
OO第一次博客作业
OO第一单元的三周练习,使我收获颇多,这篇博客记录了第一单元作业中的自我分析与反思,欢迎大家批评指正。
基于度量的程序结构分析
第一次作业
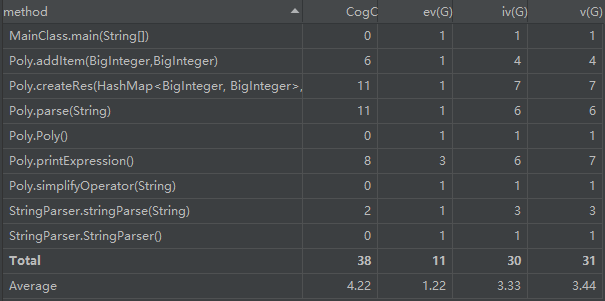
类与方法的评估
| 类 | 属性个数 | 方法个数 | 方法规模 | 方法的分支数目 | 类总代码规模 |
|---|---|---|---|---|---|
| MainClass | 0 | 1 | 7 | 无 | 13 |
| StringParser | 0 | 2 | 28 | 无 | 39 |
| Poly | 1 | 6 | 20~30 | 存在2~3层分支嵌套 | 119 |
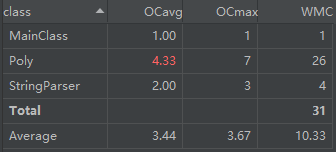
经典的OO度量
类图分析
第一次作业层次化较差(几乎没有严格的层次划分),因此选择如下方式进行说明而不采用标准类图:
-
MainClass
-
main(String[]):主函数入口,负责输入输出
-
-
StringParser
-
stringParser(String):解析表达式字符串
-
-
Poly
-
printExpression():输出求导结果
-
createRes(HashMap<BigInteger, BigInteger>, BigInteger):生成求导后的表达式
-
addItem(BigInteger, BigInteger):把项加入列表容器
-
parse(String):解析项
-
simplifyOperator(String):合并加减运算符
-
优缺点分析
第一次作业采用正则表达式,写了一串很长的正则表达式来解析表达式:
String regex1 = "([+-]?([+-]?(x(\\*\\*[+-]?[0-9]+)?|[+-]?[0-9]+)" +
"(\\*(x(\\*\\*[+-]?[0-9]+)?|[+-]?[0-9]+))*))(.*)";
String regex2 = "([+-]([+-]?(x(\\*\\*[+-]?[0-9]+)?|[+-]?[0-9]+)" +
"(\\*(x(\\*\\*[+-]?[0-9]+)?|[+-]?[0-9]+))*))(.*)";
由于第一次作业没有表达式的嵌套,因此根据题干中的形式化表达写出正则表达式比较容易。但是这样的写法拓展性较差,这也导致了之后的第二次作业无法在第一次的基础上进行迭代。
第二次作业
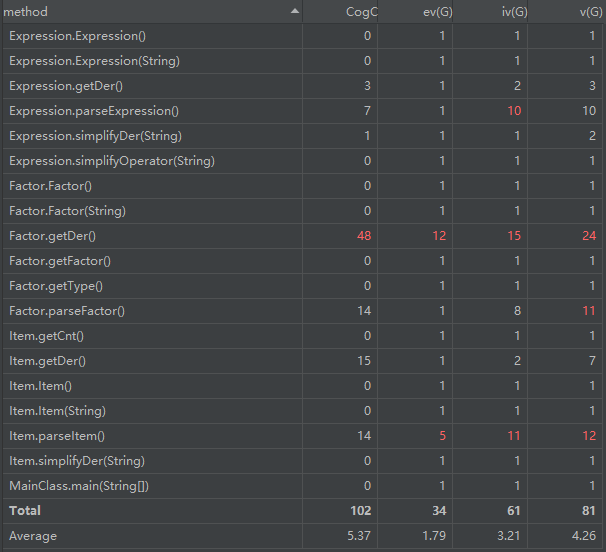
类与方法的评估
| 类 | 属性个数 | 方法个数 | 方法规模 | 方法的分支数目 | 类总代码规模 |
|---|---|---|---|---|---|
| MainClass | 0 | 1 | 7 | 无 | 10 |
| Expression | 2 | 5 | 10~34 | 存在2层分支嵌套 | 76 |
| Item | 5 | 3 | 20~30 | 存在2~3层分支嵌套 | 116 |
| Factor | 3 | 4 | 30~60 | 分支数目较多,且存在2~3层嵌套 | 121 |
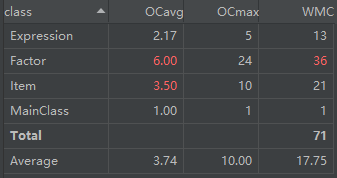
经典的OO度量
类图分析
与第三次作业一起给出类图和每个类的设计考虑。
优缺点分析
由于第一次作业的代码拓展性较差,面对表达式嵌套的需求,第二次作业果断采用重构,根据指导书的提示,按层次分为Expression(表达式)类、Item(项)类、Factor(因子)类。
这样的做法采用了递归下降的思想,有利于迭代开发,但是每个类内部逻辑较为复杂,代码的层次性还有待提高。
第三次作业
类与方法的评估
| 类 | 属性个数 | 方法个数 | 方法规模 | 方法的分支数目 | 类总代码规模 |
|---|---|---|---|---|---|
| MainClass | 0 | 3 | 10~25 | 存在2~3层分支嵌套 | 56 |
| Expression | 2 | 4 | 5~30 | 分支数目较多,且存在2~3层嵌套 | 55 |
| Item | 3 | 5 | 5~20 | 存在2层分支嵌套 | 76 |
| Factor | 3 | 6 | 5~40 | 分支数目较多,且存在2~3层嵌套 | 144 |
| OpAdd | 1 | 2 | 3~7 | 无分支嵌套 | 22 |
| OpMult | 1 | 2 | 3~12 | 存在3层分支嵌套 | 27 |
经典的OO度量
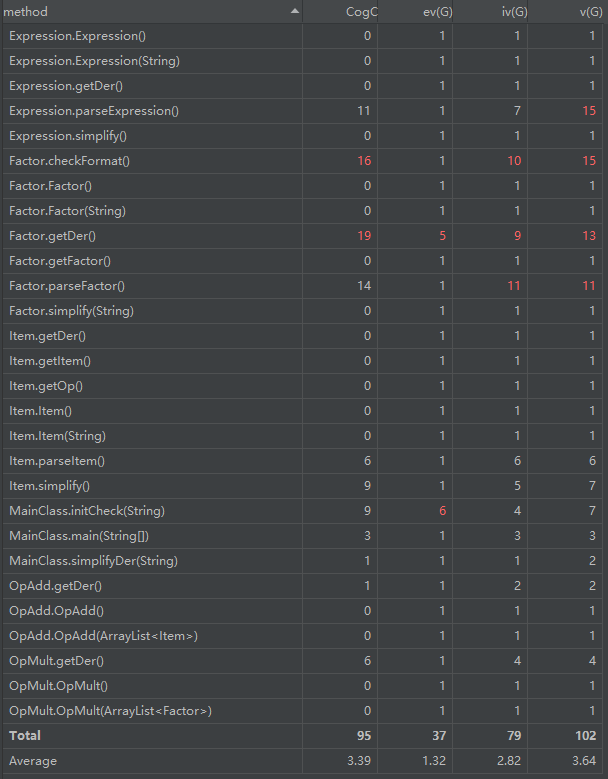
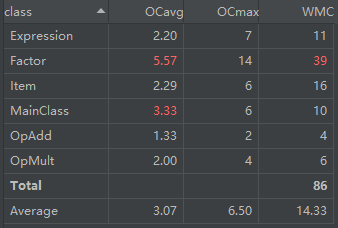
类图分析
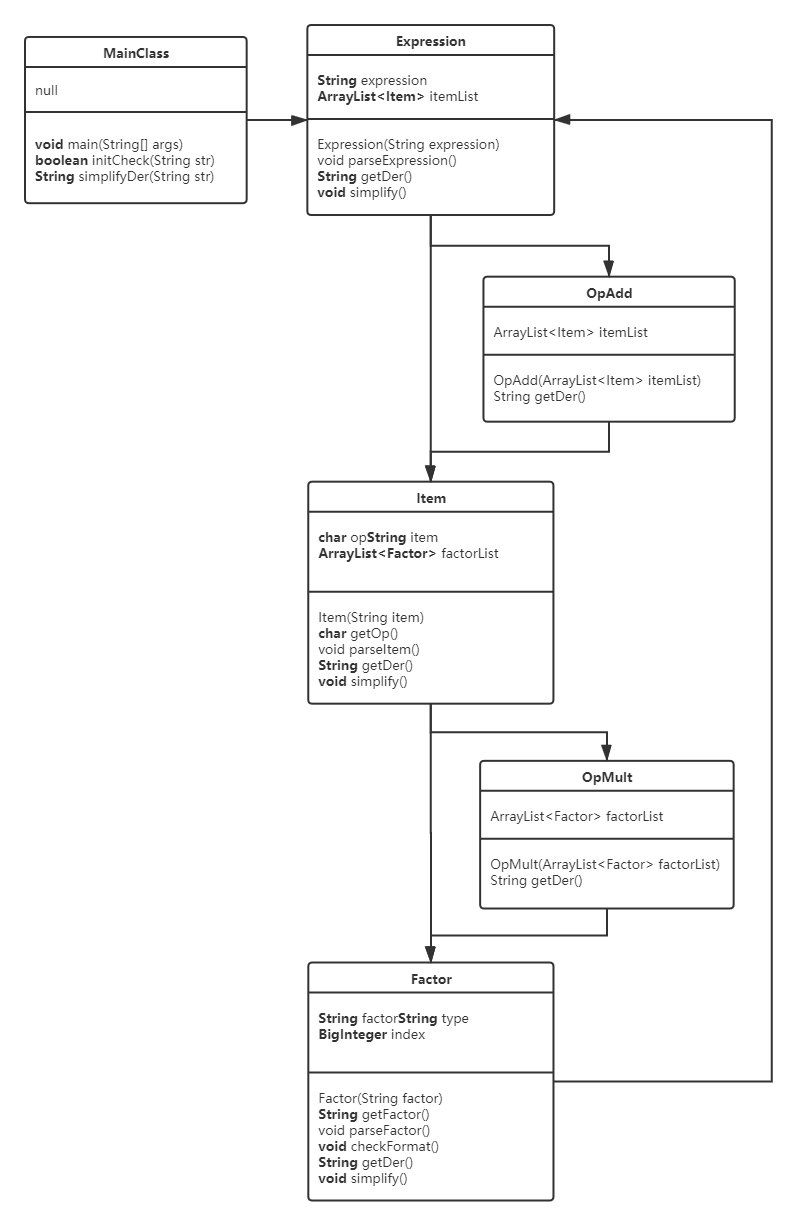
MainClass:主入口,主要负责输入输出
Expression:表达式类,用于处理表达式,并获取由项组成的列表
Item:项类,用于处理项,并获取由因子组成的列表
OpAdd:连加类,用于实现加法求导法则
OpMult:连乘类,用于实现乘法求导法则
优缺点分析
第三次作业在第二次作业的基础上增加了两个类:OpAdd(连加类)、OpMult(连乘类),进一步解放了Expression、Item、Factor三个类中的复杂逻辑。
本次作业仍然采用递归下降的思想,这也有利于格式的检查,可拓展性也较高。但是,类内部仍然使用较多的if和switch,不够简洁,层次性也不佳。
Bug及性能分析
第一次作业
第一次作业在公测和互测中均没有被找出bug。
为了提高性能分(输出表达式的长度),我在代码中采用了合并同类项、正项提前等方法。最后,由于忽略了x**2可以缩短为x*x这个特例,性能分没有拿满。
第二次作业
第二次作业在强测和互测中均被找出不少bug,主要分为以下几类:
-
TLE
-
出现原因:在处理嵌套时,无意义地多次调用递归嵌套,导致复杂度急剧上升以至于超时
-
解决方法:将递归获得的返回值储存起来,避免重复调用
-
-
缺少外层括号
-
出现原因:在对表达式因子求导时,没有在求导结果外面添加括号,导致例如
a*(b+c)变成了a*b+c,求导出错 -
解决方法:在对表达式因子求导之后,外套一层括号
-
-
出现
(空)表达式因子-
出现原因:过度优化,当表达式求导结果为零时,直接省略,导致
(0)变成了()出现了WrongFormat -
解决方法:1、将
*()移除;2、省去此情况的优化,保留0
第二次的作业性能其实蛮尴尬的,该优化的地方没有进行优化,部分优化之处又过度导致bug的产生,可以说是得不偿失。
-
第三次作业
第三次作业为了保证正确性,因此放弃了优化。这也使得本次作业的强测和互测均没有被找出bug,但是性能分极低,除了WrongFormat的几个测试点,其他强测点得分几乎都为80(性能分一分没拿到)。
互测找bug策略
-
自己构建评测机/对拍器
在第一次作业中,由于表达式的形式化表达较简单,因此我在java中利用Xeger包和正则表达式,自动生成测试数据,并利用程序将他人的输出结果与我自己的结果进行对拍比对,从而发现bug。因此,在第一次作业中,我发现了两个人的bug。
-
使用深层嵌套的数据,发现别人TLE的bug
在第二次作业中,我手动构造了几个嵌套较深的数据,成功发现了两个人的bug。我自己的程序由于也存在这种类型的bug,也因此被别人找出了TLE的bug。
-
测试单一常数或简单因子
对于单一常数,某些人的输出为空,对于一些简单的因子(如表达式因子),一些同学的输出也可能出现bug。
-
根据表达式树构造全覆盖的测试样例(没有完全做到)
在第二次作业和第三次作业的互测阶段,我没有构建评测机/对拍器(没时间搞)。所以我试图通过表达式树,构造全覆盖的测试数据。老师和助教在研讨课上也提到过这一方法,奈何手动构造太过复杂,进行一番尝试后还是放弃了这一方式。
重构经历总结
-
在第一次作业向第二次作业迭代的时候,果断选择重构。由于第一次作业没有考虑之后可能的需求,为图简单采用了超长正则表达式的方式暴力解析,而到了第二次作业面对嵌套情况,正则表达式力不从心,因此只能选择重构,根据指导书后面的提示,建立表达式类、项类和因子类。
-
在第二次作业向第三次作业迭代的时候,为了减少每一个类中的复杂度,又进行了小规模的重构,增加了连加类和连乘类,简化了求导的计算,同时使得层次更加清晰。
-
在第三次作业内部,为了方便格式的判断,又对某些类及其内部方法进行了较小的重构,使其能够在递归下降解析字符串的过程中完成对格式的判断和输出。
-
三次作业,几乎每次都要重构,这也是我需要反思的。在进行代码开发的时候,眼光要放长远,不能图方便而采用局限性很大的算法,而应该尽量在一开始就做好规划。在之后的作业中,我也会避免过多地重构,反而在一开始就花更多时间进行思考和规划,减少之后因为重构而导致的时间浪费。
心得体会
-
第一单元的OO作业就给了我们一个下马威,让许多同学(包括我)一边挣扎一边学习。用熬夜和掉发的教训让我们领略到面向对象的艺术性——架构得好,想错都难;架构拉跨,全是bug。在理论课和研讨课上,老师、助教以及同学也都反复强调面向对象编程层次化架构的重要性,我想,之后的作业和学习过程中更应该多思考多规划。
-
就像之前在重构部分说的,OO这一单元培养我们对于较大工程的代码架构和迭代能力。虽说重构真的很难避免,但是,如果我们能在写代码之前多花点时间考虑,也许就能减少无谓的重构和时间浪费。
-
OO很重要,但是也要做好trade off,要尽力完成,但是也要做好取舍。举个例子,第一次作业较简单,我有时间去构建一个对拍器,但是之后的两次作业花了我许多时间,因此,我觉得不能再在OO上面花太多时间了,因此在通过中测后,只进行了少量的优化甚至没有优化,拿剩下的时间去巩固和学习其他科目的知识。
-
要注意身体,第一单元的作业过程中,好多同学都熬夜写代码,我也因为改bug熬了一次夜。以后的学习中还是要合理规划好时间,避免熬夜,注意身体(头发)


