读书笔记-实战jvm虚拟机
第一章 初探java虚拟机
系统虚拟机: Visual Box Vmware
程序虚拟机: JVM
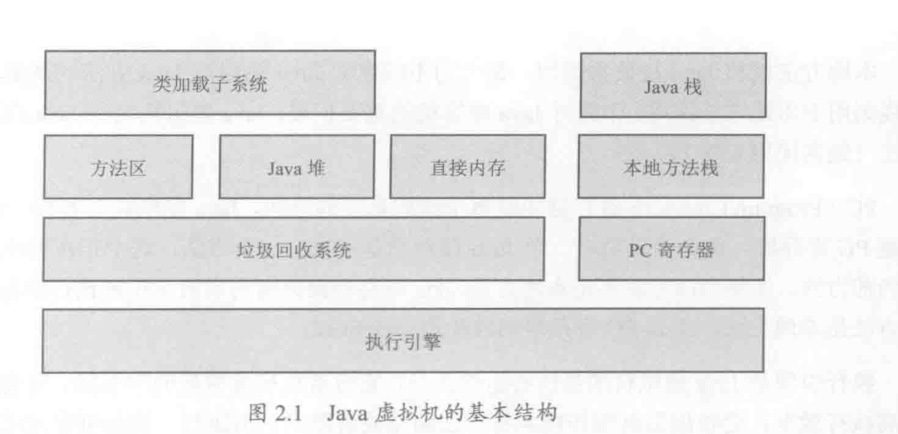
类加载子系统: 负责从文件系统或者网络加载Class信息,加载的类信息放在了方法区,方法区还会存一些运行时的常量信息,包括字符串常量和数字常量
java堆: 虚拟机启动时建立,是java程序最主要的工作区域,存放所有的类实例,堆空间是所有线程共享的
直接内存: java中的nio库允许java程序使用直接内存, 读写频繁的场合适合使用直接内存
垃圾回收系统: 对方法区,java堆和直接内存进行回收
java栈: 每个线程有一个私有的java栈, java栈保存局部变量,方法参数等
本地方法栈: 用于本地方法调用
PC寄存器: 每个线程的私有空间,一般pc寄存器会指向当前正在被执行的指令,如果当前执行的是本地方法,则寄存器就是undefined
- java堆
常见构成:将java堆分成新生代+老年代
新生代: eden区,s0区,s1区,也叫from区和to区
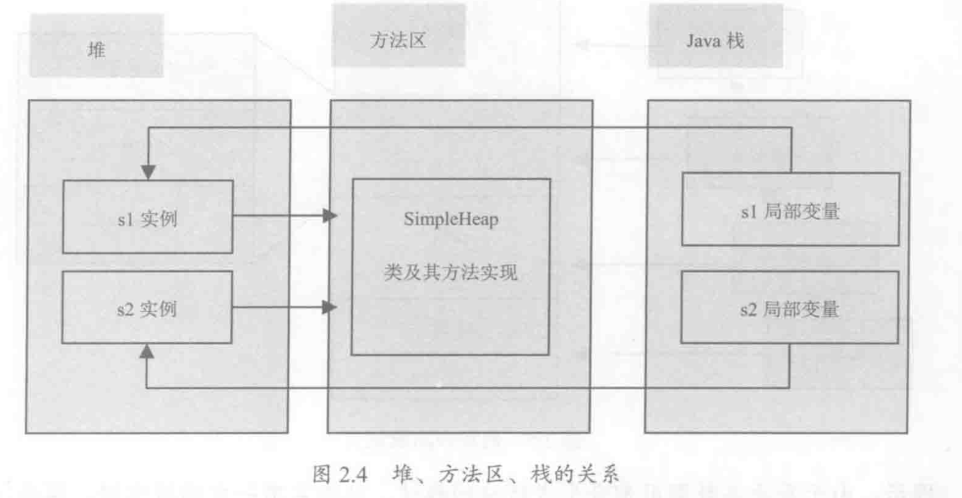
public class SimpleHeap {
private int id;
public SimpleHeap(int id) {
this.id = id;
}
public static void main(String[] args) {
SimpleHeap s1 = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
s1.show();
s2.show();
}
public void show() {
System.out.println("My ID is " + id);
}
}
-
堆,方法区,栈的关系
-
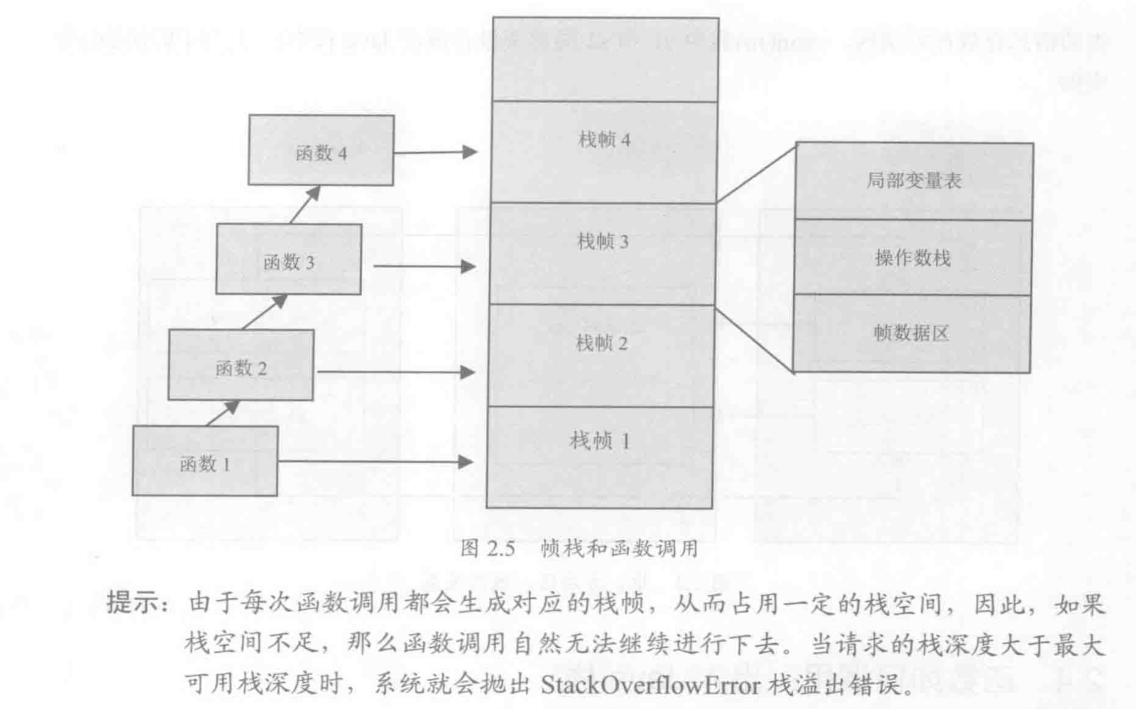
线程执行的基本行为是函数调用,每次函数调用的数据都是通过java栈传递的

public class TestStackDeep {
private static int count = 0;
public static void recursion(long a, long b, long c) {
long e = 1, f = 2, g = 3, h = 4, i = 5, k = 6, q = 7, x = 8, y = 9, z = 10;
count++;
recursion(a, b, c);
}
public static void recursion() {
count++;
recursion();
}
public static void main(String args[]) {
try {
recursion(0L, 0L, 0L);//1
//recursion();//2
} catch (Throwable e) {
System.out.println("deep of calling = " + count);
e.printStackTrace();
}
}
}
- 当方法中的参数比较多时,能够递归的层数就变少
- 局部变量表: 用于保存函数的参数以及局部变量,函数变量表只在当前函数调用中有效,函数调用结束后,局部变量表就销毁
- 相同栈容量下,局部变量少的函数可以支持更深的函数调用
第三章 常用Java虚拟机参数
- -XX:+PrintGC 简单的GC日志输出
[GC (Allocation Failure) 53572K->8476K(182272K), 0.0054765 secs]
[GC (Metadata GC Threshold) 50764K->9340K(178176K), 0.0085938 secs]
[Full GC (Metadata GC Threshold) 9340K->8998K(139776K), 0.1062219 secs]
- -XX:+PrintGCDetails 详细日志输出
[GC (Allocation Failure) [PSYoungGen: 67696K->7344K(80896K)] 76693K->16341K(172032K), 0.0067267 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Metadata GC Threshold) [PSYoungGen: 29302K->7728K(81920K)] 38299K->16725K(173056K), 0.0072769 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[Full GC (Metadata GC Threshold) [PSYoungGen: 7728K->0K(81920K)] [ParOldGen: 8997K->16190K(141312K)] 16725K->16190K(223232K), [Metaspace: 35128K->35128K(1075200K)], 0.0834686 secs] [Times: user=0.50 sys=0.00, real=0.08 secs]
-
类加载/卸载 跟踪: 有的class文件是利用反射产生,无法通过文件系统找到
-
-XX:+TraceClassUnloading 和 -XX:+TraceClassLoading 跟踪类的加载和卸载过程
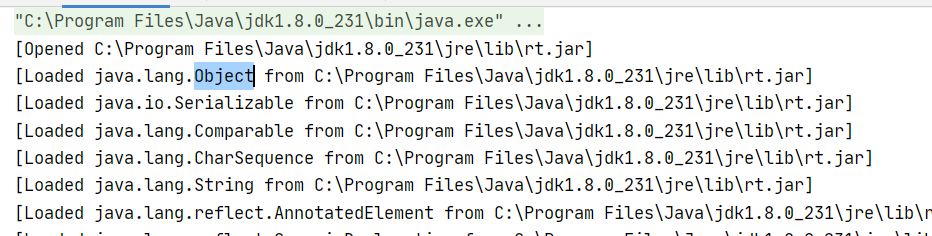
首先加载Object类
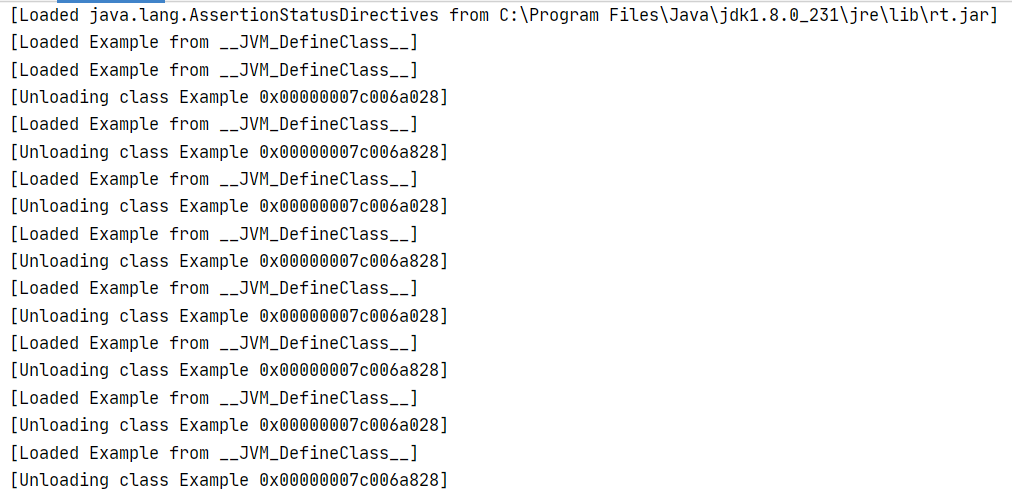
对Example类进行反复加载和卸载 -
-XX:+PrintVMOptions 程序运行时,打印虚拟机接收到的命令行参数
输出格式:
VM option '+PrintVMOptions'
VM option '+PrintGC'
- -XX:+PrintCommandLineFlags 可以打印显式和隐式参数,其中隐式参数是虚拟机自己设置的
-XX:InitialHeapSize=199409344 -XX:MaxHeapSize=3190549504 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
其中大部分参数都是虚拟机设置的
-
新生代的配置:新生代的大小一般设置为整个堆空间的1/3到1/4左右
-
-XX:SurvivorRatio 用来设置新生代中eden空间和from/to空间比例关系 eg: -XX:SurvivorRatio=eden/from=eden/to
-
使用不同的堆分配参数执行该段程序,虚拟机的表现不一样
-
基本策略: 尽可能将对象留在新生代,减少老年代GC次数


-
-Xss 指定栈大小
-
直接内存读写比jvm内存快,但是申请的时候比jvm内存慢
-
虚拟机工作模式:client和server, 用java -version可以看到是哪种模式
第四章 垃圾回收概念与算法
引用计数法: 只要有任何一个对象引用了A,则A的引用计算器就加1,引用失效后就减1,只要A的引用计算器值为0,则A就不可能再被使用
缺点: 1)无法统计循环引用 2)每次增加和减少引用都要伴随一个加法或者减法操作

标记清除: 两个阶段: 标记阶段和清除阶段 标记:通过根节点,标记所有从根节点开始的可达对象, 清除:清除所有未被标记的对象
缺点: 产生空间碎片
复制算法: 将空间分为两块,每次只使用其中一块,垃圾回收时,将存活对象复制到未被使用的内存块中,然后清除原来的内存块
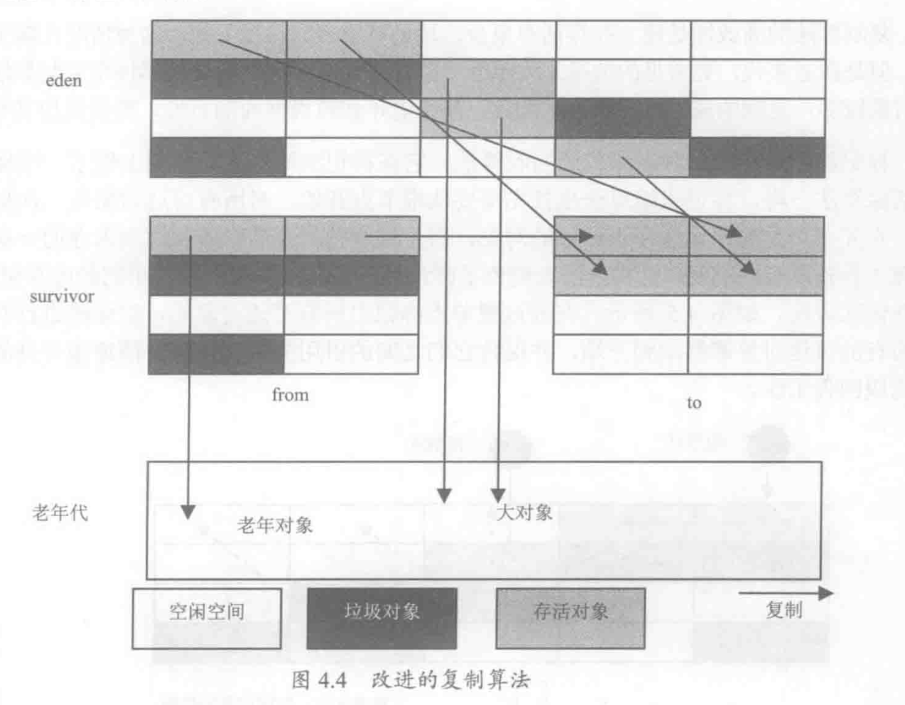

- 一般复制算法用在年轻代,因为年轻代对象存活数量少,但是老年代不适合用复制算法,因为老年代存活的对象多,复制代价大
标记压缩法: 从根节点出发,堆可达对象做标记,然后将这些对象压缩到内存的另外一边,将剩余的对象清除,可以避免碎片的产生,也不需要两块相同的内存空间
- 四个级别的引用: 强引用,软引用,弱引用,虚引用
- 强引用: StringBuffer str = new StringBuffer("Hello World");
- 软引用:
public class SoftRef {
public static void main(String[] args) {
User u = new User(1, "geym");
SoftReference<User> userSoftRef = new SoftReference<User>(u);
u = null;
System.out.println(userSoftRef.get());
System.gc();
System.out.println("After GC:");
System.out.println(userSoftRef.get());
byte[] b = new byte[1024 * 925 * 7];
System.gc();
System.out.println(userSoftRef.get());
}
public static class User {
public int id;
public String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "[id=" + String.valueOf(id) + ",name=" + name + "]";
}
}
}
软引用会在内存不足的时候被回收
- 每一个软引用都可以附带一个引用队列,当对象可达性发生改变时,由可达变成不可达,软引用对象会进入引用队列,通过这个引用队列,可以跟踪对象的回收情况
弱引用-发现即回收,在系统GC时,只要发现弱引用,马上回收,由于垃圾回收器的线程级别低,不一定马上能回收,但是一旦开始回收,就会将这个对象放入引用队列中

虚引用:随时都可以能被垃圾回收器回收,当试图通过get()方法取得强引用会失败
当垃圾回收器准备回收一个对象时,如果发现还有虚引用,就会在回收对象后将这个虚引用加入到引用队列,以便通知程序对象回收情况
如果软引用和弱引用被GC回收,JVM就会把这个引用加到引用队列里,如果是虚引用,在回收前就会被加到引用队列里。
垃圾回收器种类
- 串行收集器
- 并行收集器
- CMS回收器
- G1回收器
- 串行收集器: 使用单线程进行垃圾回收的回收器,每次回收只有一个工作线程,对并行性能弱的机器性能表现更好,
- 串行收集器可以分为新生代和老年代串行回收器
新生代串行回收器: 使用单线程回收,独占式回收,在回收的时候程序都要暂停,使用复制算法 -XX:+UseSerialGC 指定使用新生代和老年代串行收集器
老年代串行回收器: 使用标记压缩算法,因为老年代对象比较多,所以启动后可能停顿时间比较长
-XX:+UseSerialGC 新生代和老年代都用串行回收器
-XX:+UseParNewGC 新生代用ParNew,老年代用串行回收器
-XX:+UseParallelGC 新生代使用ParallelGC回收器,老年代用串行收集器
-XX:+UseConcMarkSweepGC 新生代使用ParNew回收器,老年代用CMS
新生代ParNew回收器: 只是简单的将串行收集器并行化
新生代ParallelGC回收器:也是使用复制算法的回收器,比ParNew更关注吞吐量,支持自适应的GC调节策略
-XX:+UseParallelGC: 新生代用ParallelGC 老年代用串行回收器
-XX:+UseParallelOldGC: 新生代用ParallelGC回收器,老年代用ParallelOldGC回收器
控制吞吐量的参数:
-XX:MaxGCPauseMillis: 设置最大垃圾收集停顿时间
-XX:GCTimeRatio: 设置吞吐量大小,0到100之间
老年代ParallelOldGC回收器
跟新生代的ParallelGC一样也是关注吞吐量的收集器: 使用标记压缩算法
-XX:ParallelGCThreads: 设置垃圾回收时的线程数量
CMS收集器: 主要关注停顿时间的收集器
并发标记删除: 初始标记,并发标记,预清理,重新标记,并发清除,并发重置.其中初始标记,并发标记是独占系统资源,预清理,重新标记,并发清除,并发重置是可以和用户线程一起执行
-XX:+UseConcMarkSweepGC 启用CMS回收器
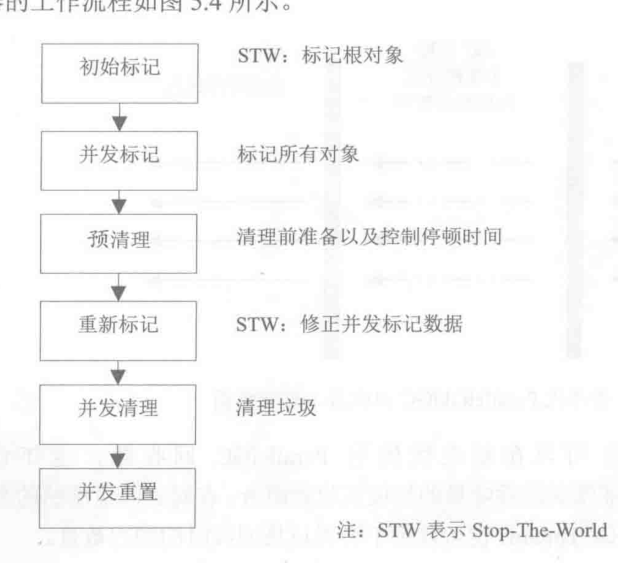


日志:
[CMS-concurrent-abortable-preclean: 0.420/0.424 secs] [Times: user=0.42 sys=0.00, real=0.42 secs]
[GC (CMS Final Remark) [YG occupancy: 33152 K (59008 K)][Rescan (parallel) , 0.0021553 secs][weak refs processing, 0.0000082 secs][class unloading, 0.0003782 secs][scrub symbol table, 0.0003757 secs][scrub string table, 0.0001182 secs][1 CMS-remark: 141244K(150496K)] 174397K(209504K), 0.0031253 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[CMS-concurrent-sweep-start]
- CMS-concurrent-abortable-preclean 表示进行一次新生代回收
G1收集器: 为了替代CMS收集器
- G1收集器使用分区算法,G1将堆分成一个个区,每次收集的时候只收集其中几个区域,所以可以控制每次收集的停顿时间

- G1收集4个阶段:
- 新生代GC
- 并发标记周期
- 混合收集
- 如果需要,则进行FullGC


2)



相关参数汇总:





第八章 锁与并发
- 偏向锁: 一个锁被线程获取后,便进入偏向模式,当线程再次请求这个锁时无需再进行同步操作,如果在此期间有其他线程进行了锁请求,则退出偏向锁模式
- -XX:+UseBiasedLocking 开启偏向锁
public class Biased {
public static List<Integer> numberList = new Vector<Integer>();
public static void main(String[] args) throws InterruptedException {
long begin = System.currentTimeMillis();
int count = 0;
int startnum = 0;
while (count < 10000000) {
numberList.add(startnum);
startnum += 2;
count++;
}
long end = System.currentTimeMillis();
System.out.println(end - begin);
}
}

启动参数:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 -client -Xmx512m -Xms512m



-
自旋锁



-
应用层锁优化策略
1.只有在必要的时候才使用锁,减少使用锁的代码面积
2.减少锁粒度,如使用ConcurrentHashMap
3.锁分离
4.锁粗化

-
无锁

-
原子操作

-
java内存模型:规范多线程下对共享资源的操作方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号