
使用.NET Hardware Intrinsics API加速机器学习场景
ML.NET 0.6版本刚刚发布不久,我们知道ML.NET代码已经依赖于使用本机代码库的性能矢量化。这是一个重新实现托管代码中现有代码库的机会,使用.NET Hardware Intrinsics进行矢量化,并比较结果。
什么是矢量化,什么是SIMD,SSE和AVX?
矢量化是用于同时将相同操作应用于阵列的多个元素的名称。在x86 / x64平台上,可以通过使用单指令多数据(SIMD)CPU指令在类似阵列的对象上操作来实现矢量化。
SSE(Streaming SIMD Extensions)和AVX(Advanced Vector Extensions)是x86架构的SIMD指令集扩展的名称。SSE已经存在很长时间了:CoreCLR底层.NET Core要求x86平台至少支持SSE2指令集。AVX是SSE的扩展,现在可以广泛使用。它的关键优势在于它可以在一条指令中处理内存中8个连续的32位元素,是SSE的两倍。
.NET Core 3.0将SIMD指令公开为可直接用于托管代码的API,从而无需使用本机代码来访问它们。
基于ARM的CPU确实提供了类似的内在函数,但.NET Core尚不支持它们(尽管工作正在进行中)。因此,当AVX和SSE都不可用时,必须使用软件回退代码路径。JIT使得以非常有效的方式执行此回退成为可能。当.NET Core确实公开ARM内在函数时,代码可以利用它们,此时软件回退很少需要。
项目目标
- 通过使用软件回退创建单个托管程序集,增加ML.NET平台范围(x86,x64,ARM32,ARM64等)
- 通过在可用的情况下使用AVX指令来提高ML.NET性能
- 验证.NET硬件内在函数API 并演示性能与本机代码相当
原本可以通过简单地更新本机代码来使用AVX指令来实现第二个目标,但是同时转移到托管代码我可以消除为每个目标架构构建和发布单独二进制文件的需要 - 它通常也更容易维护托管代码。
挑战
首先要熟悉C#和.NET,然后我的工作包括:
- 用于C#中CPU数学运算的基层实现。如果你不熟悉,请参阅这篇伟大的MSDN杂志文章C# - All About Span:探索新的.NET Mainstay以及文档。
- 根据可用性,启用AVX,SSE和软件实现之间的切换。
- 正确处理托管代码中的指针,并删除某些现有代码所做的对齐假设
- 使用multitargeting允许ML.NET继续在没有.NET Hardware Intrinsics API的平台上运行。
多目标
.NET Hardware Intrinsics将在.NET Core 3.0中提供,目前正在开发中。ML.NET还需要在.NET Standard 2.0兼容平台上运行 - 例如.NET Framework 4.7.2和.NET Core 2.1。为了支持这两者,我选择使用多目标创建一个同时针对.NET Standard 2.0和.NET Core 3.0的.csproj 文件。
- 在.NET Standard 2.0上,系统将使用具有SSE硬件内在函数的原始本机实现
- 在.NET Core 3.0上,系统将使用带有AVX硬件内在函数的新托管实现。
代码之初
在原始代码中,机器学习中使用的每个培训师,学习者和转换最终都称为包装器方法,对输入数组执行CPU数学运算,例如 SseUtils
MatMulDense,它将两个密集数组的矩阵乘法解释为矩阵,和SdcaL1UpdateSparse,执行稀疏数组的随机双坐标上升的更新步骤。
这些包装器方法假定优先选择SSE指令,并在另一个类中调用相应的方法,该方法用作托管代码和本机代码之间的接口,并包含直接调用其本机等效项的方法。文件中的这些本机方法依次使用包含SSE硬件内在函数的循环实现CPU数学运算。
打破托管代码路径
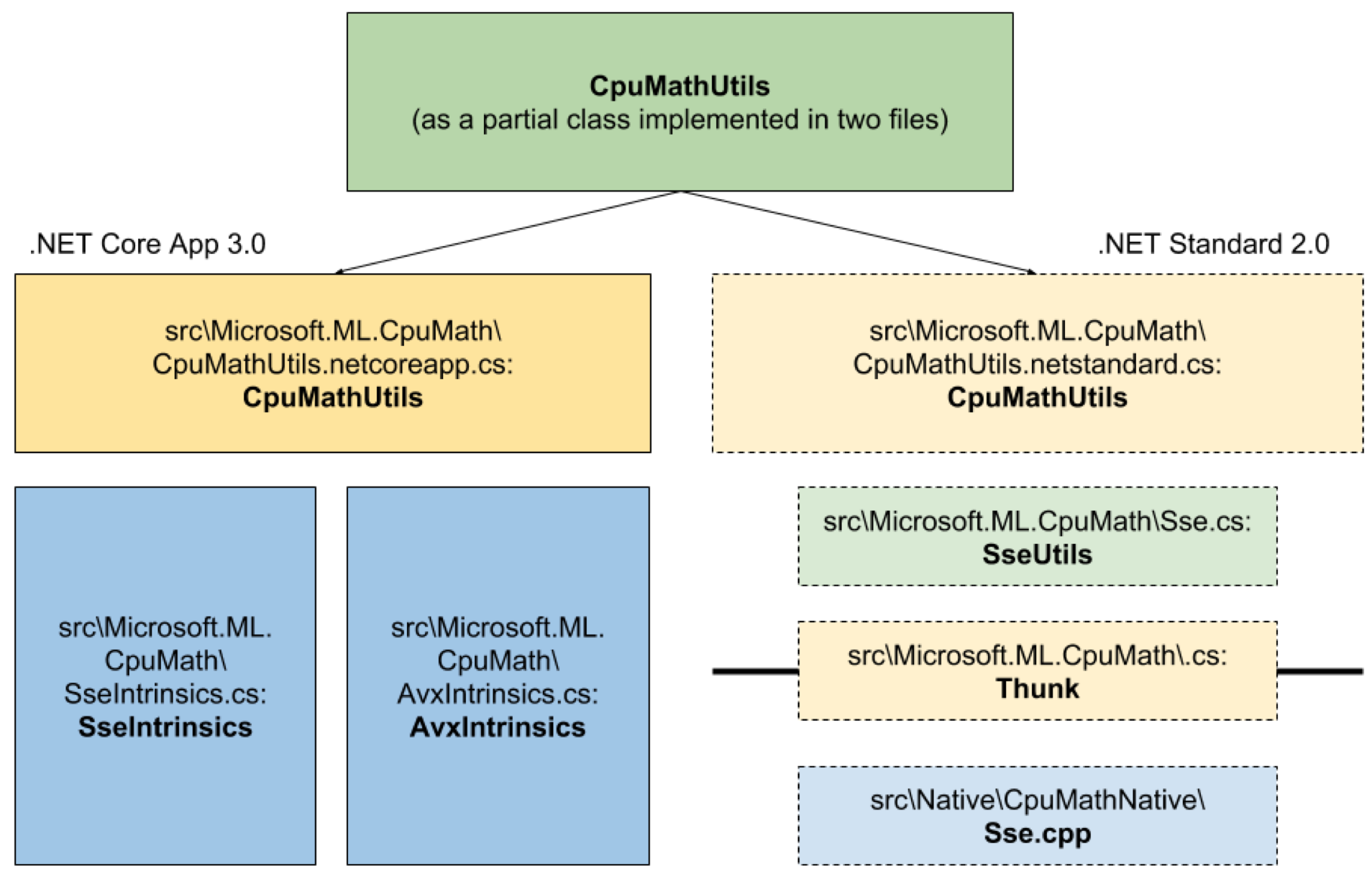
对于这段代码,我为在.NET Core 3.0上变为活动的CPU数学运算添加了一个新的独立代码路径,并保持原始代码路径在.NET Standard 2.0上运行。以前所有方法的调用站点现在都称为相同名称的方法,保持CPU数学运算的API签名相同。 SseUtils CpuMathUtils
CpuMathUtils 是一个新的分部类,它包含表示CPU数学运算的每个公共API的两个定义,其中一个仅在.NET Standard 2.0上编译,而另一个仅在.NET Core 3.0上编译。此条件编译功能为方法创建两个独立的代码路径。在.NET Standard 2.0上编译的那些函数定义直接调用它们的对应物,它们基本上遵循原始的本机代码路径。
用software fallback编写代码
另一方面,在.NET Core 3.0上编译的其他函数定义根据运行时的可用性切换到同一CPU数学运算的三个实现之一:
- 一个用包含AVX硬件内在函数的循环实现操作的方法,
AvxIntrinsics - 一个用包含SSE硬件内在函数的循环实现操作的方法
SseIntrinsics - 软件后备,以防AVX和SSE都不受支持。
每当代码使用.NET硬件内在函数时,您通常会看到此模式 - 例如,这是向向量添加标量的代码:
如果支持AVX,则首选,否则使用SSE(如果可用),否则使用软件回退路径。在运行时,JIT实际上只为这三个块中的一个生成代码,适用于它自己发现的平台。
为了给你一个想法,这里的AVX实现看起来像上面的方法调用:
您将注意到它使用AVX以8为一组进行操作,然后使用SSE对任何4组进行操作,最后为任何剩余的进行软件循环。
由于托管代码中的和方法直接实现类似于最初在文件中的本机方法的CPU数学运算,因此代码更改不仅消除了本机依赖性,还简化了公共API和基础层硬件内在函数之间的抽象级别。
在进行此替换后,我能够使用ML.NET执行任务,例如具有随机双坐标上升的列车模型,进行超参数调整,以及在Raspberry Pi上执行交叉验证,此时ML.NET需要x86 CPU。
这就是现在架构的样子(图1):
性能改进
那么这对性能有何不同?
我使用Benchmark.NET编写测试来收集测量数据。
首先,我禁用了AVX代码路径,以便在使用相同的SSE指令时公平地比较本机和托管实现。如图2所示,性能具有可比性:在测试运行的大型向量上,托管代码添加的开销并不显着。
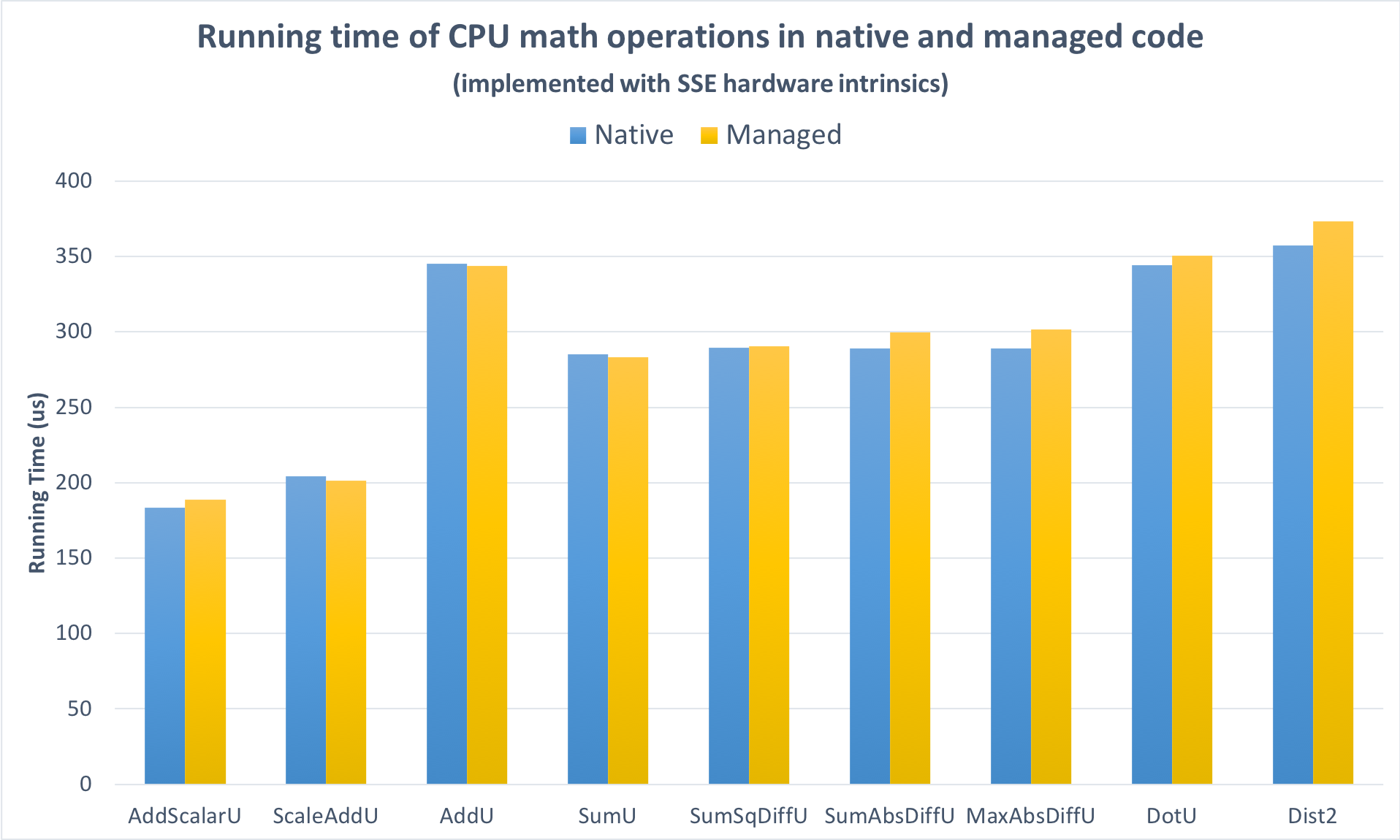
图2
其次,我启用了AVX支持。图3显示微基准测试的平均性能增益比单独的SSE高约20%。
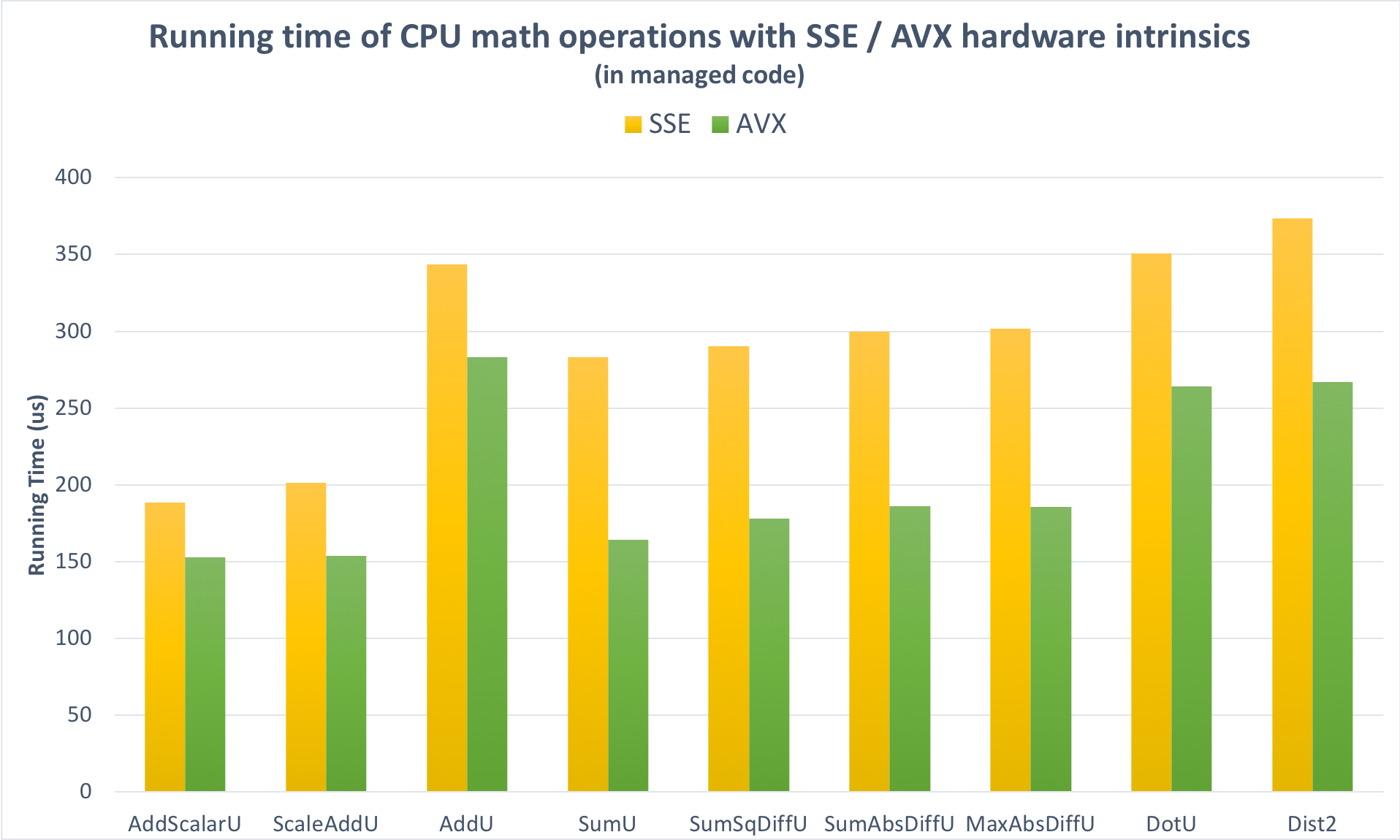
图3
将两者结合起来 - 从本机代码中的SSE实现升级到托管代码中的AVX实现 - 我测量了微基准测试的18%的改进。有些操作的速度提高了42%,而其他一些涉及稀疏输入的操作则有进一步优化的潜力。
最重要的当然是真实场景的表现。在.NET Core 3.0上,K-means聚类和逻辑回归的训练模型加快了约14%(图4)。

图4
我希望这已经证明了.NET硬件内在函数的强大功能,并且我鼓励您在.NET Core 3.0预览可用时考虑在自己的项目中使用它们的机会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号