

ML.NET 推荐引擎中一类矩阵因子分解的缺陷
ML.NET 作为 .NET 跨平台的机器学习套件,在回归、预测、分类甚至是图像识别、异常检测都展现出简洁快速的优势,以往的文章已介绍过不再赘述。其实机器学习场景中还有一类非常常见的,就是推荐,特别是在线购物、文娱产品为了提升用户体验,一个比较好的主意就是让用户优先看到他需要的物品、内容,甚至提供用户意料之外又情理之中的产商品。推荐算法正好能够通过数据实现这一目标。
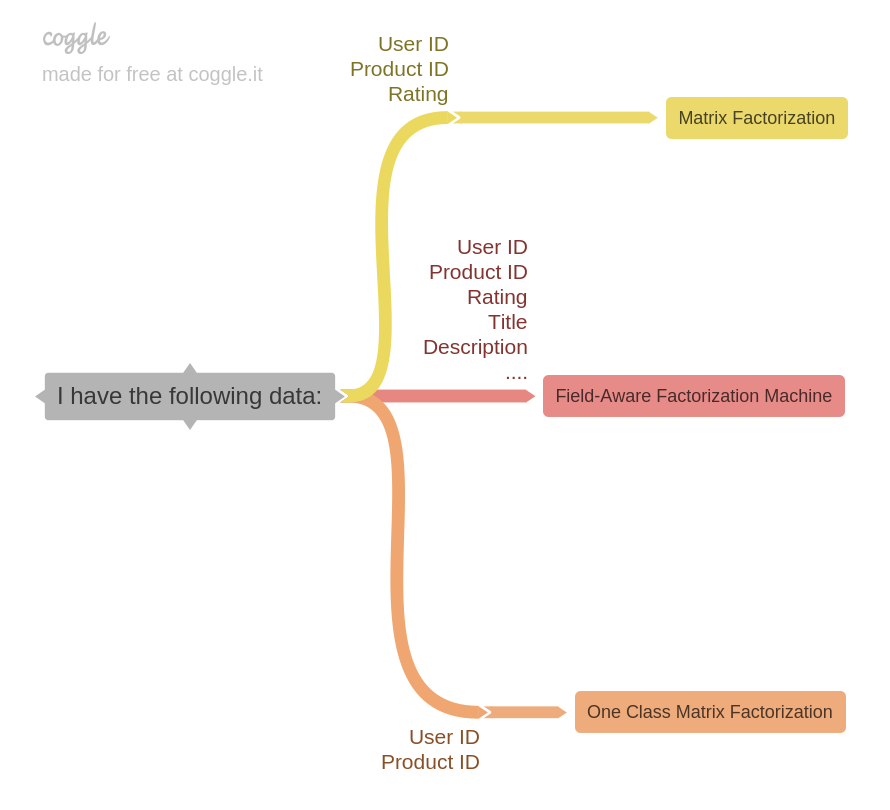
如上图所示,如果我们有用户、商品的购买关系,并且还有用户的评级、评分、评价内容,那么矩阵因子分解算法非常适用。如果我们还能获取到商品本身的一些属性,比如名称、分类、简介、价格的话,那么场感知分解机算法就能发挥特别好的作用。当然,推荐算法比较难的就是冷启动阶段,可能什么数据都没有,初始阶段没有更多选择,那么也只能从相似用户消费记录入手做推荐了,获取用户与购买商品编号的对应关系也算是容易的,此时用得比较多的是一类矩阵因子分解算法。仍然举一个例子,刚刚营业的某书店,基于借阅书的记录,我们给借了《三国志》的读者小强推荐同样借过这本书的小王借看的其他书,可能不一定是名著,不过没关系,这足够达到推荐的效果,因为算法背后的逻辑是相信他们总有其他书是都喜欢看的。
了解到前面的背景知识后,回头我们再看看 ML.NET 的推荐引擎,它同时支持矩阵因子分解和场感知分解算法,官网文档在《教程:使用矩阵因子分解和 ML.NET 生成影片推荐系统》有过详细的介绍。Sergey Tihon 在 ML.NET 的 Github 仓库中提过一个 Issue,详见《"Label" for One-Class Matrix Factorization #873》,其中谈到了 ML.NET 推荐引擎中一类矩阵因子分解算法存在一处缺陷。具体来看 MatrixFactorizationTrainer 类的详情,针对一类矩阵因子分解,在梯度下降时默认观测值都是表示正向的1,而平方误差函数调用的是MatrixFactorization将按枚举值传递给损失函数。参看《Matrix Factorization and Factorization Machines for Recommender Systems》,注意到以下这一页,预测标签始终为1。

所以如果数据集没有更多的特征可用,我们必须指定矩阵因子工厂并提供对应的参数值1而不是按默认的枚举值生成 Trainer。修复后的示例参见:《Fix Label column meaning in Recommendation sample》。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号