阿里云CTF and 其他
RE复现
login_system
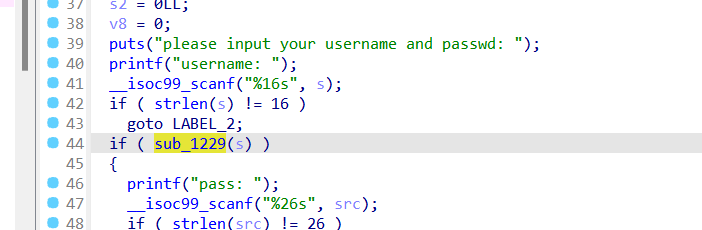
这个函数就是判断username,点进去发现是线性方程,用z3解
from z3 import *
s=Solver()
a=[0]*16
for i in range(16):
a[i]=Int('a'+"["+str(i)+"]")
s.add(a[2]+a[1]+a[0]+a[3]==447)
s.add(101*a[2]+a[0]+9*a[1]+8*a[3]==12265)
s.add(5*a[2]+3*a[0]+4*a[1]+6*a[3]==2000)
s.add(88*a[2]+12*a[0]+11*a[1]+87*a[3]==21475)
s.add(a[6]+59*a[5]+100*a[4]+a[7]==7896)
s.add(443*a[4]+200*a[5]+10*a[6]+16*a[7]==33774)
s.add(556*a[5]+333*a[4]+8*a[6]+7*a[7]==44758)
s.add(a[6]+a[5]+202*a[4]+a[7]==9950)
s.add(78*a[10]+35*a[9]+23*a[8]+89*a[11]==24052)
s.add(78*a[8]+59*a[9]+15*a[10]+91*a[11]==25209)
s.add(111*a[10]+654*a[9]+123*a[8]+222*a[11]==113427)
s.add(6*a[9]+72*a[8]+5*a[10]+444*a[11]==54166)
s.add(56*a[14]+35*a[12]+6*a[13]+121*a[15]==11130)
s.add(169*a[14]+158*a[13]+98*a[12]+124*a[15]==27382)
s.add(147*a[13]+65*a[12]+131*a[14]+129*a[15]==23564)
s.add(137*a[14]+132*a[13]+620*a[12]+135*a[15]==51206)
if s.check()==sat:
m=s.model()
for i in range(16):
print(m[a[i]],end=",")
a=[117,115,101,114,48,49,95,110,107,99,116,102,50,48,50,52]
for i in range(16):
print(chr(a[i]),end="")
#user01_nkctf2024
有一个简单的异或求解

a=[0x7E, 0x5A, 0x6E, 0x77, 0x3A, 0x79, 0x35, 0x76, 0x7C]
for i in range(9):
a[i]=(a[i]+i-9)^i
print(chr(a[i]),end="")
#uSer1p4ss
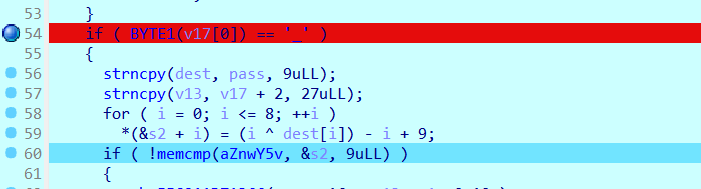
v17指向的是password的第十位,即第十位要是_
dest已经求出,可以知道password的前十位是uSer1p4ss_
后面的关键就是这个函数了
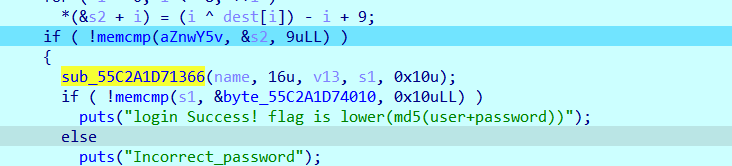
跟进,很明显的AES特征,拿出S_BOX,然后求逆S_BOX
然后就是网上找的板子
class AES:#128-ECB
sbox = [0x31, 0x52, 0x5A, 0xC8, 0x0B, 0xAC, 0xF3, 0x3A, 0x8B, 0x54,
0x27, 0x9B, 0xAB, 0x95, 0xDE, 0x83, 0x60, 0xCB, 0x53, 0x7F,
0xC4, 0xE3, 0x0A, 0x97, 0xE0, 0x29, 0xD5, 0x68, 0xC5, 0xDF,
0xF4, 0x7B, 0xAA, 0xD6, 0x42, 0x78, 0x6C, 0xE9, 0x70, 0x17,
0xD7, 0x37, 0x24, 0x49, 0x75, 0xA9, 0x89, 0x67, 0x03, 0xFA,
0xD9, 0x91, 0xB4, 0x5B, 0xC2, 0x4E, 0x92, 0xFC, 0x46, 0xB1,
0x73, 0x08, 0xC7, 0x74, 0x09, 0xAF, 0xEC, 0xF5, 0x4D, 0x2D,
0xEA, 0xA5, 0xDA, 0xEF, 0xA6, 0x2B, 0x7E, 0x0C, 0x8F, 0xB0,
0x04, 0x06, 0x62, 0x84, 0x15, 0x8E, 0x12, 0x1D, 0x44, 0xC0,
0xE2, 0x38, 0xD4, 0x47, 0x28, 0x45, 0x6E, 0x9D, 0x63, 0xCF,
0xE6, 0x8C, 0x18, 0x82, 0x1B, 0x2C, 0xEE, 0x87, 0x94, 0x10,
0xC1, 0x20, 0x07, 0x4A, 0xA4, 0xEB, 0x77, 0xBC, 0xD3, 0xE1,
0x66, 0x2A, 0x6B, 0xE7, 0x79, 0xCC, 0x86, 0x16, 0xD0, 0xD1,
0x19, 0x55, 0x3C, 0x9F, 0xFB, 0x30, 0x98, 0xBD, 0xB8, 0xF1,
0x9E, 0x61, 0xCD, 0x90, 0xCE, 0x7C, 0x8D, 0x57, 0xAE, 0x6A,
0xB3, 0x3D, 0x76, 0xA7, 0x71, 0x88, 0xA2, 0xBA, 0x4F, 0x3E,
0x40, 0x64, 0x0F, 0x48, 0x21, 0x35, 0x36, 0x2F, 0xE8, 0x14,
0x5D, 0x51, 0xD8, 0xB5, 0xFE, 0xD2, 0x96, 0x93, 0xA1, 0xB6,
0x43, 0x0D, 0x4C, 0x80, 0xC9, 0xFF, 0xA3, 0xDD, 0x72, 0x05,
0x59, 0xBF, 0x0E, 0x26, 0x34, 0x1F, 0x13, 0xE5, 0xDC, 0xF2,
0xC6, 0x50, 0x1E, 0xE4, 0x85, 0xB7, 0x39, 0x8A, 0xCA, 0xED,
0x9C, 0xBB, 0x56, 0x23, 0x1A, 0xF0, 0x32, 0x58, 0xB2, 0x65,
0x33, 0x6F, 0x41, 0xBE, 0x3F, 0x6D, 0x11, 0x00, 0xAD, 0x5F,
0xC3, 0x81, 0x25, 0xA8, 0xA0, 0x9A, 0xF6, 0xF7, 0x5E, 0x99,
0x22, 0x2E, 0x4B, 0xF9, 0x3B, 0x02, 0x7A, 0xB9, 0x5C, 0x69,
0xF8, 0x1C, 0xDB, 0x01, 0x7D, 0xFD]
s_box = {}
ns_box = { }
Rcon = {
1: ['0x01', '0x00', '0x00', '0x00'],
2: ['0x02', '0x00', '0x00', '0x00'],
3: ['0x04', '0x00', '0x00', '0x00'],
4: ['0x08', '0x00', '0x00', '0x00'],
5: ['0x10', '0x00', '0x00', '0x00'],
6: ['0x20', '0x00', '0x00', '0x00'],
7: ['0x40', '0x00', '0x00', '0x00'],
8: ['0x80', '0x00', '0x00', '0x00'],
9: ['0x1B', '0x00', '0x00', '0x00'],
10: ['0x36', '0x00', '0x00', '0x00']
}
Matrix = [
['0x02', '0x03', '0x01', '0x01'],
['0x01', '0x02', '0x03', '0x01'],
['0x01', '0x01', '0x02', '0x03'],
['0x03', '0x01', '0x01', '0x02']
]
ReMatrix = [
['0x0e', '0x0b', '0x0d', '0x09'],
['0x09', '0x0e', '0x0b', '0x0d'],
['0x0d', '0x09', '0x0e', '0x0b'],
['0x0b', '0x0d', '0x09', '0x0e']
]
plaintext = [[], [], [], []]
plaintext1 = [[], [], [], []]
subkey = [[], [], [], []]
def __init__(self, key):#密钥扩展
self.s_box = dict(zip(["0x%02x"%i for i in range(256)], ["0x%02x"%i for i in self.sbox]))
self.ns_box = dict(zip(self.s_box.values(), self.s_box.keys()))
for i in range(4):
for j in range(0, 8, 2):
self.subkey[i].append("0x" + key[i * 8 + j:i * 8 + j + 2])
# print(self.subkey)
for i in range(4, 44):
if i % 4 != 0:
tmp = xor_32(self.subkey[i - 1], self.subkey[i - 4],0)
self.subkey.append(tmp)
else: # 4的倍数的时候执行
tmp1 = self.subkey[i - 1][1:]
tmp1.append(self.subkey[i - 1][0])
# print(tmp1)
for m in range(4):
tmp1[m] = self.s_box[tmp1[m]]
# tmp1 = self.s_box['cf']
tmp1 = xor_32(tmp1, self.Rcon[i / 4], 0)
self.subkey.append(xor_32(tmp1, self.subkey[i - 4],0))
def AddRoundKey(self, round):#轮密钥加
for i in range(4):
self.plaintext[i] = xor_32(self.plaintext[i], self.subkey[round * 4 + i],0)
# print('AddRoundKey',self.plaintext)
def PlainSubBytes(self):
for i in range(4):
for j in range(4):
self.plaintext[i][j] = self.s_box[self.plaintext[i][j]]
# print('PlainSubBytes',self.plaintext)
def RePlainSubBytes(self):
for i in range(4):
for j in range(4):
self.plaintext[i][j] = self.ns_box[self.plaintext[i][j]]
def ShiftRows(self):#行移位
p1, p2, p3, p4 = self.plaintext[0][1], self.plaintext[1][1], self.plaintext[2][1], self.plaintext[3][1]
self.plaintext[0][1] = p2
self.plaintext[1][1] = p3
self.plaintext[2][1] = p4
self.plaintext[3][1] = p1
p1, p2, p3, p4 = self.plaintext[0][2], self.plaintext[1][2], self.plaintext[2][2], self.plaintext[3][2]
self.plaintext[0][2] = p3
self.plaintext[1][2] = p4
self.plaintext[2][2] = p1
self.plaintext[3][2] = p2
p1, p2, p3, p4 = self.plaintext[0][3], self.plaintext[1][3], self.plaintext[2][3], self.plaintext[3][3]
self.plaintext[0][3] = p4
self.plaintext[1][3] = p1
self.plaintext[2][3] = p2
self.plaintext[3][3] = p3
# print('ShiftRows',self.plaintext)
def ReShiftRows(self):
p1, p2, p3, p4 = self.plaintext[0][1], self.plaintext[1][1], self.plaintext[2][1], self.plaintext[3][1]
self.plaintext[3][1] = p3
self.plaintext[2][1] = p2
self.plaintext[0][1] = p4
self.plaintext[1][1] = p1
p1, p2, p3, p4 = self.plaintext[0][2], self.plaintext[1][2], self.plaintext[2][2], self.plaintext[3][2]
self.plaintext[0][2] = p3
self.plaintext[1][2] = p4
self.plaintext[2][2] = p1
self.plaintext[3][2] = p2
p1, p2, p3, p4 = self.plaintext[0][3], self.plaintext[1][3], self.plaintext[2][3], self.plaintext[3][3]
self.plaintext[0][3] = p2
self.plaintext[1][3] = p3
self.plaintext[2][3] = p4
self.plaintext[3][3] = p1
def MixColumns(self):#列混淆
for i in range(4):
for j in range(4):
self.plaintext1[i].append(MatrixMulti(self.Matrix[j], self.plaintext[i]))
# print('MixColumns',self.plaintext1)
def ReMixColumns(self):
for i in range(4):
for j in range(4):
self.plaintext1[i].append(MatrixMulti(self.ReMatrix[j], self.plaintext[i]))
def AESEncryption(self, plaintext):
self.plaintext = [[], [], [], []]
for i in range(4):
for j in range(0, 8, 2):
self.plaintext[i].append("0x" + plaintext[i * 8 + j:i * 8 + j + 2])
self.AddRoundKey(0)
for i in range(9):
self.PlainSubBytes()
self.ShiftRows()
self.MixColumns()
self.plaintext = self.plaintext1
self.plaintext1 = [[], [], [], []]
self.AddRoundKey(i + 1)
self.PlainSubBytes()
self.ShiftRows()
self.AddRoundKey(10)
return Matrixtostr(self.plaintext)
def AESDecryption(self, cipher):
self.plaintext = [[], [], [], []]
for i in range(4):
for j in range(0, 8, 2):
self.plaintext[i].append('0x' + cipher[i * 8 + j:i * 8 + j + 2])
# print(self.ns_box)
self.AddRoundKey(10)
for i in range(9):
self.ReShiftRows()
self.RePlainSubBytes()
self.AddRoundKey(9-i)
self.ReMixColumns()
self.plaintext = self.plaintext1
self.plaintext1 = [[], [], [], []]
self.ReShiftRows()
self.RePlainSubBytes()
self.AddRoundKey(0)
return Matrixtostr(self.plaintext)
def Encryption(self, text):
group = PlaintextGroup(TextToByte(text), 32, 1)
# print(group)
cipher = ""
for i in range(len(group)):
cipher = cipher + self.AESEncryption(group[i])
return cipher
def Decryption(self, cipher):
group = PlaintextGroup(cipher, 32, 0)
# print(group)
text = ''
for i in range(len(group)):
text = text + self.AESDecryption(group[i])
text = ByteToText(text)
return text
def xor_32(start, end, key):
a = []
for i in range(0, 4):
xor_tmp = ""
b = hextobin(start[i])
c = hextobin(end[i])
d = bin(key)[2:].rjust(8,'0')
for j in range(8):
tmp = int(b[j], 10) ^ int(c[j], 10) ^ int(d[j],10)
xor_tmp += str(tmp )
a.append(bintohex(xor_tmp))
return a
def xor_8(begin, end):
xor_8_tmp = ""
for i in range(8):
xor_8_tmp += str(int(begin[i]) ^ int(end[i]))
return xor_8_tmp
def hextobin(word):
word = bin(int(word, 16))[2:]
for i in range(0, 8-len(word)):
word = '0'+word
return word
def bintohex(word):
word = hex(int(word, 2))
if len(word) == 4:
return word
elif len(word) < 4:
return word.replace('x', 'x0')
def MatrixMulti(s1, s2):
result = []
s3 = []
for i in range(4):
s3.append(hextobin(s2[i]))
for i in range(4):
result.append(MultiProcess(int(s1[i], 16), s3[i]))
for i in range(3):
result[0] = xor_8(result[0], result[i+1])
return bintohex(result[0])
def MultiProcess(a, b):
if a == 1:
return b
elif a == 2:
if b[0] == '0':
b = b[1:] + '0'
else:
b = b[1:] + '0'
b = xor_8(b, '00011011')
return b
elif a == 3:
tmp_b = b
if b[0] == '0':
b = b[1:] + '0'
else:
b = b[1:] + '0'
b = xor_8(b, '00011011')
return xor_8(b, tmp_b)
elif a == 9:
tmp_b = b
return xor_8(tmp_b, MultiProcess(2, MultiProcess(2, MultiProcess(2, b))))
elif a == 11:
tmp_b = b
return xor_8(tmp_b, xor_8(MultiProcess(2, MultiProcess(2, MultiProcess(2, b))), MultiProcess(2, b)))
elif a == 13:
tmp_b = b
return xor_8(tmp_b, xor_8(MultiProcess(2, MultiProcess(2, MultiProcess(2, b))), MultiProcess(2, MultiProcess(2, b))))
elif a == 14:
return xor_8(MultiProcess(2, b), xor_8(MultiProcess(2, MultiProcess(2, MultiProcess(2, b))), MultiProcess(2, MultiProcess(2, b))))
def Matrixtostr(matrix):
result = ""
for i in range(4):
for j in range(4):
result += matrix[i][j][2:]
return result
def PlaintextGroup(plaintext, length, flag):
group = re.findall('.{'+str(length)+'}', plaintext)
group.append(plaintext[len(group)*length:])
if group[-1] == '' and flag:
group[-1] = '16161616161616161616161616161616'
elif len(group[-1]) < length and flag:
tmp = int((length-len(group[-1])) / 2)
if tmp < 10:
for i in range(tmp):
group[-1] = group[-1] + '0'+str(tmp)
else:
for i in range(tmp):
group[-1] = group[-1] + str(tmp)
elif not flag:
del group[-1]
return group
#字符串转16进制
def TextToByte(words):
text = words.encode('utf-8').hex()
return text
def ByteToText(encode):
tmp = int(encode[-2:])
word = ''
for i in range(len(encode)-tmp*2):
word = word + encode[i]
# print(word)
word = bytes.decode(binascii.a2b_hex(word))
return word
#字节非轮异或
def xorbytes(bytes1,bytes2):
length=min(len(bytes1),len(bytes2))
output=bytearray()
for i in range(length):
output.append(bytes1[i]^bytes2[i])
return bytes(output)
res='B0CC93EAE92FEF5699396E023B4F9E42'.lower()
key = ''
for i in username:
key+=hex(ord(i))[2:].rjust(2,"0")
A1 = AES(key)
tail_pass=""
for i in range(0,len(res),32):
tail_pass+=bytes.fromhex(A1.AESDecryption(res[i:i+32])).decode()
print(tail_pass)
print(hashlib.md5(str(username+pre_pass+"_"+tail_pass).encode("utf-8")).hexdigest())
#user01_nkctf2024
#uSer1p4ss
#9ee779cd2abcde48
#2961bba0add6265ba83bc6198e0ec758
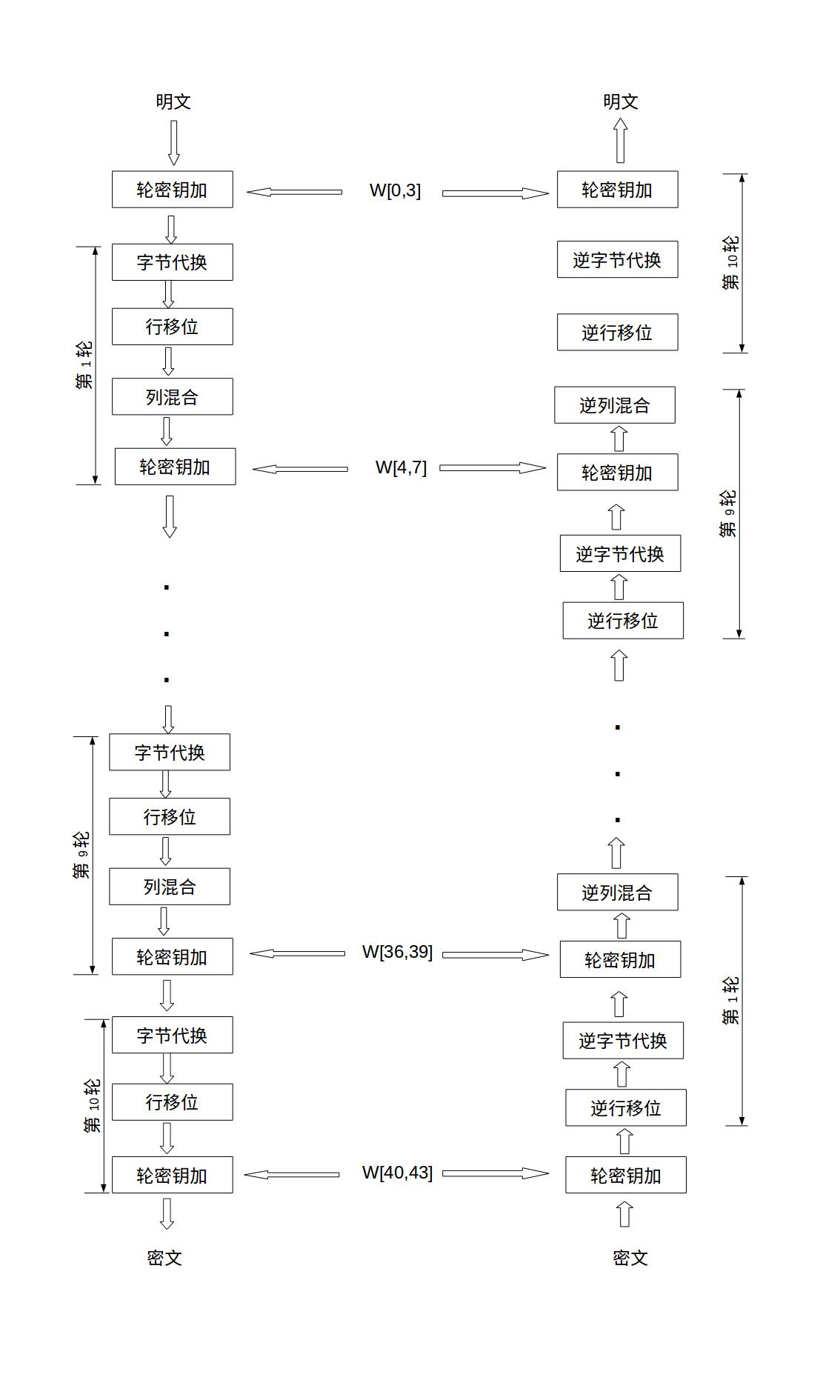
下面来学习一下标准的AES加密:
AES为分组密码,分组密码也就是把明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文。在AES标准规范中,分组长度只能是128位,也就是说,每个分组为16个字节(每个字节8位)。密钥的长度可以使用128位、192位或256位。密钥的长度不同,推荐加密轮数也不同
AES-128 密钥长度为4(32比特字) 加密轮数10
AES-192 密钥长度为6(32比特字) 加密轮数12
AES-256 密钥长度为8(32比特字) 加密轮数14
AES的加密处理单位是字节,128位输入的明文和密钥key都被分成16字节,然后放在对应矩阵里,偷一下图()
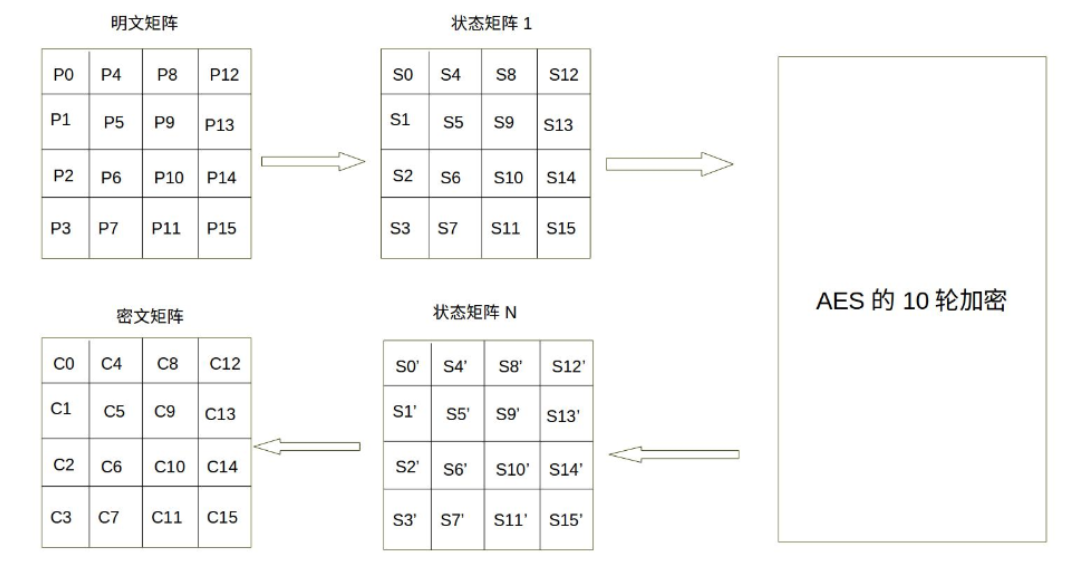
继续借用一下例子
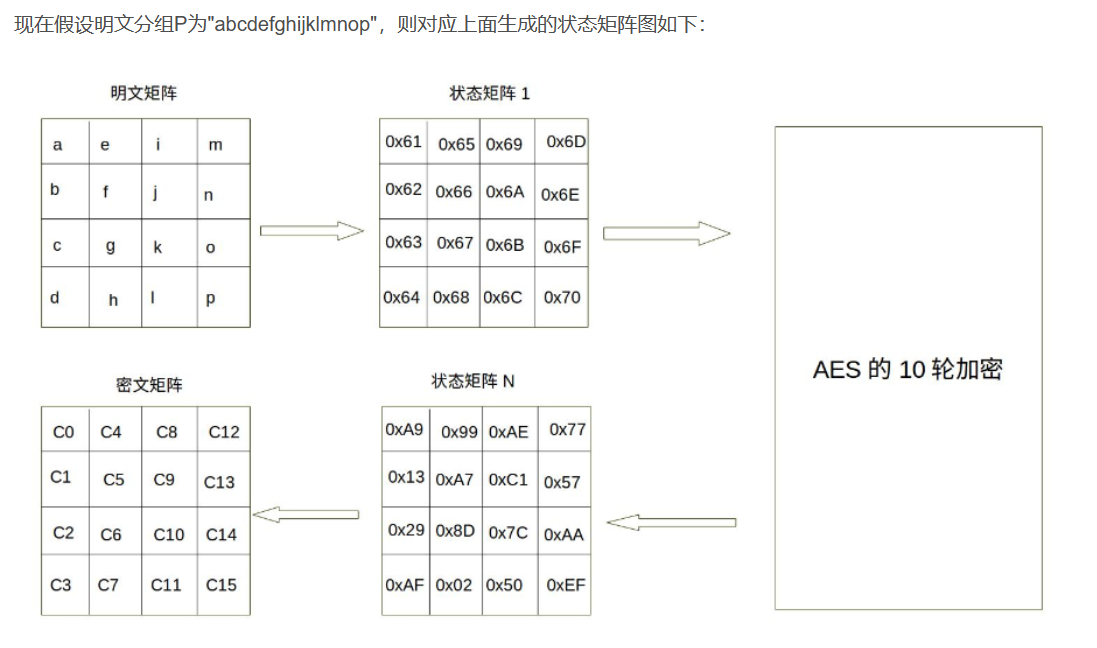
同理,密钥也是通过相同的矩阵表示,
Genshin
下载的是.beam后缀的文件,考察erlang beam文件的逆向
首先要配置好erlang的编译器Index - Erlang/OTP
配置好环境后可以通过
io:format("~p~n",[beam_disasm:file("genshin.beam")]).
获得字节码
另外可以通过
escript genshin.beam "111111"
来运行程序
这是得到的字节码,分为了main,check,transform等函数,一段一段看
{beam_file,genshin,
[{main,1,2},{module_info,0,11},{module_info,1,13}],
[{vsn,[294325075297162417208450880208266398775]}],
[{version,"8.3.1"},
{options,[]},
{source,
[47,109,110,116,47,100,47,67,84,70,47,20986,39064,47,50,48,50,51,45,
56,45,100,117,105,110,101,105,115,97,105,47,103,101,110,115,104,105,
110,46,101,114,108]}],
[{function,main,1,2,
[{label,1},
{line,1},
{func_info,{atom,genshin},{atom,main},1},
{label,2},
{test,is_nonempty_list,{f,3},[{x,0}]},
{get_list,{x,0},{x,1},{x,0}},
{test,is_nil,{f,3},[{x,0}]},
{move,{x,1},{x,0}},
{call_only,1,{genshin,check,1}},
{label,3},
{move,
{literal,"Usage: xxxxxxxx genshin.beam <input_string>~n"},
{x,0}},
{line,2},
{call_ext_only,1,{extfunc,io,format,1}}]},
{function,check,1,5,
[{line,3},
{label,4},
{func_info,{atom,genshin},{atom,check},1},
{label,5},
{test,is_list,{f,4},[{x,0}]},
{allocate,1,1},
{move,{x,0},{y,0}},
{move,{literal,[21407,31070,46,46,46,126,110]},{x,0}},
{line,4},
{call_ext,1,{extfunc,io,format,1}},
{move,{integer,1},{x,1}},
{move,nil,{x,2}},
{move,{y,0},{x,0}},
{init_yregs,{list,[{y,0}]}},
{line,5},
{call,3,{genshin,transform,3}},
{line,6},
{call_ext,1,{extfunc,erlang,list_to_binary,1}},
{test,is_eq_exact,
{f,6},
[{tr,{x,0},{t_bitstring,8,false}},
{literal,
<<107,114,102,103,130,68,118,106,107,119,88,109,131,70,
114,130,122,81,111,40,107,77,76,38,52,73,72,101>>}]},
{move,{literal,[21551,21160,65281,126,110]},{x,0}},
{line,7},
{call_ext_last,1,{extfunc,io,format,1},1},
{label,6},
{move,{literal,[20851,38381,126,110]},{x,0}},
{line,8},
{call_ext_last,1,{extfunc,io,format,1},1}]},
{function,transform,3,8,
[{line,9},
{label,7},
{func_info,{atom,genshin},{atom,transform},3},
{label,8},
{test,is_nonempty_list,{f,9},[{x,0}]},
{get_list,{x,0},{x,3},{x,0}},
{line,10},
{gc_bif,'bxor',
{f,0},
4,
[{x,3},{tr,{x,1},{t_integer,{1,'+inf'}}}],
{x,3}},
{gc_bif,'+',{f,0},4,[{tr,{x,3},{t_integer,any}},{integer,4}],{x,3}},
{line,11},
{gc_bif,'+',
{f,0},
4,
[{tr,{x,1},{t_integer,{1,'+inf'}}},{integer,1}],
{x,1}},
{test_heap,2,4},
{put_list,{x,3},{x,2},{x,2}},
{call_only,3,{genshin,transform,3}},
{label,9},
{test,is_nil,{f,7},[{x,0}]},
{move,{x,2},{x,0}},
{line,9},
{call_ext_only,1,{extfunc,lists,reverse,1}}]},
{function,module_info,0,11,
[{line,0},
{label,10},
{func_info,{atom,genshin},{atom,module_info},0},
{label,11},
{move,{atom,genshin},{x,0}},
{call_ext_only,1,{extfunc,erlang,get_module_info,1}}]},
{function,module_info,1,13,
[{line,0},
{label,12},
{func_info,{atom,genshin},{atom,module_info},1},
{label,13},
{move,{x,0},{x,1}},
{move,{atom,genshin},{x,0}},
{call_ext_only,2,{extfunc,erlang,get_module_info,2}}]}]}
然后丢给chatgpt问了一下基本的问题
当解释 {get_list, {x, 0}, {x, 1}, {x, 0}} 指令的每个参数时,以下是它们的含义:
get_list:指令的操作码,表示从列表中获取元素。{x, 0}:第一个参数,表示目标寄存器,指定要将列表的第一个元素存储在哪个寄存器中。在这里,{x, 0}表示寄存器x0。{x, 1}:第二个参数,表示源寄存器,指定要从哪个寄存器中获取列表。在这里,{x, 1}表示寄存器x1。{x, 0}:第三个参数,表示目标寄存器,指定要将列表的第一个元素存储在哪个寄存器中。在这里,再次使用{x, 0}表示寄存器x0。
因此,该指令的作用是将寄存器 x1 中的列表的第一个元素提取出来,并将其存储在寄存器 x0 中以供后续使用。
-
{func_info, {atom, genshin}, {atom, main}, 1}: 函数信息,表示函数名为genshin:main/1 -
{test, is_nil, {f, 3}, [{x, 0}]}`: 检查参数是否为空列表
{f, 3}是一个表示函数的元组,其中f表示函数,3表示该函数在字节码中的位置。在Erlang字节码中,函数由函数指令序列组成。每个函数指令都有一个唯一的位置标识符,称为函数索引。这个索引是一个非负整数,用于表示函数在字节码中的位置。在这里,
{f, 3}表示该函数指令位于函数索引为3的位置。
然后大概看一下各个函数的意思
最后得到的check大概是
flag[i] = (flag[i]^(i+1))+4
写出脚本
A=[107,114,102,103,130,68,118,106,107,119,88,109,131,70,114,130,122,81,111,40,107,77,76,38,52,73,72,101]
for j in range(len(A)):
A[j] = (A[j] -4 )^ (j+1)
flag="".join([chr(x) for x in A])
print(flag)
#flag{Funny_erLang_x0r__:)__}
欧拉!
阿里云的一道唯一能听懂的题
图论题
无向图求欧拉路径,限制条件变为了前一步的y必须和后一步的x相同,才能继续走
然后有一个限制条件

用dfs搜
map=[0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000001, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000001, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000001, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000001, 0x00000001, 0x00000001, 0x00000000, 0x00000001, 0x00000000, 0x00000001, 0x00000001, 0x00000001, 0x00000000]
import numpy as np
map=np.array(map).reshape(9, 9)
map=map.tolist()
c=[]
for i in range(9):
for j in range(9):
if map[i][j]==1:
c.append((i,j))
print(c)
def dfs(maze, start):
rows = len(maze)
cols = len(maze[0])
visited = [[False for _ in range(cols)] for _ in range(rows)] # 用于记录访问过的位置
paths = [] # 用于记录路径
def check(input):
m = input[11] > input[12] and input[13] < input[14] and input[10] == input[18] and input[21] == input[25] and \
input[20] > input[15] and input[13] < input[23] and input[17] < input[14] and input[24] == "7" and input[27] == "4"
return m
def is_valid(x, y):
# 可通过的路径(值为1)
check1 = 0 <= x < rows and 0 <= y < cols and not visited[x][y] and maze[x][y] == 1
# check2 = maze[y][x] == 0 or True
return check1
def dfs_helper(x, y, path):
visited[x][y] = True # 标记当前位置为已访问
visited[y][x] = True
if len(path) == 17:
flag = "aliyunctf{"
flag+=f"{path[0][0]}"
for tem in path:
flag+=str(tem[1])
flag+="}"
if check(flag):
print(flag)
paths.append(path.copy())
for new_x, new_y in c:
if new_x != path[-1][1]:
continue
if is_valid(new_x, new_y):
path.append((new_x, new_y))
dfs_helper(new_x, new_y, path)
path.pop()
visited[x][y] = False # 恢复当前位置的未访问状态
visited[y][x] = False
# 调用DFS辅助函数从起点开始搜索
dfs_helper(start[0], start[1],[start])
return paths
for start in c:
result = dfs(map, start)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号