

ML.NET 十一月更新
ML.NET是一个开源的跨平台机器学习框架,适合 .NET 开发人员。它允许将机器学习集成到 .NET 应用中,而无需离开 .NET 生态系统,甚至拥有 ML 或数据科学背景。ML.NET工具(Visual Studio 中的 UI 模型生成器和跨平台 ML.NET CLI),可根据您的场景和数据自动训练自定义机器学习模型。
此版本ML.NET生成器带来了许多错误修复和增强功能以及新功能,包括高级数据加载选项和来自 SQL Server的流训练数据。
高级数据加载选项
以前,模型生成器不提供任何数据加载选项,它依赖于 AutoML 来检测列、标头和分隔符以及十进制分隔符样式。
让我们看一下模型生成器中使用出租车费数据集中新的高级数据加载选项。这是一个回归问题,您可以根据旅行距离、付款类型和乘客人数等几个因素预测出租车票价金额。
在模型生成器中,选择值预测方案和本地训练环境后,您将最终进入"数据"步骤。选择"文件"作为数据源类型,浏览出租车票价数据集,选择数据集后,将"列"更改为"预测" fare_amount。
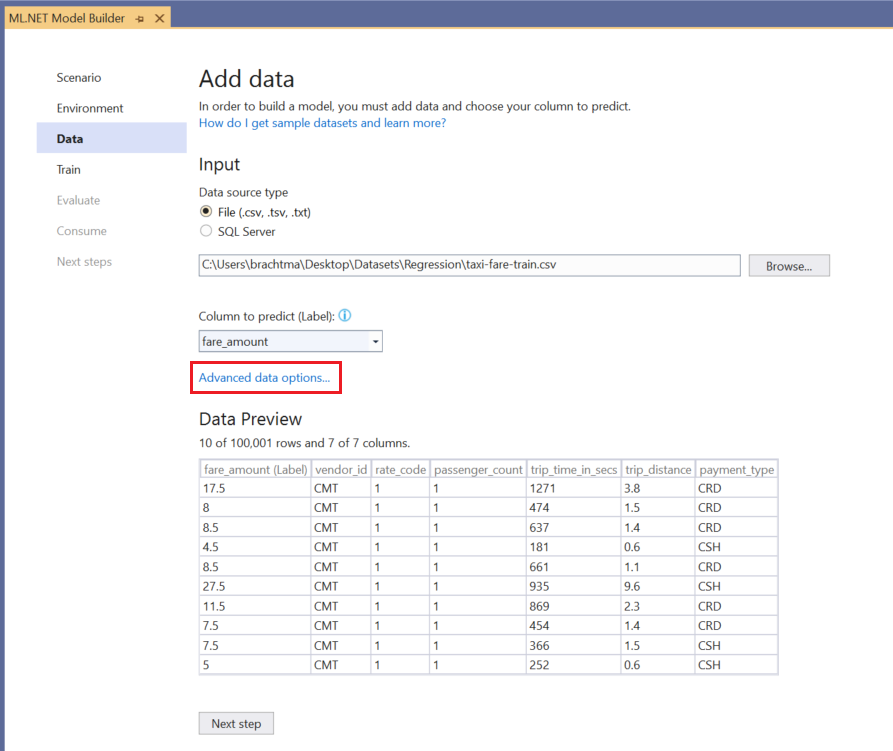
选择"高级数据"选项以打开高级数据加载选项对话框。
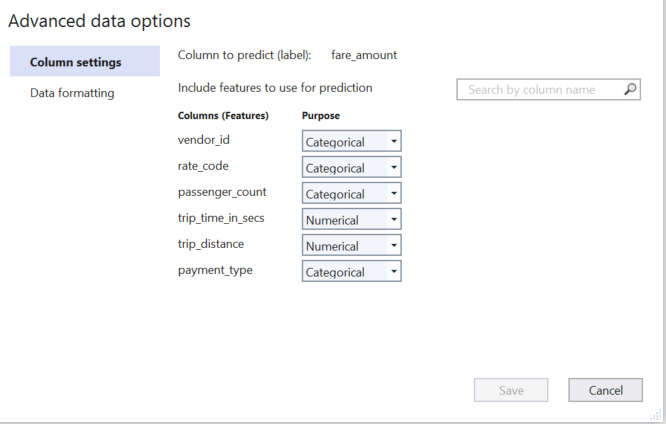
在此对话框中,有两个部分 -列设置和数据格式。
列设置
在"列设置"部分中,您可以将每个要素列(用于预测标签的列)的列更改为分类、文本、数字或忽略:
- 分类列包含在标记组离散数量中的数据。例如,付款类型可以是 CSH(现金)或 CRD(卡)分类。
- 文本列包含自由格式文本形式的字符串。例如,如果您有一个模型,该模型预测出租车乘客留下的关于其乘坐的评论是正面的还是负面的,则包含自由格式注释的列将具有 Text 的列目的。
- 数字列仅包含数字(浮点或整数)。在出租车票价示例中,行程距离和行程时间都是数字列。
- 您可以忽略不想用于训练的列。
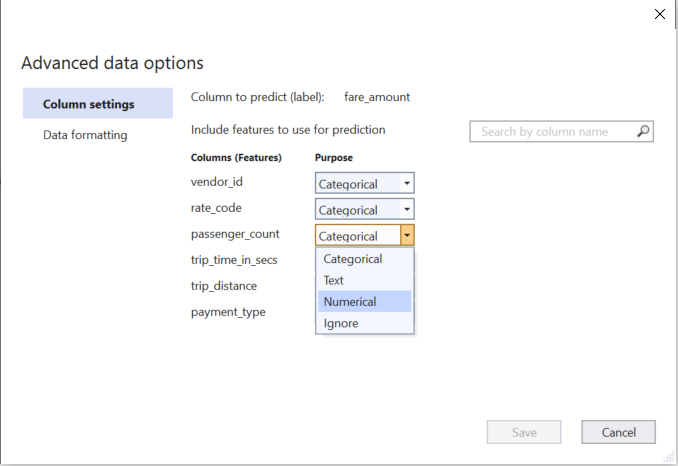
通常,模型生成器会确定合适的列能正常执行,但在某些情况下,它可能会推断错误或可能选择一个列,使模型性能稍微差一些。例如,在出租车票价示例中,模型生成器为"passenger_count"选择分类,可能默认就是数字列。
您可以使用模型生成器选择的默认设置尝试训练,然后尝试将 passenger_count 的列更改为数字,以查看它如何影响模型的性能。
数据格式
在"数据格式"部分中,您可以覆盖模型生成器选择的以下数据加载选项:
- 数据集是否具有列标题
- 列分隔符(逗号、分号或制表符)
- 十进制分隔符(十进制点或逗号)
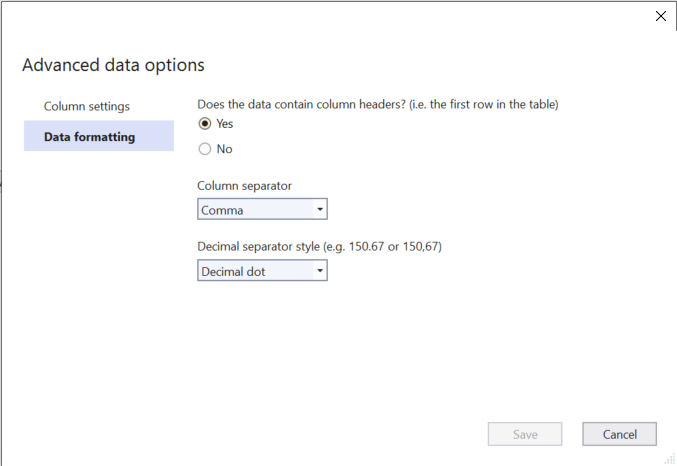
保存数据格式选项后,可以在"数据预览"中看到它如何影响数据集。
使用数据库加载程序从 SQL Server流式传输
模型生成器现在利用数据库加载器!
以前,如果您的训练数据存储在 SQL Server 中,模型生成器将在本地下载数据,然后进行训练。现在,模型生成器将直接从 SQL Server 加载和训练数据,而无需加载内存中的所有数据,因此它可以处理大小高达 TB 的巨大数据集。
入门和资源
如果您遇到任何问题,请通过在 GitHub 中创建问题(或使用模型生成器中的新反馈按钮)提交!
开始学习 ML.NET,详细了解有关 Microsoft 文档中ML.NET模型生成器。

