笔记-java基础巩固-侧重源码分析
变量
Byte
Bate类分析:
范围是-128~127 包装类全都有做缓存
源码分析:https://blog.csdn.net/DJLDYHZSZ/article/details/89918020
Short
short的范围是-32768~32676
包装类缓存的范围是-128~127
源码与Byte的源码非常相似
private static class ShortCache {
private ShortCache(){}
static final Short cache[] = new Short[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Short((short)(i - 128));
}
}
Integer
toString方法中有
public static String toString(int i) {
if (i == Integer.MIN_VALUE)
return "-2147483648";
int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);
char[] buf = new char[size];
getChars(i, size, buf);
return new String(buf, true);
}
static int stringSize(int x) {
for (int i=0; ; i++)
if (x <= sizeTable[i])
return i+1;
}
其中sizeTable分为几个等级,
final static int [] sizeTable = { 9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, Integer.MAX_VALUE };
根据值得大小返回对应字符串的长度,在新建char的时候不用每次都生成最大位数,可以节省空间
Integer同样缓存了-128~127的对象
这里用到的是享元模式
一片森林中有成千上万棵树木,如果每棵树都创建一个对象,那么内存中的对象数量相当庞大,更何况我们现实世界中还有成千上万个森林。
比如围棋有300颗棋子,
用一般的设计模式,
创建一个类,
每个棋子都用一个对象的话
那就会非常麻烦,并且各自定义各自在棋盘的位置.....等等
而使用 享元模式 来实现的话,
就用两个对象 :一个黑,一个白。
这样就可以了,至于棋子的方位不同,那只是对象的不同的外部表现形式或者说是外部状态。
这样三百多个对象就减到了两个对象。
享元模式以共享的方式高效地支持大量的细粒度对象,
说的再具体一些是将所有具有相同状态的对象指向同一个引用,
从而解决了系统在创建大量对象时所带来的内存压力。
Integer设置缓存的大小:(low是写死的-128)
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
- sun.misc.VM.getSavedProperty和System.getProperty有啥区别?
- 唯一的区别是,System.getProperty只能获取非内部的配置信息;例如java.lang.Integer.IntegerCache.high
像sun.zip.disableMemoryMapping、sun.java.launcher.diag、sun.cds.enableSharedLookupCache等不能获取,
这些只能使用sun.misc.VM.getSavedProperty获取
Character
1.阅读Character源码
Character对象会缓存127以内的字符
CharacterCache里面缓存着char的代码点对应[0,127]的Character实例
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
定义了很多特殊字符
使用静态内部类实例化缓存,只有当使用到CharacterCache.cache[(int)c]的时候才会去初始化
这里用到懒汉式单例模式
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
equal方法,先判断对象是否是Character类,如果是Character类就使用基本类型进行==比较
public boolean equals(Object obj) {
if (obj instanceof Character) {
return value == ((Character)obj).charValue();
}
return false;
}

能把全世界的字符都装下的Unicode码

真正能落地的是utf-8

boolean:只能取true或false
源码分析:https://www.cnblogs.com/wzyxidian/p/4769579.html
Float
源码:https://blog.csdn.net/luoyoub/article/details/80199131
Double
源码:https://blog.csdn.net/qq_26896085/article/details/94733615
字符串
String
StringBuffer是线程不安全的,所以在初始化的时候需要加同步代码块
StringBuilder 是线程安全的
String的存储是用char数组存储的`private final char value[];`
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
源码:https://segmentfault.com/a/1190000017489265
- intern()方法:如果常量池有当前String的值,就返回这个值,没有就加进去,返回这个值的引用
String str1="a";
String str2="b";
String str3="ab";
String str4 = str1+str2;
String str5=new String("ab");
System.out.println(str5==str3);//堆内存比较字符串池
//intern如果常量池有当前String的值,就返回这个值,没有就加进去,返回这个值的引用
System.out.println(str5.intern()==str3);//引用的是同一个字符串池里的
System.out.println(str5.intern()==str4);//变量相加给一个新值,所以str4引用的是个新的
System.out.println(str4==str3);//变量相加给一个新值,所以str4引用的是个新的
false
true
false
false
重点: --两个字符串常量或者字面量相加,不会new新的字符串,其他相加则是新值,(如 String str5=str1+"b"😉
StringBuilfer
初始化默认加16个空间
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
很多具体实现都放在AbstractStringBuilder类
源码:https://blog.csdn.net/u012317510/article/details/83721250
StringBuffer
- 所有方法都加上了synchronized关键字
源码:https://blog.csdn.net/wqqqianqian/article/details/80001256
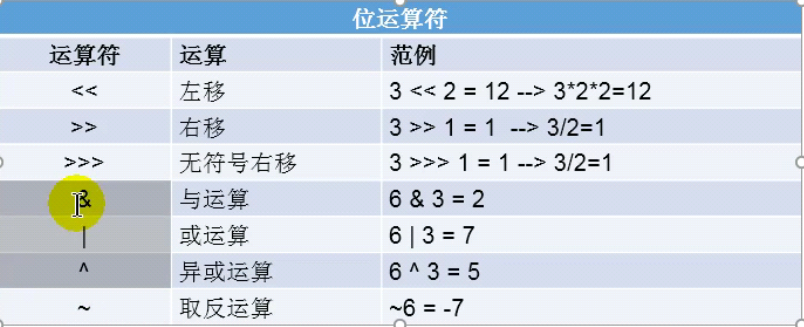
位运算符
switch-case
switch语句可以接受int ,String ,Enum ,char类型。 其实还有byte、short ,不过最后这两种类型会转换成int处理
- switch使用枚举类型demo
想使用枚举类型的switch,必须实现getEnumByName返回Enum类型
这种方法当枚举匹配不到name的时候会产生空指针异常,需要小心
public enum TestEnum {
stu1("小明", "一班"),
stu2("小红", "二班"),
stu3("小丽", "一班"),
stu4("小刚", "三班"),
stu5("小敏", "一班"),
stu6("小帅", "二班");
private String name;
private String banji;
TestEnum() {
}
TestEnum(String name, String banji) {
this.name = name;
this.banji = banji;
}
public String getName() {
return name;
}
public String getBanji() {
return banji;
}
public static TestEnum getEnumByName(String name) {
for (TestEnum testEnum : TestEnum.values()) {
if (testEnum.name.equals(name)) {
return testEnum;
}
}
return null;
}
public static String getValueByKey(String name) {
for (TestEnum testEnum : TestEnum.values()) {
if (testEnum.name.equals(name)) {
return testEnum.banji;
}
}
return null;
}
}
public class Test {
public static void main(String[] args) {
String name="小明";
switch (TestEnum.getEnumByName(name))
{
case stu1:
System.out.println(TestEnum.getValueByKey(name));
break;
case stu2:
System.out.println(TestEnum.getValueByKey(name));
break;
default:
System.out.println("false");
}
}
}
enum代替switch
public enum TestEnum {
stu1("小明", "一班"),
stu2("小红", "二班"),
stu3("小丽", "一班"),
stu4("小刚", "三班"),
stu5("小敏", "一班"),
stu6("小帅", "二班");
private String name;
private String banji;
TestEnum() {
}
TestEnum(String name, String banji) {
this.name = name;
this.banji = banji;
}
//根据姓名获取所在班级
public static String getByName(String value) {
for (TestEnum testEnum : values()) {
if (testEnum.getName().equals(value)) {
return testEnum.getBanji();
}
}
return null;
}
public String getName() {
return name;
}
public String getBanji() {
return banji;
}
}
class Test {
//用法
public static void main(String[] args) {
System.out.println(TestEnum.getByName("小红"));
}
}
跳出多重循环
public static void main(String[] args) {
lableB:
for(int i=0;i<3;i++){
lableA:
for(int j=0;j<3;j++){
System.out.println(j);
if(j==1){
break lableB;
}
}
}
System.out.println("over!");
}
Arrays工具类使用
源码:https://blog.csdn.net/qq_35029061/article/details/100504573
this

异常

受检异常和非受检异常
受检异常:是编译过程中能发现的异常
非受检异常: 运行时产生的异常


子类异常必须要在父类异常之前声明,否则会编译通不过,报错
try、catch、finally用法总结:
1、不管有没有异常,finally中的代码都会执行
2、当try、catch中有return时,finally中的代码依然会继续执行
3、finally是在return后面的表达式运算之后执行的,此时并没有返回运算之后的值,而是把值保存起来,
不管finally对该值做任何的改变,返回的值都不会改变,依然返回保存起来的值。
也就是说方法的返回值是在finally运算之前就确定了的。(但是如果改变引用类型里面的值,则会修改值的)
4、finally代码中最好不要包含return,程序会提前退出,也就是说返回的值不是try或catch中的值
推荐使用try-resource这种方式
public static void main(String[] args) {
try (
InputStream fileInputStream = Files.newInputStream(Paths.get("/Users/xie/delete/test.txt"));
OutputStream outputStream = Files.newOutputStream(Paths.get("/Users/xie/delete/test2.txt"));
) {
byte[] bytes = new byte[1024];
int len;
while ((len = fileInputStream.read(bytes)) > 0) {
outputStream.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
运行时异常可以考虑不使用trycatch

自雷声明的异常范围不能大于父类声明的异常
多线程
线程创建和使用
创建线程有4中方式
1.继承Thread,重写run方法
public class MyThread extends Thread{
private String name;
public MyThread(String name) {
this.name=name;
}
@Override
public void run() {
System.out.println(name);
}
}
2.实现Runnable接口
public class MyThread implements Runnable{
private String name;
public MyThread(String name) {
this.name=name;
}
@Override
public void run() {
System.out.println(name);
}
}
3、实现Callable接口
public class MyThread implements Callable {
private String name;
public MyThread(String name) {
this.name = name;
}
@Override
public Object call() throws Exception {
return name;
}
}
需要借助FutureTask
public static void main(String[] args) throws Exception {
MyThread t = new MyThread("测试");
FutureTask f = new FutureTask(t);
new Thread(f).start();
String result = (String) f.get();
System.out.println(result);
}
4、通过线程池创建
public static void main(String[] args) throws Exception {
ExecutorService service = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
int temp = i;
service.execute(new Runnable() {
@Override
public void run() {
System.out.println("threadName" + Thread.currentThread().getName() + ",i=" + temp);
}
});
}
}
或者
public static void main(String[] args) throws Exception {
ExecutorService service = Executors.newCachedThreadPool();
service.execute(new Runnable() {
@Override
public void run() {
System.out.println("aaaa");
}
});
}
- 线程的优先级

setPriority()设置线程优先级 - run和start区别
run 方法里面定义的是线程执行的任务逻辑,直接调用跟普通方法没啥区别
start 方法启动线程,使线程由 NEW 状态转为 RUNNABLE,然后再由 jvm 去调用该线程的 run () 方法去执行任务
start 方法不能被多次调用,否则会抛出 java.lang.IllegalStateException;而 run () 方法可以进行多次调用,因为它是个普通方法
线程生命周期
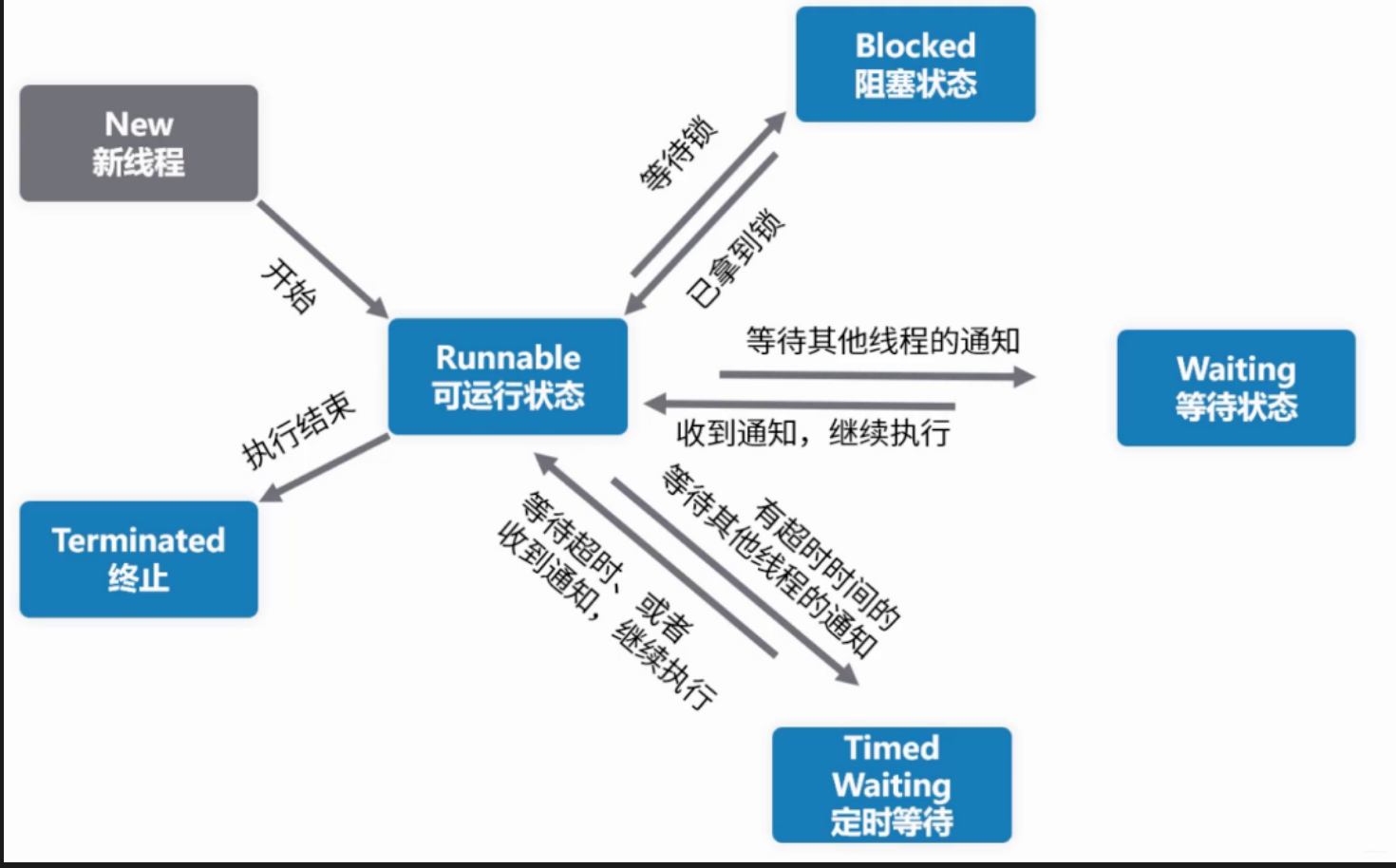
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
线程同步
1.线程同步其实实现的是线程排队。
2.防止线程同步访问共享资源造成冲突。
线程通信
线程等待唤醒机制。
用到的API, 下面的方法都是Object中的。
void wait(): 让当前的线程等待。
void notify(): 随机唤醒一个线程
void notifyAll(): 唤醒所有的线程。
上面这些方法虽然是Object中的方法,但是不能通过对象直接去调用
这些方法一定要放在同步代码块中,并且使用锁对象(对象监视器)去调用。
当一个线程调用wait方法后,会释放自己的锁。
wait和sleep的方法的区别了:
wait方法会释放锁
sleep方法不会释放锁。
demo:同步方法必须放在同步代码块里面才行
public class InputThread extends Thread {
private int count = 0;
private MyCache myCache;
public InputThread(MyCache myCache) {
this.myCache = myCache;
}
@Override
public void run() {
//往myCache写入内容
while (true) {
synchronized (myCache) {
if (!myCache.isEmpty) {
try {
myCache.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
if (myCache.isEmpty) {
if (count == 0) {
myCache.key = "username";
myCache.value = "hestyle";
} else {
myCache.key = "password";
myCache.value = "123456";
}
count = (count + 1) % 2;
//写入了内容,标记cache不为空
myCache.isEmpty = false;
}
myCache.notifyAll();
}
}
}
}
public class OutputThread extends Thread{
private MyCache myCache;
public OutputThread(MyCache myCache) {
this.myCache = myCache;
}
@Override
public void run() {
//往myCache读出内容
while (true) {
synchronized (myCache){
if(myCache.isEmpty){
try {
myCache.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
if (!myCache.isEmpty) {
System.out.println(myCache);
//读出了内容,标记cache为空
myCache.isEmpty = true;
}
myCache.notifyAll();
}
}
}
}
public class MyCache {
public String key;
public String value;
/**标记cache是否为空*/
public boolean isEmpty = true;
@Override
public String toString() {
return "MyCache{" +
"key='" + key + '\'' +
", value='" + value + '\'' +
", isEmpty=" + isEmpty +
'}';
}
}
public static void main(String[] args) {
//创建一个公共cache
MyCache myCache = new MyCache();
//创建input、output进程
InputThread inputThread = new InputThread(myCache);
OutputThread outputThread = new OutputThread(myCache);
//启动两个线程
inputThread.start();
outputThread.start();
}
死锁
死锁产生的条件
互斥条件:一个资源,或者说一个锁只能被一个线程所占用,当一个线程首先获取到这个锁之后,在该线程释放这个锁之前,其它线程均是无法获取到这个锁的。
占有且等待:一个线程已经获取到一个锁,再获取另一个锁的过程中,即使获取不到也不会释放已经获得的锁。
不可剥夺条件:任何一个线程都无法强制获取别的线程已经占有的锁
循环等待条件:线程A拿着线程B的锁,线程B拿着线程A的锁。
死锁demo
package test;
public class DeadLock {
private Object o1 = new Object();
private Object o2 = new Object();
public void method1() throws InterruptedException {
synchronized (o1) {
System.out.println(Thread.currentThread().getName() + "获取到lock1,请求获取lock2");
Thread.sleep(2000);
synchronized (o2) {
System.out.println("获取到lock2");
}
}
}
public void method2() throws InterruptedException {
synchronized (o2) {
System.out.println(Thread.currentThread().getName() + "获取到lock2,请求获取lock1");
Thread.sleep(2000);
synchronized (o1) {
System.out.println("获取到lock1");
}
}
}
public static void main(String[] args) {
DeadLock deadLock = new DeadLock();
new Thread(() -> {
try {
deadLock.method1();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread1").start();
new Thread(() -> {
try {
deadLock.method2();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread2").start();
}
}
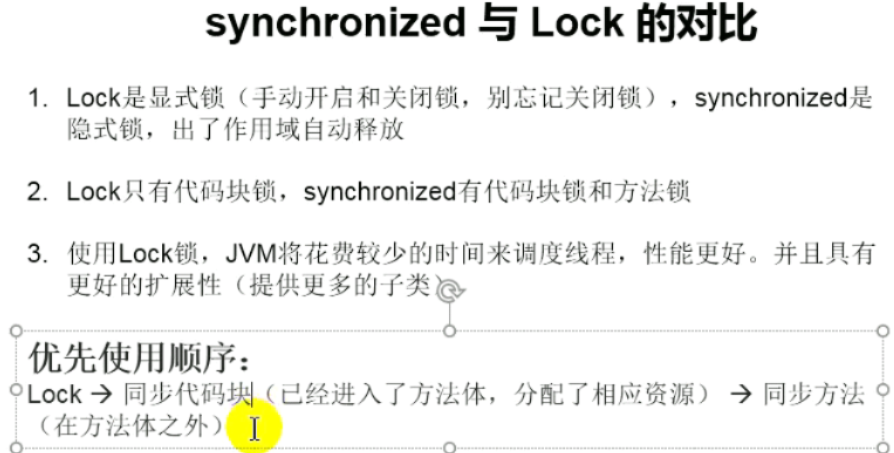
synchronized和Lock对比

Thread和Runnable源码分析
Runnable是一个函数式接口,只有一个run方法
sleep和wait异同
相同点: 都可以使当前线程进入阻塞状态
不同点: 两个方法声明的位置不同,Thread声明sleep, Object声明wait
wait必须使用在同步代码块内,sleep没有限制
如果两个方法都使用在同步代码块中
sleep不会释放锁
wait会释放锁
java常用类
string

不可变性:只要对字符串中的任意字符进行修改,都会创建一个新的字符串
日期和时间api
System类源码
日期相关类研究
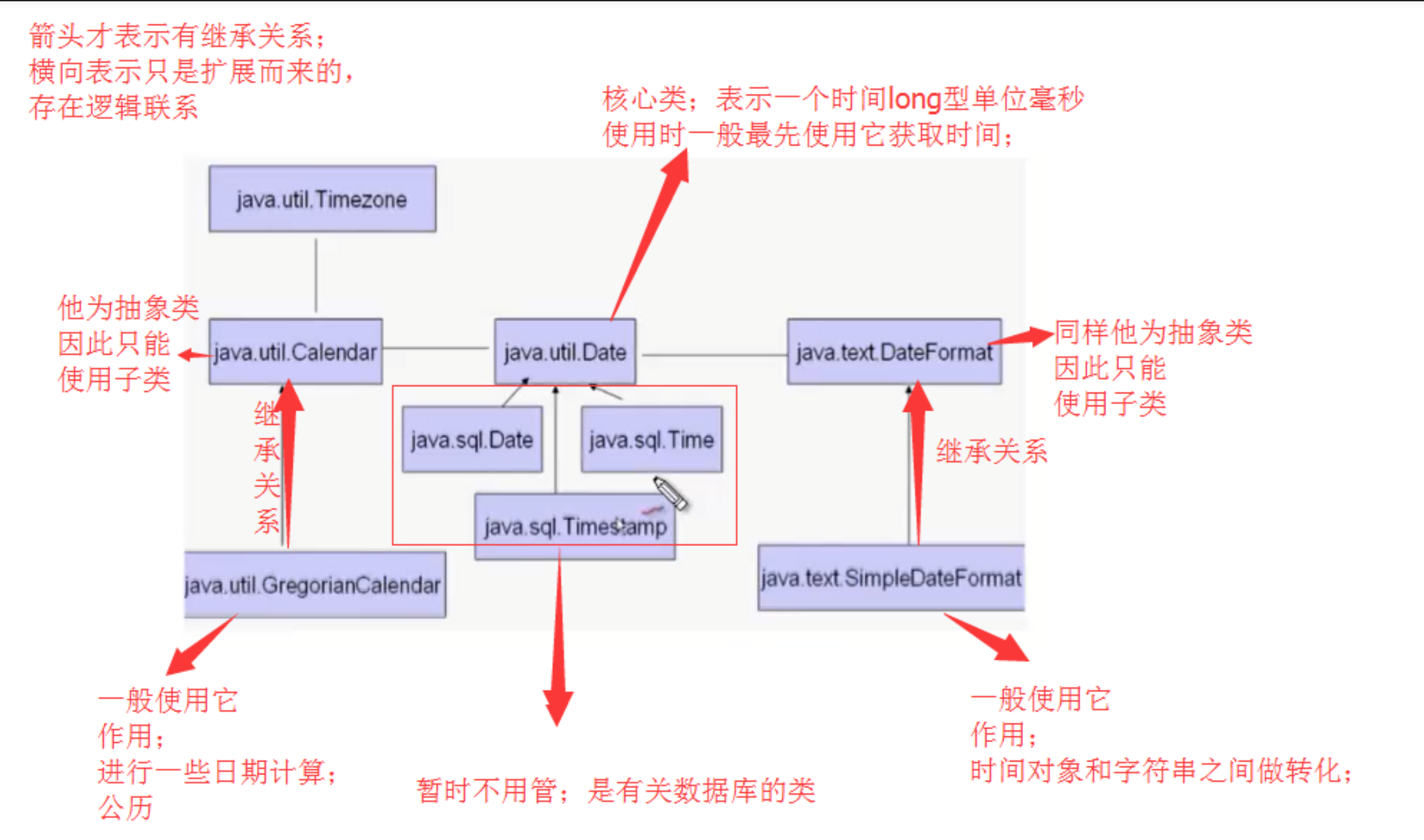
源码:https://blog.csdn.net/zw1996/article/details/53248354
Date主要在于一个long的时间戳
所有操作都是基于这个时间戳来的
private transient long fastTime;
Calendar c= new GregorianCalendar();
c.set(Calendar.YEAR,2016);
Date f = c.getTime();
System.out.println(f.toString());
java.sql.Date和java.util.Date的转换
因为两个的底层都是存long的数字
java.util.Date d = new java.util.Date();
java.sql.Date f = new Date(d.getTime());
转换方法: https://www.cnblogs.com/chenyanlong/p/8041889.html
java8日期api:https://segmentfault.com/a/1190000012922933
获取时间的方法:
LocalDateTime lt = LocalDateTime.now();
System.out.println(lt.withNano(0).toString().replace("T"," "));
获取当前毫秒数:
Instant.now().toEpochMilli()
精确到秒的:
Instant.now().getEpochSecond()
日期间隔计算
LocalDate startDate = LocalDate.of(1993, Month.OCTOBER, 19);
System.out.println("开始时间 : " + startDate);
LocalDate endDate = LocalDate.of(2017, Month.JUNE, 16);
System.out.println("结束时间 : " + endDate);
long daysDiff = ChronoUnit.DAYS.between(startDate, endDate);
System.out.println("两天之间的差在天数 : " + daysDiff);
时间之间互转:https://www.cnblogs.com/luweiweicode/p/14217505.html
Comparable和Comparator区别
一个类只要实现了Comparable接口,就可以排序
Good类实现了Comparable接口
Goods[] arr = new Goods[4];
arr[0] = new Goods("a",1);
arr[1] = new Goods("b",2);
arr[2]=new Goods("c",3);
arr[3]=new Goods("d",4);
Arrays.sort(arr);
Comparator接口的使用:
Arrays.sort(arr, new Comparator<Goods>() {
@Override
public int compare(Goods o1, Goods o2) {
return 0;
}
});
集合
集合,数组都是对多个数据进行存储操作的结构,简称java容器
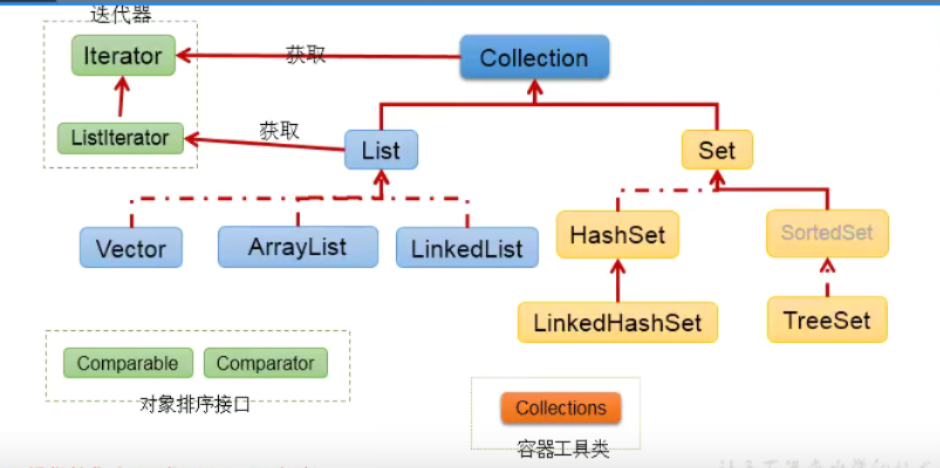
iterator遍历原理:

List
通常使用List替代数组,相比于数组可以动态扩展
ArrayList LinkedList Vector区别?
相同点: 都实现了List,存储特点相同
不同点:
ArrayList: 作为list主要实现类,线程不安全,效率高,底层使用Object类的数组,是对底层数组的封装
LinkedList: 底层使用双向链表,频繁插入和删除效率比ArrayList高
Vector: 古老的list实现类,线程安全,效率低,也是使用Object类数组
源码分析: https://www.cnblogs.com/dafanjoy/p/9690568.html
Set
HashSet
LinkedSet:使用LinkedHashMap实现
TreeSet:使用TreeMap实现, TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法
set基本上是依靠HashMap实现,增删改查基本上是用HashMap的方法
set的无序性: 指的是数据在底层并非按照数组索引顺序添加,而是计算hashcode后存储在相应的位置
set的不可重复: 保证添加的元素的equals()判断时不能返回true
在set对象时,要重写equals和hashcode方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return userName.equals(user.userName);
}
@Override
public int hashCode() {
return Objects.hash(userName);
}
Map
-- HashMap
-- LinkedHashMap
-- TreeMap
-- Hashtable
HashMap

加载因子为什么取0.75

主数组的长度为什么要取2^n?
获取位置:

防止哈希冲突,位置冲突


数组的长度为什么是2的你次幂:方便进行取余运算;;方便进行扩容操作后元素的整体移动
HashMap在调用构造器的时候没有进行初始化,而是在put的时候调用resize函数进行初始化数组
这个右移的过程是扰动的作用,使数据更均匀
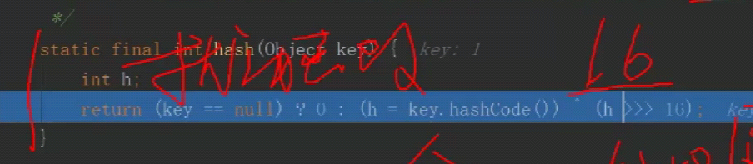
迭代器是针对collection的, 所以map中没有迭代器
遍历所有key
Set set = map.keySet();
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
遍历所有value
Collection coll = map.values();
Iterator valueItr = coll.iterator();
while(valueItr.hasNext()){
System.out.println(valueItr.next());
}
遍历所有key value
Set valueSet = map.entrySet();
Iterator entryItr = valueSet.iterator();
while (entryItr.hasNext()){
Map.Entry obj = (Map.Entry) entryItr.next();
System.out.println(obj.getKey());
System.out.println(obj.getValue());
}
泛型
泛型方法:
public <E> List<E> copyFrom(E[] array){
List list = new ArrayList<E>();
for (E e: array){
list.add(e);
}
return list;
}
其中需要加上
如果不加E的话,会被认为E是一个对象,而不是泛型
io流
File代表一个文件或文件夹
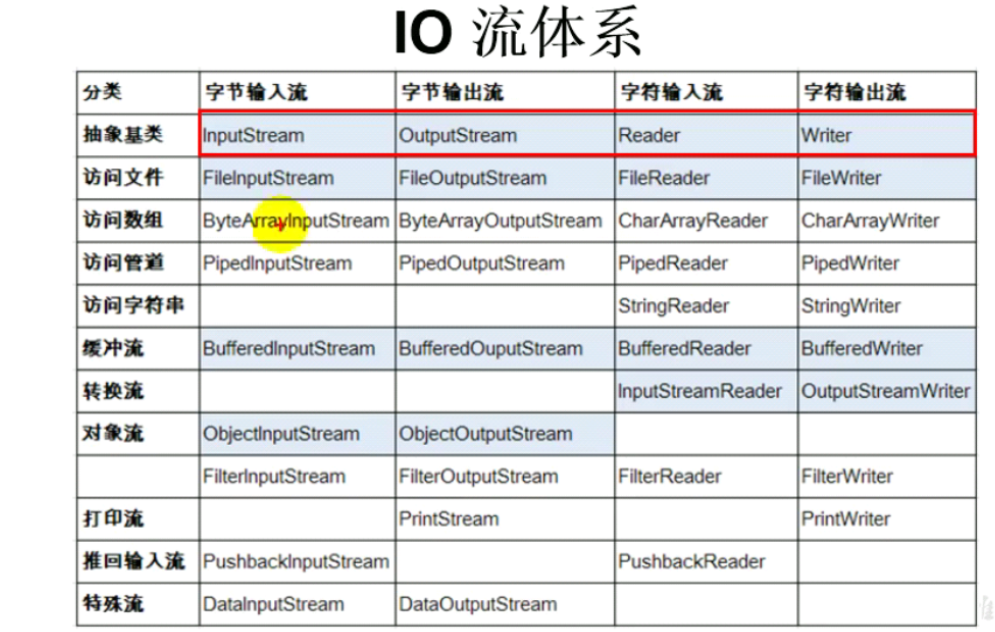

对象序列化
如果在实现了序列化接口的类不加private static final long serialVersionUID = 1111L;
则当类添加或删除字段之后,反序列化之前序列化的类会报错,相当于一个版本控制的意思
如果类中引用了其他类,则其他类也要实现序列化接口
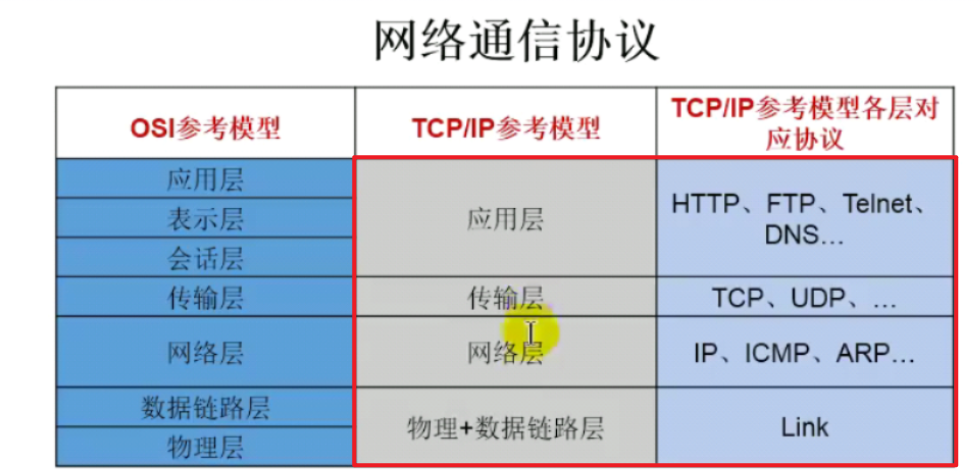
网络编程

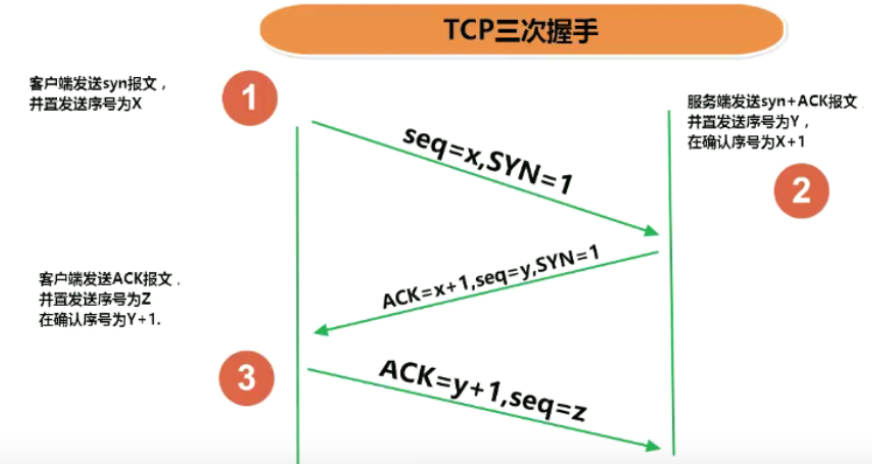
TCP三次握手
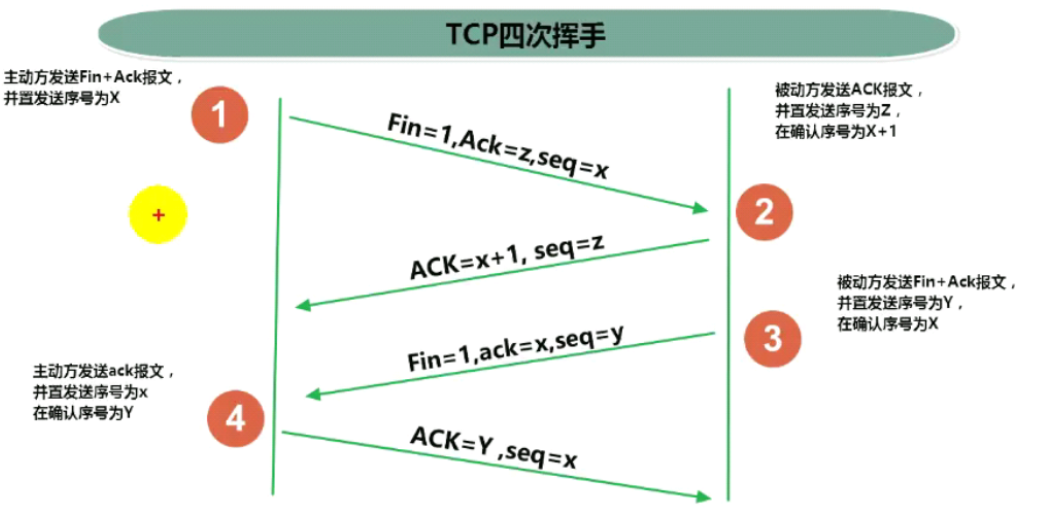
TCP四次挥手

 浙公网安备 33010602011771号
浙公网安备 33010602011771号