 不会因字符串增长操作损耗性能。
2.3.2 惰性空间释放
预分配对应字符串的增长操作,而空间释放则对应字符串的缩短操作。
惰性空间释放是指:在对 SDS 进行缩短操作时,程序不立即回收缩短后多出来的字节,等待将来使用。
举个栗子,我们使用 sdstrim() 函数,移除下图 SDS 中所有指定的字符:
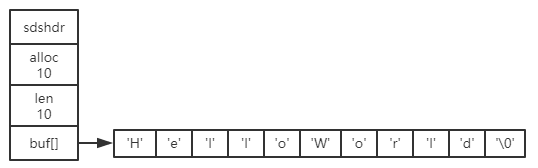
对上图 SDS,执行:
sdstrim(s, "l"); // 移除 SDS 字符串中所有的 'l'
会将 SDS 修改为图 2-4 所示:

可以看到,执行 sdstrim() 之后的 SDS 并没有释放多出来的 3 字节空间,而是将这 3 字节空间作为未使用空间保留在了 SDS 里面,以待备用。
正是通过惰性空间释放策略,SDS 避免了缩短字符串时所需的内存重分配操作,并为将来可能的增长操作提供了优化。
此外,SDS 也提供了相应的 API,让我们在有需要时,真正的释放 SDS 的未使用空间,避免造成内存浪费。
总结
- Redis 只会使用 C 字符串作为字面量,大多数情况下,使用 SDS 作为字符串表示。
- SDS 对比 C 字符串,有几大优点:常数复杂度获取字符串长度、杜绝缓冲区溢出、减少修改字符串时所需的内存重分配次数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?