
python爬虫(二)
一、BeautifulSoup库的使用
1.对beautifulSoup库的理解
HTML文档可以看作是有很多个标签相互嵌套形成的“标签树”,而BeautifulSoup库是解析、遍历、维护“标签树”的功能库。
2.BeautifulSoup库的基本使用
#HTML文档《==》标签树《==》BeautifulSoup类 from bs4 import BeautifulSoup soup=BeautifulSoup("<html>data</html>","html.parser") #“html.parser”是beautiflSoup库解析器 soup2=BeautifulSoup(open("D://demo.html"),"html.parser")
BeautifulSoup对应一个HTML/XML文档的全部内容
3.BeautifulSoup库解析器
- bs4的HTML解析器:BeautifulSoup(mk,"html.paarser"),需安装bs4库
- lxml的解析器:BeautifulSoup(mk,"lxml"),需安装lxml库
- lxml的解析器:BeautifulSoup(mk,"xml"),需安装lxml库
- html5lib的解析器:BeautifulSoup(mk,"html5lib"),需安装html5lib库
4.BeautifulSoup类的基本元素
对HTML标签的内容的概括:

- Tag:标签,最基本的信息组织单元,分别用<></>标明开头和结尾。任何存在HTML语法中的标签可以通过soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个,bs4.element.Tag类型
- Name:标签的名字,<p>..</p>的名字是“p”,格式:<tag>.name,字符串类型
- Attributes:标签的属性,字典形式组织,格式:<tag>.attrs,字典类型
- NavigableString:标签内非属性字符串,<>..</>中字符串,格式:<tag>.string,bs4.element.NavifableString类型
- Comment:标签内字符串的注释部分,一种特殊的Comment类型,格式同上,bs4.element.Comment类型
例子:


<html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.title) #<title>This is a python demo page</title> print(type(soup.title)) #<class 'bs4.element.Tag'>
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.title.name) #title print(type(soup.title.name)) #<class 'str'>
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.a) #<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> print(soup.a.attrs) #{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'} print(type(soup.a.attrs)) #<class 'dict'> print(soup.a.attrs['href']) #http://www.icourse163.org/course/BIT-268001
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.p) #<p class="title"><b>The demo python introduces several python courses.</b></p> print(soup.p.string) #跨域获取,The demo python introduces several python courses. print(type(soup.p.string)) #<class 'bs4.element.NavigableString'>
demo="<b><!--The demo python introduces several python courses. --></b>" \ "<p>The demo python introduces several python courses.</p>" soup=BeautifulSoup(demo,"html.parser") print(soup.b) #<b><!--The demo python introduces several python courses. --></b> print(soup.b.string) #The demo python introduces several python courses. print(type(soup.b.string)) #<class 'bs4.element.Comment'> print(soup.p) #<p>The demo python introduces several python courses./p> print(soup.p.string) #The demo python introduces several python courses. print(type(soup.p.string)) #<class 'bs4.element.NavigableString'> #使用.string方法获取注释和非属性字符串内容得到的结果是相同的 #b和p标签的例子说明,可以利用标签内容的类型来区分注释和非属性字符串
5.标签树的遍历
(1)HTML基本格式
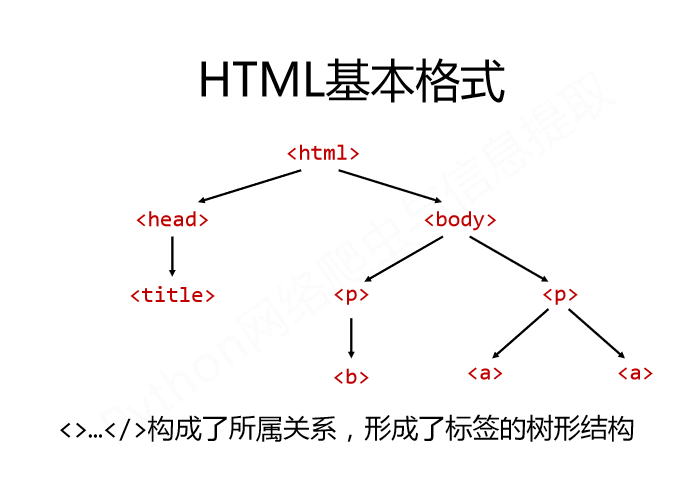
(2)标签树的下行遍历
- .contents:子节点的列表,将<tag>所有儿子节点存入列表
- .children:子节点的迭代类型,用于循环遍历儿子节点
- .descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.head) #<head><title>This is a python demo page</title></head> print(soup.head.contents) #[<title>This is a python demo page</title>]
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") for child in soup.body.children: print(child) #孩子中包括换行符、字符串 ''' <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> '''
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") for tag in soup.body.descendants: print(tag) ''' <p class="title"><b>The demo python introduces several python courses.</b></p> <b>The demo python introduces several python courses.</b> The demo python introduces several python courses. <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> Basic Python and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> Advanced Python . '''
(3)标签树的上行遍历
- .parent:节点的父亲标签
- .parents:节点先辈标签大的迭代类型,用于循环遍历先辈节点
例子:
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.a.parent) ''' <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> ''' print(soup.parent) #None
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.parent) #soup的父节点为空,但在遍历时不需要进行非空判断,parents函数内部帮我们进行了处理 for parent in soup.a.parents: print(parent.name) ''' None p body html [document] '''
(4)标签树的平行遍历
- .next_sibling:返回按照HTMl文本顺序的下一个平行节点标签
- .previous_sibling:返回按照HTML文本顺序的上一个平行节点标签
- .next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签.
- .previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
注:平行遍历发生在同一个父节点下的各节点间
例子:
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.a.previous_sibling) #Python is a wonderful general-purpose programming language. # You can learn Python from novice to professional by tracking the following courses: print(soup.a.next_sibling) # and
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") for sibling in soup.a.previous_siblings: print(sibling.name) print("===================") for sibling in soup.a.next_siblings: print(sibling.name) ''' None =================== None a None '''
标签树的遍历方法总结:
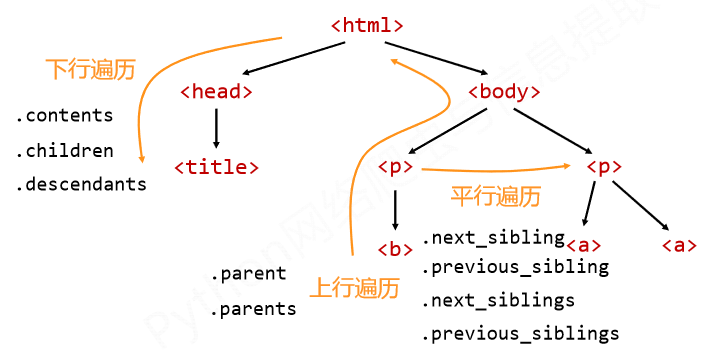
6.bs4库的HTML格式输出
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.prettify()) ''' <html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a> . </p> </body> </html> '''
7.bs4库的编码
bs4库将任何HTML输入都变成urf-8编码,python 3.x默认支持编码是utf-8,解析无障碍。
若使用python2.x则要进行相应的转码处理
二、信息标记与提取方法
1.信息标记的三种方式
(一) XML


(二) jSON



(三) YAML
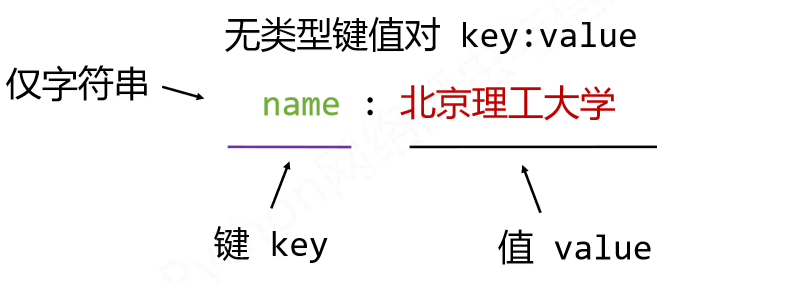



(四) 三种信息标记形式的比较
- XML:最早的通用信息标记语言,可扩展性好,但是非常繁琐。用于Internet上信息交互与传递
- JSON:信息有类型,适合程序处理,叫XML简洁。用于移动应用云端和节点的信息通信,无注释
- YAML:信息无类型,文本信息比例最高,可读性好。用于各类系统的配置文件,有注释易读
三种信息标记实例:



2.信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息。这种方法需要标记解析器,例如:bs4库 的标签树遍历。
优点:信息解析准确
缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息。对信息的文本调用相应的查找函数即可。
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容有关
方法三:结合形式解析与搜索方法,提取关键信息。需要标记解析器及文本查找函数。
实例:提取HTML中所有URL链接
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") for link in soup.find_all('a'): print(link.get('href')) #http://www.icourse163.org/course/BIT-268001 # http://www.icourse163.org/course/BIT-1001870001
3.基于bs4库的HTML内容查找方法
<>.find_all(name, attrs, recursive, string, **kwargs),返回一个列表类型,存储查找结果
- name:对标签名称的检索字符串
- attrs:对标签属性值的检索字符串,可标注属性检索
- recursive:是否对子孙全部检索,默认为True
- string:<>..</>中字符串区域的检索字符串
注:<tag>(..) 《==》 <tag>.find_all(..)
例子:
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.find_all("a")) print(soup.find_all(["a","b"])) ''' [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] [<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] '''
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.find_all('p',attrs='course')) print("====================") print(soup.find_all(attrs={'id':'link1'})) ''' <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>] ==================== [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>] '''
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.find_all('a',recursive=False)) #[]
import requests from bs4 import BeautifulSoup r=requests.get("http://python123.io/ws/demo.html") demo=r.text soup=BeautifulSoup(demo,"html.parser") print(soup.find_all(string="Basic Python")) #['Basic Python']
扩展方法:
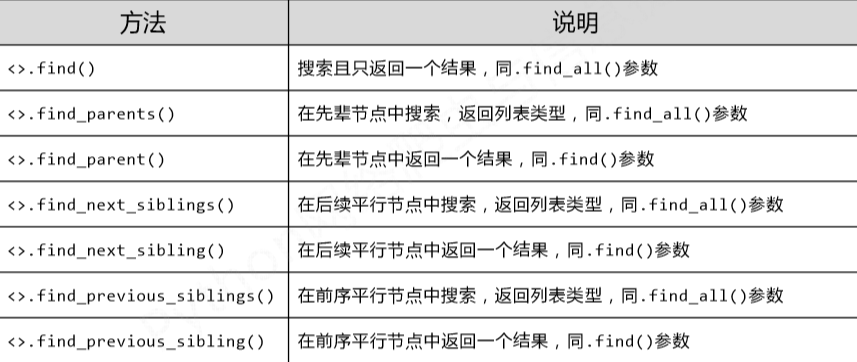
三、实例:中国大学排名定向爬虫
URL:http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html
网页信息:
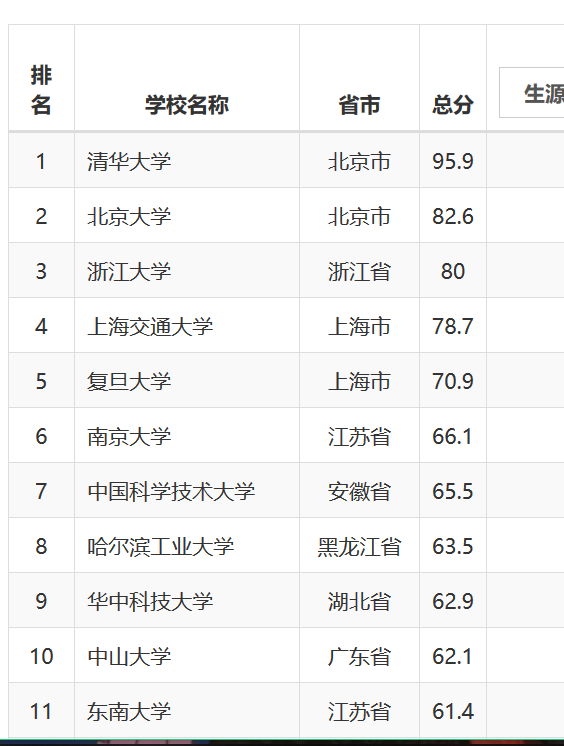
大学排名部分的HTML文本信息:
<tbody class="hidden_zhpm" style="text-align: center;"> <tr class="alt"> <td>1</td> <td> <div align="left">清华大学</div> </td> <td>北京</td> <td>95.3</td> <td class="hidden-xs need-hidden indicator5">100.0</td> <td class="hidden-xs need-hidden indicator6" style="display: none;">97.50%</td> <td class="hidden-xs need-hidden indicator7" style="display: none;">1182145</td> <td class="hidden-xs need-hidden indicator8" style="display: none;">44730</td> <td class="hidden-xs need-hidden indicator9" style="display: none;">1.447</td> <td class="hidden-xs need-hidden indicator10" style="display: none;">1556</td> <td class="hidden-xs need-hidden indicator11" style="display: none;">121</td> <td class="hidden-xs need-hidden indicator12" style="display: none;">1586283</td> <td class="hidden-xs need-hidden indicator13" style="display: none;">500525</td> <td class="hidden-xs need-hidden indicator14" style="display: none;">6.90%</td> </tr> <tr class="alt"> <td>2</td> <td> <div align="left">北京大学</div> </td> <td>北京</td> <td>78.6</td> <td class="hidden-xs need-hidden indicator5">96.4</td> <td class="hidden-xs need-hidden indicator6" style="display: none;">97.39%</td> <td class="hidden-xs need-hidden indicator7" style="display: none;">665616</td> <td class="hidden-xs need-hidden indicator8" style="display: none;">43731</td> <td class="hidden-xs need-hidden indicator9" style="display: none;">1.374</td> <td class="hidden-xs need-hidden indicator10" style="display: none;">1278</td> <td class="hidden-xs need-hidden indicator11" style="display: none;">94</td> <td class="hidden-xs need-hidden indicator12" style="display: none;">480918</td> <td class="hidden-xs need-hidden indicator13" style="display: none;">4110</td> <td class="hidden-xs need-hidden indicator14" style="display: none;">6.01%</td> </tr> <tr class="alt"> <td>3</td> <td> <div align="left">浙江大学</div> </td> <td>浙江</td> <td>73.9</td> <td class="hidden-xs need-hidden indicator5">86.3</td> <td class="hidden-xs need-hidden indicator6" style="display: none;">96.56%</td> <td class="hidden-xs need-hidden indicator7" style="display: none;">452414</td> <td class="hidden-xs need-hidden indicator8" style="display: none;">47915</td> <td class="hidden-xs need-hidden indicator9" style="display: none;">1.131</td> <td class="hidden-xs need-hidden indicator10" style="display: none;">939</td> <td class="hidden-xs need-hidden indicator11" style="display: none;">91</td> <td class="hidden-xs need-hidden indicator12" style="display: none;">1266561</td> <td class="hidden-xs need-hidden indicator13" style="display: none;">27720</td> <td class="hidden-xs need-hidden indicator14" style="display: none;">5.18%</td> </tr> <tr class="alt"> <td>4</td> <td> <div align="left">上海交通大学</div> </td> <td>上海</td> <td>73.1</td> <td class="hidden-xs need-hidden indicator5">90.5</td> <td class="hidden-xs need-hidden indicator6" style="display: none;">98.65%</td> <td class="hidden-xs need-hidden indicator7" style="display: none;">226279</td> <td class="hidden-xs need-hidden indicator8" style="display: none;">49749</td> <td class="hidden-xs need-hidden indicator9" style="display: none;">1.176</td> <td class="hidden-xs need-hidden indicator10" style="display: none;">960</td> <td class="hidden-xs need-hidden indicator11" style="display: none;">79</td> <td class="hidden-xs need-hidden indicator12" style="display: none;">742538</td> <td class="hidden-xs need-hidden indicator13" style="display: none;">15264</td> <td class="hidden-xs need-hidden indicator14" style="display: none;">7.33%</td> </tr> <!-- 后面的内容格式完全相同-->
功能描述:大学排名信息的屏幕输出(排名,大学名称、省份、总分)
定向爬虫:仅对输入URl进行爬取,不进行扩展爬取
#爬取中国最好大学排名网的学校学校排名数据 import requests,bs4 from bs4 import BeautifulSoup def getHTMLText(url): ''' 爬取网页 :param url: url :return: text ''' try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "" def fillUnivList(uList,demo): ''' 解析网页并将数据封装在列表中 :param uList: [] :param demo: html :return: [] ''' soup=BeautifulSoup(demo,"html.parser") for tr in soup.find('tbody', attrs={'class': "hidden_zhpm"}).children: #soup.tbody.children也可 if isinstance(tr,(bs4.element.Tag,)): tds=tr.find_all('td') uList.append([tds[0].string,tds[1].contents[0].string,tds[2].string,tds[3].string]) def printUnivList(uList,num): ''' 输出列表 :param uList: [] :param num: count :return: ''' tplt = "{0:^10s}\t\t{1:{4}^10s}\t\t{2:{5}^10s}\t\t{3:^10s}" print(tplt.format("排名", "学校名称","省份","总分",chr(12288),chr(12288))) for i in range(num): u = uList[i] print(tplt.format(u[0], u[1],u[2],u[3],chr(12288),chr(12288))) # print("排名\t\t学校名称\t\t省份\t\t总分") # for i in range(num): # u = uList[i] # print(u[0],"\t\t",u[1],"\t\t",u[2],"\t\t",u[3]) def inputCount(): ''' :return:university count ''' countUiv = input("输入您希望得到的排名数量[max:600]:") if not countUiv: print("输入不能为空!") else: if countUiv.isdigit(): countUiv = int(countUiv) if countUiv >= 600: print("数量超过600无效!") else: return countUiv else: print("请输入数字!") if __name__ == '__main__': url="http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html" uList=[] #存放大学排名信息 countUniv=inputCount() demo=getHTMLText(url) fillUnivList(uList,demo) printUnivList(uList,countUniv)
输出:
输入您希望得到的排名数量[max:600]:100
排名 学校名称 省份 总分
1 清华大学 北京 95.3
2 北京大学 北京 78.6
3 浙江大学 浙江 73.9
4 上海交通大学 上海 73.1
5 复旦大学 上海 66.0
6 中国科学技术大学 安徽 61.9
7 南京大学 江苏 59.8
8 华中科技大学 湖北 59.1
9 中山大学 广东 58.6
10 哈尔滨工业大学 黑龙江 57.4
11 同济大学 上海 56.4
12 武汉大学 湖北 55.5
13 东南大学 江苏 55.3
14 西安交通大学 陕西 54.2
15 北京航空航天大学 北京 54.0
16 南开大学 天津 53.9
17 四川大学 四川 53.3
18 天津大学 天津 52.4
19 华南理工大学 广东 51.8
20 北京师范大学 北京 51.7
21 北京理工大学 北京 51.1
22 厦门大学 福建 50.9
23 吉林大学 吉林 50.2
24 山东大学 山东 50.0
25 大连理工大学 辽宁 49.7
26 中南大学 湖南 49.5
27 苏州大学 江苏 48.8
28 对外经济贸易大学 北京 47.7
29 西北工业大学 陕西 47.6
30 中国人民大学 北京 47.5
31 湖南大学 湖南 47.4
32 华东师范大学 上海 46.5
33 电子科技大学 四川 46.4
34 华东理工大学 上海 45.5
35 重庆大学 重庆 45.2
35 南京航空航天大学 江苏 45.2
37 北京科技大学 北京 44.5
37 南京理工大学 江苏 44.5
39 上海财经大学 上海 44.3
40 中国农业大学 北京 43.7
41 上海大学 上海 43.6
42 东北大学 辽宁 43.5
43 华中师范大学 湖北 43.3
43 南方科技大学 广东 43.3
45 北京交通大学 北京 43.0
46 首都医科大学 北京 42.9
47 武汉理工大学 湖北 42.8
48 北京化工大学 北京 42.4
48 北京邮电大学 北京 42.4
48 东华大学 上海 42.4
51 北京外国语大学 北京 42.1
52 天津医科大学 天津 42.0
52 中央财经大学 北京 42.0
54 西安电子科技大学 陕西 41.9
55 南京医科大学 江苏 41.7
56 暨南大学 广东 41.6
57 兰州大学 甘肃 41.4
58 江南大学 江苏 40.8
59 华北电力大学 北京 40.5
60 中国海洋大学 山东 40.3
61 哈尔滨工程大学 黑龙江 40.2
61 中国地质大学(武汉) 湖北 40.2
63 华中农业大学 湖北 40.1
63 南京师范大学 江苏 40.1
65 东北师范大学 吉林 40.0
66 西南财经大学 四川 39.9
67 福州大学 福建 39.8
67 中国药科大学 江苏 39.8
69 中国地质大学(北京) 北京 39.7
70 上海外国语大学 上海 39.6
71 南京农业大学 江苏 39.5
72 北京工业大学 北京 39.2
72 河海大学 江苏 39.2
74 西南交通大学 四川 39.1
74 中国医科大学 辽宁 39.1
76 西南大学 重庆 39.0
77 南方医科大学 广东 38.8
77 中南财经政法大学 湖北 38.8
79 南京信息工程大学 江苏 38.4
80 江苏大学 江苏 38.3
80 中国石油大学(华东) 山东 38.3
82 合肥工业大学 安徽 38.2
83 上海中医药大学 上海 38.1
83 中国矿业大学 江苏 38.1
85 浙江工业大学 浙江 38.0
86 北京中医药大学 北京 37.9
86 华侨大学 福建 37.9
86 西北农林科技大学 陕西 37.9
89 北京林业大学 北京 37.8
89 东北财经大学 辽宁 37.8
91 南京邮电大学 江苏 37.7
91 深圳大学 广东 37.7
91 中央民族大学 北京 37.7
94 南京工业大学 江苏 37.6
94 中国政法大学 北京 37.6
96 大连医科大学 辽宁 37.5
97 中国石油大学(北京) 北京 37.3
98 西北大学 陕西 37.2
98 中国传媒大学 北京 37.2
100 宁波大学 浙江 36.8
