
Hadoop HDFS负载均衡
Hadoop HDFS负载均衡
转载请注明出处:http://www.cnblogs.com/BYRans/
Hadoop HDFS
Hadoop 分布式文件系统(Hadoop Distributed File System),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件系统。它和现有的分布式文件系统有很多的共同点。HDFS 是一个高容错性的文件系统,提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
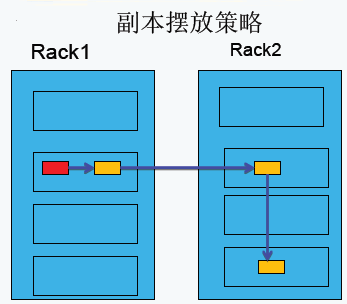
HDFS副本摆放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
需要注意的是:
- HDFS中存储的文件的副本数由上传文件时设置的副本数决定。无论以后怎么更改系统副本系数,这个文件的副本数都不会改变;
- 在上传文件时优先使用启动命令中指定的副本数,如果启动命令中没有指定则使用hdfs-site.xml中dfs.replication设置的默认值;
HDFS负载均衡
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
Hadoop HDFS数据负载均衡原理
数据均衡过程的核心是一个数据均衡算法,该数据均衡算法将不断迭代数据均衡逻辑,直至集群内数据均衡为止。该数据均衡算法每次迭代的逻辑如下:
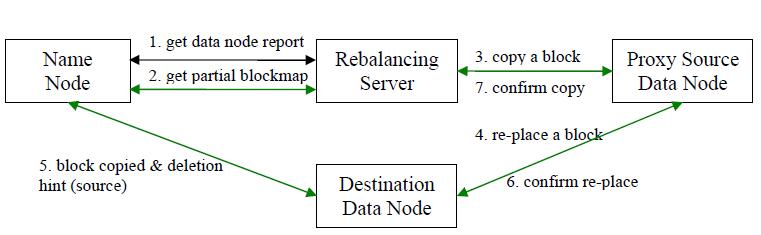
步骤分析如下:
- 数据均衡服务(Rebalancing Server)首先要求 NameNode 生成 DataNode 数据分布分析报告,获取每个DataNode磁盘使用情况
- Rebalancing Server汇总需要移动的数据分布情况,计算具体数据块迁移路线图。数据块迁移路线图,确保网络内最短路径
- 开始数据块迁移任务,Proxy Source Data Node复制一块需要移动数据块
- 将复制的数据块复制到目标DataNode上
- 删除原始数据块
- 目标DataNode向Proxy Source Data Node确认该数据块迁移完成
- Proxy Source Data Node向Rebalancing Server确认本次数据块迁移完成。然后继续执行这个过程,直至集群达到数据均衡标准
**DataNode分组** 在第2步中,HDFS会把当前的DataNode节点,根据阈值的设定情况划分到Over、Above、Below、Under四个组中。在移动数据块的时候,Over组、Above组中的块向Below组、Under组移动。四个组定义如下:
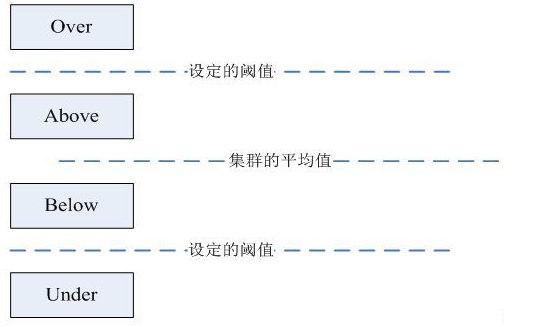
- Over组:此组中的DataNode的均满足
DataNode_usedSpace_percent > Cluster_usedSpace_percent + threshold
- Above组:此组中的DataNode的均满足
Cluster_usedSpace_percent + threshold > DataNode_ usedSpace _percent > Cluster_usedSpace_percent
- Below组:此组中的DataNode的均满足
Cluster_usedSpace_percent > DataNode_ usedSpace_percent > Cluster_ usedSpace_percent – threshold
- Under组:此组中的DataNode的均满足
Cluster_usedSpace_percent – threshold > DataNode_usedSpace_percent
Hadoop HDFS 数据自动平衡脚本使用方法
在Hadoop中,包含一个start-balancer.sh脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。\(Hadoop_Home/bin 目录下的 start-balancer.sh 脚本就是该任务的启动脚本。
启动命令为:`\)Hadoop_home/bin/start-balancer.sh –threshold
影响Balancer的几个参数:
- -threshold
- 默认设置:10,参数取值范围:0-100
- 参数含义:判断集群是否平衡的阈值。理论上,该参数设置的越小,整个集群就越平衡
- dfs.balance.bandwidthPerSec
- 默认设置:1048576(1M/S)
- 参数含义:Balancer运行时允许占用的带宽
示例如下:
#启动数据均衡,默认阈值为 10%
$Hadoop_home/bin/start-balancer.sh
#启动数据均衡,阈值 5%
bin/start-balancer.sh –threshold 5
#停止数据均衡
$Hadoop_home/bin/stop-balancer.sh
在hdfs-site.xml文件中可以设置数据均衡占用的网络带宽限制
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号