

跟着大彬读源码 - Redis 5 - 对象和数据类型(上)
相信很多人应该都知道 Redis 有五种数据类型:字符串、列表、哈希、集合和有序集合。但这五种数据类型是什么含义?Redis 的数据又是怎样存储的?今天我们一起来认识下 Redis 这五种数据结构的含义及其底层实现。
首先要明确的是,Redis 并没有直接使用这五种数据结构来实现键值对数据库,而是基于这些数据结构创建了一套对象系统,我们常说的数据类型,准确来说,是 Redis 对象系统的类型。
1 对象
对于 Redis 而言,所有键值对的存储,都是将数据存储在对象结构中。所不同的是,键总是一个字符串对象,值可以是任意类型的对象。
对象源码结构如下:
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 对象编码
unsigned lru:LRU_BITS; // LRU
int refcount; // 引用统计
void *ptr; // 指向底层实现数据结构的指针
} robj;
- type 字段:对象类型,就是我们常说的。string、list、hash、set、zset。
- encoding:对象编码。也就是我们上面说的底层数据结构。
- LRU:键值对的 LRU。
- refcount:键值对对象的引用统计。当此值为 0 时,回收对象。
- *ptr:指向底层实现数据结构的指针。就是实际存放数据的地址。
1.2 对象类型
对象有五种数据类型,就是我们上面提过的:
- 字符串类型
- 列表类型
- 哈希类型
- 集合类型
- 有序集合类型
结合我们上面提到的键值对存储类型的差别,可以了解到,我们常说的“一个列表键或一个哈希键”,本质上指的是:一个 key 对应的 value 是列表对象或哈希对象。
对于 type 字段,我们可以使用 TYPE 命令来查看指定 key 对应 value 值的对象类型。
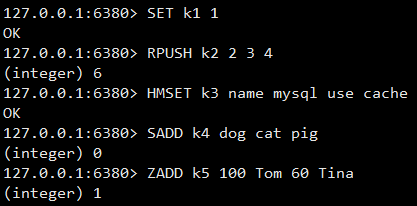
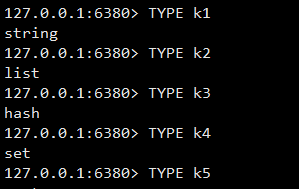
1.3 对象编码
按道理讲,已经有了 type,为什么还要搞个编码呢?
想想看,通过 encoding 属性,我们是不是使用不同编码的对象?这种使用方式可以根据不同的使用场景来为一个对象设置不同的编码,从而优化在某一场景下的效率,极大的提升了 Redis 的灵活性和效率。
举个栗子,在列表对象包含的元素比较少时,Redis 使用压缩列表作为列表对象的底层实现:
- 压缩列表比快速链表更节约内存,并且在元素数量较少时,在内存中以连续块方式报错的压缩列表比起快速列表可以更快的载入到缓存中;
- 随着列表对象包含的元素越来越多,使用压缩列表保存元素的优势消失时,对象就会将底层实现从压缩列表转为功能更强、也更适合保存大量元素的快速链表。
后面介绍完编码类型后,我们会详细认识不同类型对应的各个编码方式。
encoding 属性有以下取值:
- OBJ_ENCODING_RAW
- OBJ_ENCODING_INT
- OBJ_ENCODING_HT
- OBJ_ENCODING_QUICKLIST
- OBJ_ENCODING_ZIPLIST
- OBJ_ENCODING_INTSET
- OBJ_ENCODING_SKIPLIST
- OBJ_ENCODING_EMBSTR
对象的编码类型可以由 OBJECT ENCODING 命令获取。
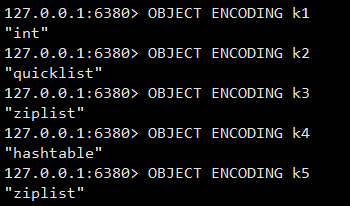
OBJECT ENCODING 命令对应源码如下:
# src/object.c
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_ZIPLIST: return "ziplist";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
default: return "unknown";
}
}
OBJECT ENCODING 命令输出值与 encoding 属性取值对应关系如下:
| 对象使用的底层数据结构 | 编码常量 | OBJECT ENCODING 输出 |
|---|---|---|
| 简单动态字符串 | OBJ_ENCODING_RAW | "raw" |
| 整数 | OBJ_ENCODING_INT | "int" |
| embstr 编码的简单动态字符串 | OBJ_ENCODING_EMBSTR | "embstr" |
| 字典 | OBJ_ENCODING_HT | "hashtable" |
| 压缩列表 | OBJ_ENCODING_ZIPLIST | "ziplist" |
| 快速列表 | OBJ_ENCODING_QUICKLIST | "quicklist" |
| 整数集合 | OBJ_ENCODING_INTSET | "intset" |
| 跳跃表 | OBJ_ENCODING_SKIPLIST | "skiplist" |
总结来看,如下图:
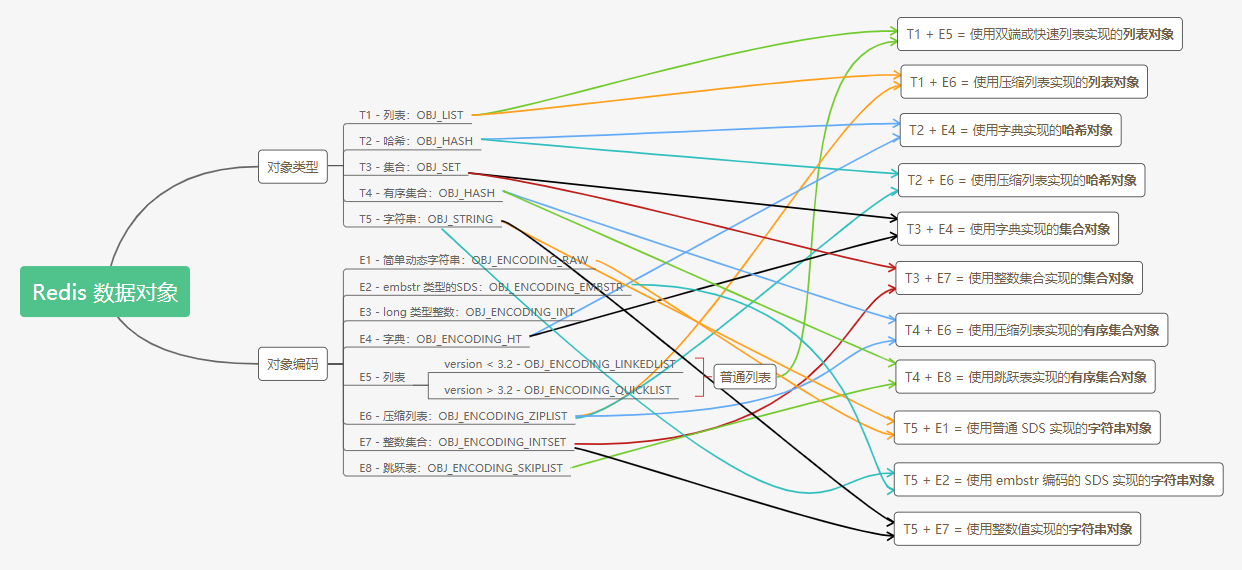
十一种不同编码的对象分别是:
- 使用双端或快速列表实现的列表对象
- 使用压缩列表实现的列表对象
- 使用字典实现的哈希对象
- 使用压缩列表实现的哈希对象
- 使用字典实现的集合对象
- 使用整数集合实现的集合对象
- 使用压缩列表实现的有序集合对象
- 使用跳跃表实现的有序集合对象
- 使用普通 SDS 实现的字符串对象
- 使用 embstr 编码的 SDS 实现的字符串对象
- 使用整数值实现的字符串对象
接下来,我们将对上述十一种对象一一介绍。之后再一一认识对象编码。
2 字符串对象
字符串对象的可选编码分别是:int、raw 或者 embstr。
2.1 int 编码的字符串对象
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型表示,那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性中,并将字符串对象的编码设置为 int。
我们执行以下 SET 命令,服务器将创建一个如下图所示的 int 编码的字符串对象作为 num 键的值:
# redis-cli
127.0.0.1:6380> set num 12345
OK
127.0.0.1:6380> OBJECT ENCODING num
"int"
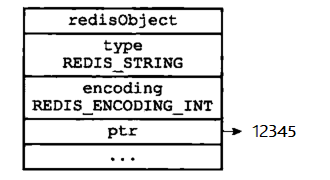
2.2 raw 编码的字符串对象
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于 44 字节(根据版本的不同,这个值会有差异。详见 object.c 文件中的 OBJ_ENCODING_EMBSTR_SIZE_LIMIT 常量),那么字符串对象将使用**简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为 raw。
我们执行下面的 SET 命令,服务器将创建一个图 7 所示的 raw 编码的字符串对象作为 k1 键的值(45 字节):
127.0.0.1:7379> set story 'k01234567890123456789012345678901234567890123'
OK
127.0.0.1:7379> OBJECT ENCODING k4
"raw"
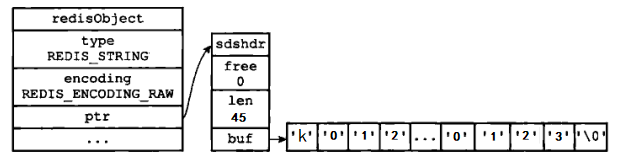
2.3 embstr 编码的字符串对象
如果字符串保存的是一个字符串值,并且这个字符串值的长度小于等于 44 字节(根据版本的不同,这个值会有差异。详见 object.c 文件中的 OBJ_ENCODING_EMBSTR_SIZE_LIMIT 常量),那么字符串对象将使用 embstr 编码的方式来保存这个字符串。
embstr 编码是专门用于保存段字符串的一种优化编码方式,这种编码和 raw 编码一样,都使用 redisObject 和 sdshdr 结构来表示字符串对象。但和 raw 编码的字符串对象不同的是:
- raw 编码会调用两次内存分配函数来分别创建 redisObject 和 sdshdr 结构
- embstr 编码通过一次内存分配函数分配一块连续的空间,空间中依次包含 redisObject 和 sdsHdr 两个结构。
相对应的,释放内存时,embstr 编码的对象也只需调用一次内存释放函数。
因此,使用 embstr 编码的字符串对象来保存短字符串值有以下好处:
- 创建字符串对象时,内存分配次数从两次降低为一次。
- 释放 embstr 编码的字符串对象时,调用内存释放函数的次数从两次降低为一次。
- 更好地利用缓存优势。embstr 编码的字符串对象的所有数据都保存在一块连续的内存中 ,这种方式比 raw 编码的字符串对象能够更好的利用缓存带来的优势。
以下命令创建了一个 embstr 编码的字符串对象作为 msg 键的值,值对象结构如图 8。
127.0.0.1:6380> SET msg hello
OK
127.0.0.1:6380> OBJECT ENCODING msg
"embstr"

2.4 浮点数编码
Redis 中,long double 类型的浮点数也是作为字符串值来保存的。
我们要保存一个浮点数到字符串对象中,程序会先将这个浮点数转换成字符串值,然后再保存转换所得的字符串值。
执行以下代码,将创建一个包含 3.14 的字符串表示 "3.14" 的字符串对象:
127.0.0.1:6380> SET pi 3.14
OK
127.0.0.1:6380> OBJECT ENCODING pi
"embstr"
在有需要的时候,程序会将保存在字符串对象里的字符串值转换成浮点数值,执行某些操作,然后将所得的浮点数值转换回字符串值,继续保存在字符串对象中。
比如,我们对 pi 键执行以下操作:
127.0.0.1:6380> INCRBYFLOAT pi 2.0
"5.14"
127.0.0.1:6380> OBJECT ENCODING pi
"embstr"
执行 INCRBYFLOAT 命令过程中,实际上就会出现字符串与浮点数值互相转换的情况。
2.5 编码转换
int 编码的字符串对象和 embstr 编码的字符串对象在满足某些条件的情况下,会被转换为 raw 编码的字符串对象。
对于 int 编码的字符串对象来说,如果我们在执行命令后,使得这个对象保存的不再是整数值,而是一个字符串,那么字符串对象就会从 int 变为 raw。比如 APPEND 命令等。
另外,对于 embstr 编码的字符串,由于 Redis 没有为其编写任何相应的修改程序,所以 embstr 编码的字符串对象实际上是只读的。当我们对 embstr 编码的字符串对象执行任何修改命令时,程序都会先将对象的编码从 embstr 转换成 raw。也就是说,embstr 编码的字符串一旦修改,一定会转换成 raw 编码的字符串对象。
2.6 值与编码对应关系
对于字符串对象各个编码的情况,总结如下:
| 值 | 编码 |
|---|---|
| 可以用 long 表示的整数值 | int |
| 可以用 long double 保存的浮点数 | raw 或 embstr |
| 不可以用 long 或 long double 表示的整数或小数值 | raw 或 embstr |
| 大于 44 字节的字符串 | raw |
| 小于或等于 44 字节的字符串 | embstr |
3 列表对象
列表对象的可选编码分别是:quicklist(3.2 版本前是 ziplist 和 linkedlist)。
3.1 quicklist 编码的列表对象
3.2 版本引入了 quicklist 编码,此编码结合了 ziplist 和 linkedlist,使用双向链表的形式,在每个节点上存储一个 ziplist,而每个 ziplist 又可以存储多个键值对。也就是说,quicklist 每个节点上存储的不是一个数据,而是一片数据。
执行以下命令,服务器将会创建一个列表对象,quicklist 结构如图 8 所示:
127.0.0.1:7379> RPUSH animal 'dog' 'cat' 'pig'
(integer) 3
(5.12s)
127.0.0.1:7379> OBJECT ENCODING animal
"quicklist"
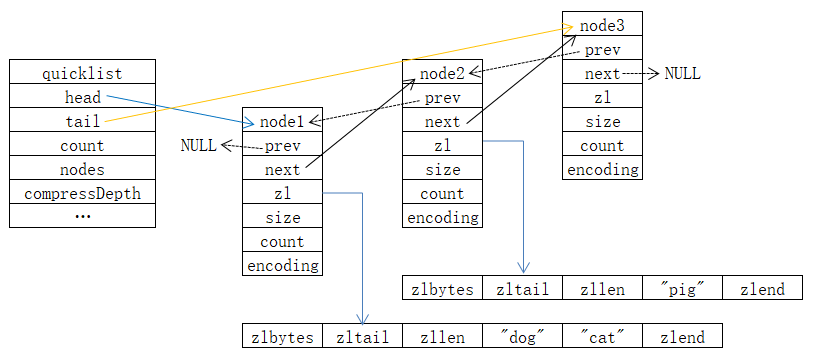
总结
- Redis 自己实现了一套对象系统来实现所有功能。
- 对象有对象类型和对象编码。
- 对象类型对应字符串、列表、哈希、集合、有序集合五种。
- 对象编码对应跳跃表、压缩列表、集合、动态字符串等八种底层数据结构。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具