

使用ML.NET实现白葡萄酒品质预测
导读:ML.NET系列文章
本文将基于ML.NET v0.2预览版,介绍机器学习中的分类和回归两个重要概念,并实现白葡萄酒品质预测。
本系列前面的文章也提到了一些,经典的机器学习最主要的特点就是模拟,具体来说就是定义出一个y=f(x)函数,x就是我们定义的特征值(它可能是一个/组标量,也可能是一个/组向量),y就是目标值,这个函数的目标是要无限满足所有(x, y)都出现在函数y=f(x)在坐标轴上经过的地方,这有时候也叫函数逼近。试想,只要这个函数是模拟出了对某类问题的输入和输出值(x, y)的运算过程,那再来一个新的输入值x,是不是就可以求解出输出值y是什么了!基于这个道理,机器学习才有了预知未来的能力。那么,对未来的预知最常见的两种情况:一个是为了分类,一个是为了回归。“分类”的概念容易理解,它要解决的目标值是标签类的数据,比如属于什么物种,是否是垃圾邮件,什么类型的电影之类的问题,而“回归”的概念需要一点想像力,它要解决的目标值是纯粹的实数的数据,比如下一场考试得多少分,今年世界杯冠军是进几个球获胜,那个小伙能吸引到周边妹子的魅力值有多高等等。是不是一下子觉得很神奇,兴致就来了?!
再容我多说几句,分类预测与回归预测,同样是建模,解决的问题“可以是”不一样的(注意这个——可以是),简单地来看,分类要预测一个离散的标签,多个标签互相之间没有关系,目的是要选其中最恰当的一个;而回归是预测一个连续变化的数,且必须是在一定范围内有延续关系的数,预测的结果值是变化过程中的其中一个。分类和回归其实也能说有一些相同的地方,分类算法也是有预测到一个连续的值,但是这些连续值对应的是一个类别在概率上不同的面而已;而回归算法照样可以预测离散值,但是以整数形式预测离散值的,本质上是把类别下的每一个子类都按字典形式找一个数值对应上罢了。于是,得出一个奇妙的结论,分类和回归问题能够以合适的手段进行转换。这个结论的作用,就是说当以分类或回归之一进行机器学习找不到合适的算法训练出模型时,不妨尝试转换到另一个方向去寻求突破。

好了,胡诌了一些晕乎乎的理论后,本文继续使用ML.NET带来一个回归模型的案例,根据白葡萄酒的各项酿制成分参数来预测其品质好坏。这次的数据集取自著名的竞赛网站——Kaggle.com的其中一个考题UCI Wine Quality Dataset,数据内容类似如下:
fixed.acidity,volatile.acidity,citric.acid,residual.sugar,chlorides,free.sulfur.dioxide,total.sulfur.dioxide,density,pH,sulphates,alcohol,quality,id 6.5,0.28,0.35,15.4,0.042,55,195,0.9978,3.23,0.5,9.6,6,3900 7.3,0.19,0.49,15.55,0.058,50,134,0.9998,3.42,0.36,9.1,7,3901 6.4,0.16,0.32,8.75,0.038,38,118,0.99449,3.19,0.41,10.7,5,3902 7.4,0.19,0.3,12.8,0.053,48.5,229,0.9986,3.14,0.49,9.1,7,3903 ...
各个字段说明是这样:
成分 1 - fixed acidity 非挥发性酸 2 - volatile acidity 挥发性酸度 3 - citric acid 柠檬酸 4 - residual sugar 剩余糖分 5 - chlorides 氯化物 6 - free sulfur dioxide 游离二氧化 7 - total sulfur dioxide 总二氧化硫 8 - density 密度 9 - pH 酸碱度 10 - sulphates 硫酸盐 11 - alcohol 酒精 输出标签 (品酒师的感受值): 12 - 品质(分值0-10) 其它: 13 - id (样本序号)
首先创建训练和预测用的数据结构:
public class WineData { [Column(ordinal: "0")] public float FixedAcidity; [Column(ordinal: "1")] public float VolatileAcidity; [Column(ordinal: "2")] public float CitricACID; [Column(ordinal: "3")] public float ResidualSugar; [Column(ordinal: "4")] public float Chlorides; [Column(ordinal: "5")] public float FreeSulfurDioxide; [Column(ordinal: "6")] public float TotalSulfurDioxide; [Column(ordinal: "7")] public float Density; [Column(ordinal: "8")] public float PH; [Column(ordinal: "9")] public float Sulphates; [Column(ordinal: "10")] public float Alcohol; [Column(ordinal: "11", name: "Label")] public float Quality; [Column(ordinal: "12")] public float Id; } public class WinePrediction { [ColumnName("Score")] public float PredictionQuality; }
训练部分,这次使用了一个对象叫ColumnDropper,可以用来在训练开始前舍弃掉不需要的字段,比如id,对结果没有任何影响,因此可以去掉。
static PredictionModel<WineData, WinePrediction> Train() { var pipeline = new LearningPipeline(); pipeline.Add(new Microsoft.ML.Data.TextLoader(DataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false)); pipeline.Add(new ColumnDropper() { Column = new[] { "Id" } }); pipeline.Add(new ColumnConcatenator("Features", "FixedAcidity", "VolatileAcidity", "CitricACID", "ResidualSugar", "Chlorides", "FreeSulfurDioxide", "TotalSulfurDioxide", "Density", "PH", "Sulphates", "Alcohol")); pipeline.Add(new FastTreeRegressor()); var model = pipeline.Train<WineData, WinePrediction>(); return model; }
评估部分,要注意三个值 ,Rmsj是均方根值,用来展示有效度的,LossFn是损失值,顾名思义损失的程度嘛,当然越低越好了,RSquared是误差值,用来反映拟合度好坏的,如果接近0甚至负数,说明训练出来的模型已瞎,还不如人眼了。
static void Evaluate(PredictionModel<WineData, WinePrediction> model) { var testData = new Microsoft.ML.Data.TextLoader(TestDataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false); var evaluator = new Microsoft.ML.Models.RegressionEvaluator(); var metrics = evaluator.Evaluate(model, testData); Console.WriteLine("Rms=" + metrics.Rms); Console.WriteLine("LossFn=" + metrics.LossFn); Console.WriteLine("RSquared = " + metrics.RSquared); }
预测部分,如上一篇那样,通过新版本的TextLoader进行加载,并且处理成集合。
static void Predict(PredictionModel<WineData, WinePrediction> model) { using (var environment = new TlcEnvironment()) { var textLoader = new Microsoft.ML.Data.TextLoader(TestDataPath).CreateFrom<WineData>(useHeader: true, separator: ',', trimWhitespace: false); var experiment = environment.CreateExperiment(); var output = textLoader.ApplyStep(null, experiment) as ILearningPipelineDataStep; experiment.Compile(); textLoader.SetInput(environment, experiment); experiment.Run(); var data = experiment.GetOutput(output.Data); var wineDatas = new List<WineData>(); using (var cursor = data.GetRowCursor((a => true))) { var getters = new ValueGetter<float>[]{ cursor.GetGetter<float>(0), cursor.GetGetter<float>(1), cursor.GetGetter<float>(2), cursor.GetGetter<float>(3), cursor.GetGetter<float>(4), cursor.GetGetter<float>(5), cursor.GetGetter<float>(6), cursor.GetGetter<float>(7), cursor.GetGetter<float>(8), cursor.GetGetter<float>(9), cursor.GetGetter<float>(10), cursor.GetGetter<float>(11), cursor.GetGetter<float>(12) }; while (cursor.MoveNext()) { float value0 = 0; float value1 = 0; float value2 = 0; float value3 = 0; float value4 = 0; float value5 = 0; float value6 = 0; float value7 = 0; float value8 = 0; float value9 = 0; float value10 = 0; float value11 = 0; float value12 = 0; getters[0](ref value0); getters[1](ref value1); getters[2](ref value2); getters[3](ref value3); getters[4](ref value4); getters[5](ref value5); getters[6](ref value6); getters[7](ref value7); getters[8](ref value8); getters[9](ref value9); getters[10](ref value10); getters[11](ref value11); getters[12](ref value12); var wdata = new WineData() { FixedAcidity = value0, VolatileAcidity = value1, CitricACID = value2, ResidualSugar = value3, Chlorides = value4, FreeSulfurDioxide = value5, TotalSulfurDioxide = value6, Density = value7, PH = value8, Sulphates = value9, Alcohol = value10, Quality = value11, Id = value12, }; wineDatas.Add(wdata); } } var predictions = model.Predict(wineDatas); var wineDataAndPredictions = wineDatas.Zip(predictions, (wineData, prediction) => (wineData, prediction)); Console.WriteLine($"Wine Id: {wineDataAndPredictions.Last().wineData.Id}, Quality: {wineDataAndPredictions.Last().wineData.Quality} | Prediction: { wineDataAndPredictions.Last().prediction.PredictionQuality}"); Console.WriteLine(); } }
最后调用Main函数部分。
static void Main(string[] args) { var model = Train(); Evaluate(model); Predict(model); }
好了,运行起来结果如下:
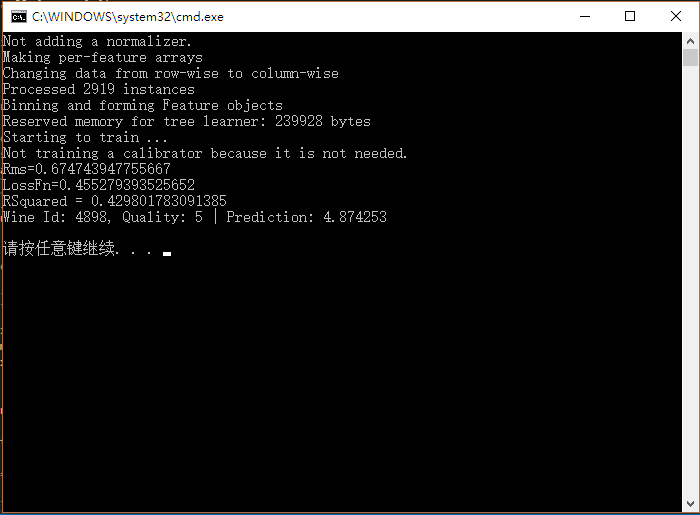
怎么样,没喝过酒咱也能当一把品酒师,专业程度照样不会差!
本案例代码和数据:下载
更多案例值得期待!
不少新入门的伙伴来问,有没有给力的学习课程,想早一点跨入机器学习的门槛,我在《机器学习课程不完全收录(持续更新)》收集了一些,都是容易学起来的课程,理论与实践都有,不论怎么说比我讲的要高出不知多少个档次了,可以按自己的喜好选择。

