天堂之门
天堂之门
WoW64是Windows x64提供的一种兼容机制,可以认为WoW64是64位Windows系统创建的一个32位的模拟环境,使得32位可执行程序能够在64位的操作系统上正常运行
所以也弄明白了之前为什么32位的dll需要放在WoW64里面了,而64位的dll需要放在System32里面
系统运行程序的时候,会检测CS段寄存器的值来调用API
CS为0x33的时候会切换到64位模式,当CS为0x23的时候就会切换到32位模式
下面通过天堂之门技术调用WIN32 API的过程。这里我们通过一些操作绕过了WoW64机制,手动切换到64位模式并调用64位下的ZwOpenProcess函数,大致流程如下(和图中不太一样):
- 将cs段寄存器设为0x33,切换到64位模式
- 从gs:0x60读取64位PEB
- 从64位PEB中定位64位ntdll基址
- 遍历ntdll64导出表,读取ZwOpenProcess函数地址
- 构造64位函数调用
结合最近的做题,我总结就是找到更改cs段寄存器值的地方,然后根据汇编找到跳转的对应地址
关注0X33和0x23和关键的汇编指令 jmp far ptr.....
dump下来可以用bn看,然后就可以逆向解密,最近发现了ida的一个插件
OllyDumpEx · Issue #41 · mentebinaria/retoolkit (github.com)
也是可以直接在ida里面直接dump了,对于调试可以使用windbg或者CE(目前对于这两个的使用还差的很多,还要学)
unicorn
Unicorn 是一个轻量级, 多平台, 多架构的 CPU 模拟器框架. 我们可以更好地关注 CPU 操作, 忽略机器设备的差异. 想象一下, 我们可以将其应用于这些情景: 比如我们单纯只是需要模拟代码的执行而非需要一个真的 CPU 去完成那些操作, 又或者想要更安全地分析恶意代码, 检测病毒特征, 或者想要在逆向过程中验证某些代码的含义. 使用 CPU 模拟器可以很好地帮助我们提供便捷.
Programming with C & Python languages – Unicorn – The Ultimate CPU emulator (unicorn-engine.org)
它的亮点 (这也归功于 Unicorn 是基于 qemu 而开发的) 有:
- 支持多种架构: Arm, Arm64 (Armv8), M68K, Mips, Sparc, & X86 (include X86_64).
- 对 Windows 和 nix 系统 (已确认包含 Mac OSX, Linux, BSD & Solaris) 的原生支持
- 具有平台独立且简洁易于使用的 API
- 使用 JIT 编译技术, 性能表现优异
官方文档里讲了c和python接口,这里主要说一下python接口
1 from __future__ import print_function
2 from unicorn import *
3 from unicorn.x86_const import *
4
5 # code to be emulated
6 X86_CODE32 = b"\x41\x4a" # INC ecx; DEC edx
7
8 # memory address where emulation starts
9 ADDRESS = 0x1000000
10
11 print("Emulate i386 code")
12 try:
13 # Initialize emulator in X86-32bit mode
14 mu = Uc(UC_ARCH_X86, UC_MODE_32)
15
16 # map 2MB memory for this emulation
17 mu.mem_map(ADDRESS, 2 * 1024 * 1024)
18
19 # write machine code to be emulated to memory
20 mu.mem_write(ADDRESS, X86_CODE32)
21
22 # initialize machine registers
23 mu.reg_write(UC_X86_REG_ECX, 0x1234)
24 mu.reg_write(UC_X86_REG_EDX, 0x7890)
25
26 # emulate code in infinite time & unlimited instructions
27 mu.emu_start(ADDRESS, ADDRESS + len(X86_CODE32))
28
29 # now print out some registers
30 print("Emulation done. Below is the CPU context")
31
32 r_ecx = mu.reg_read(UC_X86_REG_ECX)
33 r_edx = mu.reg_read(UC_X86_REG_EDX)
34 print(">>> ECX = 0x%x" %r_ecx)
35 print(">>> EDX = 0x%x" %r_edx)
36
37 except UcError as e:
38 print("ERROR: %s" % e)
- 行号 2~3: 在使用 Unicorn 前导入unicorn模块. 样例中使用了一些 x86 寄存器常量, 所以也需要导入unicorn.x86_const模块
- 行号 6: 这是我们需要模拟的二进制机器码, 使用十六进制表示, 代表的汇编指令是: "INC ecx" 和 "DEC edx".
- 行号 9: 我们将模拟执行上述指令的所在虚拟地址
- 行号 14: 使用Uc类初始化 Unicorn, 该类接受 2 个参数: 硬件架构和硬件位数 (模式). 在样例中我们需要模拟执行 x86 架构的 32 位代码, 我 们使用变量mu来接受返回值.
- 行号 17: 使用mem_map方法根据在行号 9 处声明的地址, 映射 2MB 用于模拟执行的内存空间. 所有进程中的 CPU 操作都应该只访问该内存区域. 映射的内存具有默认的读, 写和执行权限.
- 行号 20: 将需要模拟执行的代码写入我们刚刚映射的内存中. mem_write方法接受 2 个参数: 要写入的内存地址和需要写入内存的代码.
- 行号 23~24: 使用reg_write方法设置ECX和EDX寄存器的值
- 行号 27: 使用emu_start方法开始模拟执行, 该 API 接受 4 个参数: 要模拟执行的代码地址, 模拟执行停止的内存地址 (这里是 X86_CODE32的最后 1 字节处), 模拟执行的时间和需要执行的指令数目. 如果我们像样例一样忽略后两个参数, Unicorn 将会默认以无穷时间和无穷指令数目的条件来模拟执行代码.
- 行号 32~35: 打印输出ECX和EDX寄存器的值. 我们使用函数reg_read来读取寄存器的值.
后面对于这个的使用会补上一些题....
每日一题

最开始点进来发现是一串数字,c了过后感觉也不太对,觉得是SMC,然后动态走一下,小改一下花指令

基本可以确定是SMC了,然后调试开始乱飞
从这里开始飞,然后根据逻辑判断这里也是关键的加密部分

jmp far ptr可以知道的是可以同时改变eip和cs段寄存器值的指令
这种格式的jmp指令实现的是上述的段间转移,同时修改CS和IP,在跳转范围大于-32768~32767时使用jmp near ptr不会编译失败,但是会链接失败。
该指令执行后CS:IP将同时修改
这个不要看反汇编指令,其实是跳转的是4011D0这个地址,修改的CS段寄存器为0X33
然后可以在bn里设置64位然后查看反汇编,有个反调试PEB.BeingDebugged
记得绕过
dump下来后可以看见
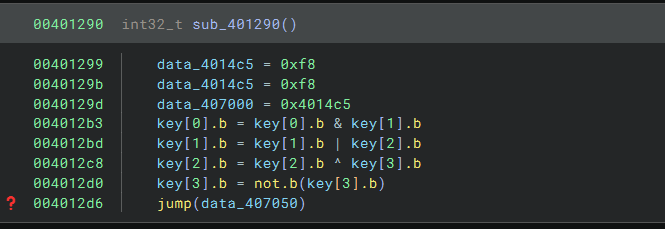
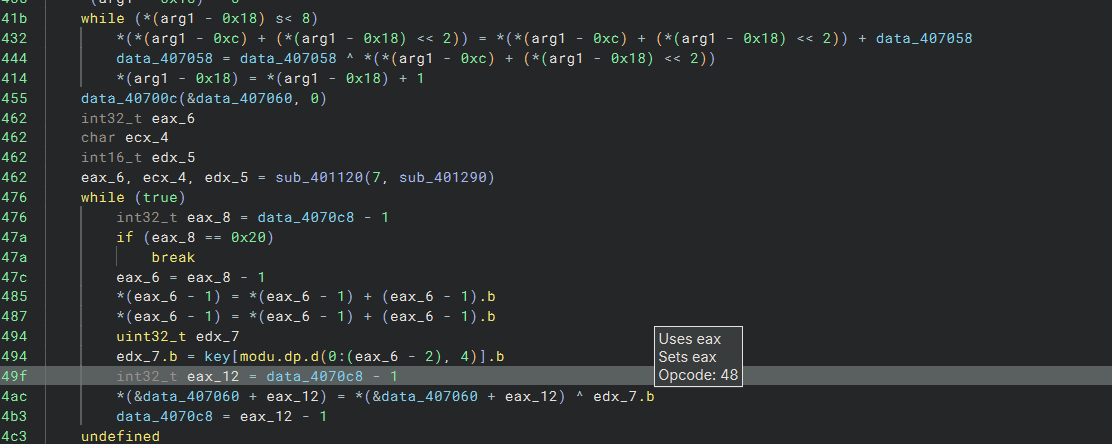
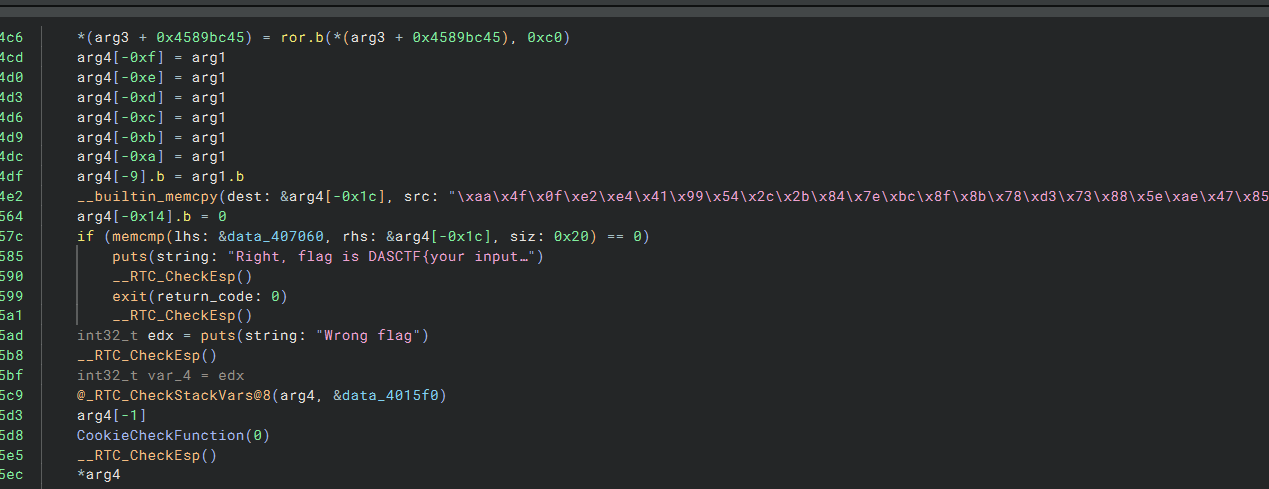
最后求flag的过程不难,就是简单的异或和循环左移右移
贴一个其他师傅写的脚本
rol = lambda val, r_bits, max_bits: \
(val << r_bits%max_bits) & (2**max_bits-1) | \
((val & (2**max_bits-1)) >> (max_bits-(r_bits%max_bits)))
ror = lambda val, r_bits, max_bits: \
((val & (2**max_bits-1)) >> r_bits%max_bits) | \
(val << (max_bits-(r_bits%max_bits)) & (2**max_bits-1))
flag = b'1234adc89012345678901234a27890ab'
cmp = [0xAA, 0x4F, 0x0F, 0xE2, 0xE4, 0x41, 0x99, 0x54, 0x2C, 0x2B, 0x84, 0x7E, 0xBC, 0x8F, 0x8B, 0x78, 0xD3, 0x73, 0x88, 0x5E, 0xAE, 0x47, 0x85, 0x70, 0x31, 0xB3, 0x09, 0xCE, 0x13, 0xF5, 0x0D, 0xCA]
# key = [0x9d,0x44,0x37,0xb5]
key = [4,0x77,0x82, 0x4a]
print(bytes(cmp))
print()
def enc(flag):
enc = b''
num = 0x3CA7259D
for i in range(8):
cur = int.from_bytes(flag[4*i:4*i+4],'little')
cur = (cur+num)&0xffffffff
num ^= cur
enc += cur.to_bytes(4,'little')
print("enc1 ", enc)
enc = bytearray(enc )
cur = int.from_bytes(enc[0:8],'little')
enc[0:8] = rol(cur,0xc, 64).to_bytes(8,'little')
cur = int.from_bytes(enc[8:16],'little')
enc[8:16] = rol(cur,0x22, 64).to_bytes(8,'little')
cur = int.from_bytes(enc[16:24],'little')
enc[16:24] = rol(cur,0x38, 64).to_bytes(8,'little')
cur = int.from_bytes(enc[24:32],'little')
enc[24:32] = rol(cur,0xe, 64).to_bytes(8,'little')
# for i in range(4):
# enc[i*8:i*8+4], enc[i*8+4:i*8+8] = enc[i*8+4:i*8+8], enc[i*8:i*8+4],
print("enc2 ", bytes(enc))
for i in range(32):
enc[i] ^= key[i%4]
print("enc3 ", enc)
return enc
def dec(cmp):
print("dec3 ", cmp)
dec = [0]*32
cmp = bytearray(cmp)
for i in range(32):
cmp[i] ^= key[i%4]
print("dec2 ", cmp)
# for i in range(4):
# cmp[i*8:i*8+4], cmp[i*8+4:i*8+8] = cmp[i*8+4:i*8+8], cmp[i*8:i*8+4]
cur = int.from_bytes(cmp[0:8],'little')
cmp[0:8] = ror(cur,0xc, 64).to_bytes(8,'little')
cur = int.from_bytes(cmp[8:16],'little')
cmp[8:16] = ror(cur,0x22, 64).to_bytes(8,'little')
cur = int.from_bytes(cmp[16:24],'little')
cmp[16:24] = ror(cur,0x38, 64).to_bytes(8,'little')
cur = int.from_bytes(cmp[24:32],'little')
cmp[24:32] = ror(cur,0xe, 64).to_bytes(8,'little')
print("dec1 ", bytes(cmp))
num = 0x3CA7259D
for i in range(8):
num ^= int.from_bytes(cmp[4*i:4*i+4],'little')
for i in range(7,-1,-1):
cur = int.from_bytes(cmp[4*i:4*i+4],'little')
num ^= cur
cur = (cur+0x100000000-num)&0xffffffff
dec[4*i:4*i+4] = cur.to_bytes(4,'little')
return bytes(dec)
assert(dec(enc(flag)) == flag)
print('----------------------')
print(dec(cmp)) # 6cc1e44811647d38a15017e389b3f704

 浙公网安备 33010602011771号
浙公网安备 33010602011771号