vgg&pytorch&fenlri
# softmax 将实数值转换为概率值
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers , Sequential , datasets , optimizers , models , regularizers
import numpy as np
#零均值归一化
def normalize(X_train, X_test):
X_train = X_train / 255.
X_test = X_test / 255.
mean = np.mean(X_train, axis=(0, 1, 2, 3))
std = np.std(X_train, axis=(0, 1, 2, 3))
print('mean:', mean, 'std:', std)
X_train = (X_train - mean) / (std + 1e-7)
X_test = (X_test - mean) / (std + 1e-7)
return X_train, X_test
#读取数据
(x_train,y_train), (x_test, y_test) = datasets.cifar10.load_data()
(x_train.shape,y_train.shape), (x_test.shape, y_test.shape)
#归一化数据
x_train, x_test = normalize(x_train, x_test)
# y本身就是标签值(0~9)所以不用进行归一化,只需要做one_hot处理即可
def preprocess(x, y):
x = tf.cast(x, tf.float32 )#转换为tftensor
y = tf.cast(y, tf.int32) #转换为tftensor
y = tf.squeeze(y, axis=1) # 注意y是50000,1但是我们希望y直接是batchsize,所以要把1挤压掉
y = tf.one_hot(y, depth=10) # 做hone_hot编码
return x, y
# 训练样本
train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train))
train_db = train_db.shuffle(50000).batch(128).map(preprocess)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(50000).batch(128).map(preprocess)
# 由于VGG 16对于这个数据集表现很差,于是做如下改进
num_classes = 10 #如果是imagenet数据集,这里为1000
weight_decay = 0.000
model = models.Sequential() #构造容器
#第一层
model.add(
layers.Conv2D(64,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.3)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(64,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
#第二层
model.add(
layers.Conv2D(128,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(128,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.MaxPooling2D(pool_size=(2,2)))
#第三层
model.add(
layers.Conv2D(256,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(256,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(256,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers. MaxPooling2D(pool_size=(2,2)))
#第四层
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers. MaxPooling2D(pool_size=(2,2)))
#第五层
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.4)) # 丢弃一部分神经元,防止过拟合
model.add(
layers.Conv2D(512,(3,3),
padding='same',
kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Dropout(0.5)) # 丢弃一部分神经元,防止过拟合
#拉平
#将三个全神经网络改成两个
model.add(layers.Flatten())
model.add(layers.Dense(512,kernel_regularizer = regularizers.l2(weight_decay))) #做一个l2正则化
model.add(layers.Activation('relu'))
model.add(layers.BatchNormalization()) #BN 层
model.add(layers.Dropout(0.5)) # 丢弃一部分神经元,防止过拟合
model.add(layers.Dense(num_classes))# VGG 16 为1000
model.add(layers.Activation('softmax'))
model.build(input_shape=(None,32,32,3))
model.summary()
# 优化器
model.compile(optimizer=keras.optimizers.Adam(0.0001),
loss = keras.losses.CategoricalCrossentropy(from_logits=True),#加上from_logits=True之后,训练会得到更好的结果
metrics=['accuracy'])
history = model.fit(train_db,epochs=50)
#能保存模型结构
path = 'saved_model_VGG/'
model.save(path, save_format='tf')
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.title("model loss")
plt.ylabel("1oss" )
plt.xlabel("epoch")
plt.show()
model.evaluate(test_db)
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 32
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
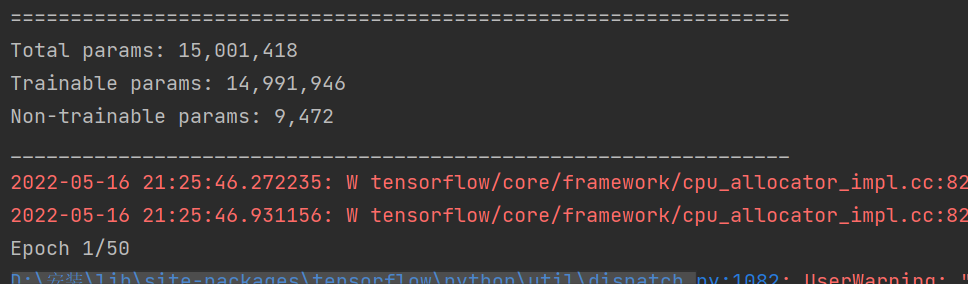
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# Get cpu or gpu device for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
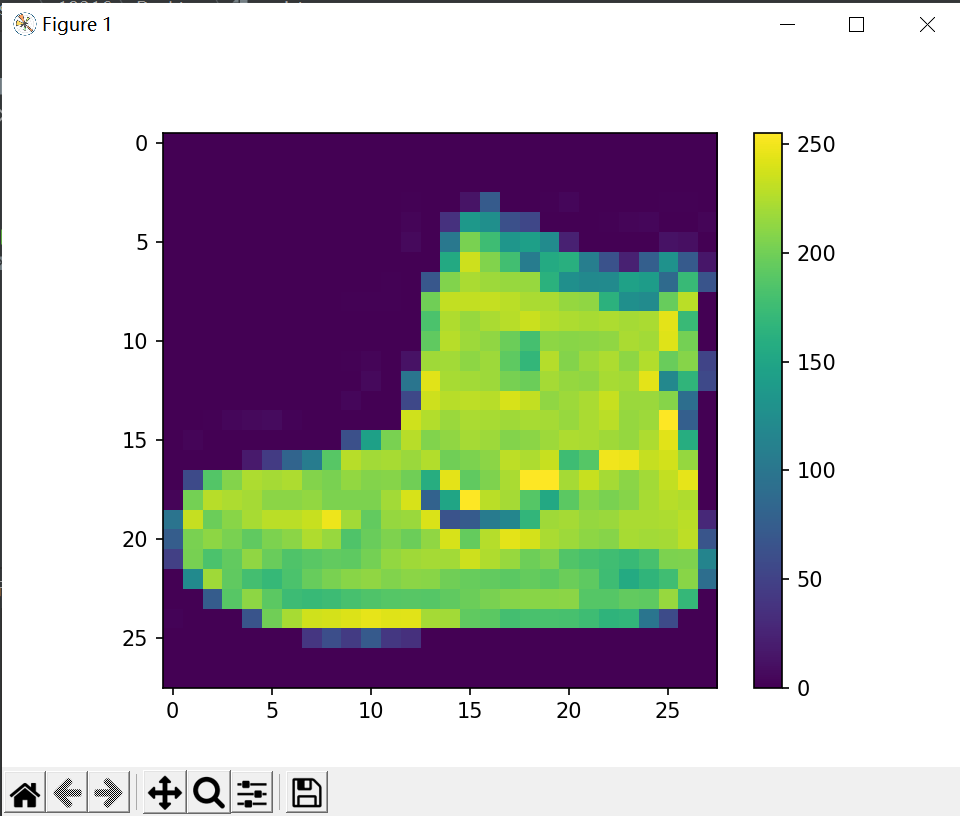
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10)
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()