
通过 ML.NET 使用预训练残差网络 ResNet 模型实现手势识别
之前我写过的一篇《基于 ONNX 在 ML.NET 中使用 Pytorch 训练的垃圾分类模型》,介绍到了 ML.NET 是如何实现图像分类的,此后我收到好多留言提出了更多的场景,比如某个在线学习应用,希望学生按照视频的要求做一个指定的动作,完成形体训练,又比如某个内部调度系统,希望通过某种肢体动作执行特定的命令,例如比个“OK”确认Job触发,又或者是想实现一个猜拳的人机游戏等等。不难发现这些场景相似性很高,从技术上我们可以分解为几个过程,首先是通过opencv一类的工具捕获图像,然后通过与目标图像的比对得到是否一致的分析结果,最后根据这个分析结果对场景的实际意义进行反馈,机器学习模型能够解决第二个过程的需求。本文就摘取跟手势有关的场景,介绍如何通过 ML.NET 使用预训练残差网络 ResNet 模型实现手势识别。
为了展现 ML.NET 在普通机器上的 GPU 训练能力,我准备的软、硬件环境如下:
- Windows 10
- cuDNN 7.6 以及 CUDA10
- CPU Intel(R) Core(TM) i7-6700HQ
- GPU NVIDIA GeForce 940MX
准备阶段
从https://aka.ms/mlnet-resources/meta/resnet_v2_101_299.meta下载 ResNet 模型文件,然后放置到 C:\Users\<Your Name>\AppData\Local\Temp\MLNET 下,否则项目运行时会出现如下图的异常。

从https://cloud.tsinghua.edu.cn/f/787490e187714336aae2/?dl=1下载训练数据集,里面是分类好的 0-5 的手势图片。
创建项目
使用 Visual Studio 2017/2019 创建一个 .NET Core 控制台应用项目,创建 assets 和 workspace 目录,将数据集文件 hand_dataset.tar 解压到 assets 目录中。
添加如下 Nuget 包的引用:
- Microsoft.ML
- Microsoft.ML.ImageAnalytics
- Microsoft.ML.Vision
- SciSharp.TensorFlow.Redist-Windows-GPU
代码部分
在预处理数据阶段,使用了 mlContext.Data.ShuffleRows 混淆了顺序,参数 shufflePoolSize 的大小由数据集的大小决定,过小的值会导致管道的异步线程抛异常,本例中训练集有4500多张图片,所以我定义的值为5000。
在创建 ImageClassificationTrainer.Options 对象时,BatchSize 和 Epoch 也要根据 GPU 的处理能力,以及前一次模型正确率调整,过高的值使得训练过程加长且模型高度拟合,对未知数据的适应性会差。
完整的代码如下。
using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision; namespace Gesture { class Program { static void Main(string[] args) { var projectDirectory = AppContext.BaseDirectory; var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets"); MLContext mlContext = new MLContext(); /** * Train and Validate Data **/ IEnumerable<ImageData> images = LoadImagesFromFile(path: assetsRelativePath, category: "images/train.txt"); IDataView imageData = mlContext.Data.LoadFromEnumerable(images); IDataView shuffledData = mlContext.Data.ShuffleRows(imageData, seed: 123, shufflePoolSize: 5000); /** * Test Data **/ IEnumerable<ImageData> testImages = LoadImagesFromFile(path: assetsRelativePath, category: "images/test.txt"); IDataView testImageData = mlContext.Data.LoadFromEnumerable(testImages); var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes(outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath")); IDataView preProcessedData = preprocessingPipeline.Fit(shuffledData) .Transform(shuffledData); TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = trainSplit.TestSet; IDataView testSet = preprocessingPipeline.Fit(testImageData) .Transform(testImageData); var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true, WorkspacePath = workspaceRelativePath, BatchSize = 10, Epoch = 2000 }; var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel")); ITransformer trainedModel = trainingPipeline.Fit(trainSet); ClassifySingleImage(mlContext, testSet, trainedModel); ClassifyImages(mlContext, testSet, trainedModel); } public static IEnumerable<ImageData> LoadImagesFromFile(string path, string category = "images/train.txt") { var fullPath = Path.Combine(path, category); return File.ReadAllLines(fullPath) .Select(line => line.Split(' ')) .Select(line => new ImageData() { ImagePath = Path.Combine(path, line[0]), Label = line[1] }); }private static void OutputPrediction(ModelOutput prediction) { string imageName = Path.GetFileName(prediction.ImagePath); Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}"); } public static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); } public static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } } } class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } } class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } } class ImageData { public string ImagePath { get; set; } public string Label { get; set; } } }
运行结果
加载显卡启用CUDA的过程如下。

训练数据的过程如下。
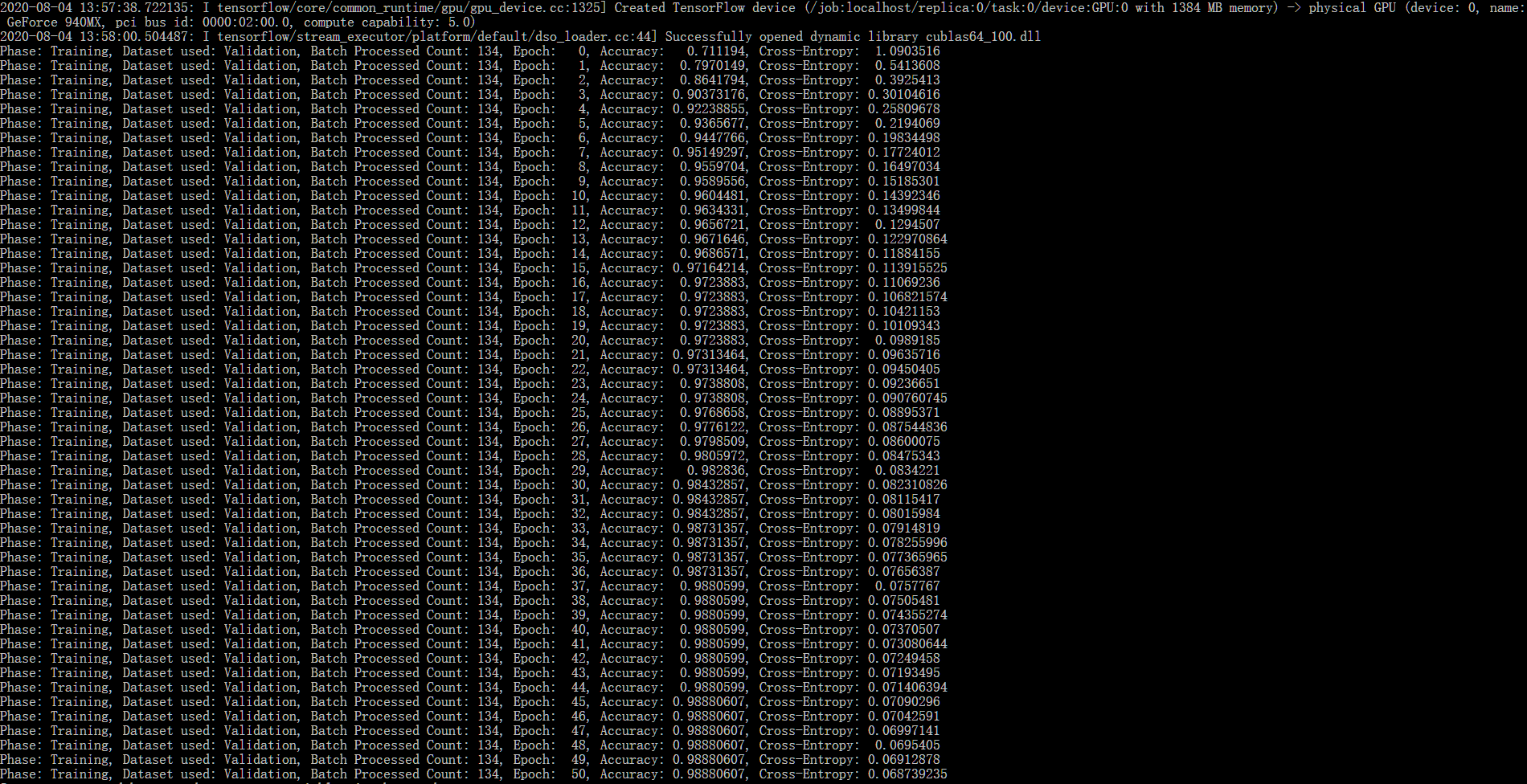
单个预测和批量预测的过程如下。
从结果上看,无论单个预测还是批量预测,正确率都得到了很好的保证,当然也要注意适当地调整超参,防止模型过拟合。好消息是,手势的预测模型训练好了,可以放心地集成到其他应用中使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号