

在 Blazor WebAssembly 静态网站中部署ML.NET机器学习模型
介绍
目前世面上有许多方法来部署机器学习模型。最常见的方法是通过 API 或 serverless functions 将模型公开为 Web 服务。将模型部署为 Web 服务时,其中一个注意事项是延迟和性能。使用模型基于 HTTP 进行预测的过程包括接受用户输入、从文件中加载模型的序列化版本、使用模型进行预测以及将预测返回给用户。由于模型通常只是静态文件,因此部署模型的另一种方法是作为 Web 上的静态资产,就像任何其他 HTML、CSS 或 JavaScript 文件一样。此部署方法与 TensorFlow.js 类似。以这种方式进行部署有几个优点。一是不再有 Web 服务只是为了为模型提供服务,从而使其更具成本效益。另一个是一旦模型下载到用户的 PC 上,此时使用的资源是用户 PC 的资源,而不是模型本来会托管的服务器。最后,由于模型是静态文件,因此可以通过 CDN 进行分发。
其中一个挑战是机器学习模型通常使用 JavaScript 以外的语言构建。这使得使用相同的代码/库构建模型变得困难或几乎不可能。WebAssembly 允许 Rust、C++、C# 和其他语言在浏览器中本机运行,从而改变了这一点。有了这种能力,加载模型和进行预测的代码/逻辑就更容易,几乎与本机平台的代码/逻辑相当。Blazor WebAssembly 为用户提供了在 C# 中完全创建基于组件的现代 Web 应用程序的能力。此外,Blazor WebAssembly 还允许用户以简单且经济高效的方式发布和部署其应用程序作为静态网站。ML.NET是一个开源的跨平台框架,允许开发人员使用 .NET 创建机器学习模型。在这篇文章中,我将演示如何训练一个多分类机器学习模型,预测鸢尾花种类。然后,我将采用该模型并将其与 Blazor WebAssembly 静态网站一起部署到 Azure 。此应用程序的完整代码可以在GitHub 上的 MLNETBlazorWASMSample 存储库中找到。
先决条件
这个项目是在Windows PC上构建的,但应该在Mac或Linux上执行以体现跨平台特性。
设置解决方案
本文中构建的解决方案包含三个项目:
- SchemaLibrary:C# .NET 标准 2.0 类库,其中包含用于训练模型的数据的架构定义类以及模型生成的预测输出。
- TrainingConsole:用于训练机器学习模型的 C# .NET Core 3.1 控制台应用程序。
- BlazorWebApp:Blazor WebAssembly Web 应用程序,使用由TrainingConsole应用程序训练的机器学习模型进行预测。
安装Blazor WebAssembly模板
使用 .NET CLI 在命令提示符中运行以下命令:
dotnet new -i Microsoft.AspNetCore.Blazor.Templates::3.2.0-preview1.20073.1
创建解决方案
给命名MLNETBlazorWASMSample的解决方案创建新目录。
mkdir MLNETBlazorWASMSample
导航到新创建的解决方案目录并创建解决方案:
cd MLNETBlazorWASMSample
dotnet new sln
创建schema类库
模型输入和输出的数据架构在训练期间和进行预测时共享。要共享资源,请创建ConsoleTraining 和 BlazorWebApp 项目共享的类库。在解决方案目录中,输入以下命令:
dotnet new classlib -o SchemaLibrary
安装Microsoft.ML NuGet 包(此解决方案是使用版本 1.4.0 构建的)。整个解决方案都使用Microsoft.ML包。
dotnet add SchemaLibrary package Microsoft.ML
将库项目添加到解决方案。
dotnet sln add SchemaLibrary
创建训练控制台应用程序
控制台应用程序包含用于训练模型的一系列数据转换和算法。在解决方案目录中,创建新的控制台应用程序。
dotnet new console -o TrainingConsole
将控制台应用程序添加到解决方案。
dotnet sln add TrainingConsole
引用 SchemaLibrary 项目。
dotnet add TrainingConsole reference SchemaLibrary
创建 Blazor WebAssembly Web 应用程序
Web 应用程序包含一些输入元素,因此用户可以提供模型随后用于进行预测的新数据。在解决方案目录中,创建新的 Blazor WebAssembly 应用程序。
dotnet new blazorwasm -o BlazorWebApp
将 Web 应用程序项目添加到解决方案。
dotnet sln add BlazorWebApp
引用 SchemaLibrary 项目。
dotnet add BlazorWebApp reference SchemaLibrary
定义架构
了解数据
用于训练模型的数据来自iris dataset。它包含四个数值列,即花瓣和萼片的度量,最后一列为鸢尾花的种类。这是数据的示例。
| Sepal length (cm) | Sepal width (cm) | Petal length (cm) | Petal width (cm) | Class (iris species) |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | Iris-versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | Iris-virginica |
定义模型输入架构
在SchemaLibrary项目中,创建一个ModelInput类,用于数据建模并作为模型输入。
ni ModelInput.cs
ModelInput类应如下所示:
using Microsoft.ML.Data; namespace SchemaLibrary { public class ModelInput { [LoadColumn(0)] public float SepalLength { get; set; } [LoadColumn(1)] public float SepalWidth { get; set; } [LoadColumn(2)] public float PetalLength { get; set; } [LoadColumn(3)] public float PetalWidth { get; set; } [LoadColumn(4)] public string Label { get; set; } } }
请注意,该列现在是一个称为ClassLabel的属性。原因有二:
- 避免使用class关键字。
- 在ML.NET中,算法要预测的列的默认列名称为Label。
另请注意每个属性顶部的LoadColumn属性。这用于告诉加载程序列的索引,其中相应属性的数据所在的位置。
定义模型输出架构
与输入架构类似,有模型输出的架构。此解决方案中使用的模型类型是多类分类模型,因为鸢尾花种有两个以上类别可供选择。多分类模型输出称为一个列,该列包含预测类别的名称。在SchemaLibrary项目中,创建一个PredictedLabelModelOutput类,用于对模型所做的预测建模。
ni ModelOutput.cs
ModelOutput类应如下所示:
namespace SchemaLibrary { public class ModelOutput { public string PredictedLabel { get; set; } } }
训练模型
现在是时候创建训练模型的应用程序了。
获取数据
下载数据并将其保存在TrainingConsole项目目录中。
curl https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data -o iris.data
定义数据准备和训练步骤
在TrainingConsole项目中,打开Program.cs文件,并在顶部添加以下内容:
using System; using System.Linq; using Microsoft.ML; using SchemaLibrary;
然后,删除Main方法内的内容,并将其替换为以下内容。
// 1. Initialize MLContext MLContext mlContext = new MLContext(); // 2. Load the data IDataView data = mlContext.Data.LoadFromTextFile<ModelInput>("iris.data", separatorChar:','); // 3. Shuffle the data IDataView shuffledData = mlContext.Data.ShuffleRows(data); // 3. Define the data preparation and training pipeline. IEstimator<ITransformer> pipeline = mlContext.Transforms.Concatenate("Features","SepalLength","SepalWidth","PetalLength","PetalWidth") .Append(mlContext.Transforms.NormalizeMinMax("Features")) .Append(mlContext.Transforms.Conversion.MapValueToKey("Label")) .Append(mlContext.MulticlassClassification.Trainers.NaiveBayes()) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel")); // 4. Train with cross-validation var cvResults = mlContext.MulticlassClassification.CrossValidate(shuffledData, pipeline); // 5. Get the highest performing model and its accuracy (ITransformer, double) model = cvResults .OrderByDescending(fold => fold.Metrics.MacroAccuracy) .Select(fold => (fold.Model, fold.Metrics.MacroAccuracy)) .First(); Console.WriteLine($"Top performing model's macro-accuracy: {model.Item2}"); // 6. Save the model mlContext.Model.Save(model.Item1, data.Schema, "model.zip"); Console.WriteLine("Model trained");
训练应用程序从文件iris.data加载数据并应用一系列转换。首先,所有单独的数字列都合并到单个矢量中,并存储在称为Features的新列中。然后,该Features列需要预处理归一化,MapValueToKey转换用于将Label列中的文本转换为数字。然后,转换后的数据用于使用NaiveBayes算法训练模型。请注意,在撰写本文时,对于多分类问题,只有 Naive Bayes 已确认与 Blazor WebAssembly 合作。最后,将PredictedLabel存储为数字,以便必须将其转换回文本。
使用Fit方法,将数据应用于管道。由于数据集很小,因此使用称为交叉验证的技术来构建更健壮的模型。训练模型后,具有最高性能的模型将序列化并保存到名为model.zip的文件,以供以后在 Web 应用程序中使用。
最终Program.cs文件应类似于以下内容:
using System; using System.Linq; using Microsoft.ML; using SchemaLibrary; namespace TrainingConsole { class Program { static void Main(string[] args) { // 1. Initialize MLContext MLContext mlContext = new MLContext(); // 2. Load the data IDataView data = mlContext.Data.LoadFromTextFile<ModelInput>("iris.data", separatorChar:','); // 3. Shuffle the data IDataView shuffledData = mlContext.Data.ShuffleRows(data); // 3. Define the data preparation and training pipeline. IEstimator<ITransformer> pipeline = mlContext.Transforms.Concatenate("Features","SepalLength","SepalWidth","PetalLength","PetalWidth") .Append(mlContext.Transforms.NormalizeMinMax("Features")) .Append(mlContext.Transforms.Conversion.MapValueToKey("Label")) .Append(mlContext.MulticlassClassification.Trainers.NaiveBayes()) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel")); // 4. Train with cross-validation var cvResults = mlContext.MulticlassClassification.CrossValidate(shuffledData, pipeline); // 5. Get the highest performing model and its accuracy (ITransformer, double) model = cvResults .OrderByDescending(fold => fold.Metrics.MacroAccuracy) .Select(fold => (fold.Model, fold.Metrics.MacroAccuracy)) .First(); Console.WriteLine($"Top performing model's macro-accuracy: {model.Item2}"); // 6. Save the model mlContext.Model.Save(model.Item1, data.Schema, "model.zip"); Console.WriteLine("Model trained"); } } }
运行应用程序
在TrainConsole项目目录中,使用以下命令运行应用程序并训练模型:
dotnet run
托管模型
保存模型后,使用 Azure 门户创建 Azure 存储帐户。
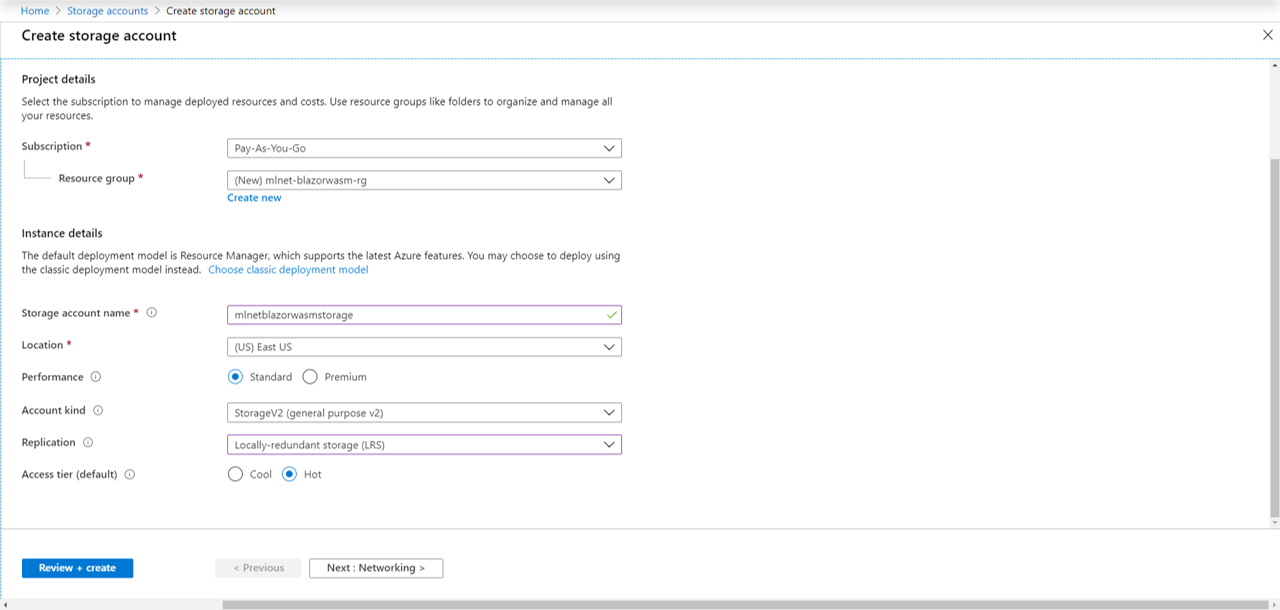
然后,导航到新创建的存储帐户资源,并创建名为models的 Blob 容器。
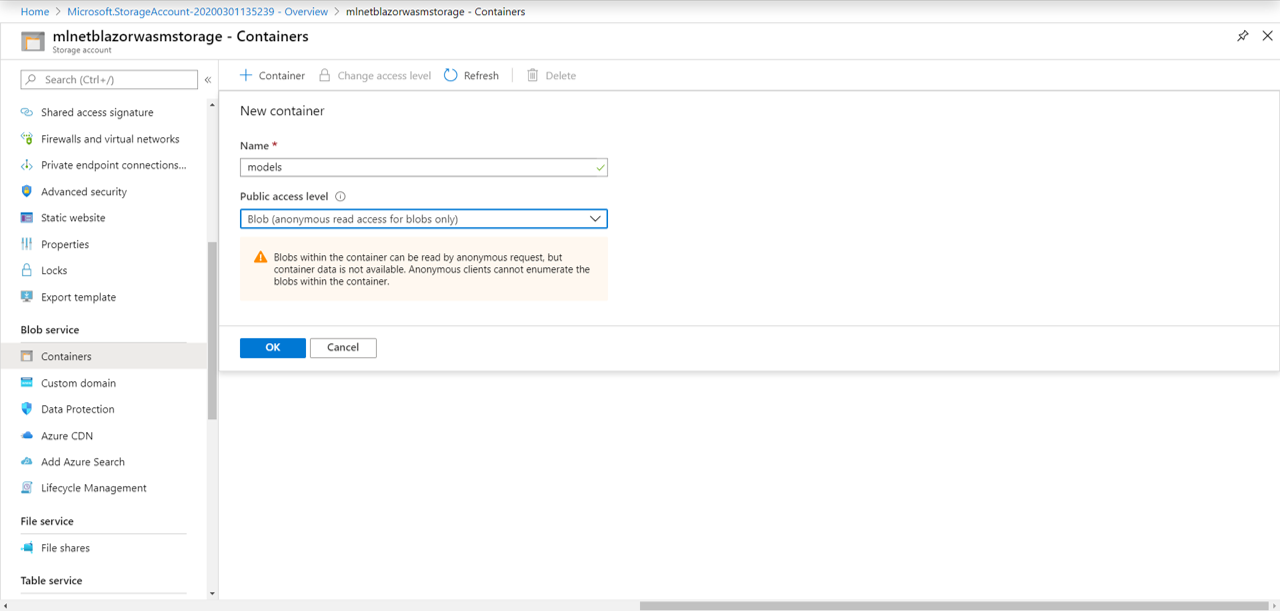
创建容器后,导航到它并上传model.zip文件。
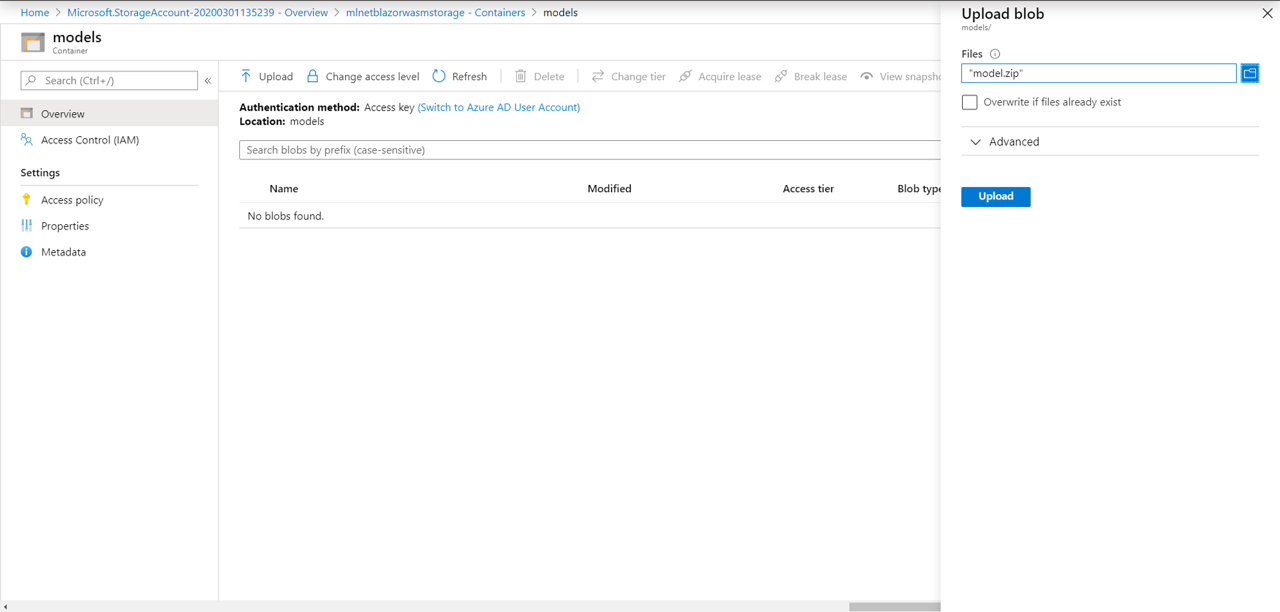
创建预测网页
要进行预测,请创建一个网页以获取用户输入。然后向模型提供用户输入,并将预测显示给用户。
设置导入
在BlazorWebApp项目目录中,打开_Imports.razor文件。这包含应用程序中页面和组件的 using 语句。添加以下使用语句:
@using System.IO
@using Microsoft.ML
@using SchemaLibrary
创建用户输入页
在BlazorWebApp项目中,在Pages目录中创建一个名为"Prediction.razor"的新razor页面。
ni Prediction.razor
向其中添加以下内容:
@page "/prediction" @inject HttpClient _client <label>Sepal Length: </label> <input type="text" @bind="_sepalLength"><br> <label>Sepal Width: </label> <input type="text" @bind="_sepalWidth"><br> <label>Petal Length: </label> <input type="text" @bind="_petalLength"><br> <label>Petal Width: </label> <input type="text" @bind="_petalWidth"><br> <button @onclick="GetPrediction">Make prediction</button> @if(@ModelPrediction == null) { <p>Enter data to get a prediction</p> } else { <p>@ModelPrediction</p> } @code { private PredictionEngine<ModelInput,ModelOutput> _predictionEngine; private string _sepalLength, _sepalWidth, _petalLength, _petalWidth, ModelPrediction; protected override async Task OnInitializedAsync() { Stream savedModel = await _client.GetStreamAsync("<YOUR-MODEL-ENDPOINT>"); MLContext mlContext = new MLContext(); ITransformer _model = mlContext.Model.Load(savedModel,out DataViewSchema schema); _predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput,ModelOutput>(_model); } private void GetPrediction() { ModelInput input = new ModelInput { SepalLength=float.Parse(_sepalLength), SepalWidth=float.Parse(_sepalWidth), PetalLength=float.Parse(_petalLength), PetalWidth=float.Parse(_petalWidth) }; ModelOutput prediction = _predictionEngine.Predict(input); ModelPrediction = prediction.PredictedLabel; } }
Prediction.razor页包含模型原始训练的每个列的文本输入元素。初始化页面时,将从 Azure 存储加载模型并创建PredictionEngine。请确保将<YOUR-MODEL-ENDPOINT>替换为包含模型的 blob 的 URL。PredictionEngine是进行单个预测的便利 API。传统上,当模型用作 Web 服务时,建议使用该PredictionEnginePool服务,因为它在多线程应用程序中具有线程安全且性能更高。但是,在这种情况下,由于模型被下载到单个用户的浏览器上,因此可以使用PredictionEngine。用户输入输入值并单击"创建预测"按钮后,该GetPrediction方法通过获取用户输入并使用PredictionEngine进行预测来执行。然后,预测将显示在浏览器中。
添加到导航菜单
在BlazorWebApp项目中,在Shared目录中打开NavMenu.razor文件。
将以下列表项添加到<ul>元素。
<li class="nav-item px-3"> <NavLink class="nav-link" href="prediction"> <span class="oi oi-list-rich" aria-hidden="true"></span> Prediction </NavLink> </li>
最终的NavMenu.razor页面应如下所示:
<div class="top-row pl-4 navbar navbar-dark"> <a class="navbar-brand" href="">BlazorWebApp</a> <button class="navbar-toggler" @onclick="ToggleNavMenu"> <span class="navbar-toggler-icon"></span> </button> </div> <div class="@NavMenuCssClass" @onclick="ToggleNavMenu"> <ul class="nav flex-column"> <li class="nav-item px-3"> <NavLink class="nav-link" href="" Match="NavLinkMatch.All"> <span class="oi oi-home" aria-hidden="true"></span> Home </NavLink> </li> <li class="nav-item px-3"> <NavLink class="nav-link" href="counter"> <span class="oi oi-plus" aria-hidden="true"></span> Counter </NavLink> </li> <li class="nav-item px-3"> <NavLink class="nav-link" href="fetchdata"> <span class="oi oi-list-rich" aria-hidden="true"></span> Fetch data </NavLink> </li> <li class="nav-item px-3"> <NavLink class="nav-link" href="prediction"> <span class="oi oi-list-rich" aria-hidden="true"></span> Prediction </NavLink> </li> </ul> </div> @code { private bool collapseNavMenu = true; private string NavMenuCssClass => collapseNavMenu ? "collapse" : null; private void ToggleNavMenu() { collapseNavMenu = !collapseNavMenu; } }
配置 Web 应用程序
Web 应用程序将作为 Azure 存储上的静态站点托管。
在 Azure 门户中,导航到托管模型的存储帐户资源。
启用静态网站
为存储帐户启用静态网站,并将索引文档名称和错误文档路径设置为index.html。
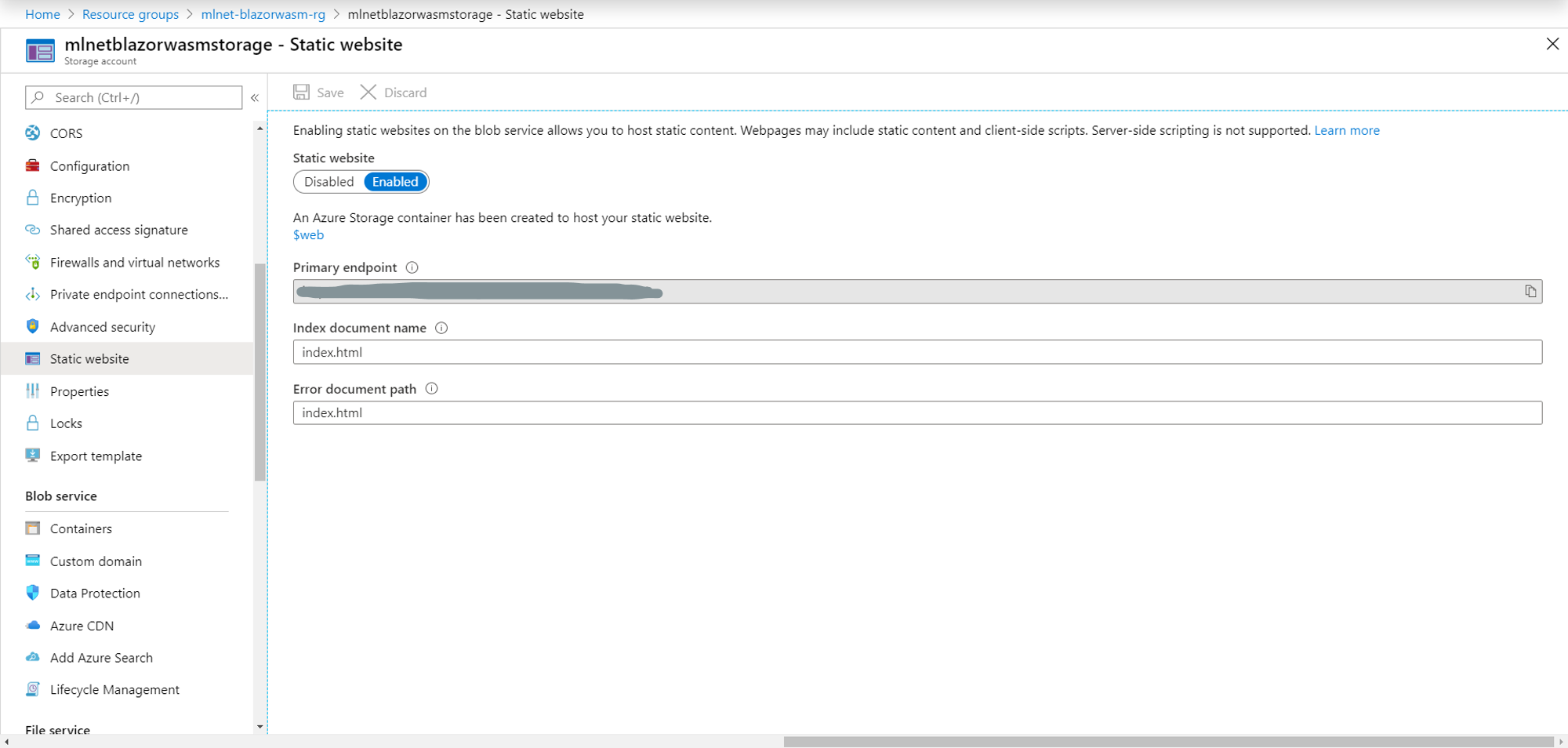
此时,在存储帐户中创建了名为$web的新容器。这是您网站的所有静态文件将驻留的位置。此外,还会创建一个主终结点。这是您将用于访问应用程序的 URL
配置 CORS
存储帐户具有一些默认的 CORS 设置。为了从应用程序下载和使用模型,您必须对其进行配置。
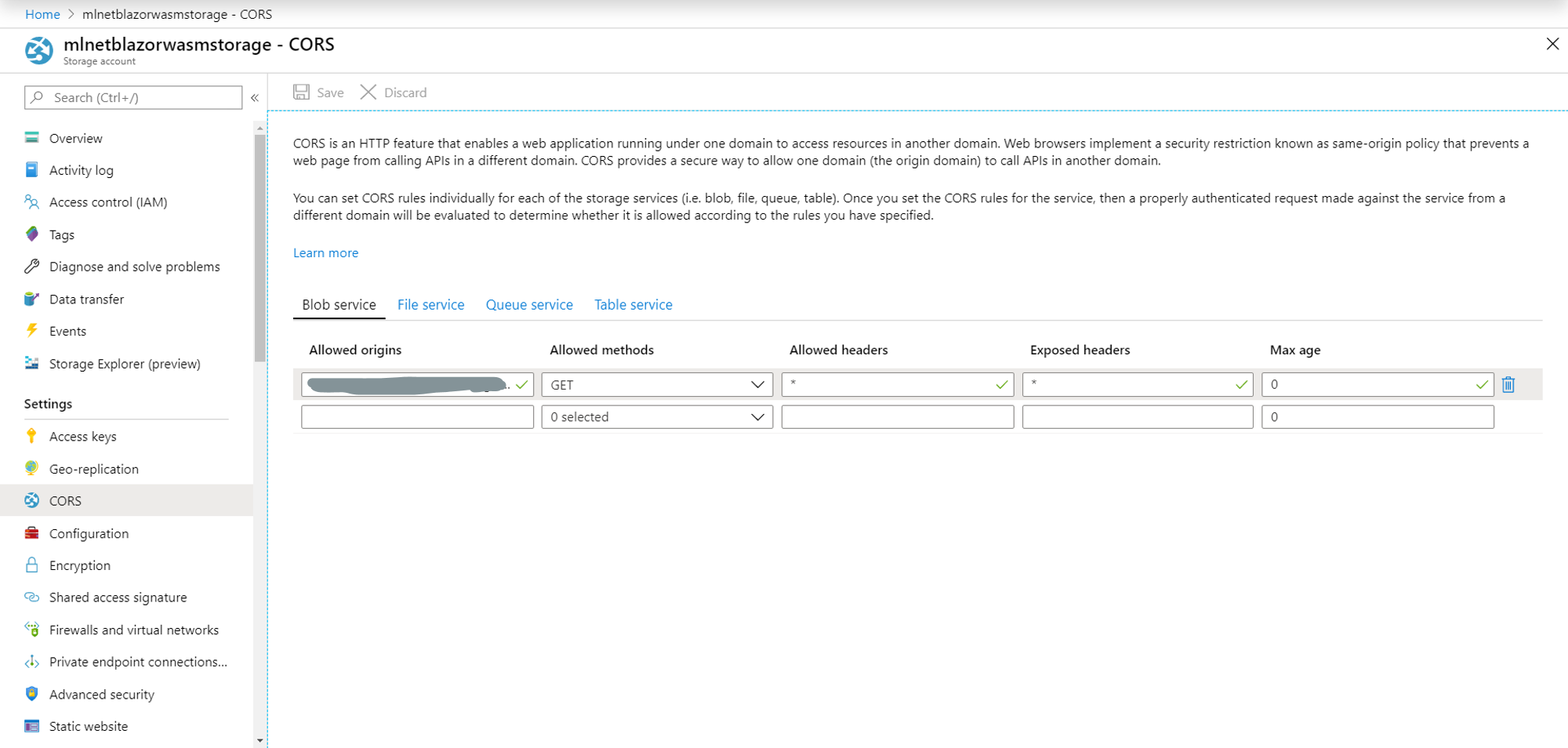
对于"Allowed origins",请输入主终结点。
发布和部署 Web 应用程序
要发布应用程序,请运行以下命令:
dotnet publish -c Release
这将生成在BlazorWebApp项目的 bin/Release/netstandard2.1/publish/BlazorWebApp/dist 目录中所需的文件托管为Web 应用程序静态网站。
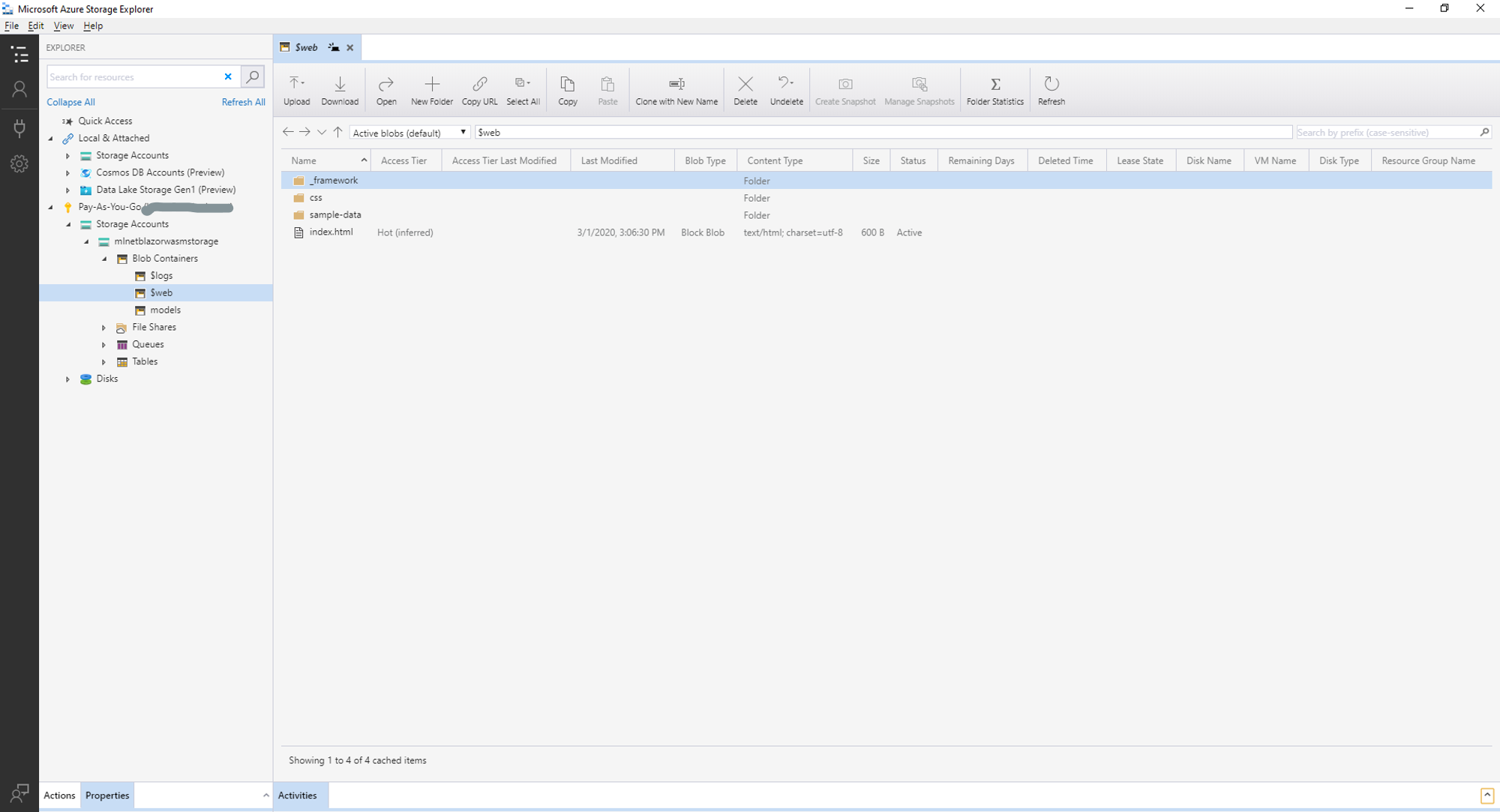
要部署应用程序,请使用 Azure 存储资源管理器将dist目录中的所有文件复制到 Azure 存储帐户的$web容器中。
测试应用程序
在浏览器中,导航到静态网站的主终结点,然后选择"Prediction"页。输入数据并单击"Make prediction"。页面应如下所示。
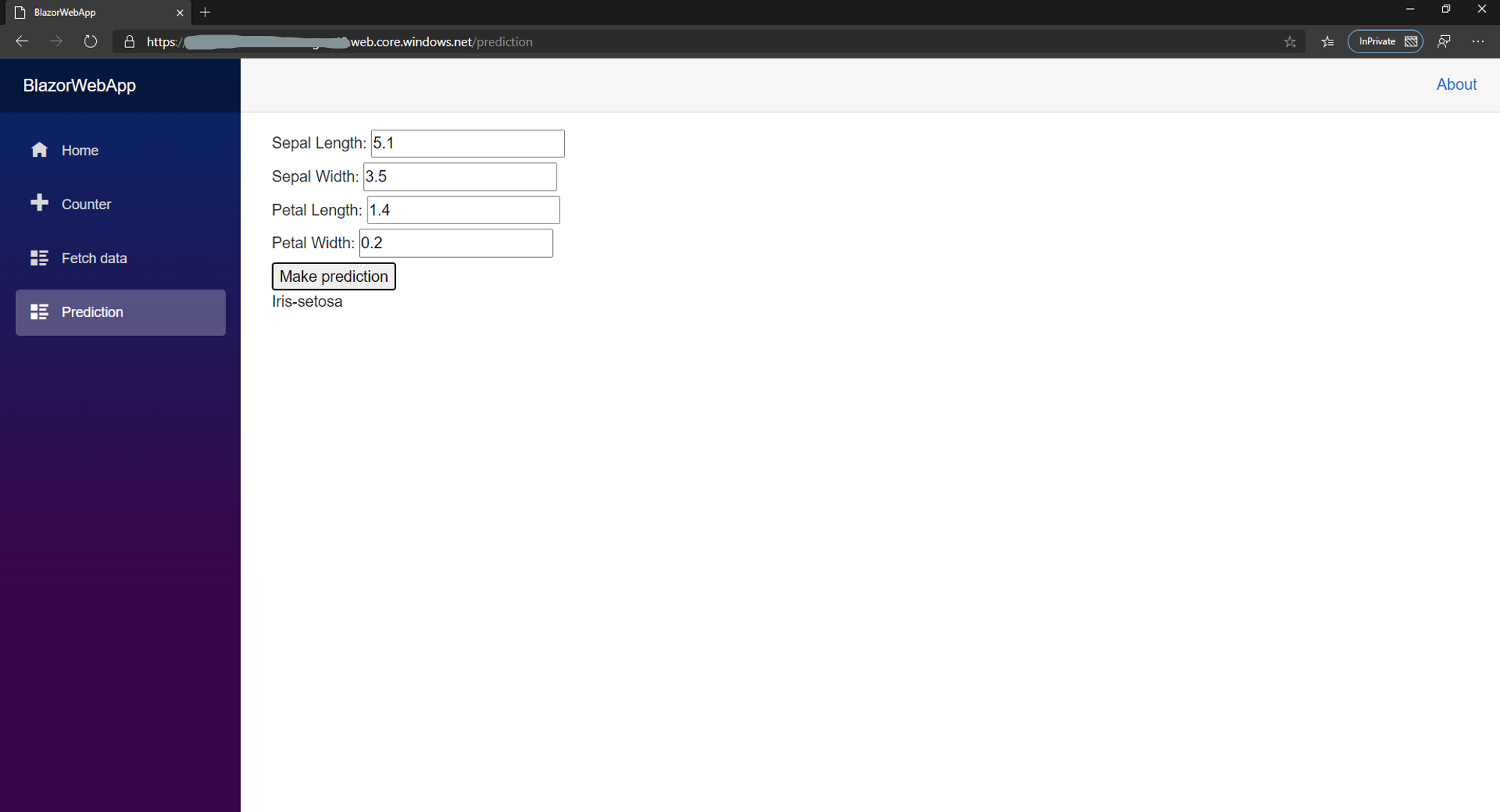
您可能会注意到,Naive Bayes 在此数据集上的性能不是最好的,因此某些预测可能不太准确。我现在可以接受这一点,因为这是一个概念验证,以展示这些技术如何协同工作。也许使用更好的数据集可以产生更好的结果。
结论
在这篇文章中,我考虑如何将ML.NET多分类模型与 Blazor WebAssembly 静态网站一起部署到 Azure。虽然由于 WebAssembly 和 Blazor WebAssembly 的早期阶段,与其他部署方法相比,这一点更为有限,但这表明了这些技术的可能性。以这种方式部署可减少部署这些模型所需的资源量,并将处理从服务器或 Web 服务转移到客户端的浏览器,从而使机器学习模型的部署和分发更加高效、可扩展且更具成本效益。
SchemaLibrary

