
这就是搜索引擎--读书笔记一
这就是搜索引擎 -- 读书笔记一
相信搜索引擎对于每一个爱好算法甚至爱好技术的IT人员都具有强烈的好奇心吧,因为搜索引擎在互联网中的地位实在是不可撼动。想象如果互联网没有了搜索引擎,那么我们平常技术上出现瓶颈了怎么办?甚至连普通的生活都离不开搜索,大学生的你订餐了吗?
搜索引擎已经发展为每个人上网都离不开的重要工具,其技术发展历程是怎样的呢?其基本目标是什么?核心技术问题又是什么呢?在接下来的一系列博文中,我会根据读书和自己的总结用平乏的语言来表达出来,希望对朋友们有所帮助。另外,博友们如果有好的相关资源,也感谢留言。
今天,我给大家讲解一下搜索引擎及其技术架构的基础知识,让我们对搜索引擎有一个大致的了解。
商业搜索引擎公司的发展
在信息量快速增长的情况下,如何能够找到满足用户需求的网页内容就日益成为越来越重要的问题。信息增长速度越快,用户需求越迫切,相应的搜索结果就越要准确。大的搜索引擎公司就是在这个用户需求背景下,从建立到逐步壮大,乃至发展到今天搜索引擎成为最重要的互联网的应用。
早期时候,随着互联网的进一步的快速发展,信息的爆炸性增长,已有的搜索引擎服务提供商所提供的搜索服务质量并无大的改善。Google于1998年成立,以PageRank链接分析等新技术大幅度提高了搜索质量,之后高速发展并抢占了绝大多数的搜索引擎市场,成为目前最重要的互联网之一。想想为什么搜索引擎公司这么看重搜索技术?就拿大学生订餐这一事情来说,够实际吧,如果你订餐时查询到的前3页搜索结果都是已经售完了的饭菜品,那么此时饥饿的你感受如何?相信你连揍死店家的冲动都有。在另外一家外卖店的首页上,搜索第一条就是很新鲜的菜品,你会选择哪一家外卖店呢?
搜索引擎技术发展史
从搜索引擎所采取的技术来说,可以将搜索引擎技术的发展划分为4个阶段:分类目录、文本检索、链接分析和用户中心。
史前时代:分类目录的一代
这个时代可以称为“导航时代”,Yahoo和国内hao123是这个时代的代表。通过人工收集整理,把属于各个类别的高质量网站或者网页分门别类罗列,用户可以根据分级目录来查找高质量的网站。这种方式是纯人工、最原始的方式,并未采取什么高深的技术手段。
第一代:文本检索的一代
文本检索的一代采用经典的信息检索模型,比如布尔模型、向量空间模型或者概率模型,来计算用户查询关键词和网页文本内容的相关程度。网页之间有丰富的链接关系,而这一代搜索引擎并未使用这些信息。早期的很多搜索引擎比如AltaVista、Excite等大都采取这种模式。
第二代:链接分析的一代
这一代的搜索引擎充分利用了网页之间的链接关系,并深入挖掘和利用了网页链接所代表的含义。通常而言,网页链接代表了一种推荐关系,所以通过链接分析可以在海量内容中找出重要的网页。这种重要性本质上是对网页流行程度的一种衡量,因为被推荐次数多的网页其实代表了其具有流行性。搜索引擎通过结合网页流行性和内容相似性来改善搜索质量。
我们都知道Google率先提出并使用PageRank链接分析技术,并大获成功,这同时引起了学术界和其他商业搜索引擎的关注。后来学术界陆续提出了很多改进的链接分析算法。目前几乎所有的商业搜索引擎都采用了链接分析技术。
采用链接分析能够有效改善搜索结果质量,但是这种搜索引擎并未考虑用户的个性化要求,所以只要输入的查询请求相同,所有用户都会获得相同的搜索结果。另外,很多网站拥有者为了获得更高的搜索排名,针对链接分析算法提出了不少链接作弊方案,这样导致了搜索结果质量变差。
第三代:用户中心的一代
目前的搜索引擎大都可以归入第三代,即以理解用户需求为核心。不同用户即使输入同一个查询关键词,但其目的也有可能不一样。比如同样输入“苹果”作为查询词,一个追捧IPhone的时尚青年和一个果农的目的会有相当大的差距。而目前搜索引擎大部分致力于解决如下问题:如何能够理解用户发出的某个很短小的查询词背后包含的真正需求,所以这一代搜索引擎称之为以用户为中心的一代。
搜索引擎的技术架构
作为互联网应用中最具技术含量的应用之一,优秀的搜索引擎需要复杂的架构和算法,以此来支撑对海量数据的获取、存储、以及对用户查询的快速而准确的相应。
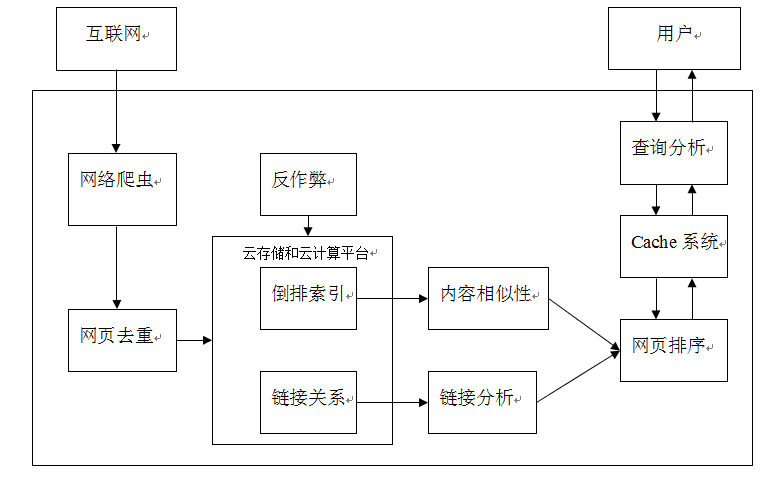
我们来看看这个搜索引擎的基础架构:
搜索引擎的信息源自于互联网的网页,通过网络爬虫将整个互联网的信息获取到本地,因为互联网页面中有相当大比例的内容是完全相同或者近似重复的,“网页去重”模块会对此做出检测,并去除重复内容。
在此之后,搜索引擎会对网页进行解析,抽取出网页主题内容,以及页面中包含的指向其他页面的链接。为了加快响应用户查询的速度,网页内容通过“倒排索引”这种高效查询数据结构来保存,而网页之间的链接关系也会予以保存。之所以要保存链接关系,是因为这种关系在网页相关性排序阶段是可利用的,通过“链接分析”可以判断页面的相对重要性,对于为用户提供准确的搜索结果帮助很大。
当搜索引擎接收到用户的查询词后,首先需要对查询词进行分析,希望能够结合查询词和用户信息来正确推到用户的真正搜索意图。在此之后,首先在缓存中查找,搜索引擎的缓存系统存储了不同的查询意图对应的搜索结果,如果能够在缓存系统找到满足用户需求的信息,则可以直接将搜索结果返回给用户,这样既省掉了重复计算对资源的消耗,又加快了响应速度;如果保存在缓存的信息无法满足用户需求,搜索引擎需要调用“网页排序”模块功能,根据用户的查询实时计算哪些网页是满足用户信息需求的,并排序输出作为搜索结果。而网页排序最重要的两个参考因素中,一个是内容相似性因素,即哪些网页是和用户查询密切相关的;另外一个是网页重要性因素,即哪些网页是质量较好或相对重要的,这点往往可以从链接分析的结果获得。结合以上两个考虑因素,就可以对网页进行排序,作为用户查询的搜索结果。
后话
如今,除了上述的子功能模块,搜索引擎的“反作弊”模块成为日益重要的功能。搜索引擎作为互联网用户的上网入口,对于网络流量的引导与分流至关重要,甚至可以说起了决定性作用。
因此,作为IT人员或者即将进入IT行业的童鞋们,我们都应该对搜索引擎有一些基本的认识。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步