
使用 Scikit-learn 和 ML.NET 实现朴素贝叶斯(Naive Bayes)分类器
当我们想到机器学习时,首先想到的语言是 Python 或 R。这是可以理解的,因为它们为我们提供了实现这些算法的许多可能性。
然而,我每天在用 C# 工作,我的注意力被 ML.NET 所吸引。在本文中,我想演示如何使用 Scikit-learn 实现 Python 语言中的 Naive Bayes 分类器,以及使用 ML.NET在 C# 中实现 Naive Bayes 分类器。
Naive Bayes 分类器
Naive Bayes 分类器是一个简单的概率分类器,假定独立变量相互独立,它基于贝叶斯定理,其数学表达如下:
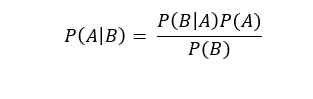
数据
我使用 UCI 机器学习存储库中的葡萄酒质量数据集进行实验。分析的数据集具有 11 个功能和 11 个类。这些等级确定0~10数值范围内的葡萄酒质量。
ML.NET
第一步是创建控制台应用程序项目。然后,您必须从 NuGet 下载 ML.NET 库。现在,您可以创建与数据集中的属性对应的类。创建的类显示在列表中。
然后,您可以继续加载数据集并将其划分为训练集和测试集。我在这里采用了一个标准结构,即 80% 的数据是训练集,而其余的是测试集。
var dataPath = "../../../winequality-red.csv"; var ml = new MLContext(); var DataView = ml.Data.LoadFromTextFile<Features>(dataPath, hasHeader: true, separatorChar: ';');
现在有必要根据ML.NET库采用的标准调整模型结构。这意味着指定类的属性必须称为 Label。其余属性必须在"Features"下聚合。
var partitions = ml.Data.TrainTestSplit( DataView, testFraction: 0.3); var pipeline = ml.Transforms.Conversion.MapValueToKey( inputColumnName: "Quality", outputColumnName: "Label") .Append(ml.Transforms.Concatenate("Features", "FixedAcidity", "VolatileAcidity","CitricAcid", "ResidualSugar", "Chlorides", "FreeSulfurDioxide", "TotalSulfurDioxide","Density", "Ph", "Sulphates", "Alcohol")).AppendCacheCheckpoint(ml);
完成上述步骤后,可以继续创建训练管道。在这里,您选择Naive Bayes分类器,您在参数中指定Label和Features的列名称。您指示的属性也表示预测标签。
var trainingPipeline = pipeline.Append(ml.MulticlassClassification.Trainers.NaiveBayes("Label","Features"))
.Append(ml.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
最后,您可以继续训练和测试模型。一切都以两行代码搞定。
var trainedModel = trainingPipeline.Fit(partitions.TrainSet); var testMetrics = ml.MulticlassClassification.Evaluate(trainedModel.Transform(partitions.TestSet));
Scikit-learn
在 Python 实现的情况下,我们还从处理数据集文件开始。为此,我们使用数字和熊猫库。在列表中,您可以看到用于从文件中检索数据并从中创建 ndarray 的函数,然后用于算法。
from sklearn.naive_bayes import GaussianNB from common.import_data import ImportData from sklearn.model_selection import train_test_split if __name__ == "__main__": data_set = ImportData() x = data_set.import_all_data() y = data_set.import_columns(np.array(['quality']))
下一步是创建一个训练和测试集。在这种情况下,我们还对测试集使用其中 20% 的数据,对训练集使用其中 80% 的数据。我使用了train_test_split函数,它来自 sklearn 库。
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
现在,您可以转到Naive Bayes分类器。在这种情况下,训练和测试也以几行代码结束。
NB = GaussianNB() NB.fit(X_train, y_train.ravel()) predictions = NB.predict(X_test) print('Scores from each Iteration: ', NB.score(X_test, y_test))
结果和摘要
Naive Bayes 分类器用于 Scikit-learn 实现的准确率为 56.5%,而 ML.NET为 41.5%。差异可能是由于其他算法实现方式造成的,但仅基于准确性,我们无法说明哪种方法更好。但是,我们可以说,机器学习算法一种有前途的方式开始出现,即使用 C# 和ML.NET。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号