springcloud相关笔记整理
Ribbon



restTemplate
getForObject:相当于json格式数据
getForEntity:在数据加上返回的强求头等信息
ribbon=负载均衡+resttemplate的组合
换一种轮询算法怎样换?怎样自己实现一个轮询算法?实现Irule接口
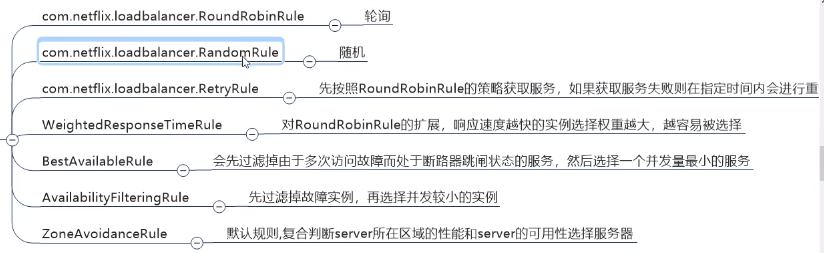
如何替换?
自定义的轮询方法类不能放在@commentScsn能扫描到的地方

然后在主启动类中配置即可

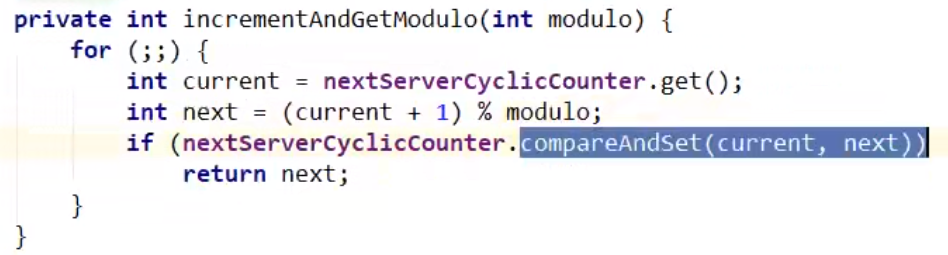
轮询算法原理:


分布式唯一ID生成方法
OpenFeign: 集成了ribbon
使用方法:
1.在主启动类中增加注解@EnableFeignClients
2.直接在接口上定义即可

openfign超时设置:

配置feign日志:


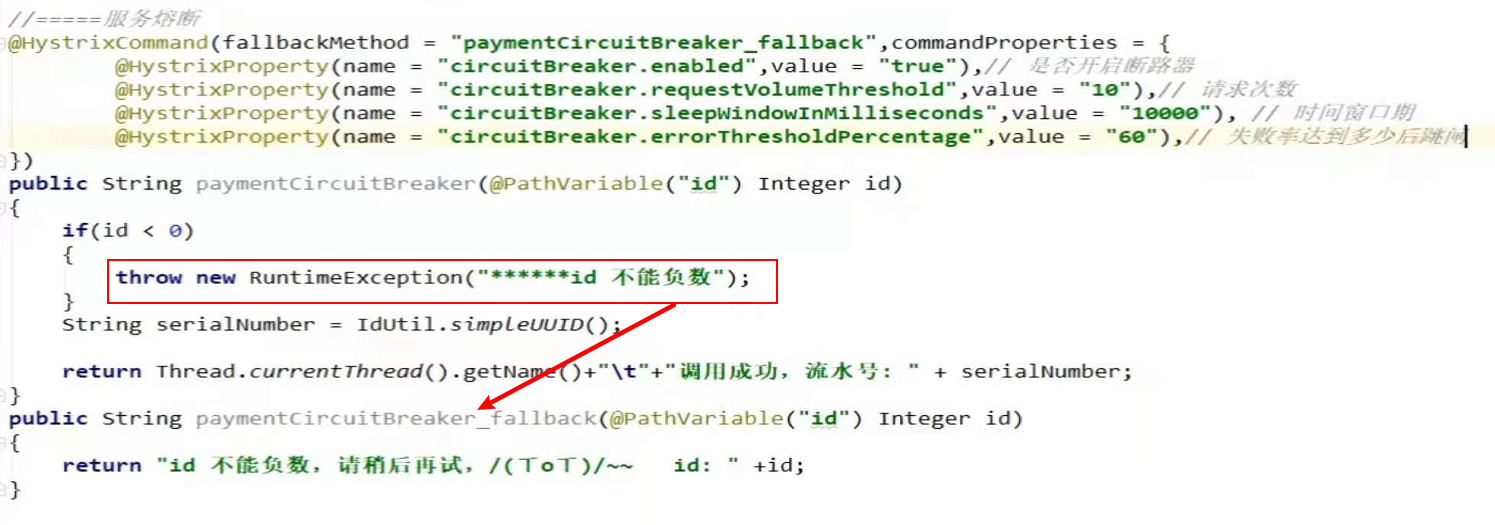
Hystrix






网关
选gateway,丢弃zuul:因为zuul缺少维护,zuul2一直跳票,所有使用springcloud gateway
SpringCloud GateWay使用Webflux中的reactor-netty响应式编程组件,底层使用了netty

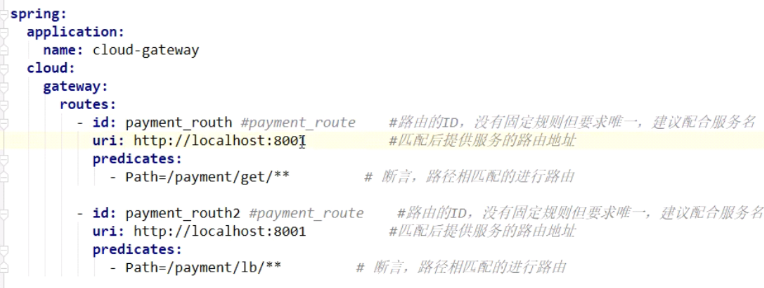
路由配置:
通过bean的方式配置:

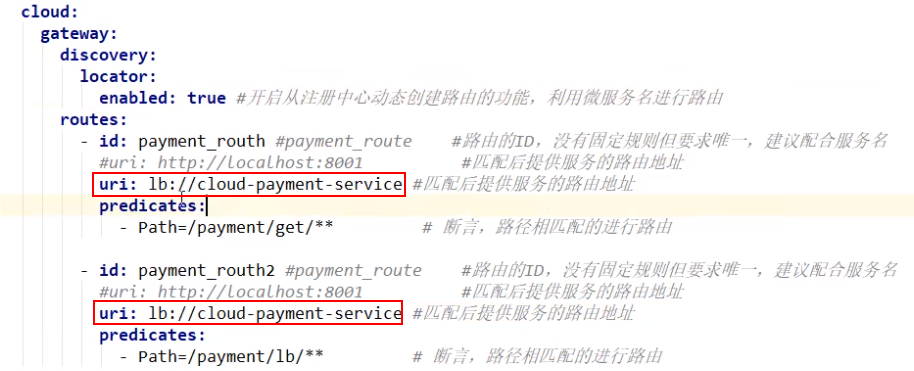
配置生效时间:

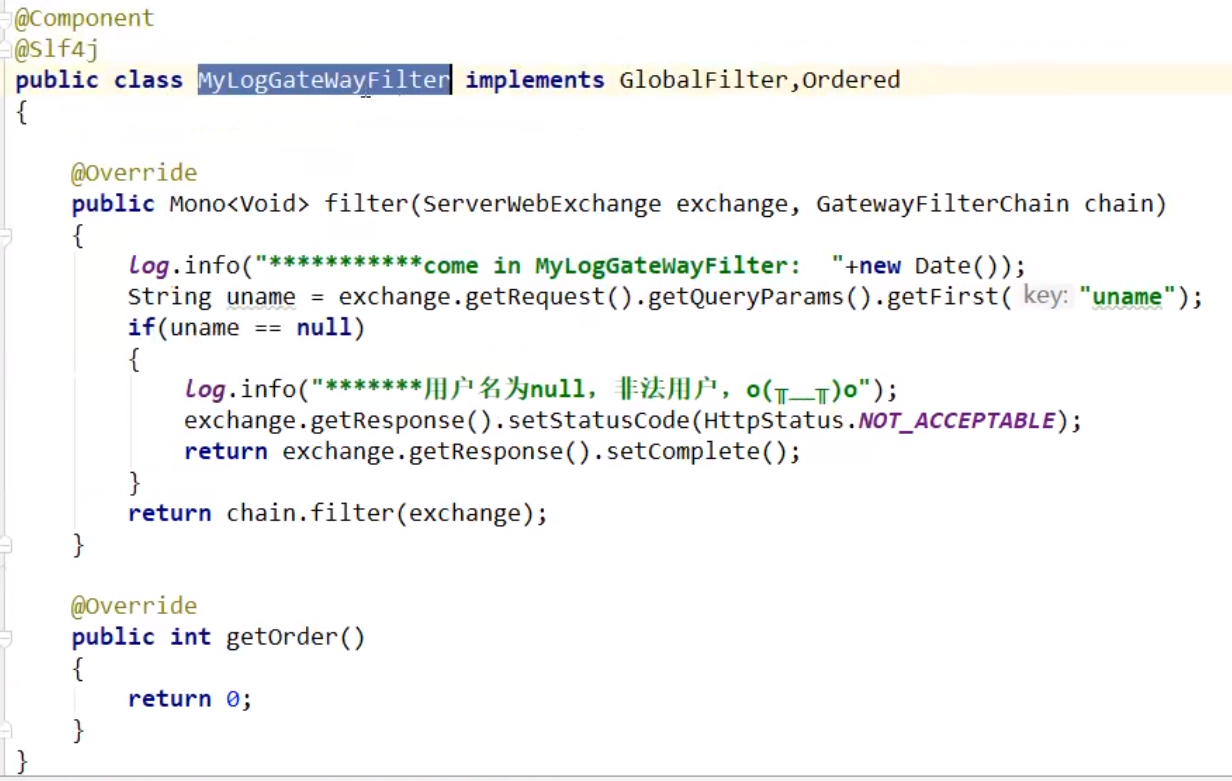
自定义网关过滤器
SpringCloud Config
配置中心的配置:
配置动态刷新:
1.增加监控依赖

2.修改yml,暴露监控端口

3.@RefreshScore注解
4.运维发送请求刷新配置: 
此时如果修改了github的配置文件,调用刷新url后本地的项目也会更新配置,如果没有调用refresh接口,则本地项目不会被更新
如果想使用广播的方法,或者指定项目的更新,需要bus的配合
SpringCloudBus
能管理和传播分布式系统间消息,用于广播状态修改,事件推送
使用轻量级的消息代理来构建一个共用的消息主题,并让所有的微服务连接上来,由于该主题中产生的消息会被所有实例监听和消费,所以称为消息总线
ConfigClient实例都监听MQ中同一个topic,当一个服务刷新数据时,将这个消息放入到Topic中,这样其他监听同一topic的服务就能得到通知,就去更新自身的配置
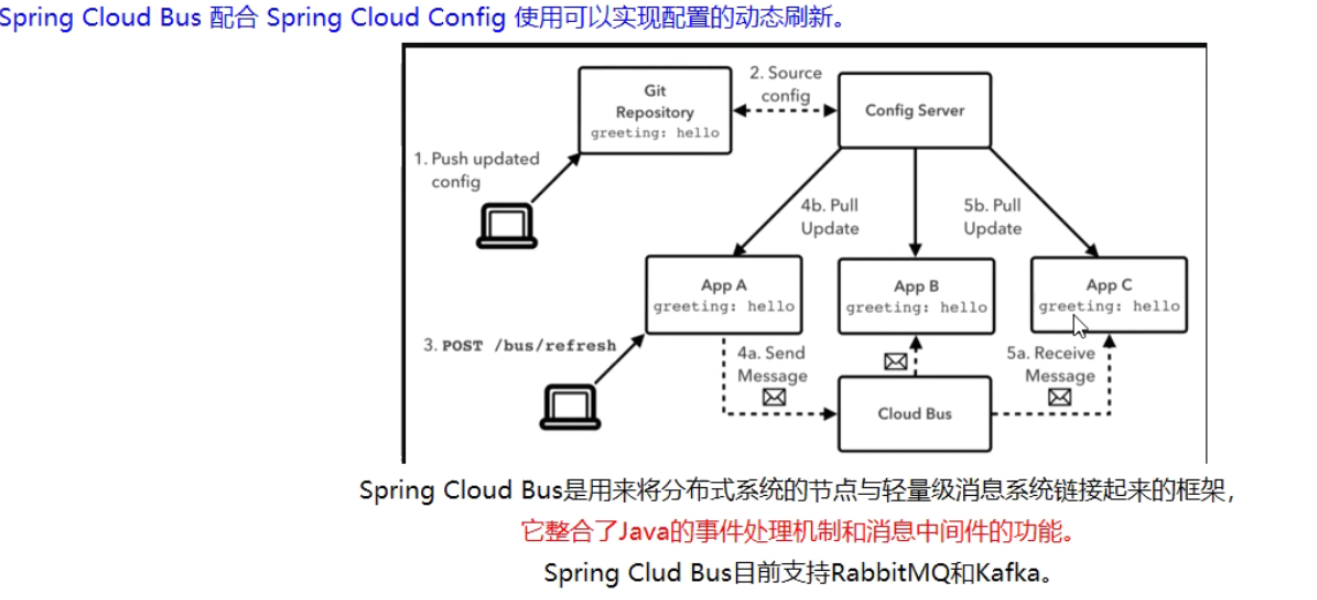


比较合理的是触发服务端的configserver而不是触发其中一个服务
添加方法:
1.增加依赖:增加rabbitmq支持

2.增加rabbitmq的相关配置
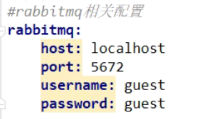
3.暴露配置端点

4.所有的客户端需要增加amqp依赖和配置文件


5.对配置服务器调用刷新操作,所有的微服务都会更新配置

动态服务定点通知


Stream:通过中间层Binder屏蔽消息中间件之间的差异

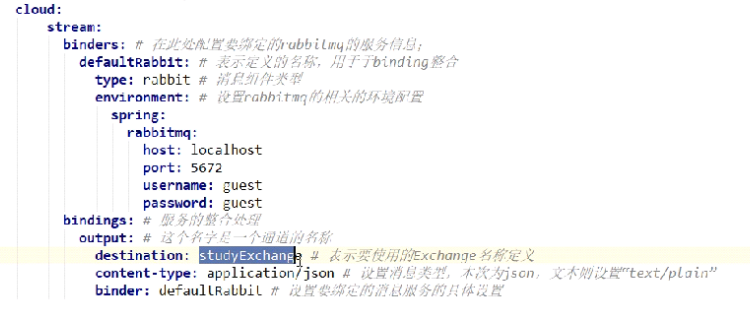


生产者
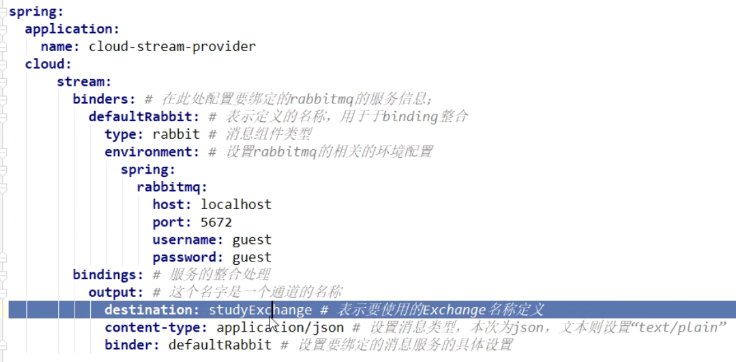
消费者
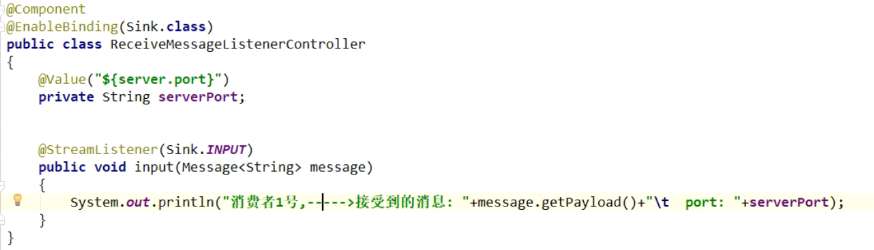
消息重复消费: 使用分组
持久化: 如果没有设置分组,则消费者停止的期间会发生消息丢失,如果配置了分组,则消费者重启后会继续消费消息,不会丢失
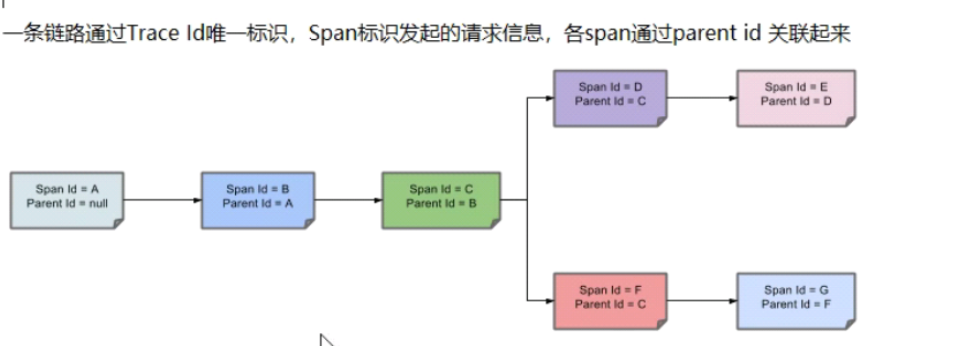
Sleuth
一整套完成服务跟踪的解决方案,zipkin:页面展示
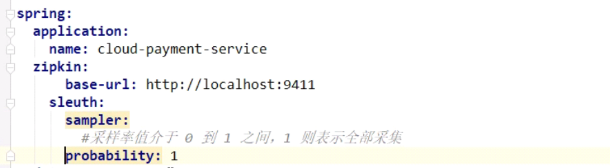
配置:需要加监控的加上这些配置
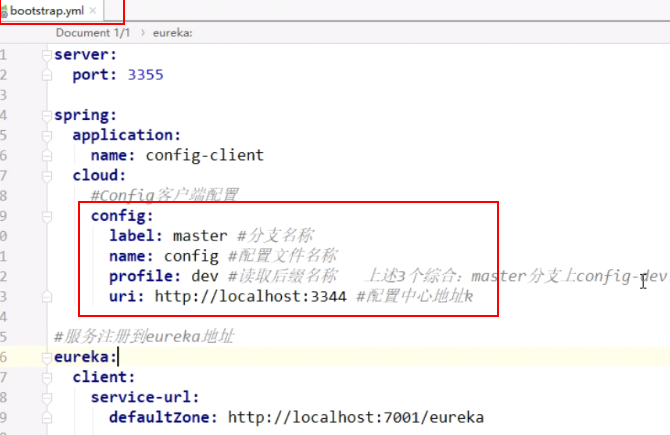
Bootstrap.yml,从外部加载配置,是系统级配置,而application.yml是用户级配置,优先级高于application.yml
SpirngcloudAlibaba

Nacos=Eureka+Config+Bus
nacos支持CP和AP模式的切换,如果需要保存服务的一些信息,则需要使用CP模式,否则就是AP模式
Sentinel实现熔断和限流
配置Sentinel
限流注解

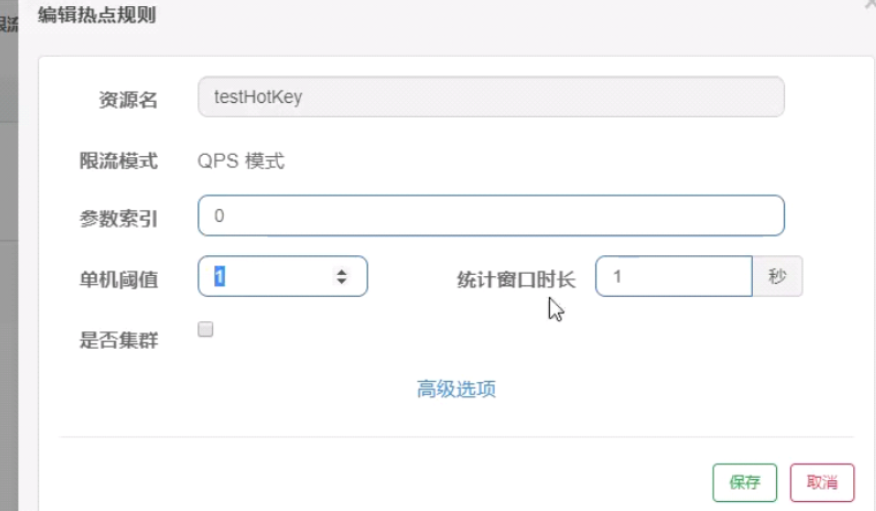
如果超过设置的阈值,则会走到配置的熔断方法,如果没有配置熔断方法,则达到阈值后直接抛异常
例外项:
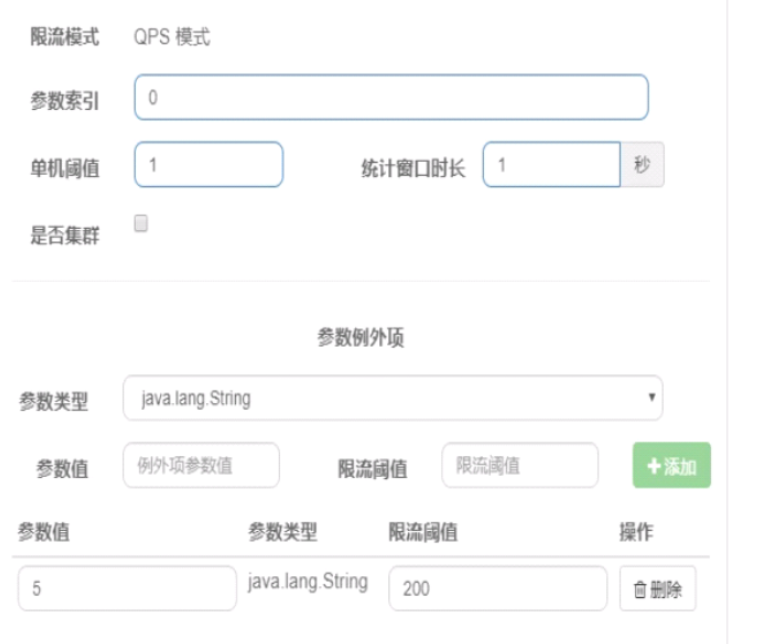

系统规则:从整个系统出发

自定义限流处理逻辑

忽略属性,指定的异常不处理

规则持久化: 因为每次重启应用,sentinel中的规则都会消失,所有需要持久化
持久化到nacos:

增加到nacos的依赖

配置yml
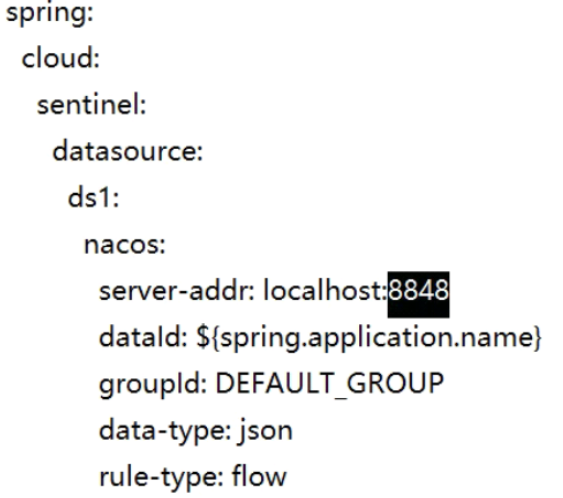

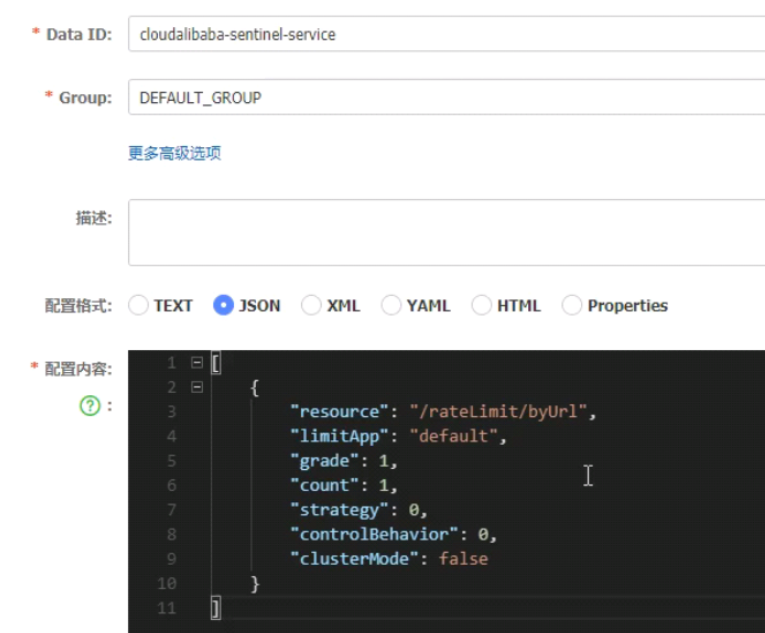
将限流配置到nacos的配置文件中
分布式事务Seata
一次业务操作需要跨多个数据源或需要多个系统进行远程调用,就会产生分布式事务
seata是阿里开源的分布式事务框架,
由一+三的套件组成
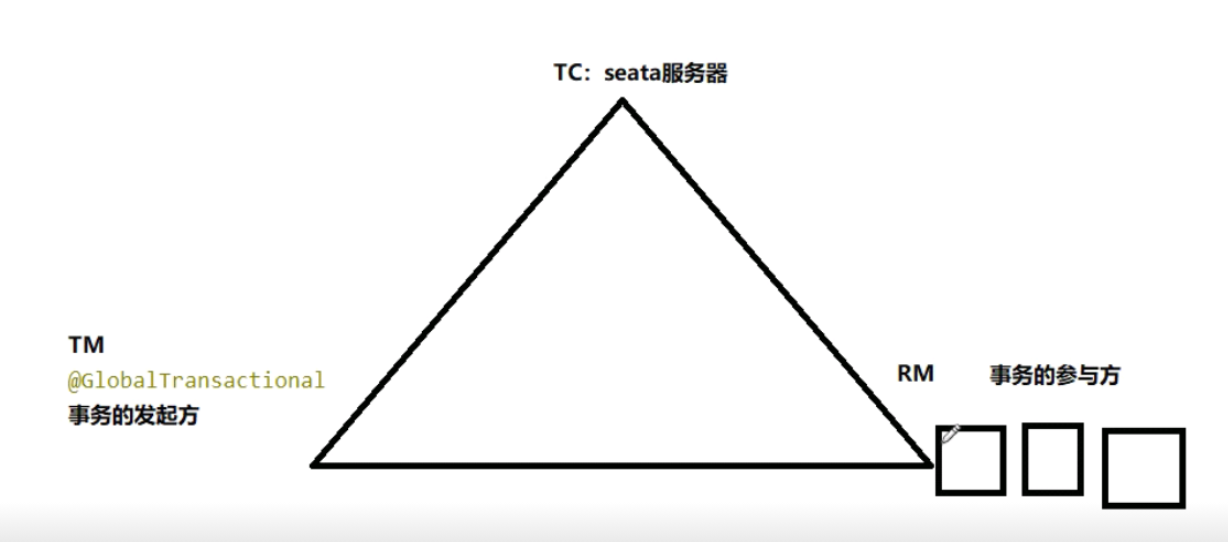
全局唯一事务Id
TC-事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚
TM-事务管理器
定义全局事务的范围,开始全局事务,提交或回滚全局事务
RM-资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务的提交或回滚
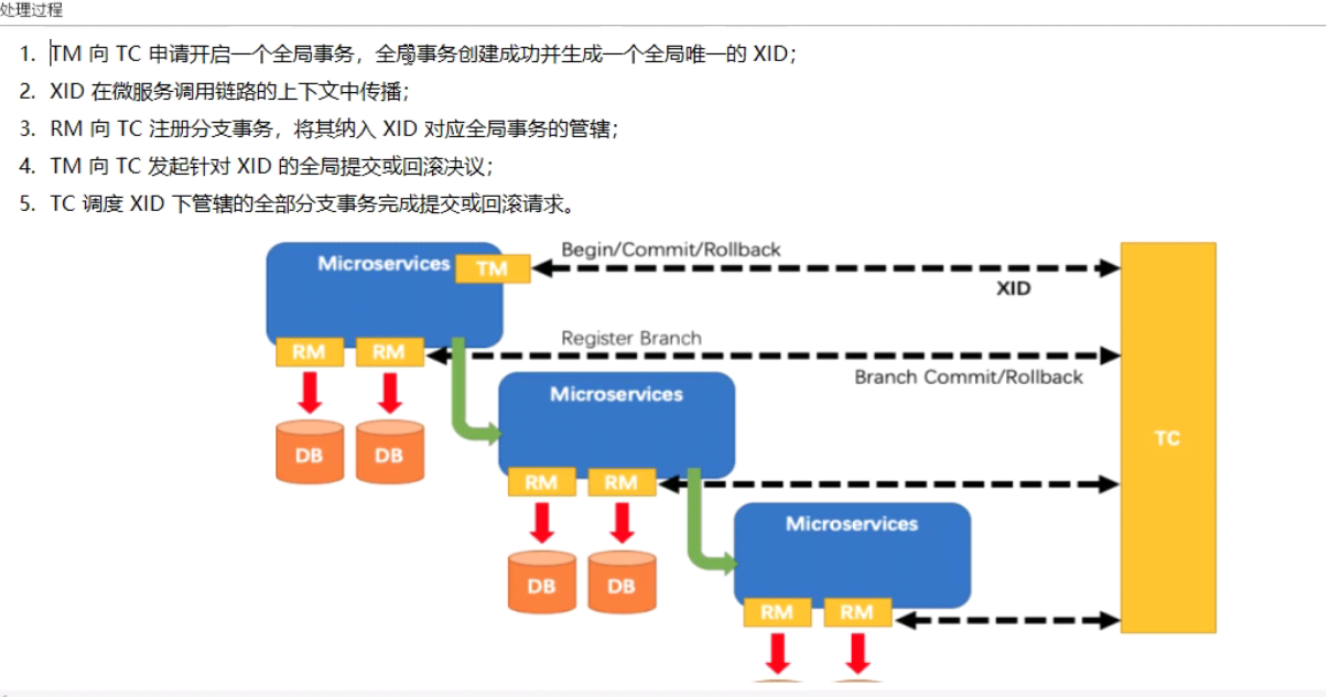
seata原理
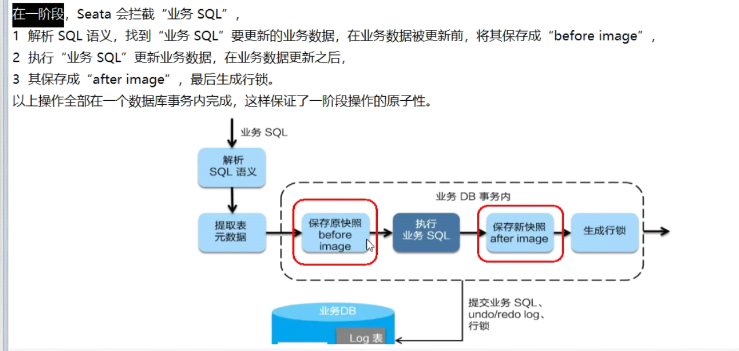
第一阶段
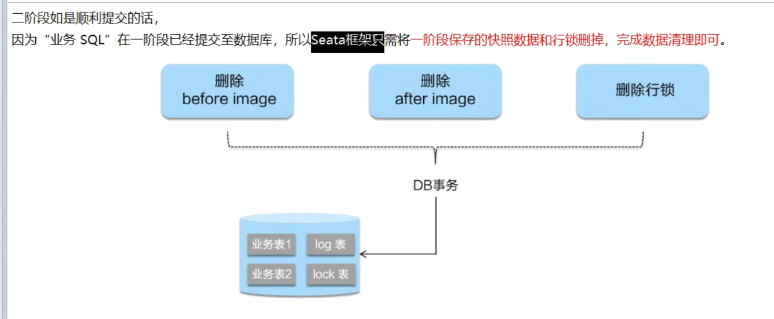
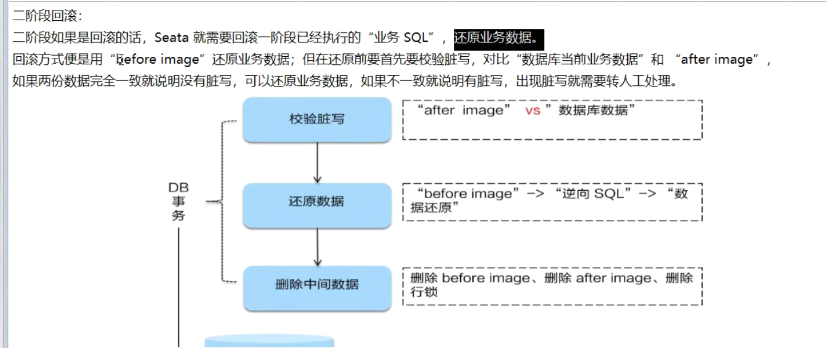
第二阶段

分布式唯一id生成方法
1.使用uuid 缺点: 无序,占用空间大,而且用到数据库做主键的话索引太大,频繁更新的话效率太低
2.使用数据库自增主键 使用replace into,首先尝试插入数据列表,如果列表中已经有数据,则删除后再插入,满足不了高可用,所以不是很合适
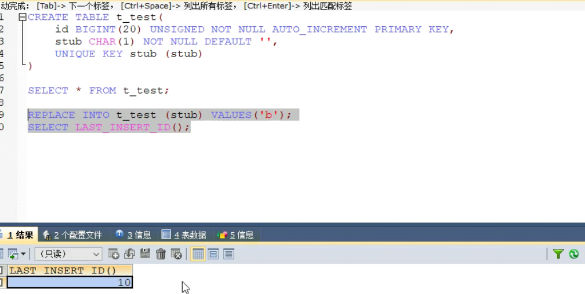


3.使用redis生成全局id
redis天生保证原子性,可以使用原子操作INCR和INCRBY

4.使用雪花算法



引入hutool工具包,直接使用,依赖机器时钟,初始值可以传入ip地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号