
Set集合架构和常用实现类的源码分析以及实例应用
说明:Set的实现类都是基于Map来实现的(HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的)。
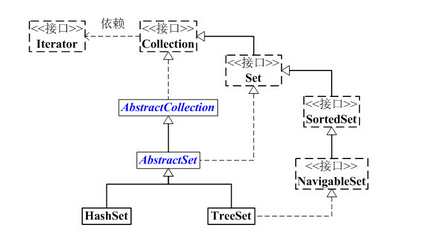
(01) Set 是继承于Collection的接口。它是一个不允许有重复元素的集合。
(02) AbstractSet 是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了Set中的绝大部分函数,为Set的实现类提供了便利。
(03) HastSet 和 TreeSet 是Set的两个实现类。
HashSet依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的。
TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是有序的。
1、具体实现类之HashSet的介绍
1.1、HashSet的简介
HashSet 是一个没有重复元素的集合。
它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。如果多个线程同时访问一个hashset,而其中至少一个线程修改了该 hashset,那么它必须保持外部同步。这通常是通过对自然封装该 set
的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装”
set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问
1 Set s = Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()返回的迭代器是通过fail-fast机制检测错误的。
1.2、HashSet的数据结构
1 java.lang.Object 2 ↳ java.util.AbstractCollection<E> 3 ↳ java.util.AbstractSet<E> 4 ↳ java.util.HashSet<E> 5 6 public class HashSet<E> 7 extends AbstractSet<E> 8 implements Set<E>, Cloneable, java.io.Serializable { }
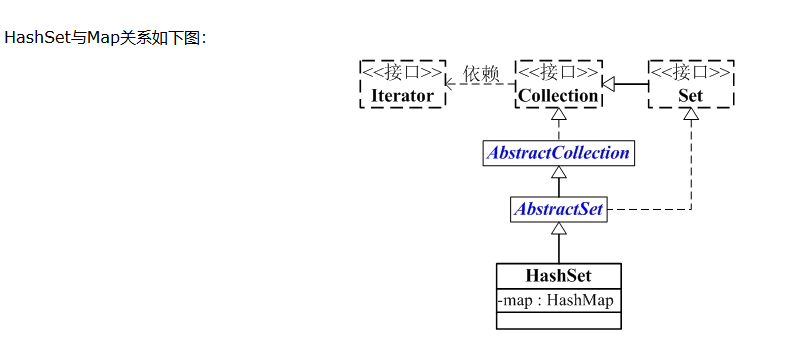
从图中可以看出:
(01) HashSet继承于AbstractSet,并且实现了Set接口。
(02) HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的
1.3、HashSet的源码分析


1 package java.util; 2 3 public class HashSet<E> 4 extends AbstractSet<E> 5 implements Set<E>, Cloneable, java.io.Serializable 6 { 7 static final long serialVersionUID = -5024744406713321676L; 8 9 // HashSet是通过map(HashMap对象)保存内容的 10 private transient HashMap<E,Object> map; 11 12 // PRESENT是向map中插入key-value对应的value 13 // 因为HashSet中只需要用到key,而HashMap是key-value键值对; 14 // 所以,向map中添加键值对时,键值对的值统一固定都是PRESENT 15 private static final Object PRESENT = new Object(); 16 17 // 默认构造函数 18 public HashSet() { 19 // 调用HashMap的默认构造函数,创建map 20 map = new HashMap<E,Object>(); 21 } 22 23 // 带集合的构造函数 24 public HashSet(Collection<? extends E> c) { 25 // 创建map。 26 // 为什么要调用Math.max((int) (c.size()/.75f) + 1, 16),从 (c.size()/.75f) + 1 和 16 中选择一个比较大的树呢? 27 // 首先,说明(c.size()/.75f) + 1 28 // 因为从HashMap的综合效率(时间成本和空间成本)考虑,并且HashMap的加载因子是0.75。 29 // 当HashMap的“阈值”(阈值=HashMap总的大小*加载因子) < “HashMap实际大小”时, 30 // 就需要通过refrash将HashMap的容量翻倍。 31 // 所以,(c.size()/.75f) + 1 计算出来的正好是总的空间大小。 32 // 接下来,说明为什么是 16 。 33 // HashMap的总的大小,必须是2的指数倍。若创建HashMap时,指定的大小不是2的指数倍; 34 // HashMap的构造函数中也会重新计算,找出比“指定大小”大且还是最小的2的指数倍的数。 35 // 所以,这里指定为16是从性能考虑。避免重复计算。 36 map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16)); 37 // 将集合(c)中的全部元素添加到HashSet中 38 addAll(c); 39 } 40 41 // 指定HashSet初始容量和加载因子的构造函数 42 public HashSet(int initialCapacity, float loadFactor) { 43 map = new HashMap<E,Object>(initialCapacity, loadFactor); 44 } 45 46 // 指定HashSet初始容量的构造函数 47 public HashSet(int initialCapacity) { 48 map = new HashMap<E,Object>(initialCapacity); 49 } 50 51 HashSet(int initialCapacity, float loadFactor, boolean dummy) { 52 map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor); 53 } 54 55 // 返回HashSet的迭代器 56 public Iterator<E> iterator() { 57 // 实际上返回的是HashMap的“key集合的迭代器”,还是一个Set集合 58 return map.keySet().iterator(); 59 } 60 61 public int size() { 62 return map.size(); 63 } 64 65 public boolean isEmpty() { 66 return map.isEmpty(); 67 } 68 69 public boolean contains(Object o) { 70 return map.containsKey(o); 71 } 72 73 // 将元素(e)添加到HashSet中 74 public boolean add(E e) { 75 return map.put(e, PRESENT)==null; 76 } 77 78 // 删除HashSet中的元素(o) 79 public boolean remove(Object o) { 80 return map.remove(o)==PRESENT; 81 } 82 83 public void clear() { 84 map.clear(); 85 } 86 87 // 克隆一个HashSet,并返回Object对象 88 public Object clone() { 89 try { 90 HashSet<E> newSet = (HashSet<E>) super.clone(); 91 newSet.map = (HashMap<E, Object>) map.clone(); 92 return newSet; 93 } catch (CloneNotSupportedException e) { 94 throw new InternalError(); 95 } 96 } 97 98 // java.io.Serializable的写入函数 99 // 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中 100 private void writeObject(java.io.ObjectOutputStream s) 101 throws java.io.IOException { 102 // Write out any hidden serialization magic 103 s.defaultWriteObject(); 104 105 // Write out HashMap capacity and load factor 106 s.writeInt(map.capacity()); 107 s.writeFloat(map.loadFactor()); 108 109 // Write out size 110 s.writeInt(map.size()); 111 112 // Write out all elements in the proper order. 113 for (Iterator i=map.keySet().iterator(); i.hasNext(); ) 114 s.writeObject(i.next()); 115 } 116 117 118 // java.io.Serializable的读取函数 119 // 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出 120 private void readObject(java.io.ObjectInputStream s) 121 throws java.io.IOException, ClassNotFoundException { 122 // Read in any hidden serialization magic 123 s.defaultReadObject(); 124 125 // Read in HashMap capacity and load factor and create backing HashMap 126 int capacity = s.readInt(); 127 float loadFactor = s.readFloat(); 128 map = (((HashSet)this) instanceof LinkedHashSet ? 129 new LinkedHashMap<E,Object>(capacity, loadFactor) : 130 new HashMap<E,Object>(capacity, loadFactor)); 131 132 // Read in size 133 int size = s.readInt(); 134 135 // Read in all elements in the proper order. 136 for (int i=0; i<size; i++) { 137 E e = (E) s.readObject(); 138 map.put(e, PRESENT); 139 } 140 } 141 }
说明:HashSet的代码实际上非常简单,通过上面的注释应该很能够看懂。它是通过HashMap实现的,若对HashSet的理解有困难,建议先学习以下HashMap;学完HashMap之后,在学习HashSet就非常容易了
1.4、HashSet的遍历方式
通过Iterator遍历HashSet
1 // 假设set是HashSet对象 2 for(Iterator iterator = set.iterator(); 3 iterator.hasNext(); ) { 4 iterator.next(); 5 }
通过for-each遍历HashSet
1 // 假设set是HashSet对象,并且set中元素是String类型 2 String[] arr = (String[])set.toArray(new String[0]); 3 for (String str:arr) 4 System.out.printf("for each : %s\n", str);
1.5、HashSet的常用API测试实例
1 import java.util.Random; 2 import java.util.Iterator; 3 import java.util.HashSet; 4 5 /* 6 * @desc 介绍HashSet遍历方法 7 * 8 * @author skywang 9 */ 10 public class HashSetIteratorTest { 11 12 public static void main(String[] args) { 13 // 新建HashSet 14 HashSet set = new HashSet(); 15 16 // 添加元素 到HashSet中 17 for (int i=0; i<5; i++) 18 set.add(""+i); 19 20 // 通过Iterator遍历HashSet 21 iteratorHashSet(set) ; 22 23 // 通过for-each遍历HashSet 24 foreachHashSet(set); 25 } 26 27 /* 28 * 通过Iterator遍历HashSet。推荐方式 29 */ 30 private static void iteratorHashSet(HashSet set) { 31 for(Iterator iterator = set.iterator(); 32 iterator.hasNext(); ) { 33 System.out.printf("iterator : %s\n", iterator.next()); 34 } 35 } 36 37 /* 38 * 通过for-each遍历HashSet。不推荐!此方法需要先将Set转换为数组 39 */ 40 private static void foreachHashSet(HashSet set) { 41 String[] arr = (String[])set.toArray(new String[0]); 42 for (String str:arr) 43 System.out.printf("for each : %s\n", str); 44 } 45 }
1 iterator : 3 2 iterator : 2 3 iterator : 1 4 iterator : 0 5 iterator : 4 6 for each : 3 7 for each : 2 8 for each : 1 9 for each : 0 10 for each : 4
2、具体实现类之TreeSet的介绍
2.1、HashSet的简介
TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet<E>, Cloneable, java.io.Serializable接口。
TreeSet 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
TreeSet 实现了Cloneable接口,意味着它能被克隆。
TreeSet 实现了java.io.Serializable接口,意味着它支持序列化。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
TreeSet为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
2.2、HashSet的数据结构
1 java.lang.Object 2 ↳ java.util.AbstractCollection<E> 3 ↳ java.util.AbstractSet<E> 4 ↳ java.util.TreeSet<E> 5 6 public class TreeSet<E> extends AbstractSet<E> 7 implements NavigableSet<E>, Cloneable, java.io.Serializable{}
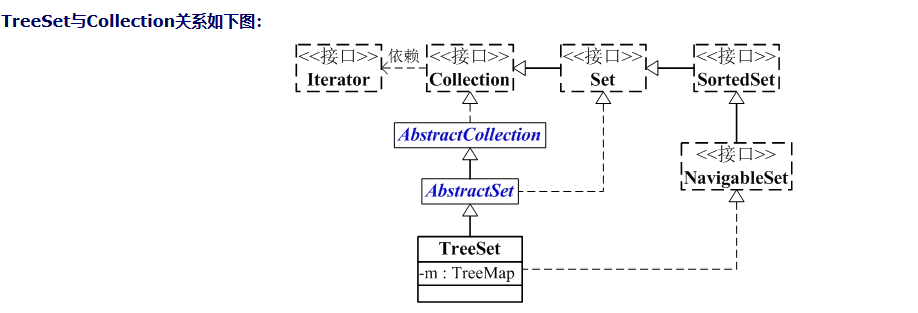
(01) TreeSet是有序的Set集合,因此支持add、remove、get等方法。
(02) 和NavigableSet一样,TreeSet的导航方法大致可以区分为两类,一类时提供元素项的导航方法,返回某个元素;另一类时提供集合的导航方法,返回某个集合。
lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。
2.3、HashSet的源码分析
1 package java.util; 2 3 public class TreeSet<E> extends AbstractSet<E> 4 implements NavigableSet<E>, Cloneable, java.io.Serializable 5 { 6 // NavigableMap对象 7 private transient NavigableMap<E,Object> m; 8 9 // TreeSet是通过TreeMap实现的, 10 // PRESENT是键-值对中的值。 11 private static final Object PRESENT = new Object(); 12 13 // 不带参数的构造函数。创建一个空的TreeMap 14 public TreeSet() { 15 this(new TreeMap<E,Object>()); 16 } 17 18 // 将TreeMap赋值给 "NavigableMap对象m" 19 TreeSet(NavigableMap<E,Object> m) { 20 this.m = m; 21 } 22 23 // 带比较器的构造函数。 24 public TreeSet(Comparator<? super E> comparator) { 25 this(new TreeMap<E,Object>(comparator)); 26 } 27 28 // 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中 29 public TreeSet(Collection<? extends E> c) { 30 this(); 31 // 将集合c中的元素全部添加到TreeSet中 32 addAll(c); 33 } 34 35 // 创建TreeSet,并将s中的全部元素都添加到TreeSet中 36 public TreeSet(SortedSet<E> s) { 37 this(s.comparator()); 38 addAll(s); 39 } 40 41 // 返回TreeSet的顺序排列的迭代器。 42 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 43 public Iterator<E> iterator() { 44 return m.navigableKeySet().iterator(); 45 } 46 47 // 返回TreeSet的逆序排列的迭代器。 48 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 49 public Iterator<E> descendingIterator() { 50 return m.descendingKeySet().iterator(); 51 } 52 53 // 返回TreeSet的大小 54 public int size() { 55 return m.size(); 56 } 57 58 // 返回TreeSet是否为空 59 public boolean isEmpty() { 60 return m.isEmpty(); 61 } 62 63 // 返回TreeSet是否包含对象(o) 64 public boolean contains(Object o) { 65 return m.containsKey(o); 66 } 67 68 // 添加e到TreeSet中 69 public boolean add(E e) { 70 return m.put(e, PRESENT)==null; 71 } 72 73 // 删除TreeSet中的对象o 74 public boolean remove(Object o) { 75 return m.remove(o)==PRESENT; 76 } 77 78 // 清空TreeSet 79 public void clear() { 80 m.clear(); 81 } 82 83 // 将集合c中的全部元素添加到TreeSet中 84 public boolean addAll(Collection<? extends E> c) { 85 // Use linear-time version if applicable 86 if (m.size()==0 && c.size() > 0 && 87 c instanceof SortedSet && 88 m instanceof TreeMap) { 89 SortedSet<? extends E> set = (SortedSet<? extends E>) c; 90 TreeMap<E,Object> map = (TreeMap<E, Object>) m; 91 Comparator<? super E> cc = (Comparator<? super E>) set.comparator(); 92 Comparator<? super E> mc = map.comparator(); 93 if (cc==mc || (cc != null && cc.equals(mc))) { 94 map.addAllForTreeSet(set, PRESENT); 95 return true; 96 } 97 } 98 return super.addAll(c); 99 } 100 101 // 返回子Set,实际上是通过TreeMap的subMap()实现的。 102 public NavigableSet<E> subSet(E fromElement, boolean fromInclusive, 103 E toElement, boolean toInclusive) { 104 return new TreeSet<E>(m.subMap(fromElement, fromInclusive, 105 toElement, toInclusive)); 106 } 107 108 // 返回Set的头部,范围是:从头部到toElement。 109 // inclusive是是否包含toElement的标志 110 public NavigableSet<E> headSet(E toElement, boolean inclusive) { 111 return new TreeSet<E>(m.headMap(toElement, inclusive)); 112 } 113 114 // 返回Set的尾部,范围是:从fromElement到结尾。 115 // inclusive是是否包含fromElement的标志 116 public NavigableSet<E> tailSet(E fromElement, boolean inclusive) { 117 return new TreeSet<E>(m.tailMap(fromElement, inclusive)); 118 } 119 120 // 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。 121 public SortedSet<E> subSet(E fromElement, E toElement) { 122 return subSet(fromElement, true, toElement, false); 123 } 124 125 // 返回Set的头部,范围是:从头部到toElement(不包括)。 126 public SortedSet<E> headSet(E toElement) { 127 return headSet(toElement, false); 128 } 129 130 // 返回Set的尾部,范围是:从fromElement到结尾(不包括)。 131 public SortedSet<E> tailSet(E fromElement) { 132 return tailSet(fromElement, true); 133 } 134 135 // 返回Set的比较器 136 public Comparator<? super E> comparator() { 137 return m.comparator(); 138 } 139 140 // 返回Set的第一个元素 141 public E first() { 142 return m.firstKey(); 143 } 144 145 // 返回Set的最后一个元素 146 public E first() { 147 public E last() { 148 return m.lastKey(); 149 } 150 151 // 返回Set中小于e的最大元素 152 public E lower(E e) { 153 return m.lowerKey(e); 154 } 155 156 // 返回Set中小于/等于e的最大元素 157 public E floor(E e) { 158 return m.floorKey(e); 159 } 160 161 // 返回Set中大于/等于e的最小元素 162 public E ceiling(E e) { 163 return m.ceilingKey(e); 164 } 165 166 // 返回Set中大于e的最小元素 167 public E higher(E e) { 168 return m.higherKey(e); 169 } 170 171 // 获取第一个元素,并将该元素从TreeMap中删除。 172 public E pollFirst() { 173 Map.Entry<E,?> e = m.pollFirstEntry(); 174 return (e == null)? null : e.getKey(); 175 } 176 177 // 获取最后一个元素,并将该元素从TreeMap中删除。 178 public E pollLast() { 179 Map.Entry<E,?> e = m.pollLastEntry(); 180 return (e == null)? null : e.getKey(); 181 } 182 183 // 克隆一个TreeSet,并返回Object对象 184 public Object clone() { 185 TreeSet<E> clone = null; 186 try { 187 clone = (TreeSet<E>) super.clone(); 188 } catch (CloneNotSupportedException e) { 189 throw new InternalError(); 190 } 191 192 clone.m = new TreeMap<E,Object>(m); 193 return clone; 194 } 195 196 // java.io.Serializable的写入函数 197 // 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中 198 private void writeObject(java.io.ObjectOutputStream s) 199 throws java.io.IOException { 200 s.defaultWriteObject(); 201 202 // 写入比较器 203 s.writeObject(m.comparator()); 204 205 // 写入容量 206 s.writeInt(m.size()); 207 208 // 写入“TreeSet中的每一个元素” 209 for (Iterator i=m.keySet().iterator(); i.hasNext(); ) 210 s.writeObject(i.next()); 211 } 212 213 // java.io.Serializable的读取函数:根据写入方式读出 214 // 先将TreeSet的“比较器、容量、所有的元素值”依次读出 215 private void readObject(java.io.ObjectInputStream s) 216 throws java.io.IOException, ClassNotFoundException { 217 // Read in any hidden stuff 218 s.defaultReadObject(); 219 220 // 从输入流中读取TreeSet的“比较器” 221 Comparator<? super E> c = (Comparator<? super E>) s.readObject(); 222 223 TreeMap<E,Object> tm; 224 if (c==null) 225 tm = new TreeMap<E,Object>(); 226 else 227 tm = new TreeMap<E,Object>(c); 228 m = tm; 229 230 // 从输入流中读取TreeSet的“容量” 231 int size = s.readInt(); 232 233 // 从输入流中读取TreeSet的“全部元素” 234 tm.readTreeSet(size, s, PRESENT); 235 } 236 237 // TreeSet的序列版本号 238 private static final long serialVersionUID = -2479143000061671589L; 239 }
总结:
(01) 通过阅读源码我们可以看出TreeSet实际上是基于TreeMap实现的。当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
(02) TreeSet是非线程安全的。
(03) TreeSet实现java.io.Serializable的方式。
当写入到输出流时,依次写入“比较器、容量、全部元素”;当读出输入流时,再依次读取
2.4、HashSet的遍历方式
Iterator顺序遍历
for(Iterator iter = set.iterator(); iter.hasNext(); ) {
iter.next();
}
Iterator顺序遍历
// 假设set是TreeSet对象
for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) {
iter.next();
}
for-each遍历HashSet
// 假设set是TreeSet对象,并且set中元素是String类型
String[] arr = (String[])set.toArray(new String[0]);
for (String str:arr)
System.out.printf("for each : %s\n", str);
注意:TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
2.5、HashSet的常用API测试实例
1 import java.util.*; 2 3 /** 4 * TreeSet的遍历程序 5 * 6 */ 7 public class TreeSetIteratorTest { 8 9 public static void main(String[] args) { 10 TreeSet set = new TreeSet(); 11 set.add("aaa"); 12 set.add("aaa"); 13 set.add("bbb"); 14 set.add("eee"); 15 set.add("ddd"); 16 set.add("ccc"); 17 18 // 顺序遍历TreeSet 19 ascIteratorThroughIterator(set) ; 20 // 逆序遍历TreeSet 21 descIteratorThroughIterator(set); 22 // 通过for-each遍历TreeSet。不推荐!此方法需要先将Set转换为数组 23 foreachTreeSet(set); 24 } 25 26 // 顺序遍历TreeSet 27 public static void ascIteratorThroughIterator(TreeSet set) { 28 System.out.print("\n ---- Ascend Iterator ----\n"); 29 for(Iterator iter = set.iterator(); iter.hasNext(); ) { 30 System.out.printf("asc : %s\n", iter.next()); 31 } 32 } 33 34 // 逆序遍历TreeSet 35 public static void descIteratorThroughIterator(TreeSet set) { 36 System.out.printf("\n ---- Descend Iterator ----\n"); 37 for(Iterator iter = set.descendingIterator(); iter.hasNext(); ) 38 System.out.printf("desc : %s\n", (String)iter.next()); 39 } 40 41 // 通过for-each遍历TreeSet。不推荐!此方法需要先将Set转换为数组 42 private static void foreachTreeSet(TreeSet set) { 43 System.out.printf("\n ---- For-each ----\n"); 44 String[] arr = (String[])set.toArray(new String[0]); 45 for (String str:arr) 46 System.out.printf("for each : %s\n", str); 47 } 48 }
1 ---- Ascend Iterator ---- 2 asc : aaa 3 asc : bbb 4 asc : ccc 5 asc : ddd 6 asc : eee 7 8 ---- Descend Iterator ---- 9 desc : eee 10 desc : ddd 11 desc : ccc 12 desc : bbb 13 desc : aaa 14 15 ---- For-each ---- 16 for each : aaa 17 for each : bbb 18 for each : ccc 19 for each : ddd 20 for each : eee


