
Web服务器实现|基于阻塞队列线程池的Http服务器|线程控制|Http协议
基于阻塞队列生产者消费者模型线程池的多线程Web服务器
README
摘要
本实验通过C++语言,实现了一个基于阻塞队列线程池的多线程Web服务器。该服务器支持通过http协议发送报文,跨主机抓取服务器上特定资源。与此同时,该Web服务器后台通过C++语言,通过原生系统线程调用
pthread.h,实现了一个基于阻塞队列的线程池,该线程池支持手动设置线程池中线程数量。与此同时,该线程池通过维护任务队列,每次Web服务器获取请求时,后台服务器就会将特定请求对应的特定任务加载到线程池中,等待线程池中线程的调用。由于在本项目中,每次的远端抓取都是短链接,因此在理论上,该Web服务器可以接收无数个请求。按照实验要求,本Web服务器可以接受并解析 HTTP 请求,然后从服务器的文件系统中读取被 HTTP 请求的文件,并根据该文件是否存在而向客户端发送正确的响应消息。
在服务端终端中,服务器能够按照不同等级打印日志信息,并且在收到请求时打印报文信息。
执行效果
定义代码下./wwwroot目录为服务器资源的根目录,定义./wwwroot/index.html为服务器主页。
- 当客户端请求资源存在时,服务器将返回对应资源。
- 当客户端请求路径是
/根目录时,服务器默认返回主页。 - 当客户端申请路径不存在时,服务端返回
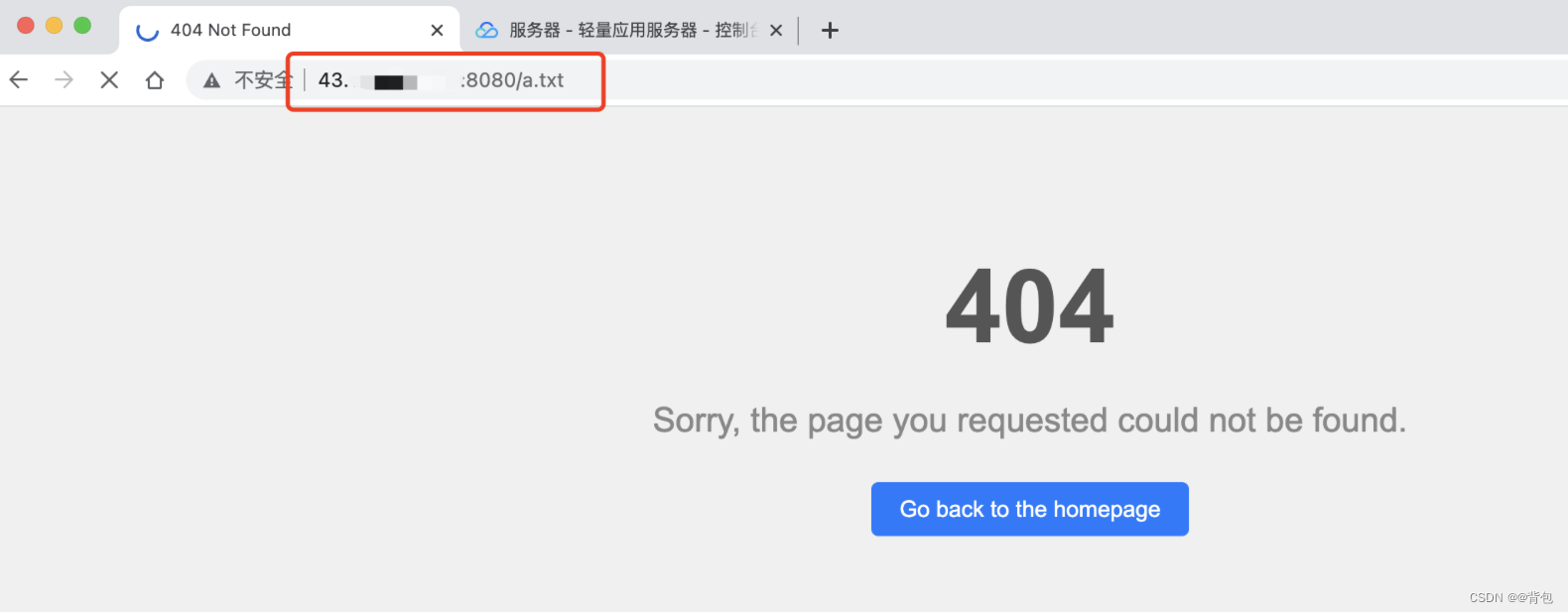
./wwwroot/error/404.html作为返回资源。
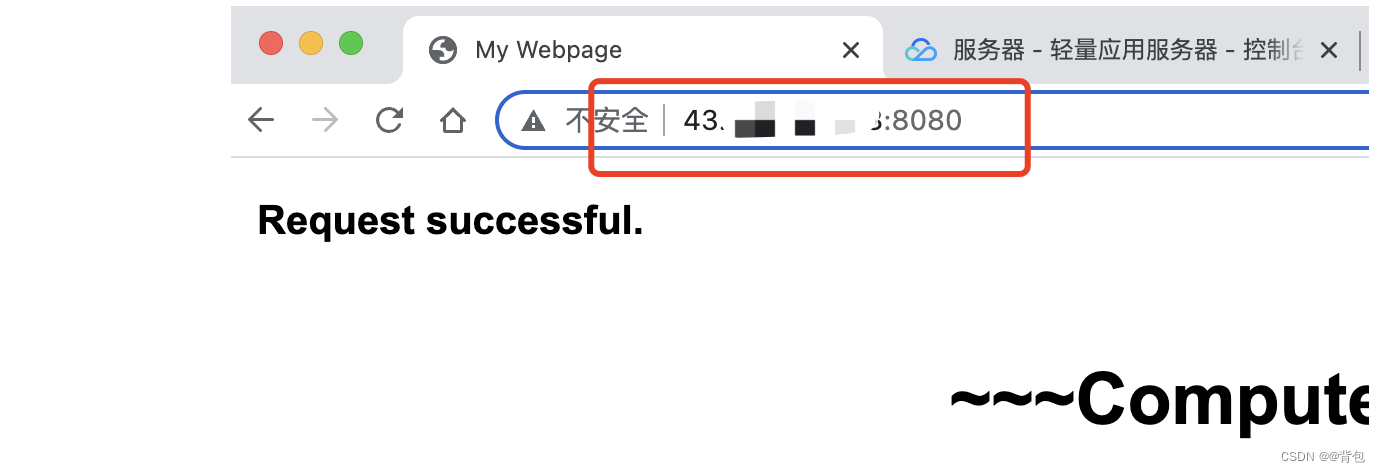
服务器开机

浏览器远端连接
服务器是腾讯云的远端服务器,浏览器是本地浏览器。这是一个跨局域网的跨主机测试。
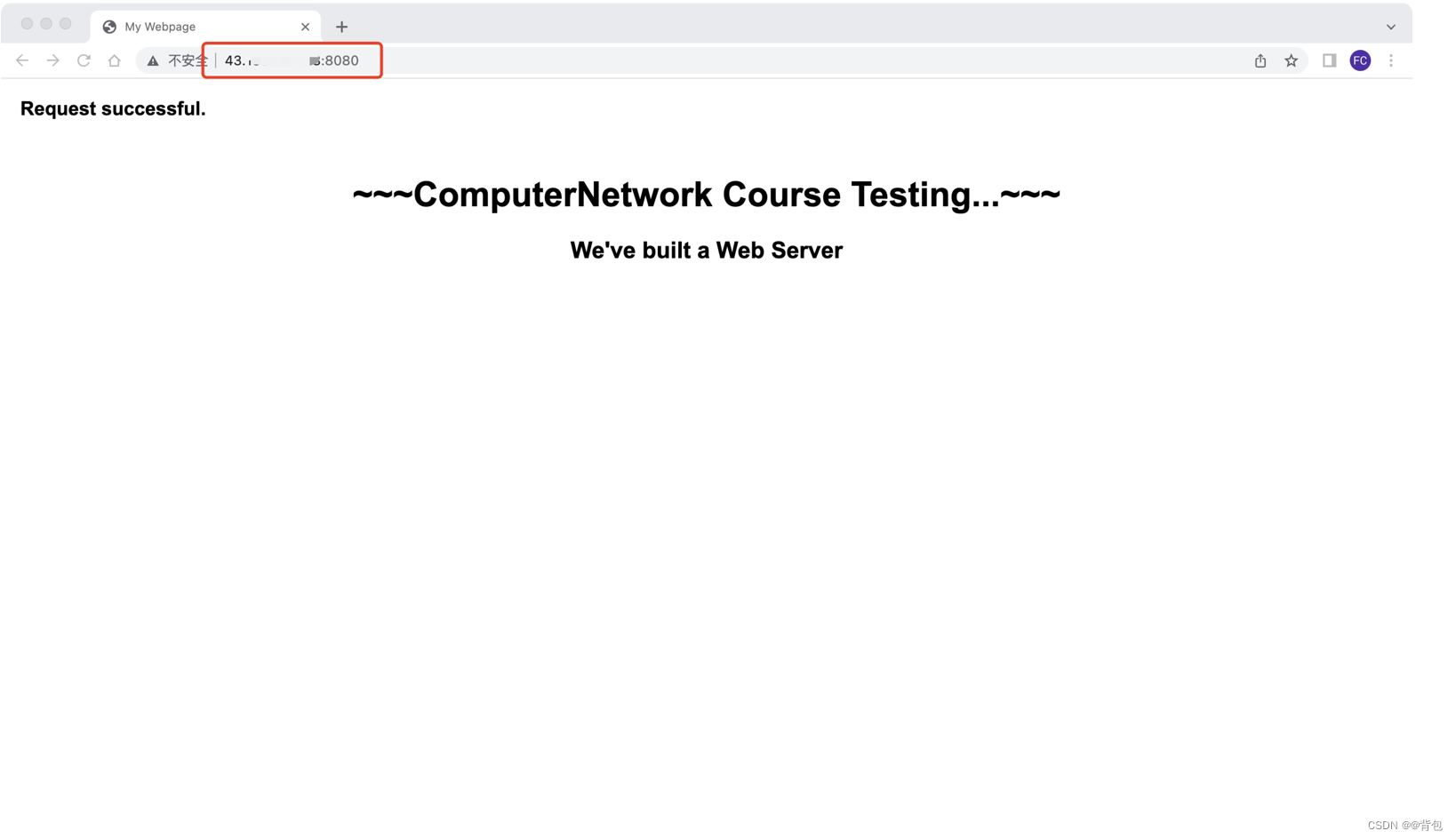
客户端申请不存在的资源
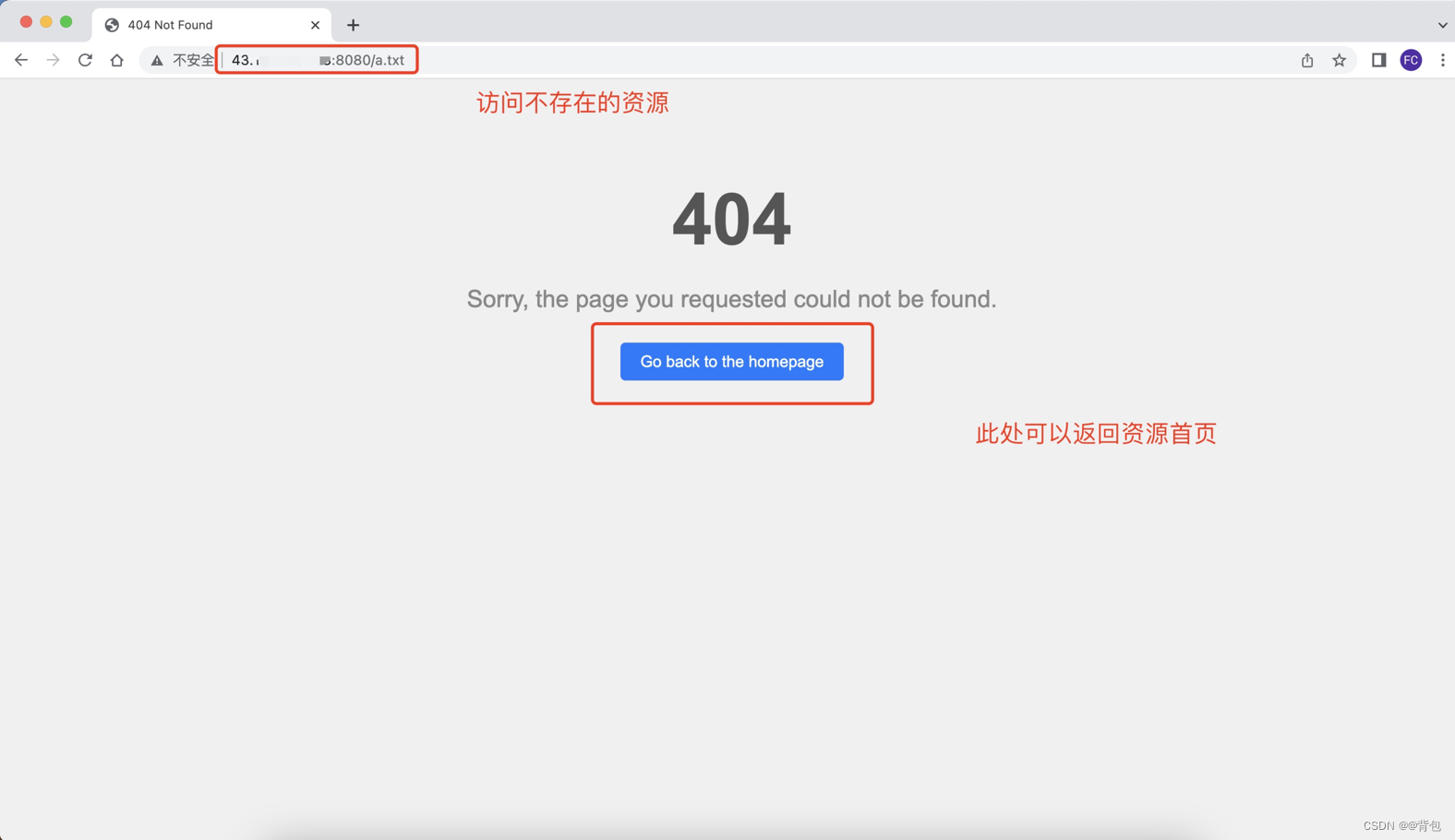
客户端发送请求时,后台服务器所获取到的报文
多个客户端发起请求
该服务器理论上支持无数个短链接进行请求
环境准备
系统: Linux version 3.10.0-1160.11.1.el7.x86_64
编译器版本: gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
资源文件/源文件准备目录结构
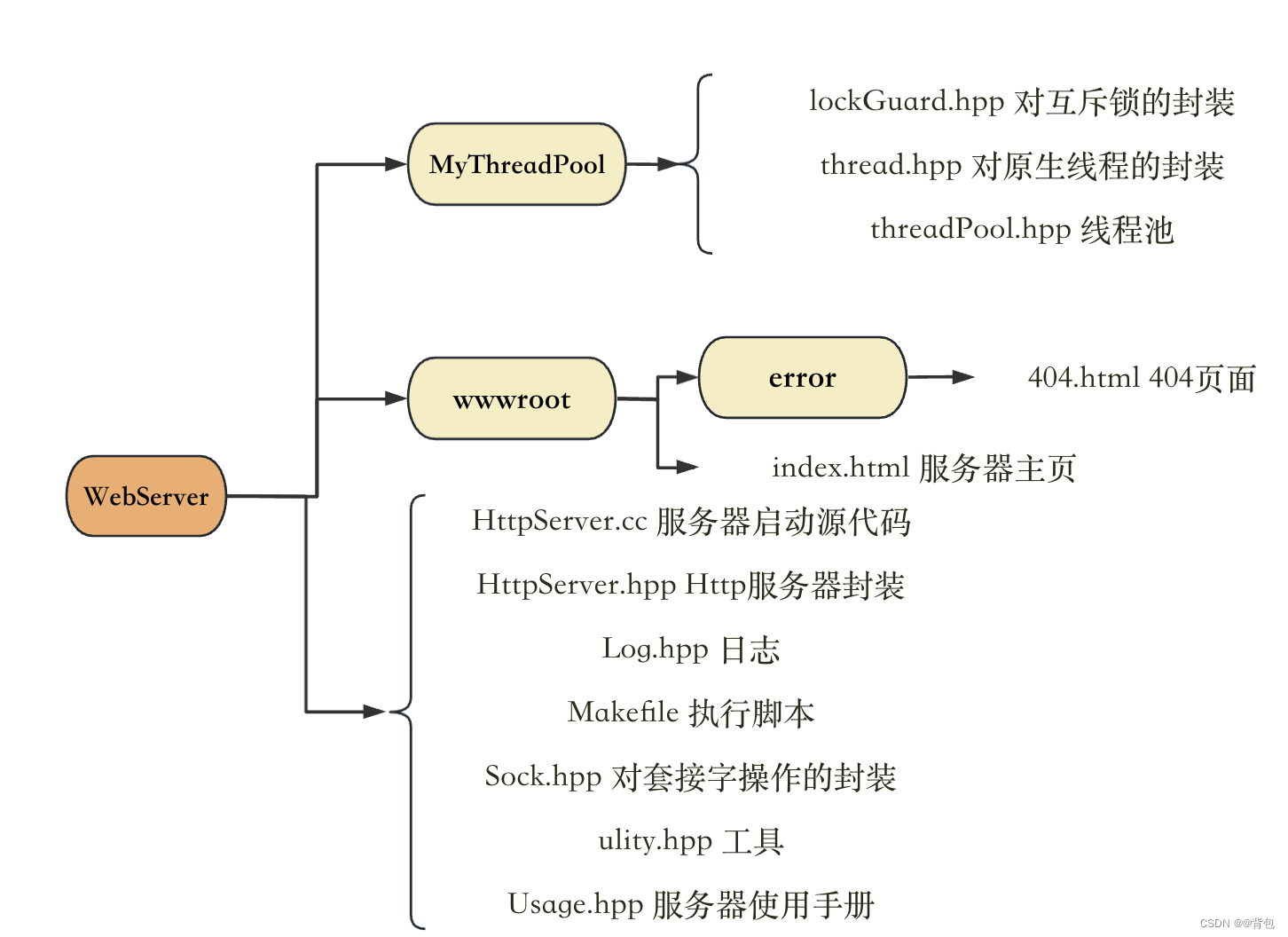
MyThreadPool目录维护手写的线程池源代码./wwwroot/目录维护服务器资源,其中./wwwroot/是客户端访问的根目录- 其他文件均为HttpServer源代码
RUN
服务默认端口号:8080
tips: 如果运行过程中二进制程序HttpServer没有可执行权限 chmod 755 HttpServer
生成可执行:make clean;make
启动服务器:./HttpServer 8080
在浏览器中输入:ip:port即可访问服务器主页
或输入:ip:port/index.html也可以访问服务器主页
输入不存在的路径: 43:xxx:xxx:xxx:8080/a.txt
代码详解
Web服务器实现架构
第一层封装:对套接字的基本操作进行封装 Sock.hpp
/* 具体接口实现可以见源代码 */
/* Sock.hpp */
class Sock
{
private:
const static int gbacklog = 20;
public:
Sock() {}
~Sock() {}
/* 以下接口内部调用的都是套接字的底层调用 */
int Socket(); // 创建获取套接字 -- 返回值: 监听套接字
void Bind(int sock, uint16_t port, std::string ip = "0.0.0.0"); // 绑定
void Listen(int sock); // 设置监听状态
int Accept(int listensock, std::string *ip, uint16_t *port); // 接收连接 -- 返回值: 服务套接字
bool Connect(int sock, const std::string &server_ip, const uint16_t &server_port);
};
第二层封装:对Http服务器的封装 HttpServer.hpp
- 通过维护
Task类,可以把线程所需要执行的动作进行封装。通过Task类的operator()()重载,线程可以直接执行内部绑定好的方法。 - 通过维护
HttpServer类,当初始化并执行HttpServer::Start()后,启动线程池,Accept成功后,把相对应的任务加载到线程池中,等待线程池中线程的调用。
#ifndef __Yufc_HttpServer
#define __Yufc_HttpServer
#include "Sock.hpp"
#include <functional>
#include "MyThreadPool/threadPool.hpp"
using func_t = std::function<void(int)>;
/* 任务类 */
struct Task
{
public:
func_t func__;
int sock__;
public:
Task() {}
Task(func_t func, int sock) : func__(func), sock__(sock) {}
void operator()()
{
func__(sock__);
}
};
/* http 服务器类 */
class HttpServer
{
private:
int __listen_sock;
uint16_t __port;
Sock __sock;
func_t __func;
yufc_thread_pool::ThreadPool<Task> *__thread_pool = yufc_thread_pool::ThreadPool<Task>::getThreadPool();
public:
HttpServer(const uint16_t &port, func_t func) : __port(port), __func(func);
~HttpServer();
void Start();
};
#endif
Http服务器的启动 HttpServer.cc
执行HttpServer.cc后,main()创建一个服务器对象指针,并调用其中的Start()启动服务器。
void HandlerHttpRequest(int sockfd);函数维护每个线程所要执行的任务,其中包括以下内容。
- 读取Http请求
- 解析Http报文
- 创建一个http响应
- 发送响应至客户端
/* 一般http都要有自己的web根目录 */
#define ROOT "./wwwroot"
/* 如果客户端只请求了一个/ ,一般返回默认首页 */
#define HOME_PAGE "index.html"
void HandlerHttpRequest(int sockfd); // 具体实现可见源代码
int main(int argc, char **argv)
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
std::unique_ptr<HttpServer> httpserver(new HttpServer(atoi(argv[1]), HandlerHttpRequest));
httpserver->Start();
return 0;
}
ulity.hpp
提供Util类,里面提供static void cutString(const std::string &s, const std::string &sep, std::vector<std::string> *out)接口。在解析http报文时,可以把传入的字符串s按照间隔为sep的方式进行切割,并把结果放到out里面。
Usage.hpp
提供Usage函数,作为HttpServer的使用手册。
Log.hpp
提供void logMessage(int level, const char *format, ...)函数,负责打印服务器日志信息。
日志等级有:
DEBUG 调试
NORMAL 正常运行
WARNING 警告 – 进程继续运行
ERROR 非致命错误 – 进程继续运行
FATAL 致命错误 – 进程终止
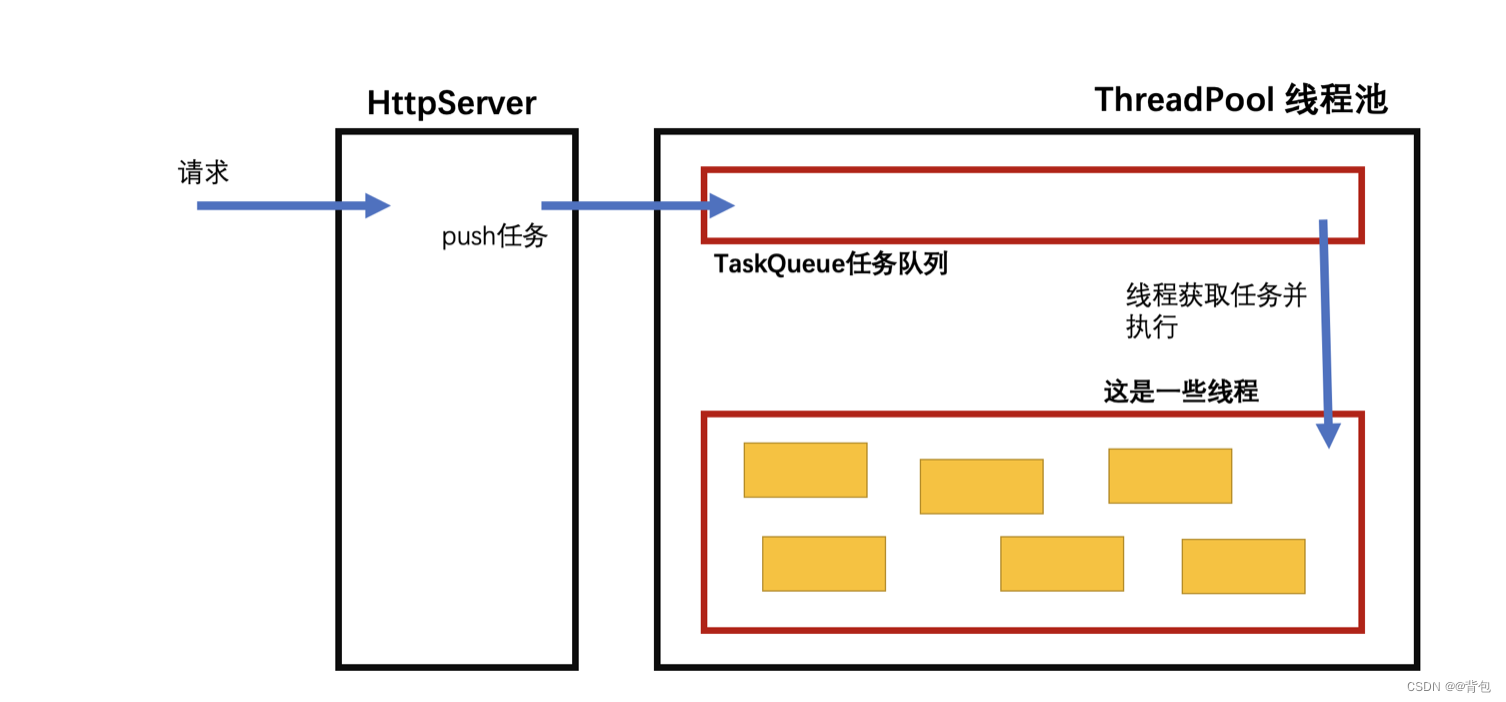
线程池实现架构
thread.hpp
- 对原生线程进行了简单封装
typedef void*(*func_t_)(void*); // 函数指针
class ThreadData
{
public:
void* __args;
std::string __name;
};
class Thread
{
private:
std::string __name; // 线程名字
pthread_t __tid; // 线程tid
func_t_ __func; // 线程要调用的函数
ThreadData __tdata; // 线程数据
public:
Thread(int num, func_t_ callback, void* args);
// num-自定义的线程编号 callback-线程要执行的任务 args-callback的参数
~Thread();
void start();
void join();
std::string name(); // 返回线程名字
};
lockGuard.hpp
- 用RAII的锁的封装风格对互斥锁进行封装
//封装一个锁
class Mutex
{
private:
pthread_mutex_t *__pmtx;
public:
Mutex(pthread_mutex_t *mtx)
:__pmtx(mtx){}
~Mutex()
{}
public:
void lock() // 加锁
{
pthread_mutex_lock(__pmtx);
}
void unlock() // 解锁
{
pthread_mutex_unlock(__pmtx);
}
};
class lockGuard
{
public:
lockGuard(pthread_mutex_t *mtx)
:__mtx(mtx)
{
__mtx.lock();
}
~lockGuard()
{
__mtx.unlock();
}
private:
Mutex __mtx;
};
threadPool.hpp
线程池整体架构
#define _DEBUG_MODE_ false
const int g_thread_num = 3; // 默认3个线程
/* 具体实现可见源代码 */
namespace yufc_thread_pool
{
template <class T>
class ThreadPool
{
private:
std::vector<Thread *> __threads; // 线程们
int __num; // 线程数量
std::queue<T> __task_queue; // 任务队列
pthread_mutex_t __lock; // 互斥锁
pthread_cond_t __cond; // 条件变量
static ThreadPool<T> *thread_ptr; // 单例模式
static pthread_mutex_t __mutexForPool; // 保护getThreadPool对互斥锁
private:
//构造放成私有的 -- 让线程池成为单例模式
ThreadPool(int thread_num = g_thread_num);
ThreadPool(const ThreadPool<T>& other) = delete;
const ThreadPool<T>& operator=(const ThreadPool<T>& other) = delete;
public:
~ThreadPool();
public:
static ThreadPool<T>* getThreadPool(int num = g_thread_num); // 懒汉模式--获取线程池
void run(); // 启动线程池
void pushTask(const T &task); // 向线程池添加任务
static void *routine(void *args); // 线程要做的事
public:
// 需要一批,外部成员访问内部属性的接口提供给static的routine,不然routine里面没法加锁
// 下面这些接口,都是没有加锁的,因为我们认为,这些函数被调用的时候,都是在安全的上下文中被调用的
// 因为这些函数调用之前,已经加锁了,调用完,lockGuard自动解锁
pthread_mutex_t *getMutex();
void waitCond(); // 等待条件变量就绪
bool isEmpty(); // 判断任务队列是否为空
T getTask(); // 获取一个任务
};
template <typename T>
ThreadPool<T> *ThreadPool<T>::thread_ptr = nullptr;
template <typename T>
pthread_mutex_t ThreadPool<T>::__mutexForPool = PTHREAD_MUTEX_INITIALIZER;
//static/全局可以这样初始化,这把锁是用来保护getThreadPool的
}
实现的一些具体细节
Http报文解析
因为我们收到的都是http请求,因此,对http请求报文进行解析,可以获得客户端信息。
以下是一段完整的http报文
GET /index.html HTTP/1.1
Host: 43.xxx.xxx.xxx:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
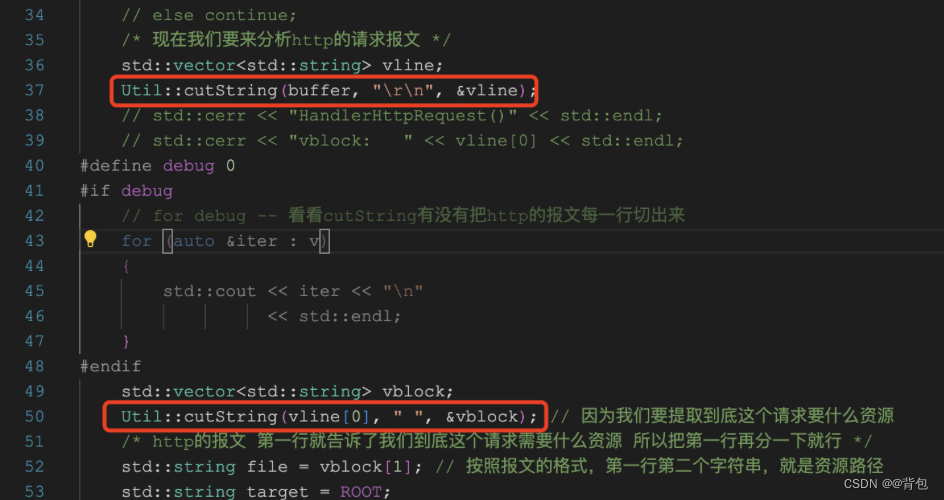
因为我们需要提取客户需要访问的资源,因此我们需要提取客户输入的资源路径。
http报文的第一行的第二个字段,则表示客户端需要提取资源的路径。
与此同时,http报文每行的间隔是特殊字符串\r\n。
因此在HttpServer.cc中的HandlerHttpRequest函数中,我们首先把http报文中的每一行分出来,并把第一行的第二个字符串提取出来,就能得到资源的路径。
单例模式的线程池
在本次实验中,我们希望一个进程只能产生一个线程池,因此我们把线程池设置成单例模式。这是一个懒汉方式的单例模式。
**懒汉:**第一次需要这个对象的时候构建该对象。
**饿汉:**在main()执行之前构建该对象。
-
把构造函数私有化
-
通过
static ThreadPool<T>* getThreadPool(int num = g_thread_num)来获取线程池在这个接口中,如果执行流是第一次执行该函数,则该函数会构造一个线程池对象并返回它的指针。如果执行流不是第一次执行该函数,则该函数则会返回
this,即自己。
另外,为了保证线程池运行时的线程安全,在线程池中多个操作中添加了互斥锁对操作进行保护。
实验结果分析和思考
改进部分:
- 实现多执行流,支持多个客户端进行连接。
- 封装线程池,使得服务器可以并行地对http请求进行响应
不足部分:
- 给客户端返回对报文是静态网页,暂时没有实现可以支持多个客户端之间共同交互的功能
- 回应报文比较粗糙,可以进一步美化。
- 可以进一步优化服务器,把服务器进程设置成守护进程,让它长期执行并提供服务。
- 没有模拟丢包的情况

