Java网络高并发
Java网络并发编程
带着问题思考
- 如何提高集群系统的可用性
- 如何提高IO效率
- 如何提高分布式系统的数据一致性
- 网络高并发存在哪些问题,如何解决
负载均衡
通常有两种类型
- 四层负载均衡:基于IP端口进行转发。通常用LVS等技术实现
- 七层负载均衡:基于URL进行转发,又叫做内容负载均衡。更灵活,更细。通常用Nginx等技术实现
算法
- 轮询均衡:平均分配到每个服务器。
- 权重轮询均衡:根据权重平均
- 随机均衡:随机分配
- 权重随机均衡:根据权重随机
- 响应速度均衡:LB设备定时发送探测请求,查看谁的响应最快
- 最少连接数均衡
- 处理能力均衡:分配给当前负荷最轻的服务器,符合根据cpu性能,内存,当前连接数计算
- DNS响应均衡:分发DNS查询到多个DNS服务器,返回最早的
- 哈希算法均衡:通过哈希算法将相同参数的请求总是发送到同一台服务器,保证长期稳定的服务。
- IP地址哈希:维护客户段和服务器的IP对应关系,适用于两者需要长连接的场景,例如TCP长连接
- URL哈希:将相同URL转发给同一个服务器
LVS原理
将一组linux服务器构建成一个虚拟的集群系统,对外界透明,在外界看来这就是一个高性能的linux服务器。
主要组成:
- 负载均衡调度器
- 服务器
- 共享存储
负载均衡器转发消息给真实服务器的模式主要有三种,可以参考以下文章
网络IO模型
-
阻塞IO(BIO)
-
非阻塞IO:不阻塞,但要用户线程轮询查看IO是否完成
-
IO多路复用:用一个叫select的线程在系统内核轮询多个socket,有读写时间触发则通知用户线程处理。适合事件响应体较小的场景,如果较大,会影响每次轮询的整个流程,导致后续事件处理不及时。
-
信号驱动IO:简单来说:信号驱动IO模型是OS通过信号通知来驱动IO操作的完成。
原理:应用程序通过为SIGIO信号注册一个信号关联函数监听文件描述符,调用注册后应用程序可立即返回继续执行。当描述符数据就绪时,通过产生SIGIO信号发起对应用程序信号关联函数的调用,应用程序可通过recvfrom进行数据拷贝。
-
异步IO(AIO):应用程序触发系统调用后可立即返回,内核在数据拷贝完成后再对应用程序发出信号,触发应用程序逻辑。Java用例:
// 打开文件通道并异步读取文件 AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open( Path.of("path/to/file.txt"), StandardOpenOption.READ ); ByteBuffer buffer = ByteBuffer.allocate(1024); long position = 0; // 从文件的起始位置开始读取 // 调用read方法异步读取文件 Future<Integer> future = fileChannel.read(buffer, position); // 可以在这里执行其他任务 // 等待IO操作完成 while (!future.isDone()) { // 可以在这里执行其他任务,或者将CPU资源让给其他线程 } // 获取读取的字节数 int bytesRead = future.get(); // 打印读取的内容 buffer.flip(); byte[] data = new byte[bytesRead]; buffer.get(data); System.out.println("读取的内容:" + new String(data)); // 关闭文件通道 fileChannel.close();
异步IO与信号驱动IO的区别:
- 信号驱动IO产生信号后,应用程序仍然需要阻塞读取数据到应用程序空间。
- 异步IO数据拷贝的过程也是由CPU进行的,直到拷贝完成才通知应用程序,做到全程非阻塞。
Java NIO模型
NIO代表非阻塞IO(Non-blocking IO),而不是信号驱动IO。
传统的IO模型,例如InputStream是阻塞的,面向数据流的,单向的。NIO模型非阻塞,面向缓冲区,双向的。
NIO模型通过引入以下几个关键组件来实现非阻塞IO操作:
缓冲区(Buffer)
存储数据。常用实现类ByteBuffer, IntBuffer CharBuffer等。
核心方法和属性
get()put()flip()切换读写模式capacity: 容量,表示缓冲区中最大存储数据的容量。一旦声明不能更改。limit: 界限,表示缓冲区中可以操作数据的大小。(limit 后的数据不能进行读写)position: 位置,表示缓冲区中正在操作数据的位置。mark: 标记,表示记录当前 position 的位置。可以通过reset()恢复到mark的位置。
注:读写模式的position和limit可能是不同的,原因如下图,简单来说就是写了的位置才能读,而调用filp()就可以切换这两个值。计算缓冲区还剩多少数据也是这limit - position。
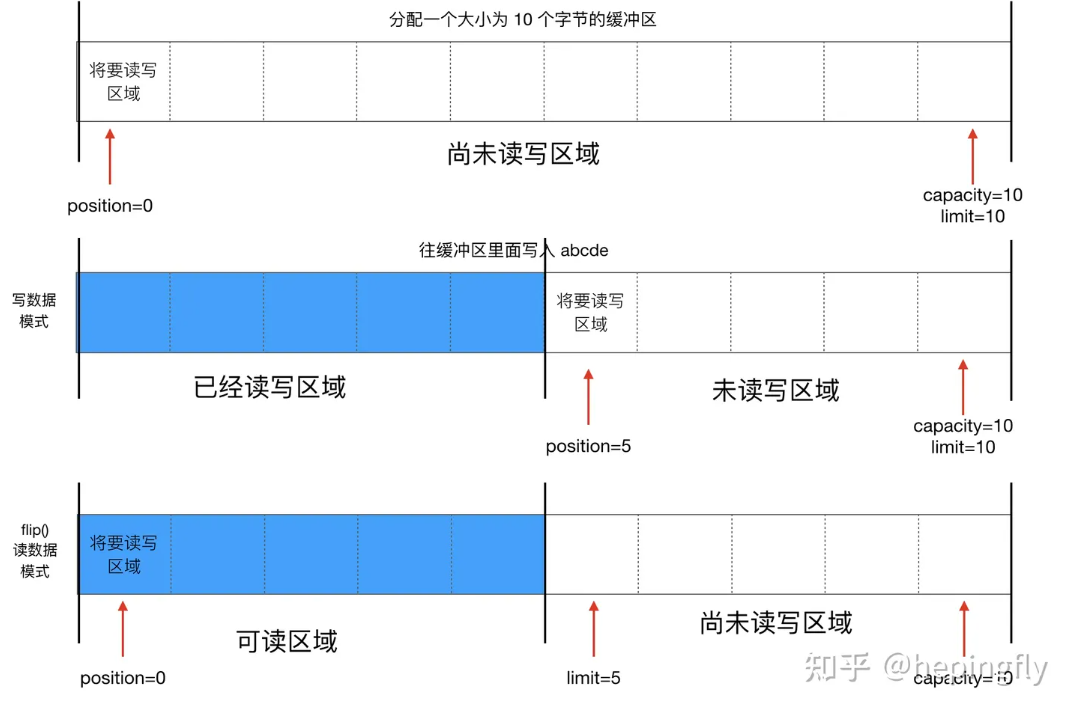
用例
注:
rewind可以重置position=0,mark可以记录当前pos位置,reset将返回这个位置。allocate是直接分配在JVM内存中,读写磁盘需要经过操作系统copy。allocateDirect()`通过内存映射技术在物理内存中映射磁盘。
String str = "abcde";
ByteBuffer byteBuffer = ByteBuffer.allocate(1024); // limit 1024 pos 0
byteBuffer.put(str.getBytes()); // limit 1024 pos 5
byteBuffer.flip(); // 切换后 limit 5 pos 0 表示只能读5个
byte[] bytes = new byte[byteBuffer.limit()]; // 注意,要在flip之后用limit()指定大小,不然大小是错的
byteBuffer.get(bytes);
System.out.println(new String(bytes, 0, bytes.length)); // limit 5 pos 5
byteBuffer.rewind(); // reset pos = 0 remain = 5 虽然读完了,但是pos归零,所以计算出来还剩5
byteBuffer.clear(); // limit 1024 pos 0
通道(Channel)
把buffer中的数据传递出去,类似于传统IO中的流(Stream),但可以同时非阻塞读写。常用实现类FileChannel, DatagramChannel, SocketChannel
非阻塞体现在:原本的socket调用
connect或者read write之类的函数, 如果没有数据可以IO,就会一直阻塞
Channel会返回true/false或者读写了多少数据,如果没读到就返回-1
创建方式
- 通过传统IO类的
getChannel()获取,例如RandomAccessFile FileInputStream FileOutputStream - 通过
Channel类的静态方法open()获取,例如SocketChannel(TCP), ServerSocketChannel, DatagramChannel(UDP)
注
实例:
RandomAccessFile file = new RandomAccessFile("myfile.txt", "rw");
FileChannel channel = file.getChannel();
SocketChannel channel = SocketChannel.open();
channel.connect(new InetSocketAddress("example.com", 80));
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress(8000));
DatagramChannel channel = DatagramChannel.open();
channel.bind(new InetSocketAddress(9000));
核心方法
read(buffer)从通道读给buffer ,write(buffer)将buffer写给通道,不要搞反map()此方法返回映射buffer可以直接对(映射到内存的)磁盘读写。transferTo(channel)通道之间的数据传输configureBlocking()设置非阻塞,注意,FileChannel没有非阻塞模式,因为这个方法是AbstractSelectableChannel的,FileChannel没继承这个类
注:read write可以传buffer数组,达到分散读取和聚集写入的效果。都是按顺序操作,write时依次将所有缓冲区的中pos和limit之间数据写入通道。read依次将通道数据填满缓冲区。
用例
注:虽然通道可以开启非阻塞模式,但是如果没有选择器配合,需要用轮询的方式判断IO事件是否到来,然后做相关操作。如下
SocketChannel channel = SocketChannel.open();
channel.configureBlocking(false);
// 如果是阻塞,则会在这里一直等待连接成功
channel.connect(new InetSocketAddress("211.159.173.136", 8090));
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
// 轮询看看有没有成功建立连接
if (!channel.finishConnect()) {
continue;
}
int read = channel.read(buffer);
// -1 => channel没有数据可以读了
if (read < 1)
continue;
buffer.flip(); // 初始默认写,需要翻转到读
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes, 0, bytes.length);
System.out.println(new String(bytes));
}
如果用上Selector,需要把他注册成Connect和Read事件。
选择器(Selector)
选择器的底层大概就是
select poll epoll之类的系统调用。ref
监听多个通道的IO事件,如读就绪、写就绪等。
只有继承了SelectableChannel的通道才能被选择监听,网络通道都可以,FileChannel不行(上面说过原因)。
调用通道的register(selector, int)方法可以注册进选择器,其中第二个参数指定选择器监控的事件类型,有四种
- 可读:SelectionKey.OP_READ
- 可写:SelectionKey.OP_WRITE
- 连接:SelectionKey.OP_CONNECT
- 接收:SelectionKey.OP_ACCEPT
如果要指定多个可以按位与。
使用方法:
Selector.open()创建选择器,然后将channel注册到选择器中- 之后(循环轮询)使用
selector.select()查看就绪的事件数量,使用selector.selectedKeys()获取事件(SelectionKey)集合 - 可以逐一判断
key的类型(isAcceptable, isReadable, isConnectable isWritable),(注:key的类型和他对应的事件一开始注册绑定的类型一致),然后用key获取到对应的通道进行操作
用例
用selector和通道创建一个Server
// 创建一个Selector
Selector selector = Selector.open();
// 创建一个ServerSocketChannel,并绑定到指定的端口
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(8080));
serverSocketChannel.configureBlocking(false);
// 将ServerSocketChannel注册到Selector,关注连接事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 选择就绪的通道
int readyChannels = selector.select();
if (readyChannels == 0) {
continue;
}
// 获取就绪的SelectionKey集合
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
keyIterator.remove(); // 注意处理过的key要remove
if (key.isAcceptable()) {
// 处理连接事件
ServerSocketChannel serverChannel = (ServerSocketChannel) key.channel();
SocketChannel clientChannel = serverChannel.accept();
clientChannel.configureBlocking(false);
// 注册新连接的socket的读取事件
clientChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 处理读取事件
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = channel.read(buffer);
if (bytesRead > 0) {
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
String message = new String(data);
System.out.println("Received message: " + message);
}
}
// 处理完毕后,需要移除当前的SelectionKey
keyIterator.remove();
}
}
Reactor线程模型
共三种,单线程,多线程,主从多线程
- 单线程:靠一个线程处理所有连接,IO,业务逻辑。就像上面那个选择器的例子。
- 多线程:把业务逻辑和连接IO分开,另外弄一个线程池来执行
- 主从多线程:在多线程基础上,把连接(主
MainReactor)和IO(从SubReactor)分开,分别使用不同线程池。
注:上面说的连接可以指TCP连接,也可以泛指业务的连接,例如进行登录,认证之类的。
Netty
Netty是一个异步事件驱动NIO框架,基于Java NIO的API实现,用户可以主动或者以通知机制获取IO结果。可以理解为一个将Java NIO进行了大量封装,并大大降低Java NIO使用难度和上手门槛的超牛逼框架。
Netty 主要基于Reactors 主从多线程模型
Dubbo、Elasticsearch都采用了Netty。
因为 Netty 本身自己能编码/解码字节流,所有 Netty 可以实现,HTTP 服务器、FTP 服务器、UDP 服务器、RPC 服务器、WebSocket 服务器、Redis 的 Proxy 服务器、MySQL 的 Proxy 服务器等等。即可以自定义协议。
应用场景:实时通讯应用,数据传输,网络游戏开发
主要使用类
-
EventLoopGroup:处理I/O操作的线程池,分为两种类型:NioEventLoopGroup和EpollEventLoopGroup。包含一个或多个EventLoop(单线程),每个EventLoop负责处理一个或多个Channel的I/O事件。EventLoop是对NIO中Selector以及轮询逻辑的封装。 -
Bootstrap:用于启动客户端和非服务器端(如UDP服务器)。提供了配置和启动客户端的功能,并创建和连接Channel。 -
Channel:提供了异步的I/O操作,如读取、写入和关闭等,对Java NIO中的SocketChannel和ServerSocketChannel的封装。如NioSocketChannel、NioServerSocketChannel等 -
ChannelHandler:处理入站和出站数据以及事件。它可以被添加到ChannelPipeline中,用于拦截、处理和转换数据。是对Java NIO中的SelectionKey和对应事件业务逻辑的封装。注:NioEventLoop.processSelectedKey()可以看到本质上还是通过SelectionKey判断类型。常见的
ChannelHandler包括编解码器(如ByteToMessageDecoder和MessageToByteEncoder)可用于自定义协议、业务逻辑处理器(如(Simple)ChannelInboundHandler和ChannelOutboundHandler)用于读写等。
此图承上启下。图src
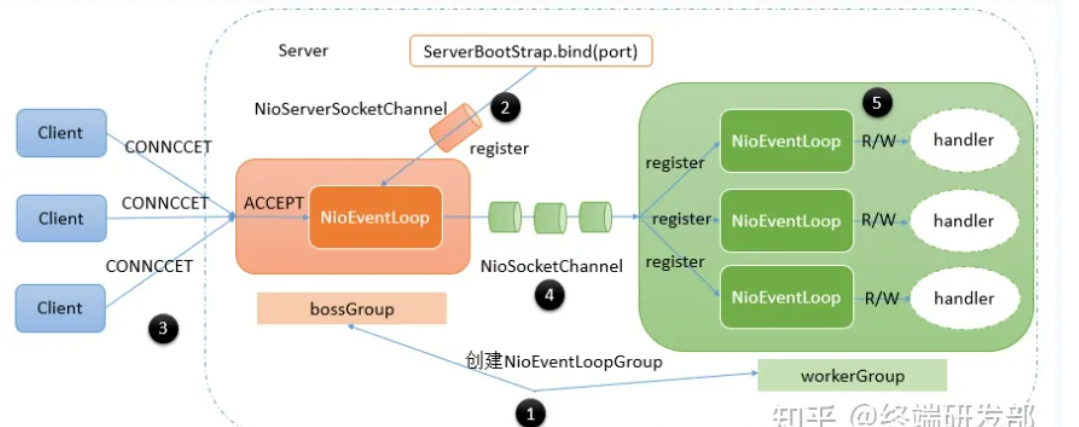
简单使用流程
-
创建一个
EventLoopGroup,用于处理I/O操作的线程池。通常,客户端和服务器端分别创建自己的EventLoopGroup。在服务端一般是两个,一个Group监听接收,另一个负责传输数据。 -
创建一个
Bootstrap或ServerBootstrap实例,配置相关的参数,如EventLoopGroup、Channel类型和处理器等。完全可以不用这个Bootstrap类,可以一点点去手动创建通道、完成各种设置和启动注册到EventLoop反应器。但效率低
-
group方法将EventLoopGroup设置为该实例的事件循环组。 -
channel方法设置Channel的类型,如NioSocketChannel这种非阻塞的,也可以设置阻塞的。 -
option和childoption设置选项。详见ChannelOption类
在Netty中,将有接收关系的监听通道和传输通道叫作父子通道。例如ServerSocket和Socket
-
用
childHandler或者Handler配置通道的Handler流水线。需要传入一个ChannelInitializer子类。像这样b.childHandler(new ChannelInitializer<SocketChannel>() { //有连接到达时会创建一个通道的子通道,并初始化 protected void initChannel(SocketChannel ch){//SocketChannel和上面channel()指定的类型要兼容 //向子通道流水线添加一个Handler业务处理器 ch.pipeline().addLast(new MyServiceHandler()); // 还有addFirst() addAfter() addBefore } });注:可以不调用
Handler父通道(NioServerSocketChannel)的内部业务处理一般是固定的,就是接收新连接然后创建子通道,netty有默认实现。如果要自定义也可以。实际执行Handler的顺序和这个一致。 -
调用
connect方法或bind方法连接到远程服务器或绑定本地端口。注:netty中所有IO操作都是异步的,可以通过
sync()指定其同步执行。也可以给他的future添加回调监听器,如ChannelFuture channelFuture = bootstrap.connect().sync(); // 指定同步 ChannelFuture channelFuture = bootstrap.connect(); // 异步,添加回调listener channelFuture.addListener((ChannelFutureListener) future->{ if (future.isSuccess()) else });
-
-
当连接建立或端口绑定完成后,Netty将自动创建一个
Channel,并将该Channel注册到一个EventLoop中。 -
在
ChannelPipeline中,入站和出站的数据将依次经过添加的ChannelHandler进行处理。 -
当有数据到达或需要发送数据时,
ChannelHandler会被触发执行相应的方法,如channelRead、channelReadComplete、write等。 -
在适当的时候,使用
Channel的write方法将数据写入到连接中,或使用closeFuture(), close()方法关闭连接。 -
用
eventLoopGroup.shutdownGracefully();关闭线程池。
用例
只给出关键的代码,否则太长
创建ServerBootstrap
ServerBootstrap b = new ServerBootstrap();//用于启动NIO服务
b.group(group)
.channel(NioServerSocketChannel.class) //通过工厂方法设计模式实例化一个channel
.localAddress(new InetSocketAddress(port))//设置监听端口
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new HandlerServerHello());
}
});
//绑定服务器,该实例将提供有关IO操作的结果或状态的信息
ChannelFuture channelFuture= b.bind().sync();
System.out.println("在"+ channelFuture.channel().localAddress()+"上开启监听");
//阻塞操作,closeFuture()开启了一个channel的监听器(这期间channel在进行各项工作),直到链路断开
channelFuture.channel().closeFuture().sync();
Server的Handler
client类似,但是两者继承的类不同。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception
{
//处理收到的数据,并反馈消息到到客户端
ByteBuf in = (ByteBuf) msg;
System.out.println("收到客户端发过来的消息: "+ in.toString(CharsetUtil.UTF_8));
//写入并发送信息到远端(客户端)
ctx.writeAndFlush(Unpooled.copiedBuffer("你好,我是服务端,我已经收到你发送的消息", CharsetUtil.UTF_8));
}
注
ChannelHandlerContext作用
- 在
handler链传递数据:我调用write()方法将数据写入到ChannelPipeline中,由下一个Handler进行处理。注意writeAndFlush()会直接写入然后发送给对方,后续Handler可以继续处理数据但不发送,即使再次调用此函数。 - 事件传播:例: 调用
fireChannelRead()方法触发下一个Handler的channelRead()方法的执行。 - 管理Handler:ChannelHandlerContext可以用于动态地添加、移除或替换ChannelHandler,方法:addLast()
、remove()、replace()`。 - 异常处理:调用
fireExceptionCaught()方法将异常事件传播到ChannelPipeline中的异常处理器进行处理,以便进行统一的异常处理逻辑。
Handler调用原理
Netty中Handler有两大类,处理in和out,如图
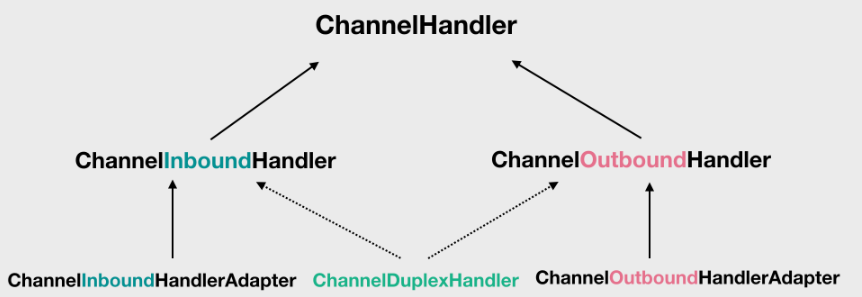
Handler调用顺序
in和out节点们在同一个双向链表中。调in时从前往后,调out时从后往前。问题来了,in和out过渡的时候顺序如何?
ref 先说结论,正常来讲有两种调用方式:用
HandlerContext和用HandlerContext.pipeline() Handler.channel()调用下图中的方法因为context和pipeline都实现了
ChannelInboundInvoker, ChannelOutboundInvoker接口,而channel实现两者之一。若用
context的方法,则从当前节点开始寻找另一种handler,若用pipeline的方法,则从头/节点寻找。底层原理其实是pipeline调context方法,传了头尾节点参数,如果没传就是当前节点。channel则是调用pipeline如果在两种handler不适当的互相调用消息传递的方法,会无限递归。
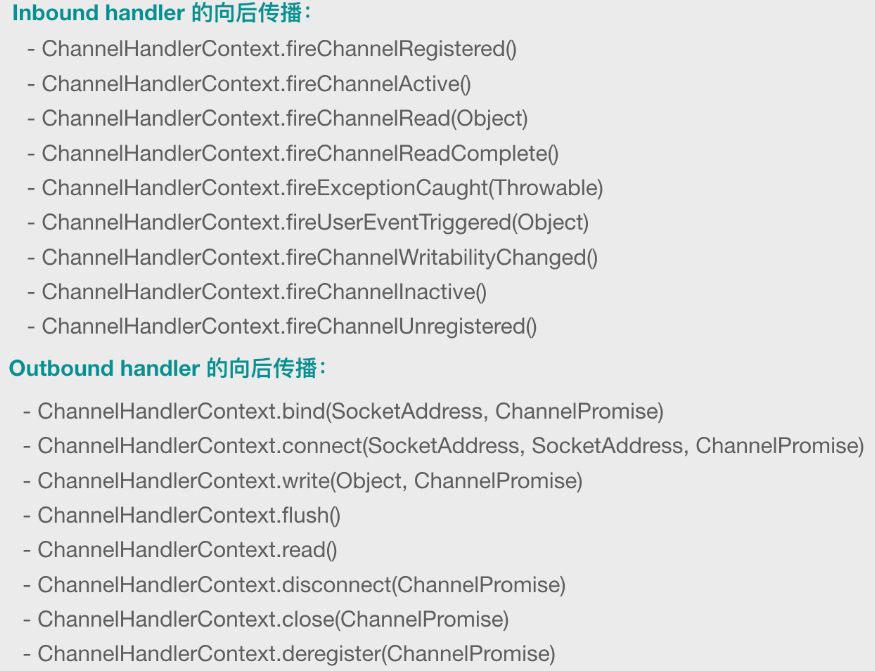
调用顺序源码分析
以下源码主要涉及两个类:AbstractChannelHandlerContext和DefaultChannelPipeline, AbstractChannel
先看in -> out,调用write(),pipeline的write()调用了context的write。
// channel的
public ChannelFuture write(Object msg) {
return pipeline.write(msg);
}
// pipeline的
public final ChannelFuture write(Object msg) {
return tail.write(msg);
}
// context的,省略次要
private void write(Object msg, boolean flush, ChannelPromise promise) {
final AbstractChannelHandlerContext next = findContextOutbound(...); // 上一个out
next.invokeWrite(m, promise); // 内部依然是调用write,
}
// 寻找outhandler
private AbstractChannelHandlerContext findContextOutbound(int mask) {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev; // 从后往前
} while ((ctx.executionMask & mask) == 0);
return ctx;
}
可见如果直接用context调用write,只会从当前节点往前找out,如果当前是in,前面没有out,就执行不到out了。
out->in,和上面类似,也是pipeline传递了头节点参数给context对应的方法。
关于Handler类型
NioEventLoop.processSelectedKey中有这样的代码,可见原本的SelectionKey类型如何对应现在的Handler类型
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
int ops = k.interestOps();
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
unsafe.finishConnect();
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
高性能原因
// TODO这部分后面有时间另外写
- IO多路复用,将接收监听和IO分离。
- 零拷贝。(// TODO另外写笔记)
- 基于内存池的缓冲区重用机制
- 无锁化设计
- 使用了高性能的序列化框架
ProtoBuf。
租约机制
主要思想就是某件事给一个时间限制。主要作用是在多个网络节点之间协调资源的使用,以防止资源被过度占用或滥用。,如连接池管理、线程池管理、分布式锁等。
Eureka HBase都有用到
解决的问题
-
双主问题:主从结构分布式系统中,若主机和从机之间因为网络原因心跳包接收不到,从机选出新的主机,这样网络恢复之后会出现两个主机。数据不一致。
解决:给主机一个时间期限,即租约,过了期限,从机才会重选
-
分布式缓存:客户端可以有服务器资源的缓存。问题在于缓存一致性。客户端轮询服务器有米有更新?服务器一更新就通知客户端?
解决:给客户端一个租约,若服务器在期限内要更改数据,则要通知客户端,清空缓存,重新获取租约。如果超过租约期限,服务器更新数据不用通知客户端,客户端读取的时候也不读缓存,直接请求服务器。
RPC
远程过程调用(Remote Procedure Call),可以理解为函数在不同主机上,调用后,通过网络将返回值传回来,RPC框架能让人调用远程函数跟调本地函数一样方便,不用考虑太多网络编程的语法。
为什么要这样做?
- 系统复杂化,按模块拆分,或者分布式系统,不同模块在不同主机。传递数据要用网络。
- 可以跨语言调用。方便不同团队协作或者提高性能。
概念:
存根:其实是代理,在调用者和socket之间的代理。起到简化调用的作用,不用每次都写socket来发起请求。
高性能系统设计原则
高并发
在后面很多框架中都可见这些设计原则
- 服务拆分:例如微服务
- 服务治理:自动注册、服务发现、分组、隔离、限流、路由
- 异步编程:例如使用
Future Callback - 缓存:浏览器,app缓存,cdn缓存,redis缓存
- 可监控设计:如系统日志,调用链依赖关系,监控指标比如内存占用,流量之类的
高可用
- 多副本部署:某台服务器出现故障可以自动切换别的
- 服务降级:指高并发时保证核心服务可用,非核心服务可以直接读取缓存或者返回错误码
- 限流:网关限流,应用接口限流
- 负载均衡
- 数据可回滚
- 服务隔离:防止某个服务将整个系统搞崩,比如可以每个项目一个单独数据库
linux服务器优化
/etc/security/limits.conf设置文件句柄的最大值sysctl -w vm.max_map_count = 102100设置虚拟内存
还有很多,用到再学。
JVM参数调优
// TODO JVM笔记中再写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号